Heritage Health Prize data mining contest ends
The largest competition since the Netflix Prize in the analysis of large data sets has come to an end. And although the official results of the first ten and the winner will be announced in two months, the results can already be summed up.
The goal was to predict hospitalization of patients over the next year based on data from the previous two years of treatment. According to the sponsor's plan, this will allow more attention to be paid to those patients who most need it, thereby saving some of the $ 30 billion spent annually in the United States on hospitalization.
The prize declared by the organizers of $ 3,000,000 was unattainable due to the established accuracy limit of 0.4 RMSLE (less-better; best result achieved 0.46; the difference between the first and the hundredth place is 0.008; RMSLE is the standard deviation of logarithms) and the data provided - it’s just did not contain sufficient to achieve this level of accuracy of the amount of information. Therefore, in fact, the struggle was for $ 500,000, getting to the best team, a foundation of intermediate finishes and invaluable experience.
Despite the complexity of the task, there were more than one and a half thousand people willing to try their hand. It is said that two Nobel laureates even participated in the contest, but who it was and what the success is not being recognized. Considering that in the field of mathematics and programming they do not exist, there remains medicine - as a consultant or economics.
The competition lasted two years and had three intermediate finishes, each of which had two prizes. The winners, under the terms of the competition, laid out a description of their methods. However, it didn’t help much to rivals, the fact is that the basic algorithms are well known - these are decision trees , Random Forest , Gradient Boosting , Gradient descent , Ridge Regression (ridge regression, Tikhonov regularization), their modifications and combinations. The differences lay in the intricacies of implementation, use, combination, and small variations of the algorithms themselves. However, there were so many details that it was not clear - due to which the result itself is achieved. That is, what the winners do is understandable, it is not clear why they do exactly this, and why what they are doing is working.
Intermediate finishes were distributed as follows:
- 1. Market Makers 2. Willem Mestrom
- 1. Market Makers 2. Edward & Willem
- 1. Edward & Willem 2. crescendo
')
The oddities began before the third intermediate finish - all three teams almost did not use the model-tested 30% test data per day, and the leader changed without a fight. The reason was the unification of one team, while it was impossible to exceed the limit of sent models for all the time since the beginning of the competition - miraculously met.
On the day of the finish, preliminary results for 30% of the test data looked like this .
But the most interesting was in the results on the hidden part , published in a few days, reflecting the true evaluation of the algorithms.
Summary table for the first 50 places:
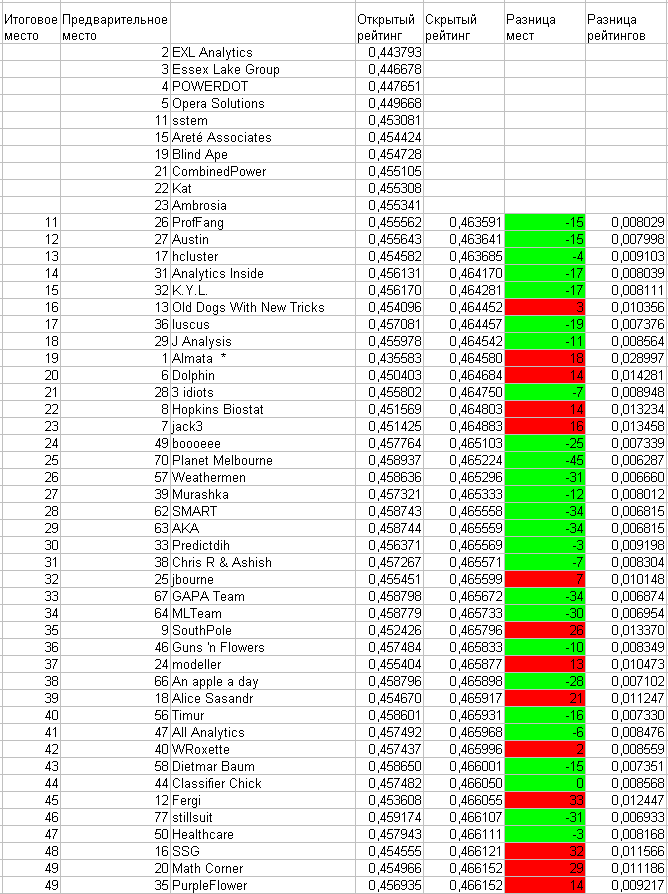
The main enemy was the effect, most vividly observed by the Almata team, which ranked first in the open rating. This is overfitting - overfitting. They extracted all the useful information from the data for which the rating was considered, based on the rating estimates, and with it captured harmful, recruitment-specific information. As a result, the estimate for unknown data worsens (or at least does not improve). The result - moving from 1st to 19th place.
The winner and marks of the first 10 participants will be officially announced in early June at the Health Datapalooza IV conference. However, there is almost no doubt about winning POWERDOT - the team formed by the merger of the winners of the intermediate finishes. Having at their disposal 3 best results, they got the opportunity to learn implicitly on the hidden part of the rating, after which it became impossible to fight with them.
But there was something to learn. For me, this was expressed in moving from 261st place in the last intermediate finish to the final 27th. It could be higher - the understanding of the processes taking place came too late, but next time it will be more interesting.
The description of the methods of the winners of intermediate finishes (the winner algorithm will probably be compiled from their combination) can be read here (a lot of mathematics and maneuvers, which I still do not understand).
UPD 2013.07.15. As predicted, POWERDOT won with a score of 0.461197. After stripping from violators of rules that used multiple accounts, the look of the summary table changed. And the organizers promise the second part of the competition with invitations based on the results of the first.
Source: https://habr.com/ru/post/176267/
All Articles