Assembling a Cmake packer or training on cats
- You will not say how many degrees below zero?
- What?
- Well, I …. I train.
- Train better .. (looks at Morgunov) ... on cats.
The article describes the experience of using CMAKE and LZ4 with some bias on the embedded system. Those familiar with Makefiles or even CMAKE can safely skip the first few paragraphs.
Cats
As cats, it is better to take a small opensource project on the network consisting of a small number of files and several targets (executable files and libraries). Such a project is difficult to find, because many popular projects are already overgrown with a bunch of files. However, the LZ4 packer turned out to be a good candidate. LZ4 is still young, and most importantly, it is quite simple and aimed at SUPER FAST data compression, which may therefore be small, since a large piece of code will not work quickly (it will not be optimized in the cache).
LZ4 can quickly compress information, which, for the embedded world, most likely means no great demands on performance and memory. I managed to adapt it to compression for LPC2478 while the amount of RAM it occupied was 12k (4k input buffer + 4k output + 4k dictionary). I think this volume can be reduced to 256 +256 + 256, naturally due to the loss of the compression ratio. Nevertheless, even this is a good option so that you do not dodge your cunning compression algorithms of the polling history of any systems if you have “almost” repeated records of 30 ~ 100 bytes in size. Those who are interested in the compression algorithm, I note, LZ4 is the optimized version of the LZ77 algorithm.
Separate praise deserves the unpacking function. It is very simple and fits in dozens of lines of code, it allows you to achieve a 1GB / s decompression speed on modern PCs.
What is the assembly system in embedded systems for?
As a rule, any project in embedded systems starts with
')
Source code → build system → compiler → executable (s) file (s)
Of course, your new-fangled proprietary IDE will do its best to do all the assembly work for you, just click “Build all”. As your “code base” grows, you will think about collecting existing code as often as possible and in various ways.
The reasons for the presence of several variants of code assembly can be the presence of the following factors:
- several projects
- several boards
- even several types of controllers
- testing parts of code on a PC
- several development branches because of a large team
The first reaction to such requirements is always: “let's insert ifdefs”, however, very soon you realize that you cannot do with ifdefs alone, but the code does not look very nice.
Makefiles
The Make utility enters the arena, and brutal men take the compiler and the keys to it and begin to write assembly rules. Make is quickly mastered, however, if you already have three projects and a lot of folders, each of which has a library, you have to be more diligent in writing Makefiles. The build scheme with Make looks like this:
Source Code → GNU MAKE → Compiler → Executable (s) File (s)
MAKE
CMAKE is an advanced make. Based on the build rules described in CmakeLists.txt, CMAKE generates build management files for MAKE and other utilities and development environments (the list of supported utilities can be obtained by running “cmake –help”). Now the scheme is as follows:
Source Code → CMAKE → GNU MAKE or NMAKE or .... → compiler → executable file (s)
Among the advantages of CMAKE I will note:
- The language of the rules of the Lisp assembly is similar and more developed than that of MAKE. A good chance to try something different from the traditional C paradigm.
- The utility is cross-platform, your build will not be dependent on IDE and working OS.
- Not only build rules are generated, but also projects for Code-blocks, Eclipse and Visual Studio.
- There are ample opportunities to generate the source code itself, as well as many modules, which allows replacing Automake and Qmake.
- There are automatic assembly systems (CDASH), packaging (CPACK) and testing (CTEST).
- MAKE is popular. Many development teams translate their projects under it (for example, KDE).
The main advantage in the field of embedded solutions is that, ultimately, your code becomes more portable, you are still one step closer to building a part of your application under a PC for more comfortable debugging. You can arrange BUILD tests automatically, I don’t know if it allows Code Red or CoCox, but with CMAKE you are not dependent on the IDE.
minimal project
Below is a simple (but not the simplest) file CmakeLists.txt.
cmake_minimum_required (VERSION 2.8) PROJECT(LZ4 C) set(SRC_DIR ${CMAKE_CURRENT_SOURCE_DIR}/) ADD_DEFINITIONS("-Wall") ADD_DEFINITIONS("-W") ADD_DEFINITIONS("-Wundef") ADD_DEFINITIONS("-Wcast-align") ADD_DEFINITIONS("-Wno-implicit-function-declaration") ADD_DEFINITIONS("-O3 -march=native -std=c99") INCLUDE_DIRECTORIES (${SRC_DIR}) set(LZ4_SRCS_LIB lz4_decoder.h lz4_encoder.h ${SRC_DIR}lz4.c ${SRC_DIR}lz4hc.c ${SRC_DIR}lz4.h ${SRC_DIR}lz4_format_description.txt) set(LZ4_SRCS ${LZ4_SRCS_LIB} ${SRC_DIR}xxhash.c ${SRC_DIR}bench.c ${SRC_DIR}lz4c.c ) set(FUZZER_SRCS # - ${LZ4_SRCS_LIB} ${SRC_DIR}fuzzer.c # ${SRC_DIR}ooops_commented_source_file.c ) # lz4c add_executable(lz4c ${LZ4_SRCS}) # fuzzer add_executable(fuzzer ${FUZZER_SRCS}) make_minimum_required sets the minimum version of Cmake. The PROJECT command sets the project name as well as the programming language (s).
Commands can be written in both lowercase and uppercase letters. The most frequent set command is an analogue of assigning and creating variables, like in Let BASIC it starts to bother a little, but then you get used to it. In CMAKE, other variables are also “predetermined”, one of them is $ {CMAKE_CURRENT_SOURCE_DIR} . As in make, SRC_DIR is the name of the variable, and $ {SRC_DIR} is the value. Variables in CMAKE are treated as lists, but can sometimes be interpreted as strings or numbers. File lists can be easily broken into several lines.
ADD_DEFINITIONS should actually be used to set the preprocessor macros, but here it is simply used to set the keys to the compiler.
add_executable sets the build target — the executable file.
Configuration
Already such a small CmakeLists.txt allows you to collect the packer LZ4 (today revision 94). Open the command console and run cmake with an indication of the generator (see image of the screen).
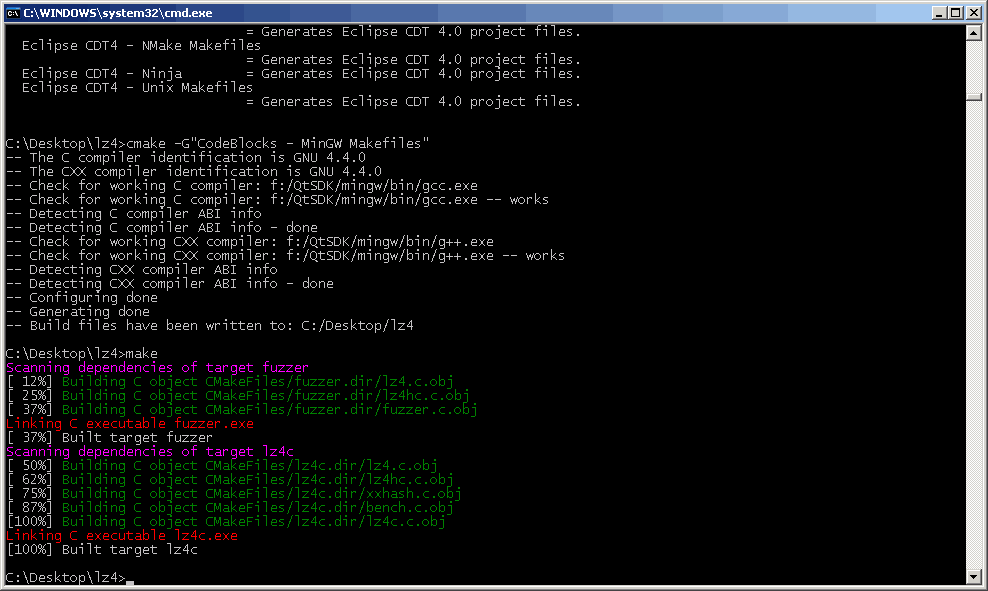
make produces some basic messages, which in this case we ignore - nothing non-standard has happened - a Makefile is generated and a project for CodeBlocks.
The presence of a preliminary setup phase in the form of running Cmake before make allows you to change the compilation process based on the launch arguments of CMAKE and the software version (OS, compiler) on which the build takes place. You can also copy files, download files, apply patches, generate source files, and more. Cmake has the ability to pass additional user-defined arguments. make can also run various utilities during the configuration process. I will try to write about this in the next section.
With a big stretch, we can say that in terms of the build, CMAKE is able to perform Portage + automake functionality in Gentoo Linux, but compared to portage, Cmake is much more compact than the python distribution, it is more portable to many platforms (primarily Windows).
Running the build
The build starts through a) CodeBlocks b) make (I advise you to try also 'make VERBOSE = 1' and 'make help'). Additional buns over make are color output to the console, as well as percentages of completion.
Meow!
Now let's have fun with our lz4 packer.
C: \ Desktop \ lz4> lz4c.exe -H
*** LZ4 Compression CLI, by Yann Collet (May 1 2013) ***
Usage:
lz4c.exe [arg] input output
Arguments:
-c0 / -c: Fast compression (default)
-c1 / -hc: High compression
-d: decompression
-y: overwrite without prompting
-H: Help (this text + advanced options)
Advanced options:
-t: test compressed file
-B #: Block size [4-7] (default: 7)
-x: enable block checksum (default: disabled)
-nx: disable stream checksum (default: enabled)
-b #: benchmark files, using # [0-1] compression level
-i #: iteration loops [1-9] (default: 3), benchmark mode only
input: can be 'stdin' (pipe) or a filename
output: can be 'stdout' (pipe) or a filename or 'null'
example: lz4c -hc stdin compressedfile.lz4
The packaging itself.
C: \ Desktop \ lz4> lz4c.exe lz4c.exe lz4c.lz4 *** LZ4 Compression CLI, by Yann Collet (May 1 2013) *** Compressed 98828 bytes into 56586 bytes ==> 57.26% Done in 0.03 s ==> 3.04 MB / s
Launch benchmark.
C: \ Desktop \ lz4> lz4c.exe -b lz4c.exe lz4c.lz4 *** LZ4 Compression CLI, by Yann Collet (May 1 2013) *** lz4c.exe: 98828 -> 56567 (57.24%), 163.3 MB / s, 467.5 MB / s lz4c.lz4: 56586 -> 56278 (99.46%), 273.1 MB / s, 1442.1 MB / s TOTAL: 155414 -> 112845 (72.61%), 191.3 MB / s, 620.0 MB / s
My computer is not very fast, and I do not pretend to complete testing, but these figures are very impressive.
Total
So, I hope this article will help you in mastering the Cmake utility. In the next part I will try to write about further research on the issue of assembly LZ4. For those who are curious, the final version of the file I wrote was accepted by the author of the program, however, in the current version of LZ4 there are two CmakeLists files, one written by me and used for assembly, and the other used to build libraries, although it is possible to combine these two files I have not reached the hands. Guru Smake-dare!
Source: https://habr.com/ru/post/178839/
All Articles