Million PPS per second - connectedness and balancing

At the last RIT ++ conference I was lucky to be the first speaker of a conference of such a scale and of such significance. In this article, I do not just want to retell everything that I reported. It was unusual for me to speak for such a large audience for the first time and I forgot to tell half, I was nervous a little. It will be about creating from scratch your own fault-tolerant structure for web projects. Few system administrators are given the opportunity to start a large project in production from scratch. I was lucky.
As I have already written, I could not tell everything that I planned from the stage, in this article I will fill these gaps, and for those who could not attend, it would be nice, the video from the conference was not given to everyone for free. Yes, and I wanted to become a Habr user for a long time, only there was no time. May holidays gave time and effort. The article will be not so much technical with a bunch of configs and graphs - the article will be principled, all the gaps of minor technical issues can be filled in the comments.

We set the task : we need to organize a 99.9% fault-tolerant web project, which will not depend on a specific data center (DC), have double redundancy on switching to DC, have fault tolerance on balancing and very quickly enter and output a Real server. If one of the DCs falls, the second one should receive all traffic without drops and retransmitters. We will only talk about the front, about failures, balancing and a bit about the deployment of such a large number of servers. All have their own specificity backend.
')
Connectivity reservation
The project, which I do is very critical to even minute failures. If you sum up the RPS 400+ top Runet projects: Yandex, Mail, Rambler, Poster, Auto, etc., get our total RPS. At some point it became clear that if you keep all the eggs in one basket (DC), you can fall very well and beautifully. If you recall Chubais ’puffs in Moscow, you can understand me. We began to study the issue of separation of the server farm into several DCs. The main question is not to scatter the server on several DCs that are not connected by the same trunk, but quickly and seamlessly for the client to switch traffic from one DC to another.
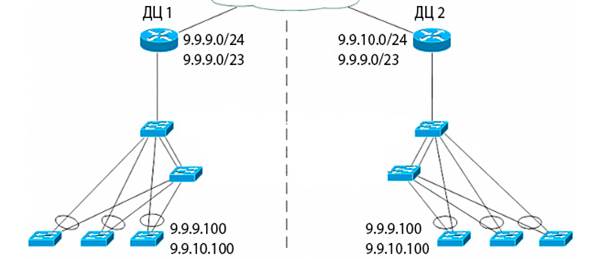
At once I will make a reservation: the implementation chosen by us is possible only if we have our own AS with a minimum of / 23 mask, officially cut into RIPE into 2 networks of / 24. Honestly, I do not know how it is at the moment, but earlier there were problems with transit announcements for the same TTK networks less than / 24. We chose as routers in the Cisco ASR 1001 DC with the corresponding filling and the ability to work with EXIST-MAP, NON-EXIST-MAP. Consider the example of 2 DC. 2 ASRs keep the tunnel just to know that the connectivity of both DCs is alive. From one DC we announce one class C network, from the second DC - the second network. As soon as we see from the second DC that the connectivity is broken, we start using NON-EXIST-MAP to announce the second network / 24 from the first DC. It is advisable to carry the DC geographically - but it is on the budget and color.
Here an important point, to which we will return a little later : on the balancing servers and on the Real servers the IP addresses from both networks in both DCs should be constantly raised simultaneously , this is important. If all the DCs are correctly connected, the routes are guided, who answers the addresses of this or that network, so you need a tunnel between the routers so that the head is not carried away. I ask the OpenSource community not to kick with my feet - I know how to implement this on quagga with prefix weights, but the project is large and there are corresponding requirements. I am simply telling how this is implemented in our country.
When testing route changes, we stumbled upon an unpleasant situation: many have Juniper access . Let me explain why unpleasant. By default, the route change is announced once every 3 minutes. For us, it's a loss of hundreds of gigabytes of data. We started experimenting with reducing the time of announcements - up to 20 seconds everything was fine: announcements rose from different ends of our huge motherland perfectly and faster, but after reducing this parameter we lost one of the DC. As it turned out, Juniper, who served one of the uplinks for less than 20 seconds, is considered a flood and it is not possible to reduce it, these are features of the firmware. Total: 21 seconds - the best option.
So. Everything. Failover for 2 DC we made, tested - it works. The real time of switching routes in Russia - from 25 to 60 seconds - depending on the distance and transit. At this stage, we have 2 bare DCs with routers. Let's start putting the stuffing in both DCs.
Redundant switching inside DC
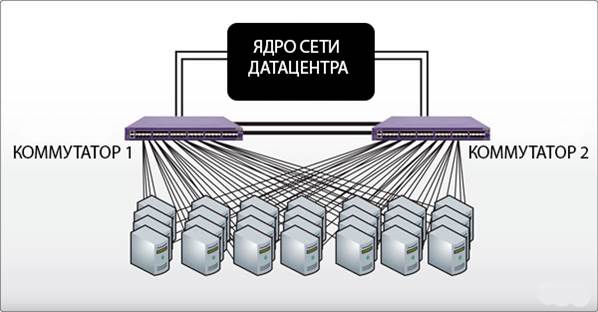
Here I will be brief - switching inside the DC is made 2 to 2: 2 physical interfaces in Bond look at different switches in vlan, serving real IP addresses, 2 physical interfaces in Bond look at different switches in vlan, serving backend. Bonding mode, we chose the simplest mode = 1 - to failure, we simply scattered the zero parts of the bonding on different switches. In general, the simpler, the more reliable . On each server participating in the front and back - 4 physical interfaces. The picture shows only the front. The switches are connected not only over 10G, but also with a backup power cable and are connected to different UPSs. Mode = 1 does not require special configuration of switches, which simplifies the management of the entire infrastructure.
Balancing
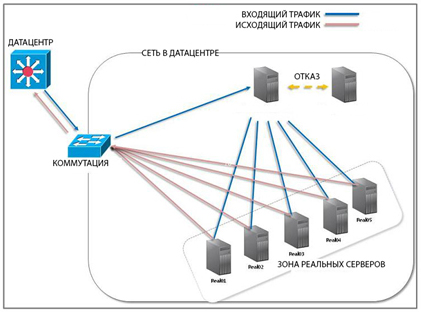
Actually there were no specific alternatives, IPVS was selected in DR (Direct Routing) mode. As I said above, this balancing method is less expensive. It deprives the charms of dumping connections in both directions, as in NAT, but requires less resources. Notrack lovers will say - it is better not to do this if it is important for you to save 100% of the compounds. IPVS is a regular at Centos and does not require special shamanism during installation. The only nuance we encountered is that by default IPVS is ready to accept 4096 simultaneous connections - this is 12 bits.

In order for the balancer to be ready to accept a million connections, this parameter needs to be increased to 20 bits. It was not possible to do this through options in the module management (modprobe.d) - ipvsadm also stubbornly repeated that it was ready to serve 4096 connections. I had to run my pens in src and rebuild the module. For a small project, this is not so important, but if you are servicing hundreds of thousands and above connections, this is critical.
Balancing has many methods. The easiest one - RR (Round Robin) - to send incoming connections “in a circle” to the Real server. But we chose the WLC type - weighted balancing with connection control. If we synchronize the persistence parameter on the balancer with the keepalive parameter in nginx on Real servers, then we will get harmony in the connections. Just if, for example, the persistence on the balancer is 90 seconds, and keepalive in nginx on Real - 120, then we will get the following situation: the balancer will give all client connections to another Real in 90 seconds, and the old Real will keep the client connections. If we take into account that with 30 seconds keepalive for 10 thousand ESTABLISHED connections, we have about 120 thousand TIME_WAIT (this is perfectly normal, Igor Sysoev and I thought on the sidelines of the mail technoforum), then this is quite critical.
Now, by the balancing technology itself, how it works: the IP address that we have is registered in the DNS for the domain we broadcast to the external physical interface of the balancer and to the aliases of the loopbacks of Real servers. Below is an example of the configuration of sysctl Real servers - there it is necessary to cover the arp announcements and, optionally, source routing, in order for switching not to go crazy with IP duplication. I will not describe the entire sysctl - it is specific enough for each project - I will show only the parameters that are mandatory for DR specificity.
For balancers:
# Fast port recycling (TIME_WAIT) net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_tw_reuse = 1 # Local port range maximized net.ipv4.ip_local_port_range = 1024 65535 # Dont allow LB send icmp redirects on local route net.ipv4.conf.eth1.send_redirects = 0 net.ipv4.conf.eth0.send_redirects = 0 net.ipv4.conf.lo.send_redirects = 0 # Dont allow LB to accept icmp redirects on local route net.ipv4.conf.eth1.accept_redirects = 0 net.ipv4.conf.eth0.accept_redirects = 0 net.ipv4.conf.lo.accept_redirects = 0 net.ipv4.conf.default.send_redirects = 0 net.ipv4.conf.default.accept_redirects = 0 net.ipv4.conf.all.send_redirects = 0 net.ipv4.conf.all.accept_redirects = 0 # Do not accept source routing net.ipv4.conf.default.accept_source_route = 0 # Ignore ARP net.ipv4.conf.eth0.arp_ignore = 1 net.ipv4.conf.eth1.arp_ignore = 1 net.ipv4.conf.all.arp_ignore = 1 net.ipv4.conf.default.arp_ignore = 1 For Real servers:
# sysctl.conf net.ipv4.conf.bond0.arp_ignore = 1 net.ipv4.conf.all.arp_ignore = 1 net.ipv4.conf.default.arp_ignore = 1 Routing for loopback alias with real IP on Real servers with mask 255.255.255.255 should be assigned to the IP of the router serving your network and announcing it to the outside, otherwise requests for balancing will come, but Real will not respond. Some are wise with iproute2 and VIP tables, but this complicates the configuration.
Now about failover balancing and Real. Keepalived was chosen perfectly logical - the IPVS developers themselves recommend using it in conjunction with their product. The nominal scheme - MASTER + SLAVE is suitable for 99% of projects, but this did not suit us, because at the moment there are 5 balancers in one DC, in the other 3. The average cost of the blade is 120-140 thousand, so we decided to save a little. If you look closely at the keepalived configuration section, where groups are described, it becomes clear that if you specify different groups on 2 masters and describe both in the 1st slave, then 1 slave will work for 2 masters according to the scheme: 1 master fell out, The slave picked up its IP, but if the second one fell out, then the second IP is picked up on the same slave. There is a minus, of course, when both masters take off, a double load will fall on the slave, but for the balancer it is not very critical, unlike Real.
And one more little trick: in the keepalived config, the CHECK of Real servers is provided. It can be a simple TCP, it can pull an HTTP page over the control of the 200th response, but there is a MISC_CHECK. Stuck comfortable and functional. If you put a small script on the Real server, no matter what is written on it, which according to your logic will calculate the current LA and generate the dynamic weight of the Real server for the balancers, then you will get a dynamic change in the Real's weight using the MISC_DYNAMIC parameter on the balancer.
Deploy
A little bit of delay. Deploy is an automation of server deployment. If you have 2-3-4 servers, of course you will not deploy automation, but if you have dozens or hundreds of them, then you definitely need it, especially if the servers are grouped by the same tasks.
I have only 2 groups on the front - these are balancers and Real servers with nginx, which actually give the content to the user.
# file top.sls base: '*': - ssh - nginx - etc 'ccs*': - ccs 'lb*': - lbs There are many deployment systems - puppet, chief ..., but we chose salt (saltstack.org). How it works: on the salt server in the configuration you create server groups and for each group paint the deployment plan - it includes system users and groups that are required for the services to function, configuration files that should be on all servers, installed software ...
# file /srv/salt/etc/init.sls /etc/hosts: file: - managed - source: salt://files/hosts /etc/selinux/config: file: - managed - source: salt://files/selinux.config /etc/snmp/snmpd.conf: file: - managed - source: salt://files/snmpd.conf If the configuration files require data unique for each server, the salt contains a pillar template engine that can generate unique configs on the fly. Before deploying the entire farm, I started from the deployment server, so that after the formation of the server farm is completed, I can be sure that the deployment is written correctly. And so I advise you.
This is only part of the report. Be sure to choose the time and write a separate article on how to test web farms, “squeezing” the maximum from nginx without drops and retransmitters, the differences between synthetic and production tests.
Good luck in highload!
Source: https://habr.com/ru/post/179535/
All Articles