Images: formats and compression (1/3)

What does a site consume more traffic? Most often these are pictures, and their total “weight” is often several times larger than that of markup, scripts and styles. In image files of common formats, raster data is stored in a compressed form, and this is significantly better than uncompressed BMP. And if you want even better? After all, in fairly large projects every byte is on the account (for example, in TradingView, which is really too modest).
There are many tools for perezhatiya graphics, from highly specialized to powerful combines. On Habré already have a wonderful overview of such programs, and the question of how you can squeeze the picture, considered more than in detail.
')
But how do such programs work, what can be improved and how to make one's own? I invite you to a tour of image formats and algorithms for compressing raster data.
Middle Ages
The eighties of the last century were the time of the formation of raster graphics. Graphics as such has been used before, but now it has become much more accessible, and not least the game industry has influenced it. Atari 2600 allowed to draw something more refined than a white rectangle. And Commodore 64 had video memory, with real pixels, and it was more convenient to work with it than “ switch the color no later than the 31415th clock ”.
It is difficult to draw Mona Lisa on the screen, exposing the pixels manually using a tricky algorithm. Yes, and not necessary, because from the video memory to pull out a piece of data and save it to a file, and then insert it from the file. Such a memory dump in BASIC was made by the
BSAVE team, and the format itself was named after it BSAVE'd . It became much more convenient to edit images, and simple graphical editors, which are mostly indistinguishable from each other, flourished in a lush color.But some of the editors have outgrown the childhood age and have become a very convenient and useful tool. So in 1984 appeared PCPaint, in which you could draw with the mouse. In addition to the obvious comforts of the user interface, PCPaint gave another advantage. The fact is that the BSAVE dump did not include data on image size, color depth and palette, and if there were few video modes (and the color image was shown in black and white), then for the palette you had to use a separate PAL file. In the PIC format of PCPaint, both the palette and the BSAVE dump were contained. This is a small step for the programmer and a giant leap for the whole of humanity. Something like “let's think out the MKV format, in which the subtitles can be stored inside, so that they do not need to be put in the correct daddy”.
But one more problem remained unsolved: on the PC there is
BSAVE and on Apple there is BSAVE , but they generate files of different formats. This is not surprising, the internal representation of the picture in the memory differed. There were transcoders, but it became clear that this vendor-dependent fuss would not last long. In 1984, Truevision introduced the TARGA format, better known as TGA. And the next in 1985 saw the light of PC Paintbrush. Although PC Paintbrush sold worse, its PCX format, portable and fairly simple, lived longer than the PIC.Both in TGA and PCX, data on image size and palette were stored explicitly, without strong reference to hardware. This became possible because pixel data no longer depended on a specific platform and were simply scanlines: from left to right, from top to bottom.
But there was another important feature of these two formats, the raster data in them were stored in a compressed form. The RLE algorithm used was not the height of efficiency, but it was already quite good.
RLE
RLE (Run length encoding) is quite a simple algorithm, but it shows well how data compression works. To compress data without loss means to get rid of redundancy in them. To do this, take a set of data, find a chain of duplicate values in them and replace them with something more compact.
RLE is usually translated as “run length coding”, and such duplicate values are called “runs”. And although I prefer the translation of the “run”, I can’t do anything, this is already an established term.
Most likely, you are already using it. Let's look at the line “
AAAAAAAAAAAABBBAAAAAAAAA ”. If we have to dictate it over the phone, it will sound like “twelve capital letters A, three capital letters B, nine capital letters A”. If we write this down, we get “ 12 A 3 B 9 A ”, and in order to avoid misunderstandings, then “ 9 A 3 A 3 B 9 A ”. Much more compact.Now take another line, “
0KXQsNCx0YDQsNGF0LDQsdGA ”, and try to compress it like this. It turns out " 1 0 1 K 1 X ...", stop-stop-stop! The string is obtained twice as long as the original, it is never compression. We modify the algorithm and add letters to the numbers: the letter A means that the next character is written "as is"; if B, then two; if C, then three, and so on. It turns out " X 0KXQsNCx0YDQsNGF0LDQsdGA ". So, at best, we get a compression of 350%, and at worst, we lose only 4%.Of course, in real conditions, bytes are usually encoded, not letters of the Latin alphabet, and sequence lengths are encoded with values from 0 to 255. Plus, usually meaningless values of run lengths are ignored: in our example, 1 and A do the same, and 0 in general does not make sense. But these are the details, the essence remains the same.
Entropy
No matter how much you want to avoid the theory, this thing is too important to ignore. Have you noticed that not all sequences can be compressed? The
AAAAAAAAAAAABBBAAAAAAAAA and 0KXQsNCx0YDQsNGF0LDQsdGA lines are 24 characters long, but in the second, these characters are more chaotic and harder to compress.The measure of such randomness is informational entropy, which is defined as the amount of information in the message.
 |  |  |
|---|---|---|
| Little entropy | More | More |
The very presence of informational entropy suggests that the data can only be compressed to a certain length. Further, no magic in the process is not involved. And according to Claude Shannon , the movie “Click” does not shrink to kilobytes.
To illustrate this, we turn to the fact that at first glance it has nothing to do with IT.
 |  |  |
|---|
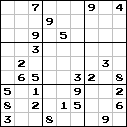
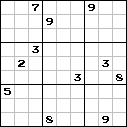
Sudoku on the left contains 81 figures and has already been resolved. The one in the middle contains less information, 26 figures, but having solved it, you can restore all the original 81.
But on the right side of Sudoku everything is very bad - too much data has been removed from it, and it is no longer solved, that is, we will not receive the initial data set.
PCX
But back to the PCX and do what no one else has done for ten years, create the PCX file, and manually. You need to know your tool, so let's look at the specifications and find out what this format is. Here are the main points:
- The image can be up to 65536 × 65536. Palette to 256 colors, or 24-bit color without a palette. The header is always 128 bytes in size. It contains the image size, the number of colors and the palette up to 16 colors one byte per channel. Naturally, the 256-color palette does not fit into such a header, and if it exists, it is added to the end of the file and has a size of 769 bytes (1 byte of signature and 256 × 3 bytes of data). There is also a field for the CGA palette, but it is no longer supported.
- The raw data stream consists of scanlines — horizontal lines into one scribble. Up to 4 bit planes can be inside each scanline: R, G, B, A. All planes are written sequentially:
RRRRGGGGBBBBAAAA. Planes consist of a strictly even number of bytes, and, if necessary, placeholders are added to the raw data so that this condition is fulfilled. Such data placeholders are ignored during decoding. - Compression of "raw" raster data is performed line by line, using RLE. “Line by line” means that the RLE series cannot go beyond the limits of the bit plane.
- In RLE, byte values from 192 to 255 encode the number of repetitions of a character from 0 to 63 times, respectively. The remaining values are literal; if they are found on the place where the number of repetitions is expected, they are considered to be repeated once.
PCX in practice
Now let's take this technical data sheet as an example. Take for example such a picture (17 × 8, for convenience, increased 8 times):

We will be defined with a palette. In the image there are three different colors, so we are suitable palettes of 4, 16 and 256 colors, as well as Truecolor. In the 4-color palette, we will have 4 values in one byte (8 bits of a byte divided by 2 bits of the number in the palette); in 16-color - 2 pixels per byte; in 256-color - pixel per byte (plus 769 bytes of an additional palette); in Truecolor, three bytes per pixel. The choice is obvious, 4 colors.
Colors arrange, for example, like this:
 |  |  |  |
|---|
Now we write out the bit values of the first line, starting with the most significant bits. Listing in quaternary, separators - byte boundaries.
0000 0000 0000 0000 0It turns out 4.25 bytes. RLE with fractional bytes does not work, we finish up to five.
0000 0000 0000 0000 0 000The documentation states that there must be an even number of bytes in the scanline. Nothing to do, we finish more.
0000 0000 0000 0000 0 000 0000Do the same with the rest of the lines, we get:
0000 0000 0000 0000 0 000 00000111 1111 1111 1111 0 000 00000121 2121 2121 2121 0 000 00000212 1212 1212 1212 0 000 00000222 2222 2222 2222 0 000 00000202 0202 0202 0202 0 000 00000020 2020 2020 2020 0 000 00000000 0000 0000 0000 0 000 0000Now let's see what values can be compressed. We note only sequences of identical bytes longer than 2, because the encoding of a series of 2 bytes will take 2 bytes, and there is no special reason for this.
0000 0000 0000 0000 0 000 00000111 1111 1111 1111 0 000 00000121 2121 2121 2121 0 000 00000212 1212 1212 1212 0 000 00000222 2222 2222 2222 0 000 00000202 0202 0202 0202 0 000 00000020 2020 2020 2020 0 000 00000000 0000 0000 0000 0 000 0000Please note that although zero bytes at the end of the last but one line are asked to cling to the last line, this will not work, the border of the scanline should not be crossed.
Now the knight's move. In the specification it is not written anywhere, what exactly is the need to finish scanlines to an even number of bytes. All the same, the decoder will throw out these values. Therefore, we can save as much as two bytes by doing this:
0000 0000 0000 0000 0 000 00000111 1111 1111 1111 0 000 00000121 2121 2121 2121 0 000 00000212 1212 1212 1212 0 000 00000222 2222 2222 2222 0 000 00000202 0202 0202 0202 0 202 02020020 2020 2020 2020 0 000 00000000 0000 0000 0000 0 000 0000Encode the resulting RLE. It would probably be more convenient to move to a more familiar hexadecimal view:
00 00 00 00 00 0015 55 55 55 00 0019 99 99 99 00 0026 66 66 66 00 002A AA AA AA 00 0022 22 22 22 22 2208 88 88 88 00 0000 00 00 00 00 00We encode the first line. 6 bytes
0x00 . Repeat 6 times corresponds to the value 192 + 6 = 198 or C6 . After it we write what value we are going to repeat 6 times, it turns out 0xC6 0x00 . The first scanline is ready.The second scanline starts from
0x15 . This value can be encoded as 0xC1 0x15 (“once 0x15 ”). But due to the RLE feature in PCX, we can write it simply as 0x15 , and “once” will be implied.Then three identical bytes become
0xC3 0x55 .And at the end of the line are two null bytes, which can be represented in two ways: head on,
0x00 0x00 , or more cleverly, 0xC2 0x00 . And this way and that two bytes. It is unlikely that you will be able to impress girls with a cunning trick, but there are no other reasons to do things more intricate than necessary , so we just take 0x00 0x00 .By the way, about intricate things. Insert something like
0xC0 0x73 0xC0 0xC0 0x73 0xC0 0x65 0xC0 0x63 0xC0 0x72 0xC0 0x65 0xC0 0x74 , i.e., a series with a length of 0, and they will not affect the image itself. Wikipedia writes that it can be used for steganography, but as for me, it is so sewn with white thread, and it doesn’t work for anything other than inflating file size.Continuing in this way, we get:
C6 0015 C3 55 00 0019 C3 99 00 0026 C3 66 00 002A C3 AA 00 00C6 2208 C3 88 00 00C6 00It remains to add a 128-byte header on top and that's it! And to admire the resulting, you can run this script . It is on node.js, but I am sure that it’s easy to rewrite your favorite language.
PCX practice 2: palette
Now take another image and transfer it to PCX again, trying to compress as much as possible. This time the picture is smaller, 7 × 5.
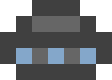
This is a UFO. I know that is not very similar.
First of all, choose the color depth: 2 bits. These are four colors, just as much as we need. Define a palette, for example, like this:
 |  |  |  |
|---|
Now it's the raster data queue. For the second time, the tedious process of writing tsiferok will not be done, we will immediately write down the raw data and what came out of them in hexadecimal.
| Raw data | Compressed data |
0F C03A B0FF FFD9 9C3F F0 | 0F C1 C03A B0C2 FFC1 D9 9C3F C1 F0 |
Oops! Compressed data turned out more in size than the original. This is because the values from
0xC0 to 0xFF are repetition markers and cannot be written just like that. Instead of 0xC0 had to substitute C1 C0 , instead of 0xF0 - 0xC1 0xF0 and so on.In the case of
0xFF 0xFF we were lucky - we did not lose precious bytes there. But in general, a sad picture comes out: now RLE, instead of helping, only hinders.Towards hopelessness, let's see what can be done with this. Markers are bytes with two high bits equal to one, 11 XXXXXX . Data is written sequentially, starting with the most significant bit. Reads, with a two-bit color depth, whether a byte is a marker or not, pixels are influenced by a 4 × n offset. Namely, the pixels of color numbered 3 (in our case, dark gray).
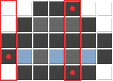
Here they are, the culprits of the proliferation of file sizes. In the third line, the dark gray pixels also fall into the selected columns, but they do not make the weather for us: the line itself will give two identical bytes when encoding.
We determine the order of colors in the palette ourselves, so we will select the color number 3 as the one that is least found at the 4 × n offset. Blue is the best candidate, it does not occur in such places at all. Redefine the palette and make a second attempt.
|  |  |  |
|---|
| Raw data | Compressed data |
0A 8025 60AA AAB7 782A A0 | 0A 8025 60AA AAB7 782A A0 |
Compressed data were identical to the original. RLE this image was too tough, but at least there is no overhead projector. Anyway, raster data is ready, and this is the maximum that can be squeezed out.
Well, and demo: UFO generator
Total
Once again, briefly, techniques to help reduce the weight of PCX:
- The choice of the minimum possible color depth (palette size);
- Optimization of garbage data;
- Delete meaningless data (series of length 0);
- Palette optimization.
To be continued
Well, perhaps that's all. I will not tell about the TGA, although it is different from the PCX, but there are much more similarities than differences. And there were no other straightforward graphic formats of that time.
Except, of course, the CompuServe GIF format. We will rummage in it next time.
Source: https://habr.com/ru/post/180381/
All Articles