Recommender systems: You can (not) advise
More than six months ago, in search of what to see, I was flipping through the top works. This occupation was repeated many times and had time to get bored - I constantly had to miss what I didn’t want to watch. Imhonetami did not use before, and did not trust them because of the specificity of the desired works. On the site where I made searches, it was possible to create my own list of viewed works and rate it, other users' ratings were also available. Then a brilliant idea came to my mind, as it turned out later to be trivial, using the ratings of other users to make recommendations. This activity is called collaborative filtering, and the program implementing it is called the Recommender System (PC). Looking back, I understand that I made a lot of mistakes due to the lack of information and its inaccessibility in this topic, and most importantly, I greatly overestimated the RS. In this post, I will review the main types and algorithms of the PC, and also try to transfer some of my knowledge and experience.
A recommendation system is a program that provides recommendations based on the data about the user (User) and the item (Item).
Such a system includes the entire process - from receiving information to its presentation to the user.
Every stage is important. From the information that you will collect depends on what algorithms you can apply. Good algorithms give good, useful recommendations. Criteria for evaluating the result allow you to choose the most appropriate algorithms. And this doesn’t work if you don’t correctly present and explain the advice to the user. I will talk about the algorithms, but do not forget about the rest of the system.
Initially, the task seems very simple, but with such an approach it is difficult to create a good system. It is necessary to carefully approach the construction of the system. Even the best algorithms do not give very good results, and if you still use clustering algorithms or otherwise worsen the accuracy, then nothing will come out at all. If you have no experience in this field - get ready for a long study, well, or take the SVD)
Test data
On the site where I took the data, a ten-point grading system, about a million users and 30k items.
You can certainly start like me, just take the algorithm and do it, but soon you will realize that this is a bad idea. After the implementation of several types of systems, questions arise - what type to choose, what have we achieved and can we do better? To answer these questions, it is necessary to evaluate the results according to some criteria.
It is necessary to create equal conditions for all algorithms - to fix some data with the help of which the algorithms will make their predictions and find some reference result with which you can compare the obtained predictions.
')
Remember that you have to test a lot of algorithms with various options and it is desirable to speed up this process as much as possible. When we have already chosen the algorithm, we can use all the data, but before that, to speed up the experiments, we need to take only a part of them. This is also a science, called sampling.
In my case, everything was simple - I already had a lot of user ratings and as the results showed, using 100%, 25% and 10% of the data, the results practically did not change, so I conducted all my experiments by 10%. Out of 200k users (30kk ratings) with more than five ratings, I randomly selected 30k users (3kk ratings). I divided each user’s scores into two sets according to the following algorithm: if the scores are more than ten, I transferred the first six marks (made earlier in time) to the training sample, and the last six scores to the test sample (reference), if less than ten, then to the test one. the sample fell less than estimates.
Performance
To conduct a study, it is sometimes necessary to restart the algorithm hundreds of times changing parameters, and what happens if one calculation takes several hours? That's right - a very strong character in Terraria, but this was not my main goal.
Initially, all algorithms were written in Python, since I know this language best of all, but then I had to rewrite a lot in Java, which worked up to twenty times faster and consumed significantly less OP (mainly due to primitive types and arrays). Java was chosen only because it is in second place for me on the basis of knowledge. Perhaps my solution to the problem is not the best (in numpy and scipy, much is implemented natively, there are many specialized frameworks and languages), but it was more interesting for me to do everything myself.
There were also problems with data storage - serialization was not suitable, because sometimes it was necessary to transfer data from python to Java and vice versa, SQL was not convenient, and then I met MongoDB. She fit me perfectly. Again, it is likely that this is not the best solution and you may need to use some Hadoop.
The calculation of Java SVD on the full amount of data takes approximately ten minutes and consumes 2 GB of memory. But for SVD ++ you need to wait about an hour.
MS assessment criteria
Before considering the types of MS, you need to talk about the criteria for evaluating the result.
There are many different criteria by which a recommendation system can be evaluated - such as accuracy, novelty, ability to surprise, resistance to attacks, dependence on a cold start, persuasiveness, and so on, but one of the most important is accuracy. It shows how much our predictions are close to the standard result. To measure accuracy, there are many methods, I recommend to approach the choice carefully, since much depends on it. I took one of the most popular methods - the calculation of the root-mean-square error (RMSE). After the algorithm makes predictions based on the test data, the error can be calculated using the following formula:
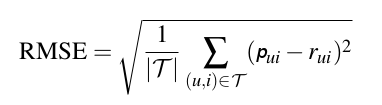
u - user
i - subject
r - score
p - predicted estimate
T is the total number of test scores
less is better
In the future, I will specify the accuracy for the algorithms in rmse.
As practice has shown, less than rmse does not always mean a better algorithm. I managed to achieve the best rmse results with the timeSVD ++ algorithm - 1.29, for the knowledge-based recommender system 1.41 (where users themselves specified dependencies). The second system subjectively gave me some very good advice that the first system did not find.
More details about the criteria can be found in the Recommendation System Handbook, which I indicated in the literature section.
The starting point of my research I took the result which is obtained if the predicted estimate is taken as the average rating of each item - then rmse will be equal to 1.53. This is done because there is practically nothing to do to obtain this assessment, and very often we already have it. Let's see how much we can beat this result.
PC types
There are four main types of recommender systems:
- Content-based
- Collaborative (Collaboration)
- Knowledge Based (Knowlege base)
- Hybrid
Content based PCs
The main steps in this system are: analyze the content of objects and make a set of its criteria (genres, tags, words), find out what criteria the user likes, compare this data and get recommendations. Criteria unite users and objects in a single coordinate system, and here everything is already simple - if the user and the object point are nearby, then the user will probably like the object.
One of the simplest types of this system is the genre system, here our criteria are genres.
My genre PC showed a result of 1.48, which is slightly better than if you just take the average rating. But not everything is so bad - the genre system, combined with an average rating of the hybrid system, showed a result of 1.40. This system is very easy to do.
Another type of this PC uses words describing the subject. On the site where I took the information, there is a section with descriptions of the subject. I took this data and drove through the tf-idf algorithm (which allows us to determine the similarity of the two texts) and the result was 1.46.
As you can see, this type of PC when using basic algorithms does not give much accuracy, but it does have other advantages: high performance, warmer “cold start”, to get the recommendation, only data about the user and objects are needed.
Very often, these systems are used before collaborative filtering, when user ratings are not yet sufficient.
I also recommend reading about this type of PC in the Recommendation System Handbook or on the web .
Collaborative PC
These are systems in which recommendations to the user are calculated based on the ratings of other users. There are many algorithms here, but the most popular ones are User / User (we are looking for neighbors by estimates), Item / Item (we are looking for similarity of objects according to users' estimates) and SVD (self-learning algorithm). All of them are described on habre - User / User & Item / Item , SVD and in Recommendation System Handbook. If you decide to create a collaborative PC, I recommend to look at the SVD algorithm, it has the best accuracy, high performance and low memory consumption.
When choosing User / User or Item / Item, it is necessary to take into account who is more - users or items. If there are more users, then Item / Item is preferable, if on the contrary, User / User.
The essence of these algorithms is finding the nearest neighbors. The proximity of two users or items is determined by similarity metrics (similarity metrics)
The most commonly used cosine metric or Pearson correlation. On my data, both methods gave similar results.
Before I met them, I came up with my own similarity metric:
sim = cross_count / euclid
sim - result
cross_count - the number of intersections
euclid - Euclidean distance
On my test data, it showed itself better than a pierson and cosine. This clearly shows the importance of the number of intersections. I warn you! Before using, be sure to test using other metrics, since it is not known what you can do for skyline. In the future, I will indicate the results without taking into account this metric.
For User / User, the best result that I was able to achieve was when using the correlation of the pierson and was equal to 1.49. This is even worse than the content system. Mainly due to the fact that the User / User algorithm badly takes into account the number of intersections of the user and gives recommendations based on just a few estimates, this can be overcome by imposing restrictions on the minimum number of intersections.
For Item / Item, the best result was also with Pearson - 1.35, which is significantly better than User / User. The reason is that there are significantly fewer items and when calculating the similarity of two items, they have many intersections of assessments.
The first time when I implemented SVD I was delighted with his work and watched with admiration as the error in teaching the model was reduced. I recommend everyone to implement it for review.
I tried 3 types of SVD: SVD, SVD ++ and timeSVD ++. I had the following results:
SVD - 1.30
SVD ++ - 1.29
timeSVD ++ - 1.29
As you can see, these algorithms allow to achieve the greatest accuracy. Of these three, I recommend using a simple SVD, as it is the most productive. Other algorithms take much longer to execute, and accuracy is not significantly increased.
Knowledge based PC
These are mainly systems in which knowledge obtained in some way is used to receive recommendations, most often this knowledge is added manually.
On the site where I took the information, users could indicate other similar items to the subject. Based on this data, I made recommendations as in Item / Item. The result was 1.41. As I indicated earlier, many of the recommendations of this system that I liked, could not find collaborative algorithms.
More information about these PCs is written in the Recommendation System Handbook.
Hybrid PCs
These systems combine several of the above algorithms into one. There are several types of them, but I didn’t go deep and I used a simple formula with weights:
res = w1 * a + w2 * b
w1 - weight for algorithm a
w2 - weight for algorithm b
Here the weights are always constant, but it is desirable that they be in the form w = f (x), that is, dependent on some parameters.
Here is a small example for the average rating and the genre algorithm:
w1 w2 - rmse
0.2 0.8 - 1.4330
0.3 0.7 - 1.4173
0.4 0.6 - 1.4092
0.45 0.55 - 1.4083
0.5 0.5 - 1.4095
0.6 0.4 - 1.4180
0.7 0.3 - 1.4347
As you can see, two algorithms with an accuracy of 1.5 made it possible to obtain an accuracy of 1.40
I managed the best result with the hybrid system w1 * (Item / Item) + w2 * (SVD), where w1 = 0.5 and w2 = 0.5. RMSE decreased by 0.01. This result does not contradict the fact that the winners of the competition NetFlix - BellKor received. To win, they used a hybrid of 27 algorithms. This allowed them to achieve an accuracy of 0.86, and the use of one SVD - 0.88 (the error is two times less than mine because of the fact that they have a 5-point system, I have a 10-point system). In their case, it was necessary, in my opinion it is completely unjustified, since productivity drops, complexity increases, and the result improvement is not significant.
You can use the best hybrid, which does not greatly complicate the system, but it will slightly increase the accuracy.
Pro hybrid systems are also described in detail in the Recommender Systems Handbook.
Literature and links
There are three books on MS:
Programming Collective Intelligence
Already obsolete since it was written before the Netflix Prize. There are examples on Python.
Recommender Systems An Introduction
The average level of complexity, more about the PC as a whole. Some things are written in more detail than in the next book. There are descriptions of algorithms. There are no code examples.
Recommender Systems Handbook
The best book about the PC, everything is here. Algorithms are well described, but without examples of implementation - they will have to be sought on the side.
Information on the Internet:
On Habré there is a blog Surfingbird , they often write about the PC
I strongly recommend BellKor collaborative filtering materials:
BellKor - some of this information is published in the Recommender Systems Handbook
there is also an opensource library for collaborative filtering, C #:
MyMediaLite Recommender System Library
Conclusion

After these experiments, I implemented a system on the basis of SVD, but the recommendations received with its help have a lot of complaints and often miss.
After reading a little about MS, at first I thought “how did we live without it before?”, But later it turned out that even the most advanced methods give poor results and there is no possibility to completely trust them with the choice. Having conducted a broad study, I was not able to create a system that would be used often, and most importantly - that would be trusted, so I will continue my research.
This area is not yet twenty years old, it is actively developing and here is full of tasks where you can express yourself.
This is a very interesting problem, after which I became interested in Data Mining and enrolled in several courses on machine learning, let's see what happens.
Source: https://habr.com/ru/post/176549/
All Articles