The tool to control the behavior of robots on your site
Greetings
Today I would like to tell you about my project, the start of which was given back in 2008. Since then, much has changed, both in the data storage architecture and in information processing algorithms.
It's about the service for SEO specialists and / or ordinary webmasters. BotHunter is a passive monitoring system (in real time) for user agents on your site. Examples of interfaces, see below, or in a DEMO account on the site of the system (limited functionality in demo mode). Read on

')
Considering my appetites and the amount of data analyzed, I wrote this service for myself. For me, it is more understandable is the "graphic answer" to all questions. Frequently asked questions BotHunter will answer:
At once I would like to stop those who are ready to ask the question “Why? Are there Yandex.Webmaster and google webmasters? "
Yes, these services are useful and well-known, but they will not answer the following questions:
1. Are there pages on my site that bots know about, but they are not in Sitemap.XML?
2. Is there a page on my site that the bot has visited, but there has never been any traffic on them (I want a list)?
3. What is the share of urls, the crawlers constantly visit, but they are not in the search?
4. Is there a page on my site with the same weight in bytes (also a duplicate theme)?
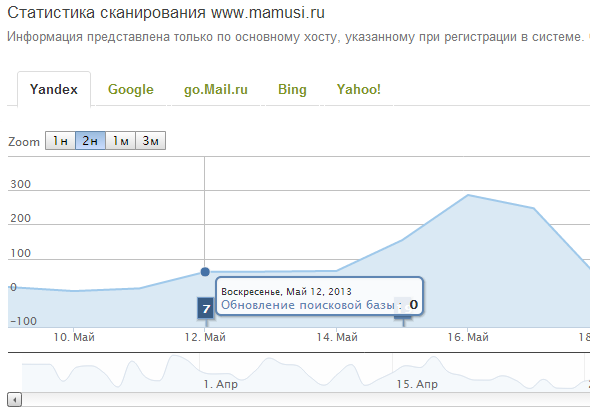
5. After updating the search base (or changing the algorithm) of such and such a number; How many pages of the site do not visit bots anymore? And how many of them are no longer traffic entry points from organic delivery?
6. etc.
The list of interesting questions can be continued, and each of us will have our own list ...


In addition to simple and clear reports, BotHunter daily checks the integrity of the robots.txt and sitemap.xml files for each of your sites. Regarding sitemap.xml a separate song, the file is being tested for validity and compliance with the sitemap protocol. The system writes a journal about all checks and facts of report generation on a daily basis.
ps about TTX, briefly:
The main objective of this post is to get your advice .
What other data would you like to receive and in what form?
What ideas would you suggest?
Thank you in advance for constructive criticism ...
Today I would like to tell you about my project, the start of which was given back in 2008. Since then, much has changed, both in the data storage architecture and in information processing algorithms.
It's about the service for SEO specialists and / or ordinary webmasters. BotHunter is a passive monitoring system (in real time) for user agents on your site. Examples of interfaces, see below, or in a DEMO account on the site of the system (limited functionality in demo mode). Read on
')
Prehistory
Considering my appetites and the amount of data analyzed, I wrote this service for myself. For me, it is more understandable is the "graphic answer" to all questions. Frequently asked questions BotHunter will answer:
- Search robots visited my site, when, how often?
- Who parsed my site & when, seeming to be a search bot?
- How many pages of my site have been loaded by a search robot?
- How many pages that visited search crawler participate in the search?
- How many pages participating in search bring traffic?
- What is the proportion of landing page (s) that the search bot visited, but they were never entry points (from search engines)?
- How many pages from Sitemap.XML have been indexed?
- the search bot visits my site all the time, is that enough?
- Is it possible in one system to see the data on working with Yandex, Google, Search.Mail.ru, Bing, Yahoo! (on the big list of my sites)?
- Are there pages on the site that can be “harmful” for search engine promotion?
- etc. etc.
There is a finished bike
At once I would like to stop those who are ready to ask the question “Why? Are there Yandex.Webmaster and google webmasters? "
Yes, these services are useful and well-known, but they will not answer the following questions:
1. Are there pages on my site that bots know about, but they are not in Sitemap.XML?
2. Is there a page on my site that the bot has visited, but there has never been any traffic on them (I want a list)?
3. What is the share of urls, the crawlers constantly visit, but they are not in the search?
4. Is there a page on my site with the same weight in bytes (also a duplicate theme)?
5. After updating the search base (or changing the algorithm) of such and such a number; How many pages of the site do not visit bots anymore? And how many of them are no longer traffic entry points from organic delivery?
6. etc.
The list of interesting questions can be continued, and each of us will have our own list ...
What are the advantages of the service
- there is an event notification system (according to the list of criteria)
- There is no limit to the number of sites in one account.
- it makes no sense to look for a “needle” in a stack of logs, the system itself will inform you about the event
- we analyze and present data on several search engines in one interface
- it is possible to analyze not only the entire site, but only its slice, segment, etc. (based on regular expressions for urla)
- All data is stored in our cloud and history is available from the moment the site is registered in the system.
- reports prevent fuzzy duplicates
- if you regularly parse your site, we will let you know who it is. You will not need to constantly log logs
- the service is free
In addition to simple and clear reports, BotHunter daily checks the integrity of the robots.txt and sitemap.xml files for each of your sites. Regarding sitemap.xml a separate song, the file is being tested for validity and compliance with the sitemap protocol. The system writes a journal about all checks and facts of report generation on a daily basis.
What's in the plans
- detection of deviations from the statistical indexing rate (of your site)
- identification of typical errors
- recommendations on indexing settings (considering the features of each site)
- [collection] collection of key phrases that brought traffic to the site
- [collection expansion] getting a list of key phrases recommended for the site
- integration with Google Analytics to predict traffic loss (by site segments)
- what is useful for specialists (your recommendations and ideas)
ps about TTX, briefly:
- own server group is used in DC Filanco
- we store and analyze all data in NoSQL, if more specifically, I use MongoDB
- your log files are not stored, only the results of processing
- For authorization use your profile in: facebook, yandex or google
The main objective of this post is to get your advice .
What other data would you like to receive and in what form?
What ideas would you suggest?
Thank you in advance for constructive criticism ...
Source: https://habr.com/ru/post/180849/
All Articles