Uninterrupted operation (HA) for OpenStack MySQL + rabbitMQ services
Posted by: Piotr Siwczak
The last article by Oleg Gelbuch gave an overview of various aspects of uninterrupted operation in OpenStack. All components of OpenStack are designed to be uninterrupted, but the platform also uses external resources, such as a database and messaging system. And it is the user's concern to deploy these external resources for uptime.
It is very important to remember that all stateful resources in OpenStack use a messaging system and a database, and all other components do not store state information (with the exception of Glance). The database and messaging system are key to the OpenStack platform. While the queue management system allows several components to exchange messages, the database stores the cluster status. Both of these systems participate in each user request, both when displaying a list of virtual objects and when creating a new virtual machine.
RabbitMQ is used by default for messaging, and MySQL is the default database. Reliable solutions are well known in the industry and, in our experience, are sufficient to scale even in large installations. In theory, any database that supports SQLAlchemy will do, but most users use the default database. For messaging, it’s hard to find an alternative to RabbitMQ, although some use the ZeroMQ driver for OpenStack.
')
Let's first take a look at how the database and messaging system work together in OpenStack. First, I will describe the data stream at the most popular user request: creating an instance of a virtual machine.
The user sends his request to OpenStack, interacting with the nova-api component. Nova-api processes the instance creation request by calling the create_instance function from the nova-compute API. The function does the following:
- Checks the data entered by users: (for example, verifies that the requested VM image, variety, network exists.) If not specified, it tries to get the default values (for example, variety, default network).
- Checks the request for compliance with user restrictions.
- Thereafter, the test described above gave positive results, creates an entry about the instance in the database (create_db_entry_for_new_instance function).
- Calls the _schedule_run_instance function, which sends the user request to the nova-scheduler component via the message queue using the AMQP protocol. The request body contains the instance parameters:
request_spec = {
'image': jsonutils.to_primitive (image),
'instance_properties': base_options,
'instance_type': instance_type
'num_instances': num_instances,
'block_device_mapping': block_device_mapping,
'security_group': security_group,
}
The _schedule_run_instance function is terminated by sending an AMQP message with a call to the scheduler_rpcapi.run_instance function.
Now the scheduler enters the job. It receives a message with a node specification and, based on it and its scheduling policies, tries to find a suitable node to create an instance. This is an excerpt from the nova-scheduler log files during this operation (here uses FilterScheduler ):
Host filter passes for ubuntu from (pid = 15493) passes_filters /opt/stack/nova/nova/scheduler/host_manager.py:163
Filtered [host 'ubuntu': free_ram_mb: 1501 free_disk_mb: 5120] from (pid = 15493) _schedule /opt/stack/nova/nova/scheduler/filter_scheduler.py:199
He chooses the node with the lowest cost, using the weighing function (there is only one node, so in this case the weighing operation does not change anything):
Weighted WeightedHost host: ubuntu from (pid = 15493) _schedule /opt/stack/nova/nova/scheduler/filter_scheduler.py:209
After the compute node on which the instance is to be launched is defined, the scheduler calls the cast_to_compute_host function, which:
- Updates the node record for the instance in the nova database (node = compute node on which the instance will be created) and
- Sends a message using the AMQP protocol to the nova-compute service on this particular node to launch an instance. The message includes the instance UUID to run and the following action to be taken, that is: run_instance.
In response, the nova-compute service on the selected node calls the _run_instance method, which receives the instance parameters from the database (based on the UUID that was transferred) and starts the instance with the appropriate parameters. While setting up an instance, nova-compute also communicates via the AMQP protocol with the nova-network service to set up network interaction (including assigning an IP address and setting up a DHCP server). The state of the virtual machine at different stages of the creation process is recorded in the nova database using the _instance_update function.
As you can see, AMQP is used for communication between the various components of OpenStack. In addition, the database is updated several times to display the initial state of the virtual machine (VM). Thus, if we lose any of the following components, we will significantly disrupt the core functions of the OpenStack cluster:
- The loss of RabbitMQ will make it impossible to perform any user tasks. Also, some resources (such as the deployable VM, for example) will remain in a disassembled state.
- The loss of the database will lead to even more destructive consequences: all instances will work, but they will not be able to determine to whom they belong, to which node they hit, or what their IP address is. Taking into account how many VMs can be running in your cloud (maybe several thousand), this situation cannot be rectified.
You can prevent a database crash by carefully backing up and replicating data. In the case of MySQL, there are many solutions with detailed descriptions, including MySQL Cluster (the “official” MySQL clustering suite), MMM (multiple replica management tool with multiple replicas), and XtraDB from Percona.
The MySQL cluster works on the basis of a special storage engine called NDB (Network DataBase). The engine is a cluster of servers called “data nodes”, which is controlled by a “management node”. Data is segmented and replicated between data nodes and there are at least two replicas for each data unit. All replicas are necessarily located on different data nodes. A MySQL server farm running NDB storage in the server part is running on top of the data nodes. Each of the processes mysqld has the ability to read / write and allows you to distribute the load to ensure efficiency and continuity.
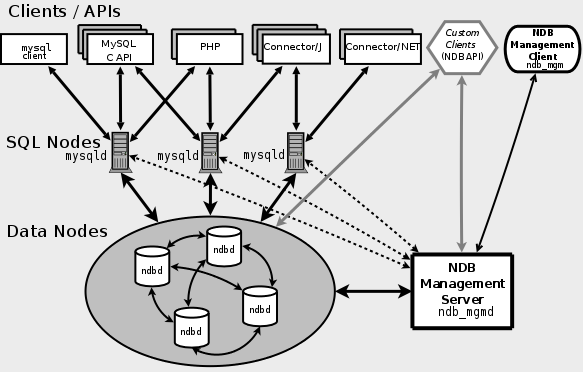
The MySQL cluster guarantees synchronous replication , which is a clear disadvantage of the traditional replication mechanism. It has some limitations compared to other storage engines (a good overview is located at this link ).
This solution is an industry recognized Percona company. XtraDB Cluster consists of a set of nodes, each of which runs an instance of Percona XtraDB with a set of add-ons to support replication. Add-ons contain a set of procedures for exchanging data with the InnoDB storage engine and allow it to create at the lower level a replication system that conforms to the WSREP specification.
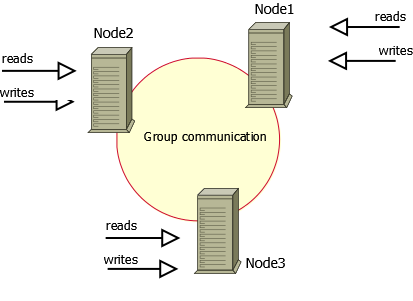
On each cluster node, a version of mysqld is running with additions from Percona. Also on each of them is a complete copy of the data. Each node allows you to perform read and write operations. Like MySQL Cluster, XtraDB Cluster has some limitations described here .
The MultiMaster replication Manager replication management tool uses the traditional “master-slave” mechanism for replication. It works on the basis of a set of MySQL servers with at least two main replicas with a set of subordinate replicas, as well as a dedicated monitoring node. On top of this node set is a pool of IP addresses that MMM can dynamically move from node to node, depending on their availability. We have two types of these addresses:
- “Recording”: the client can write to the database by connecting to this IP address (in the whole cluster there can be only one address of the recording node).
- “Reading”: the client can read in the database by connecting to this IP address (there may be several reading nodes for reading scaling).
The monitoring node checks the availability of MySQL servers and includes the transfer of “recording” and “reading” IP addresses in case of server failure. The set of checks is relatively simple: it includes checking for network availability, checking for the presence of mysqld on a host, the presence of a replication branch, and the size of the replication log. Reading load distribution between “reading” IP addresses is performed by the user (it can be done using HAProxy or DNS round robin, etc.).
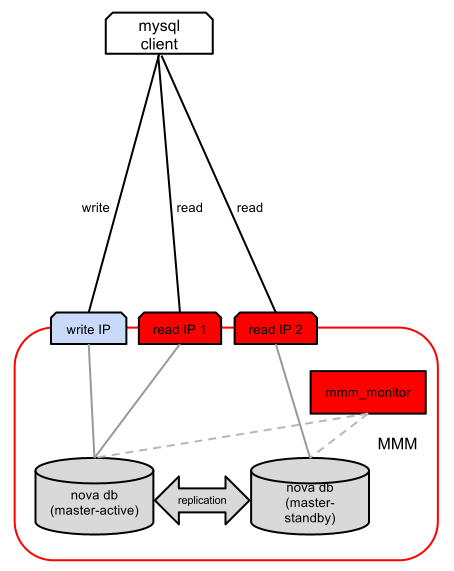
MMM uses traditional asynchronous replication. This means that there is always a chance that at the time of the failure of the master replicas are lagging behind the master. One branch of replication is being used now, which is often not enough in a multi-core world with a large volume of transactions, especially when many write requests are executed. These considerations are eliminated in a future version of MySQL, which implements a set of functions for optimizing the binary log (binlog) and uninterrupted HA.
As for the OpenStack training materials regarding MySQL continuity, Alessandro Tagliapietra presents an interesting approach (the article only describes OpenStack) to ensure MySQL accessibility through master slave replication, as well as Pacemaker with Percona's Pacemaker agent .
By nature, RabbitMQ data changes very often. Since the speed and amount of data is important for messaging, all messages are stored in RAM, unless you have defined queues as “stable” - in this case, RabbitMQ writes messages to the disk. This feature is supported by OpenStack using the rabbit_durable_queues = True parameter in nova.conf. Although messages are written to disk and thus do not disappear if the RabbitMQ server crashes or restarts, this is not a real solution to ensure continuity, since:
- RabbitMQ does not perform fsync on the disk when receiving each message, so if the server crashes, there may be messages in the file system buffer that are not written to the disk. After a reboot, they will be lost.
- RabbitMQ is still located on only one node.
You can cluster RabbitMQ and cluster RabbitMQ is called “intermediary”. Clustering itself is more designed to scale than to ensure continuity. However, it has a big disadvantage — all virtual nodes, switching elements, users, are replicated, with the exception of the message queues themselves. In order to correct this deficiency, the queue mirroring function was implemented. The creation of a middleman, as well as the mirroring of the queue, must be combined for complete fault tolerance of RabbitMQ.
There is also a solution based on Pacemaker , but it is considered obsolete compared to the one described above.
It should be noted that none of the above clustering modes is supported directly in OpenStack; nevertheless, Mirantis has a rather rich experience in this area (more on this below).
Mirantis installed highly available MySQL with MMM (Multiple Master Replication Management Tool) for several clients. Although some developers have expressed concern about errors in MMM in online discussions, in our experience we have not encountered significant glitches of this tool. We consider it a sufficient and acceptable solution. However, we know that there are people who have a lot of problems with this solution and therefore we are now considering architectures based on the WSREP synchronous replication approach, since by definition it provides greater data integrity and controllability, as well as simpler customization (for example, , Galera Cluster , XtraDB Cluster ).
Below is an illustration of the setup we performed for a large-scale installation of OpenStack:
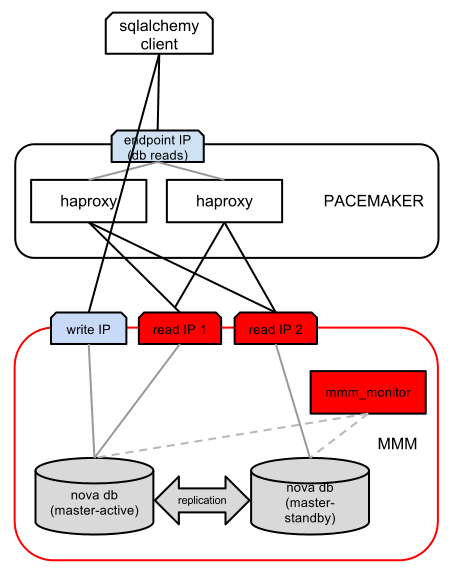
MMM uninterrupted operation: master-master replication with one master replica in standby mode (only the active replica supports writing, and both wizards support reading, so we have one “write” IP address and two “readers”). The mmm_monitor module checks the availability of both wizards and shuffles the “read” and “write” IP addresses accordingly.
On top of MMM, HAproxy provides performance improvements by distributing the load when reading between both IP addresses. Of course, for greater scalability, you can add several subordinate nodes with additional IP addresses to read. While HAproxy distributes the traffic well, it does not provide uninterrupted operation by itself, so another instance of HAproxy is created and a resource is created in Pacemaker for both instances. Therefore, if one of the HAproxy proxy servers fails, Pacemaker transfers the IP address from the failed “recording server” to the other.
Since we only have one “recording” IP address, we do not need to distribute the load and write requests go directly to it.
With this approach, we can ensure the scalability of write requests by adding more subordinate nodes to the database farm, as well as load balancing using HAproxy. In addition, we support high availability using Pacemaker (for detecting HAproxy failures) plus MMM (for detecting failures of the database node).
If we compare RabbitMQ HA and OpenStack, Mirantis proposed an add-on for nova with support for mirroring queues. From the user's point of view, the add-on adds two new options to nova.conf:
-rabbit_ha_queues = True / False - to enable queue mirroring.
-rabbit_hosts = ["rabbit_host1", "rabbit_host2"] - so that users can define a clustered pair of RabbitMQ HA nodes.
Technically, the following happens: each call to queue.declare inside nova adds x-ha-policy: all and connects the roundrobin cluster logic. The very configuration of the RabbitMQ cluster is done by the user.
I have presented several options for providing high availability for the database and messaging system. Below is a list of links for additional research on the subject.
http://wiki.openstack.org/HAforNovaDB/: Continuity for the OpenStack database
http://wiki.openstack.org/RabbitmqHA: Uninterrupted Queuing System
http://www.hastexo.com/blogs/florian/2012/03/21/high-availability-openstack: An article on various aspects of business continuity in OpenStack.
http://docs.openstack.org/developer/nova/devref/rpc.html: how messaging works in OpenStack
http://www.laurentluce.com/posts/openstack-nova-internals-of-instance-launching/: an interesting description of the sequence of steps when starting an instance
https://lists.launchpad.net/openstack/pdfGiNwMEtUBJ.pdf: nova uninterrupted presentation
http://openlife.cc/blogs/2011/may/different-ways-doing-ha-mysql/: the title explains everything
http://www.linuxjournal.com/article/10718: MySQL Replication article
http://www.mysqlperformanceblog.com/2010/10/20/mysql-limitations-part-1-single-threaded-replication/: Replication Performance Issues
https://github.com/jayjanssen/Percona-Pacemaker-Resource-Agents/blob/master/doc/PRM-setup-guide.rst: MySQL Replication Article: Percona Replication Manager Article
http://www.rabbitmq.com/clustering.html: RabbitMQ clustering
http://www.rabbitmq.com/ha.html: RabbitMQ Mirrored Queries
Original article in English
The last article by Oleg Gelbuch gave an overview of various aspects of uninterrupted operation in OpenStack. All components of OpenStack are designed to be uninterrupted, but the platform also uses external resources, such as a database and messaging system. And it is the user's concern to deploy these external resources for uptime.
It is very important to remember that all stateful resources in OpenStack use a messaging system and a database, and all other components do not store state information (with the exception of Glance). The database and messaging system are key to the OpenStack platform. While the queue management system allows several components to exchange messages, the database stores the cluster status. Both of these systems participate in each user request, both when displaying a list of virtual objects and when creating a new virtual machine.
RabbitMQ is used by default for messaging, and MySQL is the default database. Reliable solutions are well known in the industry and, in our experience, are sufficient to scale even in large installations. In theory, any database that supports SQLAlchemy will do, but most users use the default database. For messaging, it’s hard to find an alternative to RabbitMQ, although some use the ZeroMQ driver for OpenStack.
')
How OpenStack Works Messages and Database
Let's first take a look at how the database and messaging system work together in OpenStack. First, I will describe the data stream at the most popular user request: creating an instance of a virtual machine.
The user sends his request to OpenStack, interacting with the nova-api component. Nova-api processes the instance creation request by calling the create_instance function from the nova-compute API. The function does the following:
- Checks the data entered by users: (for example, verifies that the requested VM image, variety, network exists.) If not specified, it tries to get the default values (for example, variety, default network).
- Checks the request for compliance with user restrictions.
- Thereafter, the test described above gave positive results, creates an entry about the instance in the database (create_db_entry_for_new_instance function).
- Calls the _schedule_run_instance function, which sends the user request to the nova-scheduler component via the message queue using the AMQP protocol. The request body contains the instance parameters:
request_spec = {
'image': jsonutils.to_primitive (image),
'instance_properties': base_options,
'instance_type': instance_type
'num_instances': num_instances,
'block_device_mapping': block_device_mapping,
'security_group': security_group,
}
The _schedule_run_instance function is terminated by sending an AMQP message with a call to the scheduler_rpcapi.run_instance function.
Now the scheduler enters the job. It receives a message with a node specification and, based on it and its scheduling policies, tries to find a suitable node to create an instance. This is an excerpt from the nova-scheduler log files during this operation (here uses FilterScheduler ):
Host filter passes for ubuntu from (pid = 15493) passes_filters /opt/stack/nova/nova/scheduler/host_manager.py:163
Filtered [host 'ubuntu': free_ram_mb: 1501 free_disk_mb: 5120] from (pid = 15493) _schedule /opt/stack/nova/nova/scheduler/filter_scheduler.py:199
He chooses the node with the lowest cost, using the weighing function (there is only one node, so in this case the weighing operation does not change anything):
Weighted WeightedHost host: ubuntu from (pid = 15493) _schedule /opt/stack/nova/nova/scheduler/filter_scheduler.py:209
After the compute node on which the instance is to be launched is defined, the scheduler calls the cast_to_compute_host function, which:
- Updates the node record for the instance in the nova database (node = compute node on which the instance will be created) and
- Sends a message using the AMQP protocol to the nova-compute service on this particular node to launch an instance. The message includes the instance UUID to run and the following action to be taken, that is: run_instance.
In response, the nova-compute service on the selected node calls the _run_instance method, which receives the instance parameters from the database (based on the UUID that was transferred) and starts the instance with the appropriate parameters. While setting up an instance, nova-compute also communicates via the AMQP protocol with the nova-network service to set up network interaction (including assigning an IP address and setting up a DHCP server). The state of the virtual machine at different stages of the creation process is recorded in the nova database using the _instance_update function.
As you can see, AMQP is used for communication between the various components of OpenStack. In addition, the database is updated several times to display the initial state of the virtual machine (VM). Thus, if we lose any of the following components, we will significantly disrupt the core functions of the OpenStack cluster:
- The loss of RabbitMQ will make it impossible to perform any user tasks. Also, some resources (such as the deployable VM, for example) will remain in a disassembled state.
- The loss of the database will lead to even more destructive consequences: all instances will work, but they will not be able to determine to whom they belong, to which node they hit, or what their IP address is. Taking into account how many VMs can be running in your cloud (maybe several thousand), this situation cannot be rectified.
HA database solutions
You can prevent a database crash by carefully backing up and replicating data. In the case of MySQL, there are many solutions with detailed descriptions, including MySQL Cluster (the “official” MySQL clustering suite), MMM (multiple replica management tool with multiple replicas), and XtraDB from Percona.
MySQL cluster
The MySQL cluster works on the basis of a special storage engine called NDB (Network DataBase). The engine is a cluster of servers called “data nodes”, which is controlled by a “management node”. Data is segmented and replicated between data nodes and there are at least two replicas for each data unit. All replicas are necessarily located on different data nodes. A MySQL server farm running NDB storage in the server part is running on top of the data nodes. Each of the processes mysqld has the ability to read / write and allows you to distribute the load to ensure efficiency and continuity.
The MySQL cluster guarantees synchronous replication , which is a clear disadvantage of the traditional replication mechanism. It has some limitations compared to other storage engines (a good overview is located at this link ).
XtraDB Cluster
This solution is an industry recognized Percona company. XtraDB Cluster consists of a set of nodes, each of which runs an instance of Percona XtraDB with a set of add-ons to support replication. Add-ons contain a set of procedures for exchanging data with the InnoDB storage engine and allow it to create at the lower level a replication system that conforms to the WSREP specification.
On each cluster node, a version of mysqld is running with additions from Percona. Also on each of them is a complete copy of the data. Each node allows you to perform read and write operations. Like MySQL Cluster, XtraDB Cluster has some limitations described here .
MMM
The MultiMaster replication Manager replication management tool uses the traditional “master-slave” mechanism for replication. It works on the basis of a set of MySQL servers with at least two main replicas with a set of subordinate replicas, as well as a dedicated monitoring node. On top of this node set is a pool of IP addresses that MMM can dynamically move from node to node, depending on their availability. We have two types of these addresses:
- “Recording”: the client can write to the database by connecting to this IP address (in the whole cluster there can be only one address of the recording node).
- “Reading”: the client can read in the database by connecting to this IP address (there may be several reading nodes for reading scaling).
The monitoring node checks the availability of MySQL servers and includes the transfer of “recording” and “reading” IP addresses in case of server failure. The set of checks is relatively simple: it includes checking for network availability, checking for the presence of mysqld on a host, the presence of a replication branch, and the size of the replication log. Reading load distribution between “reading” IP addresses is performed by the user (it can be done using HAProxy or DNS round robin, etc.).
MMM uses traditional asynchronous replication. This means that there is always a chance that at the time of the failure of the master replicas are lagging behind the master. One branch of replication is being used now, which is often not enough in a multi-core world with a large volume of transactions, especially when many write requests are executed. These considerations are eliminated in a future version of MySQL, which implements a set of functions for optimizing the binary log (binlog) and uninterrupted HA.
As for the OpenStack training materials regarding MySQL continuity, Alessandro Tagliapietra presents an interesting approach (the article only describes OpenStack) to ensure MySQL accessibility through master slave replication, as well as Pacemaker with Percona's Pacemaker agent .
Ensuring Continuity (HA) for Message Queuing
By nature, RabbitMQ data changes very often. Since the speed and amount of data is important for messaging, all messages are stored in RAM, unless you have defined queues as “stable” - in this case, RabbitMQ writes messages to the disk. This feature is supported by OpenStack using the rabbit_durable_queues = True parameter in nova.conf. Although messages are written to disk and thus do not disappear if the RabbitMQ server crashes or restarts, this is not a real solution to ensure continuity, since:
- RabbitMQ does not perform fsync on the disk when receiving each message, so if the server crashes, there may be messages in the file system buffer that are not written to the disk. After a reboot, they will be lost.
- RabbitMQ is still located on only one node.
You can cluster RabbitMQ and cluster RabbitMQ is called “intermediary”. Clustering itself is more designed to scale than to ensure continuity. However, it has a big disadvantage — all virtual nodes, switching elements, users, are replicated, with the exception of the message queues themselves. In order to correct this deficiency, the queue mirroring function was implemented. The creation of a middleman, as well as the mirroring of the queue, must be combined for complete fault tolerance of RabbitMQ.
There is also a solution based on Pacemaker , but it is considered obsolete compared to the one described above.
It should be noted that none of the above clustering modes is supported directly in OpenStack; nevertheless, Mirantis has a rather rich experience in this area (more on this below).
Deployment Experience in Mirantis
Mirantis installed highly available MySQL with MMM (Multiple Master Replication Management Tool) for several clients. Although some developers have expressed concern about errors in MMM in online discussions, in our experience we have not encountered significant glitches of this tool. We consider it a sufficient and acceptable solution. However, we know that there are people who have a lot of problems with this solution and therefore we are now considering architectures based on the WSREP synchronous replication approach, since by definition it provides greater data integrity and controllability, as well as simpler customization (for example, , Galera Cluster , XtraDB Cluster ).
Below is an illustration of the setup we performed for a large-scale installation of OpenStack:
MMM uninterrupted operation: master-master replication with one master replica in standby mode (only the active replica supports writing, and both wizards support reading, so we have one “write” IP address and two “readers”). The mmm_monitor module checks the availability of both wizards and shuffles the “read” and “write” IP addresses accordingly.
On top of MMM, HAproxy provides performance improvements by distributing the load when reading between both IP addresses. Of course, for greater scalability, you can add several subordinate nodes with additional IP addresses to read. While HAproxy distributes the traffic well, it does not provide uninterrupted operation by itself, so another instance of HAproxy is created and a resource is created in Pacemaker for both instances. Therefore, if one of the HAproxy proxy servers fails, Pacemaker transfers the IP address from the failed “recording server” to the other.
Since we only have one “recording” IP address, we do not need to distribute the load and write requests go directly to it.
With this approach, we can ensure the scalability of write requests by adding more subordinate nodes to the database farm, as well as load balancing using HAproxy. In addition, we support high availability using Pacemaker (for detecting HAproxy failures) plus MMM (for detecting failures of the database node).
If we compare RabbitMQ HA and OpenStack, Mirantis proposed an add-on for nova with support for mirroring queues. From the user's point of view, the add-on adds two new options to nova.conf:
-rabbit_ha_queues = True / False - to enable queue mirroring.
-rabbit_hosts = ["rabbit_host1", "rabbit_host2"] - so that users can define a clustered pair of RabbitMQ HA nodes.
Technically, the following happens: each call to queue.declare inside nova adds x-ha-policy: all and connects the roundrobin cluster logic. The very configuration of the RabbitMQ cluster is done by the user.
additional information
I have presented several options for providing high availability for the database and messaging system. Below is a list of links for additional research on the subject.
http://wiki.openstack.org/HAforNovaDB/: Continuity for the OpenStack database
http://wiki.openstack.org/RabbitmqHA: Uninterrupted Queuing System
http://www.hastexo.com/blogs/florian/2012/03/21/high-availability-openstack: An article on various aspects of business continuity in OpenStack.
http://docs.openstack.org/developer/nova/devref/rpc.html: how messaging works in OpenStack
http://www.laurentluce.com/posts/openstack-nova-internals-of-instance-launching/: an interesting description of the sequence of steps when starting an instance
https://lists.launchpad.net/openstack/pdfGiNwMEtUBJ.pdf: nova uninterrupted presentation
http://openlife.cc/blogs/2011/may/different-ways-doing-ha-mysql/: the title explains everything
http://www.linuxjournal.com/article/10718: MySQL Replication article
http://www.mysqlperformanceblog.com/2010/10/20/mysql-limitations-part-1-single-threaded-replication/: Replication Performance Issues
https://github.com/jayjanssen/Percona-Pacemaker-Resource-Agents/blob/master/doc/PRM-setup-guide.rst: MySQL Replication Article: Percona Replication Manager Article
http://www.rabbitmq.com/clustering.html: RabbitMQ clustering
http://www.rabbitmq.com/ha.html: RabbitMQ Mirrored Queries
Original article in English
Source: https://habr.com/ru/post/177357/
All Articles