Redis - the main repository? What the hell?!
Redis is an in-memory key-value store commonly used for caches and similar mechanisms for accelerating network applications. We, however, store all our data in Redis - in our main database.
The network is full of warnings and cautionary tales of using this approach. There are horrific stories about data loss, exhaustion of memory, or people unable to effectively manage data in Redis, you may be interested in "What do you think?". So, our story, why we still decided to use Redis and how we overcame all these problems.
First of all, I would like to emphasize that most applications should not at all pay attention to the crutches used to go this way. This was important for our use case, but we can be a boundary case.
Redis is quick When I say fast, I mean Fast with a capital B. This is essentially memcached with more thoughtful data types than just string values. Even some advanced operations, such as intersecting sets, sampling zset ranges, are dazzlingly fast. There are all reasons to use Redis for rapidly changing actively requested data. It is quite often used as a cache that can be rebuilt according to data from a backup database. This is a powerful replacement for memcached, which provides more advanced caching for various types of data you have stored.
')
Like memcached, everything is in memory. Redis is saved to disk, but it does not save data synchronously as you write it. There are two reasons for which Redis as the main repository - sucks:
“You have to put all your data in memory, and ...”
- If the server fails between two synchronization with the disk - you will lose everything in memory.
Because of these two problems, Redis settled in a compact niche as a temporary cache for data that you can donate, but not the main data store. Providing quick access to frequently needed data with the possibility of rebuilding if necessary.
The disadvantage of using more traditional repositories behind Redis is to shut down the performance of these repositories. You have to sacrifice performance to make sure the data is saved to disk. Perfectly normal deal for almost every application. You can get great reading performance and “good” write performance. I must make it clear that what is “good” for me may very well be insanely fast for most people. Suffice it to say that “good” write performance should eliminate most, except for the most highly loaded applications.
I believe that you can execute a write request to Redis and then save it using a relational storage, but then the same risks of Redis crash and data loss of the write queue remain.
Moot is offered as a completely free product. We, therefore, need to be able to handle large loads on a very small amount of iron. If we need a bunch of large databases for a forum serving several million users per month, then there are no ways to remain a free service. Since we want Moot to be free and unlimited, we had to optimize to the limit.
We could simply avoid this by setting some restrictions on free services and taking money for browsing pages or posts. I don’t know about you, but in general I don’t like products that are free “until you unwind”. Let's say you set up a forum, and then something on your site will go viral. Suddenly, you will be stunned by the bill for exceeding the free level. And so what began as entertainment, due to the sudden popularity of your blog about conspiracy theories, turns into a horror of the upcoming bill. You are being punished for your success. This is what we would like to avoid.
We could also decide to monetize by placing advertising, and allowing ourselves higher operating costs. This, however, is completely at odds with our core values as a business. In our opinion, if someone is going to advertise on your site, it should be you and not us. Moot should be offered without conditions, restrictions and additions.
Taking into account all the above, it is necessary to achieve unsurpassed performance for posting and reading regardless of engineering difficulties. This is the basis for our ability to work. We had an initial goal for all API calls to be processed in less than 10ms, even under high load, and even when large complex lists or searches are being processed. Redis, obviously, can provide us with such performance, but two big problems have not gone away: How the hell can we use Redis if we can have hundreds of gigabytes of data, and what to do with the server crash?
This is how our study of design methods began, taking into account these limitations. From the very beginning, we had an accurate understanding of what tasks Moot would have, and our values as a company, so we were lucky to have the opportunity to think about these features before writing the first lines of code. I believe that these problems would be overly complex if we decided to go this way, having a lot of ready-made code.
This is the most difficult of two problems. The amount of memory that can be on one computer, of course. The largest number on EC2 is a 244-gigabyte server. Although this is still a finite volume, this is a pretty good limit to begin with. Unfortunately, your 16-core server will use only one core for Redis. Well, how about adding a Redis slave process to each core? Then you have 15 GB of memory left for each copy. Again garbage! This is a bad limitation if you want to be able to squeeze power from a server. This is not enough data for the hosting service.
We decided to design our Redis-storage from the very beginning divided among the many Redis clusters. We hash and divide the data into blocks containing all structures related to this data segment. The data is strongly separated from the very beginning and we can create new blocks as needed quickly and easily.
To break down data, we store a table of hashes and addresses like this:
When data arrives, we calculate the hash based on our data connectivity requirements, then we check in shards.map whether it has been assigned to a block, and if so, we can route calls to that block.
If the hash is not yet assigned to any block, we create a list of available blocks by multiplying them according to weight. If for example perform:
The list will look something like this:
After that we assign a random block from the list, save it to the distribution map and go on.
Using such a scheme, we can easily control how much data enters the blocks, add new blocks, or even exclude blocks from consideration if we see that they are full.
In fact, we started with hundreds of blocks, so there is nothing to worry about server load and memory limitations.
Individual blocks remain very small. One server contains many blocks in Redis databases and, if these blocks increase in size, we can easily divide Redis bases into independent instances. Let's say we have a copy of Redis with 100 blocks, we see that some blocks increase in size and we divide Redis into two copies of 50 blocks each. We can fine tune weights to maintain real-time distribution between blocks.
The hardest part is determining exactly how you segment your data. This is very specific and our version of segmentation, perhaps a topic for a separate post.
This storage strategy should be developed in the application from the very beginning. Often, people try to share data that is not so designed, and that’s the catch for using Redis. Since we clearly knew that memory limiting would be a problem, we were able to design a solution in the very core of our data management system, even before we wrote at least one line of code.
Dealing with the failures turned out to be easier to say funny. We had 3 different roles for the Redis cluster:
- Master, where almost all operations were recorded,
- Slave, where almost all readings took place,
- Keeper dedicated to save data.
The master and subordinate work in general like any other in the Redis cluster. This is nothing interesting. What we have done is that each cluster has 2 servers used as custodians. These servers are:
- Do not accept any incoming connections and do not carry any load of Redis requests, except simple replication
- AOF storage in every second mode
- Hourly RDB snapshot
- Synchronize AOF and RDB in S3
In view of the fact that the performance parameters for storage may differ somewhat, one server keeper can process a different number of blocks. We simply run one instance for each block that should be stored. In other words, there is no need for a 1 to 1 ratio between blocks and servers with the role of custodian.
We have two of these servers located in different availability zones, so even if one of the zones fails, we have a working up-to-date guardian server.
So in order for us to lose data, we need a rather large failure in EC2 and even then, we will lose only about a second of data.
If you consider a network connectivity violation scenario when the master can be isolated from subordinates, it can be leveled by checking the replication of subordinates (set an arbitrary key to an arbitrary value and check if the data from the subordinate is updated) If the master is isolated, we stop recording: Consistency and Resistance to loss of connectivity due to availability. Redis Sentinel could also help us with this, but Sentinel was released after we implemented most of the system. We did not explore how Sentinel would fit into our equation.
In the end, we were able to build a system that performs API calls in about 2 ms under load.
The value of 2 ms - when servicing our heaviest API call, initialization API call.
Many of our requests are serviced much faster (like, for example, often in 0.6-0.7 ms). We can execute 1000 API requests per second on one API server. And to build a page, one API call is required. All our data validation, block management, authentication, session management, connection management, JSON serialization, and so on are included.
API servers that allow you to work with such a load cost only $ 90 per month, so that we can maintain and horizontally scale quite large loads at a very small price. Another side benefit of heavily partitioned data blocks is that scaling is trivial.
Much of this merit is not only THESE solutions for Redis. There are a few more tricks for the system to work productively under a high parallel load. One of these tricks is that almost half of our code is written in Lua and works directly in Redis. This is another thing that they generally say not to do. As for how and why we have thousands of lines of Lua code - wait for the next post about our use of Redis.
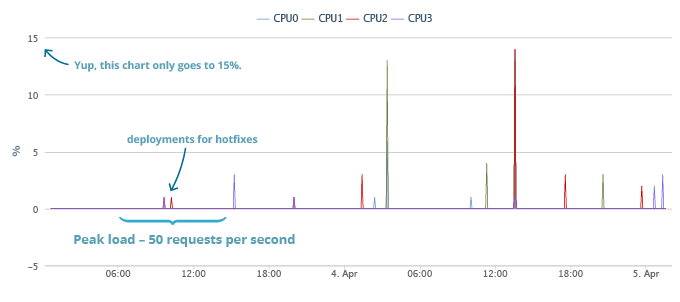
Take a look at our real performance, we started a couple of days ago, and got a good initial surge. We served 50 API calls per second and the processor of our main API server (we still send all traffic to one) was completely idle. Here are the charts, starting from our launch until the writing of the post.
Explanation: I refer to the API server as being measurable, since our application server and Redis server are one and the same. The API server carries both a few blocks and an application. The idea was to route traffic to the server where this unit is mainly located, in order to use unix sockets to connect to Redis. This will avoid unnecessary network traffic, so there is not much difference between the Application Server, the Redis master and the Redis slave. Any API server can process any request, we simply give a much higher priority to the master server of the data segment involved. All servers are application servers, and all servers are wizards for some units and subordinate to others.
tl; dr
There are many reasons not to use Redis as the main storage on a hard disk, but if, for some reason, your use case requires it, you need to start from the beginning. You should design your data separated and remember the additional cost of dedicated storage servers.
AMENDMENT
I just realized that I counted the cost of a single server and forgot to add a depreciated one-time cost of reserved instances. Must be $ 213.
The network is full of warnings and cautionary tales of using this approach. There are horrific stories about data loss, exhaustion of memory, or people unable to effectively manage data in Redis, you may be interested in "What do you think?". So, our story, why we still decided to use Redis and how we overcame all these problems.
First of all, I would like to emphasize that most applications should not at all pay attention to the crutches used to go this way. This was important for our use case, but we can be a boundary case.
Redis as data storage
Redis is quick When I say fast, I mean Fast with a capital B. This is essentially memcached with more thoughtful data types than just string values. Even some advanced operations, such as intersecting sets, sampling zset ranges, are dazzlingly fast. There are all reasons to use Redis for rapidly changing actively requested data. It is quite often used as a cache that can be rebuilt according to data from a backup database. This is a powerful replacement for memcached, which provides more advanced caching for various types of data you have stored.
')
Like memcached, everything is in memory. Redis is saved to disk, but it does not save data synchronously as you write it. There are two reasons for which Redis as the main repository - sucks:
“You have to put all your data in memory, and ...”
- If the server fails between two synchronization with the disk - you will lose everything in memory.
Because of these two problems, Redis settled in a compact niche as a temporary cache for data that you can donate, but not the main data store. Providing quick access to frequently needed data with the possibility of rebuilding if necessary.
The disadvantage of using more traditional repositories behind Redis is to shut down the performance of these repositories. You have to sacrifice performance to make sure the data is saved to disk. Perfectly normal deal for almost every application. You can get great reading performance and “good” write performance. I must make it clear that what is “good” for me may very well be insanely fast for most people. Suffice it to say that “good” write performance should eliminate most, except for the most highly loaded applications.
I believe that you can execute a write request to Redis and then save it using a relational storage, but then the same risks of Redis crash and data loss of the write queue remain.
What do we need?
Moot is offered as a completely free product. We, therefore, need to be able to handle large loads on a very small amount of iron. If we need a bunch of large databases for a forum serving several million users per month, then there are no ways to remain a free service. Since we want Moot to be free and unlimited, we had to optimize to the limit.
We could simply avoid this by setting some restrictions on free services and taking money for browsing pages or posts. I don’t know about you, but in general I don’t like products that are free “until you unwind”. Let's say you set up a forum, and then something on your site will go viral. Suddenly, you will be stunned by the bill for exceeding the free level. And so what began as entertainment, due to the sudden popularity of your blog about conspiracy theories, turns into a horror of the upcoming bill. You are being punished for your success. This is what we would like to avoid.
We could also decide to monetize by placing advertising, and allowing ourselves higher operating costs. This, however, is completely at odds with our core values as a business. In our opinion, if someone is going to advertise on your site, it should be you and not us. Moot should be offered without conditions, restrictions and additions.
Taking into account all the above, it is necessary to achieve unsurpassed performance for posting and reading regardless of engineering difficulties. This is the basis for our ability to work. We had an initial goal for all API calls to be processed in less than 10ms, even under high load, and even when large complex lists or searches are being processed. Redis, obviously, can provide us with such performance, but two big problems have not gone away: How the hell can we use Redis if we can have hundreds of gigabytes of data, and what to do with the server crash?
What to do now?
This is how our study of design methods began, taking into account these limitations. From the very beginning, we had an accurate understanding of what tasks Moot would have, and our values as a company, so we were lucky to have the opportunity to think about these features before writing the first lines of code. I believe that these problems would be overly complex if we decided to go this way, having a lot of ready-made code.
All data is in memory. Pancake.
This is the most difficult of two problems. The amount of memory that can be on one computer, of course. The largest number on EC2 is a 244-gigabyte server. Although this is still a finite volume, this is a pretty good limit to begin with. Unfortunately, your 16-core server will use only one core for Redis. Well, how about adding a Redis slave process to each core? Then you have 15 GB of memory left for each copy. Again garbage! This is a bad limitation if you want to be able to squeeze power from a server. This is not enough data for the hosting service.
We decided to design our Redis-storage from the very beginning divided among the many Redis clusters. We hash and divide the data into blocks containing all structures related to this data segment. The data is strongly separated from the very beginning and we can create new blocks as needed quickly and easily.
To break down data, we store a table of hashes and addresses like this:
shards.map = hash: {
'shard hash': [shard id]
}
shards. [shard id] = hash: {
master: [master ip / port],
slave0: [slave 0 ip / port],
slave1: [slave 0 ip / port],
...
}
shards.list = zset: {
shard1: [weight],
shard2: [weight],
...
}
When data arrives, we calculate the hash based on our data connectivity requirements, then we check in shards.map whether it has been assigned to a block, and if so, we can route calls to that block.
If the hash is not yet assigned to any block, we create a list of available blocks by multiplying them according to weight. If for example perform:
redis.call ('zadd', 'shards.list', 1, 'shard1')
redis.call ('zadd', 'shards.list', 2, 'shard2')
redis.call ('zadd', 'shards.list', 1, 'shard3')
The list will look something like this:
[shard1, shard2, shard2, shard3]
After that we assign a random block from the list, save it to the distribution map and go on.
Using such a scheme, we can easily control how much data enters the blocks, add new blocks, or even exclude blocks from consideration if we see that they are full.
In fact, we started with hundreds of blocks, so there is nothing to worry about server load and memory limitations.
Individual blocks remain very small. One server contains many blocks in Redis databases and, if these blocks increase in size, we can easily divide Redis bases into independent instances. Let's say we have a copy of Redis with 100 blocks, we see that some blocks increase in size and we divide Redis into two copies of 50 blocks each. We can fine tune weights to maintain real-time distribution between blocks.
The hardest part is determining exactly how you segment your data. This is very specific and our version of segmentation, perhaps a topic for a separate post.
This storage strategy should be developed in the application from the very beginning. Often, people try to share data that is not so designed, and that’s the catch for using Redis. Since we clearly knew that memory limiting would be a problem, we were able to design a solution in the very core of our data management system, even before we wrote at least one line of code.
Server crashes
Dealing with the failures turned out to be easier to say funny. We had 3 different roles for the Redis cluster:
- Master, where almost all operations were recorded,
- Slave, where almost all readings took place,
- Keeper dedicated to save data.
The master and subordinate work in general like any other in the Redis cluster. This is nothing interesting. What we have done is that each cluster has 2 servers used as custodians. These servers are:
- Do not accept any incoming connections and do not carry any load of Redis requests, except simple replication
- AOF storage in every second mode
- Hourly RDB snapshot
- Synchronize AOF and RDB in S3
In view of the fact that the performance parameters for storage may differ somewhat, one server keeper can process a different number of blocks. We simply run one instance for each block that should be stored. In other words, there is no need for a 1 to 1 ratio between blocks and servers with the role of custodian.
We have two of these servers located in different availability zones, so even if one of the zones fails, we have a working up-to-date guardian server.
So in order for us to lose data, we need a rather large failure in EC2 and even then, we will lose only about a second of data.
If you consider a network connectivity violation scenario when the master can be isolated from subordinates, it can be leveled by checking the replication of subordinates (set an arbitrary key to an arbitrary value and check if the data from the subordinate is updated) If the master is isolated, we stop recording: Consistency and Resistance to loss of connectivity due to availability. Redis Sentinel could also help us with this, but Sentinel was released after we implemented most of the system. We did not explore how Sentinel would fit into our equation.
Final result
In the end, we were able to build a system that performs API calls in about 2 ms under load.
The value of 2 ms - when servicing our heaviest API call, initialization API call.
Many of our requests are serviced much faster (like, for example, often in 0.6-0.7 ms). We can execute 1000 API requests per second on one API server. And to build a page, one API call is required. All our data validation, block management, authentication, session management, connection management, JSON serialization, and so on are included.
API servers that allow you to work with such a load cost only $ 90 per month, so that we can maintain and horizontally scale quite large loads at a very small price. Another side benefit of heavily partitioned data blocks is that scaling is trivial.
Much of this merit is not only THESE solutions for Redis. There are a few more tricks for the system to work productively under a high parallel load. One of these tricks is that almost half of our code is written in Lua and works directly in Redis. This is another thing that they generally say not to do. As for how and why we have thousands of lines of Lua code - wait for the next post about our use of Redis.
Take a look at our real performance, we started a couple of days ago, and got a good initial surge. We served 50 API calls per second and the processor of our main API server (we still send all traffic to one) was completely idle. Here are the charts, starting from our launch until the writing of the post.
During our peak loads, everything is quiet. You may notice a couple of bursts when we roll in hotfixes, but otherwise nothing. Later bursts correspond to system updates, patches, and other ongoing system work. The total load also includes the increased logging overhead which we conducted during the initial beta test.
Explanation: I refer to the API server as being measurable, since our application server and Redis server are one and the same. The API server carries both a few blocks and an application. The idea was to route traffic to the server where this unit is mainly located, in order to use unix sockets to connect to Redis. This will avoid unnecessary network traffic, so there is not much difference between the Application Server, the Redis master and the Redis slave. Any API server can process any request, we simply give a much higher priority to the master server of the data segment involved. All servers are application servers, and all servers are wizards for some units and subordinate to others.
tl; dr
There are many reasons not to use Redis as the main storage on a hard disk, but if, for some reason, your use case requires it, you need to start from the beginning. You should design your data separated and remember the additional cost of dedicated storage servers.
AMENDMENT
I just realized that I counted the cost of a single server and forgot to add a depreciated one-time cost of reserved instances. Must be $ 213.
Source: https://habr.com/ru/post/178525/
All Articles