bookradar.org - book search service
I want to present you my project, on which I have been working for the last few months, and also to tell how it happened. bookradar.org - search engine for books on online stores. The service is designed for people who like to read books. Using the site they can find out where you can buy the right book, as well as save on the purchase. The more a book is worth, the more its price varies in stores.

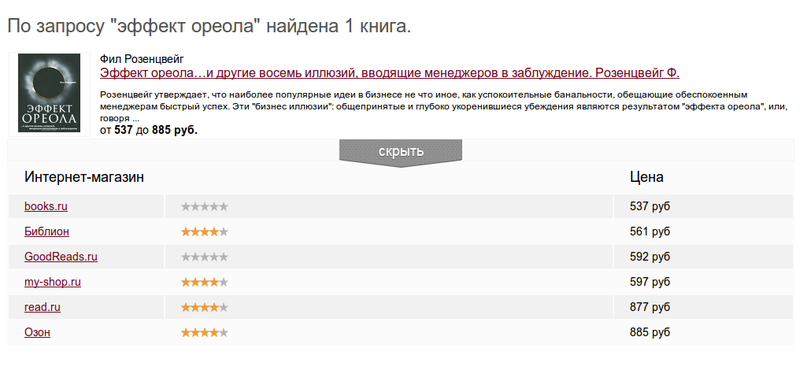
For example, Phil Rosenzweig’s book, The Halo Effect ... and the other eight illusions that mislead managers. It costs in different stores from 537 to 885 rubles. The difference is quite significant.
')
From the idea to the result further ...
Sample book request:
I love to read books, and I often buy them. To be honest, I buy them more often than I have time to read. Some books may lie on my shelf for 3 years before I get to them. I have a Kindle Paperwhite and Nook Simple Touch reader, I also read a lot of books on my computer in various pdfs. Undoubtedly, electronic books have advantages - they can be quickly bought and read in the dark, but even so, I prefer paper ones.
It was mid November 2012, I signed up for the MongoDB for Developers online course. It took a couple of weeks from its beginning. Although I have not yet introduced all the capabilities of MongoDB, I already really liked this technology. There was a desire to somehow apply new knowledge in practice. And then I got the idea to make a book search site.
At that time I had already seen one such site, but to be honest, it was not very convenient, and did not always give reliable results. It might have been worth searching other sites, but at that moment I did not. I began to look at other sites after I launched my own. They turned out to be much larger than I could have imagined. There are more than a dozen such sites. However, this did not bother me at all. I can offer users a more convenient search, and in the future I hope more accurate and wider. And indeed there is no shortage of ideas)
At first I decided that a couple of days off would be enough for me to carry out my plans, but as often happens, it took much longer. At work, I use Django, but to be honest, for a couple of years working with her, she bored me a little. Django is a great framework, but I just wanted something new, and I decided to do a project on Flask. Why choose Flask? A random acquaintance threw off a link to a blog creation tutorial on Flask + mongoDB and said that he has been using Flask in his projects for a long time. It was interesting to try.

I asked my wife to draw a design (hello Polina!), Specifying that the design is needed as simple as possible, without any shadows or gradients. At that time, it allowed me to save time on layout and make changes easier.
A month has passed ... to be honest, I was very tired all the evenings and weekends devoting to programming, and the enthusiasm is rapidly quenched. I had to urgently get feedback from real people. I laid out the project in the minimum working form. The project was already working, really looking for books in stores, but suffered greatly from a lot of minor bugs and flaws. All this was done intentionally to speed up the display of the first version. There was not even such elementary things as handling errors 404 and 500, not to mention all sorts of history API.
Having received a positive assessment of my colleagues, I was inspired to continue working. The following month was devoted mainly to refinement, in these very small schools.
Moreover, it turned out that the real data does not correspond to what I was preparing for initially. I had to change the schema of the documents in the database, separate the collections, change the algorithms.
With real data a lot of jokes. For example, I calculated that the ISBN may be a unique identifier for a book. In fact, it turned out wrong. One book can have multiple ISBNs. I don’t know who in stores is filling the base, but not only can ISBNs be invalid, instead of ISBN, it may even be devils that, from arbitrary numbers, to some phrases in Russian. Instead of the digit zero, the symbol “O” can be scored, and instead of the English “Ex” there can be the Russian “Ha”.
Moreover, two completely different books may have one ISBN. In theory, this is impossible. Some books are published by publishers in sets. For example, ISBNs from two different books and authors from two different books appear in such a supposed book.
And then I ran into a performance problem. Python, like any other dynamic language, does not work as fast as we would like. For web applications, this usually does not matter; if your site slows down it means it slows down the database, disk operations or network. I have long profiled the code, optimized the algorithms. I came to the conclusion that the algorithms are normal, inhibit Python and DB.
It was necessary to rewrite a substantial part of the project in a faster language, obviously with static typing. So Scala appeared in the project, a programming language unknown to me until now)
Why actually Scala? I chose between C, C ++ and Scala. The first Segmentation Fault made me delete from this C list. C is a good language, but obviously not optimal for this task. Of course, I watched the performance tests of languages, but to be honest, I did not believe that the speed of Java / Scala is close to the speed of C ++. Therefore, I wrote my performance test. I took a small piece of the parser and wrote its implementation in Python, Scala, and C ++.
Here are the results of a parsig 1.5 GB file:
CPython 4 min 12 sec
PyPy 2 min 48 sec
Scala 57 sec
C ++ 47 sec.
The algorithm is the same everywhere, for parsing, only string operations are used. In Scala I also tried using some standard XML parser, but it worked much slower.
As you can see, the Scala speed is really close to the pluses. And writing and debugging Scala is easier. In addition, I had someone to consult, in case of misunderstandings (Ivan hello!).
When writing code on Scala, I often found myself thinking “this code looks wrong, you need to figure out how to do it right”. Such perfectionism could significantly slow down the development. I said to myself, “Dude, you do not know this language, and therefore you cannot write rightly right away, so just write for it to work!”. Psychologically, it was difficult to force myself to write “to work”, I wanted to do “beautifully”. But in the end I took myself in hand and wrote “to work”.
TDD. All parsers from the very beginning were covered with tests, that in Python, that in Scala. This is exactly the place where tests immediately speed up development. On the other hand, there is still no test on the fortend.
On the very first day after the launch, colleagues asked me when I was going to make the search paid. And I was not going to do that. Monetization is simple and clear - affiliate programs stores. I do not plan to place advertising.
A whole mountain of shortcomings present at the launch has already been fixed, although they are still present in appreciable quantities. One of the interesting tasks that had to face is gluing books from different sources. Now the gluing algorithm is already working quite well, but sometimes it still fails. If you encounter this, email me.
The frontend is written in Python / Flask, bakand on Scala, as the base - MongoDB.
There are a lot of ideas, but in the near future I plan to work on the quality of the search and the correction of minor issues. New features are cool, and they will definitely appear, but a little later. By the way, your comments may affect the order in which they appear.
I hope you enjoyed my service,
I will be extremely grateful for the advice, criticism and suggestions.
Come in - www.bookradar.org !
For example, Phil Rosenzweig’s book, The Halo Effect ... and the other eight illusions that mislead managers. It costs in different stores from 537 to 885 rubles. The difference is quite significant.
')
From the idea to the result further ...
Sample book request:
Idea
I love to read books, and I often buy them. To be honest, I buy them more often than I have time to read. Some books may lie on my shelf for 3 years before I get to them. I have a Kindle Paperwhite and Nook Simple Touch reader, I also read a lot of books on my computer in various pdfs. Undoubtedly, electronic books have advantages - they can be quickly bought and read in the dark, but even so, I prefer paper ones.
It was mid November 2012, I signed up for the MongoDB for Developers online course. It took a couple of weeks from its beginning. Although I have not yet introduced all the capabilities of MongoDB, I already really liked this technology. There was a desire to somehow apply new knowledge in practice. And then I got the idea to make a book search site.
At that time I had already seen one such site, but to be honest, it was not very convenient, and did not always give reliable results. It might have been worth searching other sites, but at that moment I did not. I began to look at other sites after I launched my own. They turned out to be much larger than I could have imagined. There are more than a dozen such sites. However, this did not bother me at all. I can offer users a more convenient search, and in the future I hope more accurate and wider. And indeed there is no shortage of ideas)
Implementation
At first I decided that a couple of days off would be enough for me to carry out my plans, but as often happens, it took much longer. At work, I use Django, but to be honest, for a couple of years working with her, she bored me a little. Django is a great framework, but I just wanted something new, and I decided to do a project on Flask. Why choose Flask? A random acquaintance threw off a link to a blog creation tutorial on Flask + mongoDB and said that he has been using Flask in his projects for a long time. It was interesting to try.
I asked my wife to draw a design (hello Polina!), Specifying that the design is needed as simple as possible, without any shadows or gradients. At that time, it allowed me to save time on layout and make changes easier.
A month has passed ... to be honest, I was very tired all the evenings and weekends devoting to programming, and the enthusiasm is rapidly quenched. I had to urgently get feedback from real people. I laid out the project in the minimum working form. The project was already working, really looking for books in stores, but suffered greatly from a lot of minor bugs and flaws. All this was done intentionally to speed up the display of the first version. There was not even such elementary things as handling errors 404 and 500, not to mention all sorts of history API.
Having received a positive assessment of my colleagues, I was inspired to continue working. The following month was devoted mainly to refinement, in these very small schools.
Moreover, it turned out that the real data does not correspond to what I was preparing for initially. I had to change the schema of the documents in the database, separate the collections, change the algorithms.
With real data a lot of jokes. For example, I calculated that the ISBN may be a unique identifier for a book. In fact, it turned out wrong. One book can have multiple ISBNs. I don’t know who in stores is filling the base, but not only can ISBNs be invalid, instead of ISBN, it may even be devils that, from arbitrary numbers, to some phrases in Russian. Instead of the digit zero, the symbol “O” can be scored, and instead of the English “Ex” there can be the Russian “Ha”.
Moreover, two completely different books may have one ISBN. In theory, this is impossible. Some books are published by publishers in sets. For example, ISBNs from two different books and authors from two different books appear in such a supposed book.
And then I ran into a performance problem. Python, like any other dynamic language, does not work as fast as we would like. For web applications, this usually does not matter; if your site slows down it means it slows down the database, disk operations or network. I have long profiled the code, optimized the algorithms. I came to the conclusion that the algorithms are normal, inhibit Python and DB.
It was necessary to rewrite a substantial part of the project in a faster language, obviously with static typing. So Scala appeared in the project, a programming language unknown to me until now)
Why actually Scala? I chose between C, C ++ and Scala. The first Segmentation Fault made me delete from this C list. C is a good language, but obviously not optimal for this task. Of course, I watched the performance tests of languages, but to be honest, I did not believe that the speed of Java / Scala is close to the speed of C ++. Therefore, I wrote my performance test. I took a small piece of the parser and wrote its implementation in Python, Scala, and C ++.
Here are the results of a parsig 1.5 GB file:
CPython 4 min 12 sec
PyPy 2 min 48 sec
Scala 57 sec
C ++ 47 sec.
The algorithm is the same everywhere, for parsing, only string operations are used. In Scala I also tried using some standard XML parser, but it worked much slower.
As you can see, the Scala speed is really close to the pluses. And writing and debugging Scala is easier. In addition, I had someone to consult, in case of misunderstandings (Ivan hello!).
When writing code on Scala, I often found myself thinking “this code looks wrong, you need to figure out how to do it right”. Such perfectionism could significantly slow down the development. I said to myself, “Dude, you do not know this language, and therefore you cannot write rightly right away, so just write for it to work!”. Psychologically, it was difficult to force myself to write “to work”, I wanted to do “beautifully”. But in the end I took myself in hand and wrote “to work”.
TDD. All parsers from the very beginning were covered with tests, that in Python, that in Scala. This is exactly the place where tests immediately speed up development. On the other hand, there is still no test on the fortend.
Monetization
On the very first day after the launch, colleagues asked me when I was going to make the search paid. And I was not going to do that. Monetization is simple and clear - affiliate programs stores. I do not plan to place advertising.
The present
A whole mountain of shortcomings present at the launch has already been fixed, although they are still present in appreciable quantities. One of the interesting tasks that had to face is gluing books from different sources. Now the gluing algorithm is already working quite well, but sometimes it still fails. If you encounter this, email me.
The frontend is written in Python / Flask, bakand on Scala, as the base - MongoDB.
Future plans
There are a lot of ideas, but in the near future I plan to work on the quality of the search and the correction of minor issues. New features are cool, and they will definitely appear, but a little later. By the way, your comments may affect the order in which they appear.
I hope you enjoyed my service,
I will be extremely grateful for the advice, criticism and suggestions.
Come in - www.bookradar.org !
Source: https://habr.com/ru/post/175813/
All Articles