Processing and classification of requests. Part Two: Navigation Queries
What do we most want when we open an Internet search engine? We want to leave it as quickly as possible, paradoxically. We formulate our desire, press the button and rather go to where it should be fulfilled (we hope).

There are only two main ways to express desires: either describe what you need to get (or do), or indicate where you need to "teleport". In the first case, the system tries to understand the request by correctly selecting the best of the network's responses, weighing hundreds of their properties on the decision trees. In the second, the correct answer is usually only one, and we expect that the search engine knows it.
')
Requests of the second type, answering questions where or where - navigation queries. I offer you a short story about how we work with them.
Generally speaking, the border between what and where is quite vague. Consider two search queries: "cyclists forum" and "cycle forum ru". Currently, the most relevant response to both of these requests is the same velo-forum.ru website. The difference is that in the first case the answer is not the only one and there is a competition between him and his analogues, in the second one the site is obliged not only to be present in the list of results, but also to head it, no matter how bad or good it is. compared with other cycle forums. The second query is navigational, and the first is not.
There are also requests of a mixed type, for example, “wiki onomatopei”. We will put them aside for the time being, but we will return to them.
So, we must know in advance the answers to navigation requests. Technically, this task is formulated as follows: compare each navigation request with its corresponding Internet address (hereinafter referred to as the target ): the site, the site section, the site page. And before that, determine whether the query is navigational.
Why do you need it?
First of all, various studies show that navigation is subjectively perceived as the simplest type of search (which is not surprising: it’s easier to know about something than to understand it ). Because of this, users are particularly picky in assessing the quality of the search engine's navigation responses, and it is they who have the strongest influence on users when making decisions about the search engine's responsibility as a whole.
At the same time there are a lot of navigation queries. So much that just leaving them unattended is extremely frivolous. After all, the most important thing in the processing of any data is accounting and control. That is, statistics and monitoring. In this case, statistics on query properties and monitoring the quality of responses.
If you sort all the search queries in descending order of their number, and then look at the resulting list “in perspective”, you will see something like the following:

It can be seen that the entire top was captured by navigation queries, weakly diluted by the most important information needs of mankind (they are marked in red). Therefore, no longer postponing
Go!
We started by simply going along the list, throwing out red blotches, and manually assigning each of its remaining requests to its target. It turned out that only "VKontakte" with "classmates" cover 5% of the total flow of requests, while the coverage of the list of 120 top navigation queries was almost 15%. Not bad for such meager intellectual costs.
Further, however, the “density” of navigation is rapidly decreasing, and therefore we had to look for ways to automatically filter the requests we needed. That is, roughly speaking, find out how “VKontakte” is different from “porn”.
Hall assistance
Users are not inclined to click on irrelevant answers. Accordingly, for navigation queries, it makes sense to expect that they all select the only correct answer. The working hypothesis was that the reverse is also true - if the majority of users who submitted a request click the same result, then this request is navigational, and the result is its target.
The test showed that the hypothesis as a whole is correct - only rare non-competitive requests that have a very relevant response (such as “nokia themes” or “download icq”) generate a similar behavioral pattern. However, almost all the false positives of their pseudo argents turned out to be pages within sites, so we just threw (temporarily) such requests from consideration.
We went through several ways to measure the unanimity of users (including classic clickrank), and stopped at the following simple and convenient metric.
Let C i be the number of clicks in the result R i , and ∑C i be the total number of clicks on request.
Then N = log C i / log ∑C i is the degree of query navigation.
Manual evaluation showed that requests with a metric value above 0.95 are navigation with high accuracy. Moreover, this accuracy is equally high for both frequency queries and rare ones. With this method, the base of navigation requests-responses was able to grow to about 80,000 storage units.
However, the classification based on user behavior has serious drawbacks:
it works only if the request is known to us, that is, it is present in the logs, and the correct result is found and clicked. As a result, small sites and rare requests, in fact, play the lottery: no one was looking for someone, they were looking for others, but they could not find them, and only with randomly chosen people did everything go well.
New factors
At first, we decided to help those unlucky who at least looked for (but could not find).
We manually selected several thousand different navigation queries and began to study their properties. Compiled lists of words and phrases that are most characteristic for them, and lists of words for them, on the contrary, are uncharacteristic. They compared requests with the headings of the pages to which they lead, and with the text of links to these pages. We disassembled the navigation blocks of these pages. Domains and intradomain paths have been transliterated ...
All of this, ultimately, became elements of Bayesian classifiers and factors in the nodes of decision trees. After several iterations of balancing the training samples and evaluating the results of training, assessors managed to increase the base by another 10 times. It now included queries aimed at almost 800,000 different pages, including:
However, along with useful information, the machine model introduced a significant amount of low-frequency garbage, misprints and retraining artifacts into the database.
The second problem that has arisen is the clearly visible fragmentation of the base, that is, the unpredictable absence of queries in it that are semantically equivalent to those present. For example, the “headhunter job” got into the base, and the “work headhunter” seemed to the model unworthy.

In our circumstances, unpredictability is not good: requests with the same meaning should be treated the same. However, the inclusion in the database of all variants of all requests would inflate it to cosmic dimensions. And, as often happens, the solution to the second problem was found in the process of studying the first - ways to clean the base of the above-mentioned noise and redundancy. To do this, we had to look more closely at the “device” of navigation queries.
"Device" requests
It turned out that navigation queries, like sentences in natural languages, are not monolithic, they can also be disassembled by composition: different words play different roles. In total, there were five such roles (due to the lack of generally accepted terminology, I had to compose my own). Below is a complex query in which all the “members of the navigation offer” are present:

This is a real navigation query, he, as expected, the only correct answer .
We describe what are the navigation roles:
The kernel is a fragment that uniquely identifies the site to which the request leads. This is the most important part of the request. Usually the site has no more than ten different cores. For example, for the site lib.ru it is “lib ru”, “libru”, “libru” and “moshkov library”.
Background - fragments valid for the site. By itself, their presence in the request does not indicate its navigational nature, but at the same time they do not change the target in the presence of a suitable core. For youtube.com these are words like “video”, “videos”, for headhunter.ru - “vacancies”, “work”, etc.
Path - words that shift the target from the root page inside the site. For example, the word "maps", being attached to any Yandex kernel, redirects the request to maps.yandex.ru
Region - a type of path denoting the geography of the request. Its peculiarity is that for geo-dependent navigation, an explicit indication of the region in the query text is equivalent to a real change in the user's location. For example, a “IKEA” request received from a user from Kazan should lead to the same place where the IKEA Kazan request sent from any other region.
Noise - words that mean nothing in terms of navigation. These are official parts of speech and words such as “www”, “http”, “website”, etc.
For each site, all these fragments of requests, often repeated, in a different order and combinations are present in the database. In an effort to eliminate duplication, we began to look for ways to automatically partition "composite" requests into elementary parts in order to leave only unique fragments in it, and implement the logic of their interaction programmatically.
The solution was surprisingly simple - it was the data redundancy of our database that played into our hands.
If you sort the queries that have the same target, and then cut the shorter ones from the longer ones, then the whole set of queries is divided into two types of fragments: those that are present in the form of independent requests, and those that are present only as part of the request. For example, if the initial list consists of the requests “YouTube” and “YouTube Video”, then the word “YouTube” will be included in the first list, and the second “video” will be included in the first list. These will be the core and the background respectively.
If you take queries leading inside the site (for example, "Raiffeisen ATMs"), and similarly "subtract" requests from them leading to its root page ("Raiffeisen"), we get the path .
Along the way, counting the number of different fragments in the original list, we left only the most frequent in the database - thus, for large sites with many requests leading to them, we managed to throw out all the garbage without losing anything for small ones.
From chaos to order
As a result, we again complicated the classification: first, instead of one list, five appeared, and second, we had to implement a non-trivial logic of matching them in the query.
But in this way we managed to kill three birds with one stone at once: the fullness of the classification increased, while the base was reduced in size and cleared of low-frequency noise. It turned out about the following (dust - a very free translation of the word background ):

The complexity of the query splitting procedure is quadratic, but we haven’t yet had to optimize it: a simple pearl-barley script can cope with database decomposition in less than an hour.
Online logic
So, the base is structured, all five lists have become markers in dictionaries . Now, at the moment when the request is received, it is necessary to make a final decision on its navigation. To do this, we define in the parser special agent whether the following conditions are fulfilled for the request:
Separately processed paths are explicitly spelled URLs, regions in the request and the real region of the user. As a result, a verdict is made: is the request navigational, and where does the user want to go.
Below is a schematic illustration of the process of determining the navigability of the query “there are no rabbits”:

But the mysterious request “to kill three birds with one stone” is not our client: a part of the request is defined as navigation, but there are also some unfamiliar (or navigation incompatible) words.
Local searches
In some (in fact, very many) of such requests, the naming part can be presented as an independent request: “no sound of the three hares heart soundtrack”, “pelevin on librusek”, “YouTube vivaldi heimetal”, “Shakira in contact”. These are requests of the mixed type, already mentioned at the very beginning.
Strictly speaking, they are not navigational, but, as soon as we caught them in passing, they are a sin not to mention.
Unlike in-site navigation, which has static sections and pages of sites (“book file”, “beeline tariffs”), such requests require an answer obtained from the dynamic content of the specified site: personal pages in social networks, articles on news resources and encyclopedias, forum topics, etc.
In such queries, we detect the navigation part, and consider everything else that the user wants to find there.
For such queries, the following modifications of search parameters are possible:
What is the result?
As a result, we received an answer to the main questions: how many navigation queries we receive and how well we answer them. A brief summary is shown in the following diagrams:

So, from a quarter to a third of the entire flow of requests (depending on whether local searches are taken into account) are navigational. Among the navigation queries themselves, one third lead to the internal pages of the sites, almost one in ten depends on the region of the user, and a full quarter is occupied by the two most popular Russian social networks. Reason to think.
In addition, the classification results are used when ranking the results of a “large” search as a factor, which is currently quite powerful.
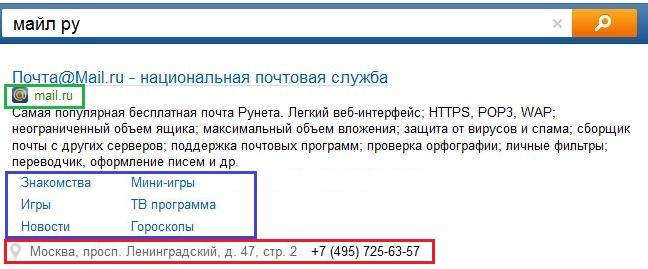
And finally, visual consequences: for the results of the navigation search, we create an extended snippet, sometimes we give several results from the desired site, we show favicons, site links and other special effects:
What's next?
In conclusion, we recall the sector that is still not covered by us: about those whom our users have not yet looked for . These are small regional organizations, highly specialized sites, local communities in social networks, personal pages and, of course, newly emerged sites and their sections. Let them be small, but there are a lot of them, and we want to be prepared for the fact that one day someone will want to find them.
There are no requests yet, and, accordingly, there is nothing to classify. However, having studied the text of the page, you can construct queries that should lead the user to this page. For this, it is necessary to find such fragments of the page text that uniquely identify it, and select those that can be used as a navigation query.
Perhaps this foggy task harbors abysses with dragons. Most likely, it will require other approaches to the solution and collisions with other pitfalls. But so it is interesting.
I’m getting round to this, thank you for your attention and, I hope, it was interesting for you! In the next part - the story of the spellchecker.
Mikhail Dolinin,
search request manager
There are only two main ways to express desires: either describe what you need to get (or do), or indicate where you need to "teleport". In the first case, the system tries to understand the request by correctly selecting the best of the network's responses, weighing hundreds of their properties on the decision trees. In the second, the correct answer is usually only one, and we expect that the search engine knows it.
')
Requests of the second type, answering questions where or where - navigation queries. I offer you a short story about how we work with them.
Generally speaking, the border between what and where is quite vague. Consider two search queries: "cyclists forum" and "cycle forum ru". Currently, the most relevant response to both of these requests is the same velo-forum.ru website. The difference is that in the first case the answer is not the only one and there is a competition between him and his analogues, in the second one the site is obliged not only to be present in the list of results, but also to head it, no matter how bad or good it is. compared with other cycle forums. The second query is navigational, and the first is not.
There are also requests of a mixed type, for example, “wiki onomatopei”. We will put them aside for the time being, but we will return to them.
So, we must know in advance the answers to navigation requests. Technically, this task is formulated as follows: compare each navigation request with its corresponding Internet address (hereinafter referred to as the target ): the site, the site section, the site page. And before that, determine whether the query is navigational.
Why do you need it?
First of all, various studies show that navigation is subjectively perceived as the simplest type of search (which is not surprising: it’s easier to know about something than to understand it ). Because of this, users are particularly picky in assessing the quality of the search engine's navigation responses, and it is they who have the strongest influence on users when making decisions about the search engine's responsibility as a whole.
At the same time there are a lot of navigation queries. So much that just leaving them unattended is extremely frivolous. After all, the most important thing in the processing of any data is accounting and control. That is, statistics and monitoring. In this case, statistics on query properties and monitoring the quality of responses.
If you sort all the search queries in descending order of their number, and then look at the resulting list “in perspective”, you will see something like the following:
It can be seen that the entire top was captured by navigation queries, weakly diluted by the most important information needs of mankind (they are marked in red). Therefore, no longer postponing
Go!
We started by simply going along the list, throwing out red blotches, and manually assigning each of its remaining requests to its target. It turned out that only "VKontakte" with "classmates" cover 5% of the total flow of requests, while the coverage of the list of 120 top navigation queries was almost 15%. Not bad for such meager intellectual costs.
Further, however, the “density” of navigation is rapidly decreasing, and therefore we had to look for ways to automatically filter the requests we needed. That is, roughly speaking, find out how “VKontakte” is different from “porn”.
Hall assistance
Users are not inclined to click on irrelevant answers. Accordingly, for navigation queries, it makes sense to expect that they all select the only correct answer. The working hypothesis was that the reverse is also true - if the majority of users who submitted a request click the same result, then this request is navigational, and the result is its target.
The test showed that the hypothesis as a whole is correct - only rare non-competitive requests that have a very relevant response (such as “nokia themes” or “download icq”) generate a similar behavioral pattern. However, almost all the false positives of their pseudo argents turned out to be pages within sites, so we just threw (temporarily) such requests from consideration.
We went through several ways to measure the unanimity of users (including classic clickrank), and stopped at the following simple and convenient metric.
Let C i be the number of clicks in the result R i , and ∑C i be the total number of clicks on request.
Then N = log C i / log ∑C i is the degree of query navigation.
Manual evaluation showed that requests with a metric value above 0.95 are navigation with high accuracy. Moreover, this accuracy is equally high for both frequency queries and rare ones. With this method, the base of navigation requests-responses was able to grow to about 80,000 storage units.
However, the classification based on user behavior has serious drawbacks:
it works only if the request is known to us, that is, it is present in the logs, and the correct result is found and clicked. As a result, small sites and rare requests, in fact, play the lottery: no one was looking for someone, they were looking for others, but they could not find them, and only with randomly chosen people did everything go well.
New factors
At first, we decided to help those unlucky who at least looked for (but could not find).
We manually selected several thousand different navigation queries and began to study their properties. Compiled lists of words and phrases that are most characteristic for them, and lists of words for them, on the contrary, are uncharacteristic. They compared requests with the headings of the pages to which they lead, and with the text of links to these pages. We disassembled the navigation blocks of these pages. Domains and intradomain paths have been transliterated ...
All of this, ultimately, became elements of Bayesian classifiers and factors in the nodes of decision trees. After several iterations of balancing the training samples and evaluating the results of training, assessors managed to increase the base by another 10 times. It now included queries aimed at almost 800,000 different pages, including:
- leading inside sites ("LJ Top")
- having several suitable sites (“tsk antares”: trade and construction company and dance and sports club)
- requests with a target, depending on the region of the user ("Sberbank", "mvideo")
However, along with useful information, the machine model introduced a significant amount of low-frequency garbage, misprints and retraining artifacts into the database.
The second problem that has arisen is the clearly visible fragmentation of the base, that is, the unpredictable absence of queries in it that are semantically equivalent to those present. For example, the “headhunter job” got into the base, and the “work headhunter” seemed to the model unworthy.
In our circumstances, unpredictability is not good: requests with the same meaning should be treated the same. However, the inclusion in the database of all variants of all requests would inflate it to cosmic dimensions. And, as often happens, the solution to the second problem was found in the process of studying the first - ways to clean the base of the above-mentioned noise and redundancy. To do this, we had to look more closely at the “device” of navigation queries.
"Device" requests
It turned out that navigation queries, like sentences in natural languages, are not monolithic, they can also be disassembled by composition: different words play different roles. In total, there were five such roles (due to the lack of generally accepted terminology, I had to compose my own). Below is a complex query in which all the “members of the navigation offer” are present:
This is a real navigation query, he, as expected, the only correct answer .
We describe what are the navigation roles:
The kernel is a fragment that uniquely identifies the site to which the request leads. This is the most important part of the request. Usually the site has no more than ten different cores. For example, for the site lib.ru it is “lib ru”, “libru”, “libru” and “moshkov library”.
Background - fragments valid for the site. By itself, their presence in the request does not indicate its navigational nature, but at the same time they do not change the target in the presence of a suitable core. For youtube.com these are words like “video”, “videos”, for headhunter.ru - “vacancies”, “work”, etc.
Path - words that shift the target from the root page inside the site. For example, the word "maps", being attached to any Yandex kernel, redirects the request to maps.yandex.ru
Region - a type of path denoting the geography of the request. Its peculiarity is that for geo-dependent navigation, an explicit indication of the region in the query text is equivalent to a real change in the user's location. For example, a “IKEA” request received from a user from Kazan should lead to the same place where the IKEA Kazan request sent from any other region.
Noise - words that mean nothing in terms of navigation. These are official parts of speech and words such as “www”, “http”, “website”, etc.
For each site, all these fragments of requests, often repeated, in a different order and combinations are present in the database. In an effort to eliminate duplication, we began to look for ways to automatically partition "composite" requests into elementary parts in order to leave only unique fragments in it, and implement the logic of their interaction programmatically.
The solution was surprisingly simple - it was the data redundancy of our database that played into our hands.
If you sort the queries that have the same target, and then cut the shorter ones from the longer ones, then the whole set of queries is divided into two types of fragments: those that are present in the form of independent requests, and those that are present only as part of the request. For example, if the initial list consists of the requests “YouTube” and “YouTube Video”, then the word “YouTube” will be included in the first list, and the second “video” will be included in the first list. These will be the core and the background respectively.
If you take queries leading inside the site (for example, "Raiffeisen ATMs"), and similarly "subtract" requests from them leading to its root page ("Raiffeisen"), we get the path .
Along the way, counting the number of different fragments in the original list, we left only the most frequent in the database - thus, for large sites with many requests leading to them, we managed to throw out all the garbage without losing anything for small ones.
From chaos to order
As a result, we again complicated the classification: first, instead of one list, five appeared, and second, we had to implement a non-trivial logic of matching them in the query.
But in this way we managed to kill three birds with one stone at once: the fullness of the classification increased, while the base was reduced in size and cleared of low-frequency noise. It turned out about the following (dust - a very free translation of the word background ):
The complexity of the query splitting procedure is quadratic, but we haven’t yet had to optimize it: a simple pearl-barley script can cope with database decomposition in less than an hour.
Online logic
So, the base is structured, all five lists have become markers in dictionaries . Now, at the moment when the request is received, it is necessary to make a final decision on its navigation. To do this, we define in the parser special agent whether the following conditions are fulfilled for the request:
- navigation markers cover the entire query from the first to the last word
- navigation core present
- there is a combination of markers with at least one common target
Separately processed paths are explicitly spelled URLs, regions in the request and the real region of the user. As a result, a verdict is made: is the request navigational, and where does the user want to go.
Below is a schematic illustration of the process of determining the navigability of the query “there are no rabbits”:
But the mysterious request “to kill three birds with one stone” is not our client: a part of the request is defined as navigation, but there are also some unfamiliar (or navigation incompatible) words.
Local searches
In some (in fact, very many) of such requests, the naming part can be presented as an independent request: “no sound of the three hares heart soundtrack”, “pelevin on librusek”, “YouTube vivaldi heimetal”, “Shakira in contact”. These are requests of the mixed type, already mentioned at the very beginning.
Strictly speaking, they are not navigational, but, as soon as we caught them in passing, they are a sin not to mention.
Unlike in-site navigation, which has static sections and pages of sites (“book file”, “beeline tariffs”), such requests require an answer obtained from the dynamic content of the specified site: personal pages in social networks, articles on news resources and encyclopedias, forum topics, etc.
In such queries, we detect the navigation part, and consider everything else that the user wants to find there.
For such queries, the following modifications of search parameters are possible:
- search only on the specified site
- use your own site search (that is, show a link like this in the results)
- don't do anything special
What is the result?
As a result, we received an answer to the main questions: how many navigation queries we receive and how well we answer them. A brief summary is shown in the following diagrams:
So, from a quarter to a third of the entire flow of requests (depending on whether local searches are taken into account) are navigational. Among the navigation queries themselves, one third lead to the internal pages of the sites, almost one in ten depends on the region of the user, and a full quarter is occupied by the two most popular Russian social networks. Reason to think.
In addition, the classification results are used when ranking the results of a “large” search as a factor, which is currently quite powerful.
And finally, visual consequences: for the results of the navigation search, we create an extended snippet, sometimes we give several results from the desired site, we show favicons, site links and other special effects:
What's next?
In conclusion, we recall the sector that is still not covered by us: about those whom our users have not yet looked for . These are small regional organizations, highly specialized sites, local communities in social networks, personal pages and, of course, newly emerged sites and their sections. Let them be small, but there are a lot of them, and we want to be prepared for the fact that one day someone will want to find them.
There are no requests yet, and, accordingly, there is nothing to classify. However, having studied the text of the page, you can construct queries that should lead the user to this page. For this, it is necessary to find such fragments of the page text that uniquely identify it, and select those that can be used as a navigation query.
Perhaps this foggy task harbors abysses with dragons. Most likely, it will require other approaches to the solution and collisions with other pitfalls. But so it is interesting.
I’m getting round to this, thank you for your attention and, I hope, it was interesting for you! In the next part - the story of the spellchecker.
Mikhail Dolinin,
search request manager
Source: https://habr.com/ru/post/176363/
All Articles