History modeling in centralized and distributed version control systems
Introduction
In my practice, I had the opportunity to participate in a project migration (codebase had 5+ years of history) from a centralized version control system (centralized VCS - SVN) to distributed (distributed VCS - Mercurial). Such activities are often accompanied by a certain amount of FUD (fear, uncertainty and doubt) among the team involved in this process. If the technical aspects of the conversion (structure of new repositories, instrumental support, working with large binary files, encodings, etc.) will be solved at a certain point, then the issues related to overcoming the learning curve for the team to effectively use the new system, at the time of the transition can only begin.
With such transitions, it is important to change the view on the new version control system and its use (mindset shift). It helps a good understanding of the principles on which VCS is based. If you understand the basics, the use of the system is much simpler. Accordingly, this material will focus on the differences in history modeling between centralized and decentralized version control systems.
A small digression about differences in structure.
To begin with, I will briefly give a brief description of the structure of both systems. Let's start with the centralized :
')
- Traditional VCSs were created to back up, track, and synchronize files.
- All changes pass through the central server.

Decentralized system:
- Everyone has their own full repository in DVCS.
- DVCS were created to exchange changes.
- When using DVCS, there is no rigidly defined repository structure with a central server.
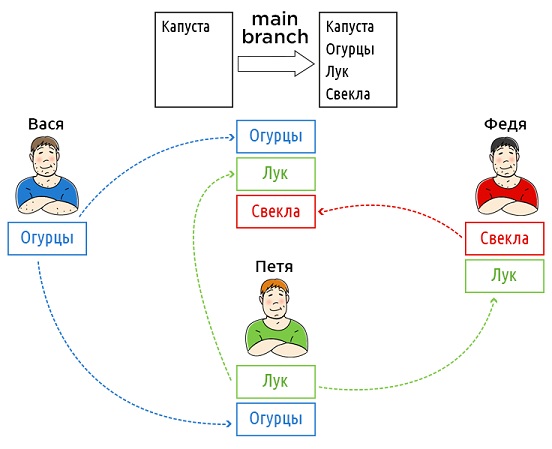
It is better not to delve into the differences in structure, in order not to weigh down the material and focus more on the main thing - modeling the history in both systems.
Myths, facts and reputation
Any person who decides to become familiar with the opportunities that provide both centralized and decentralized systems will be confronted with the myths that are associated with their use, and a certain reputation that these systems have. For example:
- Not the best SVN reputation, as a means for active branching and merging changes (branching and merging)
- The reputation of the Git system as a “magic” merge means and its greater flexibility in managing commit (removing, reordering, combining, shelving etc)
If SVN's bad reputation is mainly due to the lack of metadata associated with tracking branches in earlier versions, then Git's reputation, and indeed of all distributed systems, is associated with such an interesting thing as DAG. I want to note that centralized systems do not stand still and are actively developing in the direction of supporting scenarios that require active branching. But this is not the subject of this material, in contrast to the DAG, which we consider in more detail later in the text.
How centralized systems model their history
The key to success in using any version control system lies in understanding the model, which is used to represent the history of changes in this system. Let's start with centralized systems. The history here is modeled simply as a line. Our commits line up in a timeline. Very simple to use and understand.
The truth is, there is one thing here: we can only commit a new version if it is based on the latest version. How it looks in real conditions:
- The developers Vasya and Petya come to work in the morning and are updated for the latest revision - 2. And they start working, that is, writing code.

- Vasya manages to do everything before Petya, so he commits a new revision - 3, and with a clear conscience goes home.
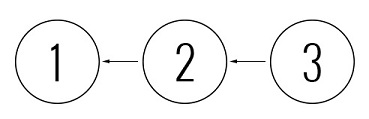
- Petya, while trying to create a new revision, cannot do this, since his changes are based on revision 2, and the last revision, thanks to Vasya's efforts, is already 3.

- Therefore, he is forced to update his working copy, merge changes, and only then he can commit revision 4, based on revision 3, not 2.
The long steps that Petya is forced to take are, in fact, automated by the means of the system used, and are not too noticeable for the developer. As a rule, in this case, Petya sees a formidable warning of the server like “You must update you working copy first”, is updated (the changes of Vasya and Petit will be combined here) and commit a new revision.
Meticulous readers will notice two things here:
- The system loses some of the information about the history of changes (the fact that initially the revisions of Vasya and Petit were based on revision 2)
- This model allows you to support branching only using external mechanisms.
For now, let's leave this information as it is and move on to distributed systems.
How do distributed systems model their history?
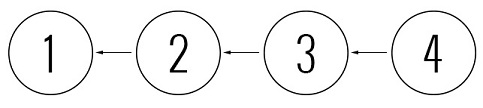
What if, in the previous example, the system would allow us to commit revision 4 based on revision 2?
And this is what would happen: our history would cease to be a line (thanks, Cap) and would turn into a graph. More specifically, in a directed acyclic graph, or directed acyclic graph (DAG). Wikipedia kindly provides us with its definition :
“The case of a directed graph in which there are no directed cycles, that is, paths that start and end at the same vertex”
Distributed systems use DAG to simulate history. As it is easy to see, DAG does not lose information about commits, in our case that revision 4 is based on revision 2.
However, there is no version in the system that contains the changes of Vasya and Petit at the same time. DAG-based tools solve this problem by merging revisions.

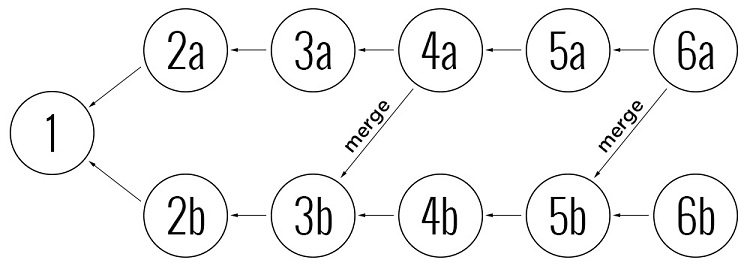
Consider an example of using DAG, in which we have two branches with a common history, and we want to synchronize branch a with branch b based on revision 5b . When transferring changes, the graph contains information that changes 2b and 3b were already merged with branch a , therefore it is only necessary to combine changes 4b and 5b with branch a . Since the DAG stores full merge history information, the merge process itself is much easier to perform automatically than if we used a system that stores history as a line and uses metadata to track branches.
For those who want to dig deeper into the version control systems, I recommend the book Eric Sink - Version Control By Example .
The problem of the latest version
On a project where more than one developer works and DVCS is used, the history of the code being developed will always look like a graph, since this reflects the real picture of how the code is developed. It is important to understand that any extra thread in history has a certain price associated with its use and tracking. Read more about this here .
I want to dwell only on the so-called “problem of the latest version”, which often raises many questions from people who have just started using DVCS. Suppose we came to work in the morning and updated our repository. The graph of the story is about the following picture:

This situation can cause a number of quite logical questions:
- The integration server must build the latest version, but it cannot determine which of the revisions is the last
- Similarly, QAs cannot determine which version to test.
- The developer cannot upgrade to the latest version for the same reason.
- If a developer wants to add a new code to the repository, on the basis of which revision should he create a new one?
- The manager should assess the progress, knowing how much functionality is completed. However, for this to happen, he must know which version is the latest
The problem with the latest version is one of the main reasons why the use of DAG-based tools seems very chaotic and incomprehensible to people after simple, centralized systems with a history in the form of a line.
The solution to this problem lies in the plane of the organization of the process on the project. You can, for example, build a process like this:
- The integration server collects all revisions or revisions, which are indicated, for example, by Test Lead
- QA team decides on its own or with the help of a manager which version to test.
- The developer is not updated to the “latest version”, but decides for himself on the basis of which revision a new commit should be created.
It is easy to see that there must be a balance between flexibility and the complexity of the applied solution.
Silver Bullet?
Is DAG the ideal solution for modeling code development history? Let's imagine this situation: I want to create revision 4, which contains the entire history of revision 1 and only revision 3 (without its history in the form of revision 2). This approach is called cherry-picking and cannot be modeled using a DAG. However, some DVCS may emulate such a scenario through extensions.

An alternative to the “classic” DVCS, such as Git, Mercurial, and Bazaar, may be Darcs , a version control system that uses a different approach to history modeling, and which is capable of supporting such a scenario as cherry-picking at the kernel level. It is quite possible that in the future such systems will force out modern DVCS.
Source: https://habr.com/ru/post/177855/
All Articles