The Future of Search: Interviews with Participants of the European Information Retrieval Conference
Especially for Habrahabr Ilya Segalovich ( iseg ), technical director of Yandex, briefly told how important she is; why the fact that it took place here is of great importance and what efforts we and our co-organizers from the Higher School of Economics had to spend ECIR in Moscow.
')
We also interviewed several authors of the most interesting articles and speeches, and the committee chairman of the Best Paper Awards jury was asked to tell what the best articles were about and why the subjects of these particular studies are now most important for science and industry. Under the cat tomograms of the brain and other interesting.
Yashar Moshfegi, University of Glasgow
Let's start with one of the authors of a somewhat unusual article for ECIR - Understanding Relevance: An fMRI Study . Scientists from the University of Glasgow using magnetic resonance imaging have studied which parts of the brain are activated at the time when it decides whether this or that information is relevant.
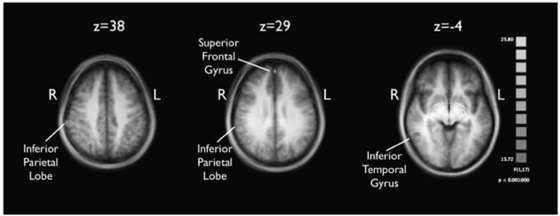
We asked Yashar Moshfegi to tell what they managed to figure out and how, in his opinion, this could affect the fate of measurements in the field of information retrieval in the future. By the way, for each interview you can include Russian subtitles.
Decryption for those who prefer to read
Tell us a little about what your research?
The goal of our research was to find brain regions that respond to clearly relevant information. Under it we understand the current definition of relevance. We tried to see which parts of the brain respond to information that is rated as relevant and irrelevant, and how these reactions differ. During the past forty years, a lot of research has been done in Information Retrieval and Information Science to understand what information is considered relevant.
The reason is that relevance is a human assessment. And, like any human assessment, it is difficult to understand and describe it by some definition. But since this is a key concept in information retrieval, it is imperative to understand it better. And one of the ways to do this is to look into the human brain and see what happens in it. Therefore, we were able to use a magnetic resonance tomography scanner in our research and see what happens in the human brain during relevance assessment and which parts of it are involved in this process.
How can research results be applied?
There are two possibilities. The first is theoretical. Since research helps us better understand which parts of the brain are activated, it can help figure out exactly what functionality each of them is associated with. We can better understand what processes occur in a person’s head when he decides whether a document is relevant to him. But there is also a practical application that can generate new ways of assessing relevance.
By the way, about Moscow. Is that how you imagined it? Snow in March?
Well, I heard a lot about snow, but I didn’t think it would be that much! So yes, this is very similar to what I saw in the movie.
The goal of our research was to find brain regions that respond to clearly relevant information. Under it we understand the current definition of relevance. We tried to see which parts of the brain respond to information that is rated as relevant and irrelevant, and how these reactions differ. During the past forty years, a lot of research has been done in Information Retrieval and Information Science to understand what information is considered relevant.
The reason is that relevance is a human assessment. And, like any human assessment, it is difficult to understand and describe it by some definition. But since this is a key concept in information retrieval, it is imperative to understand it better. And one of the ways to do this is to look into the human brain and see what happens in it. Therefore, we were able to use a magnetic resonance tomography scanner in our research and see what happens in the human brain during relevance assessment and which parts of it are involved in this process.
How can research results be applied?
There are two possibilities. The first is theoretical. Since research helps us better understand which parts of the brain are activated, it can help figure out exactly what functionality each of them is associated with. We can better understand what processes occur in a person’s head when he decides whether a document is relevant to him. But there is also a practical application that can generate new ways of assessing relevance.
By the way, about Moscow. Is that how you imagined it? Snow in March?
Well, I heard a lot about snow, but I didn’t think it would be that much! So yes, this is very similar to what I saw in the movie.
Mark Nyork, Microsoft Research
Mark has been in the information search industry for several decades. He was one of those who participated in the development of the first popular Internet search engine - AltaVista . Now Mark is Principal Researcher at Microsoft Research .
At ECIR 2013, he participated in Industry Day and talked about his vision of when social data could help with search results, and what would not. We, in turn, talked to Mark about the past and future of the search, the main trends he sees, and also which areas will be the most important and interesting in the Information Retrieval:
Decryption for those who prefer to read
As far as I know, you have been searching for a long time. Could you tell us how to start?
I started searching in the late 90s. He worked at Compaq Computer Corporation, in which AltaWista was developed. Engaged in search robots, which later began to be used in it.
You get amazed when you see how fast the web has grown, what scale it has acquired, how the search engines coped with it. I remember when Alta Vista was launched, in my opinion, from 20 million pages in the index. Today, such large search engines like Google, Bing or Yandex have indexed around tens of billions of pages. The scale of growth is a thousandfold. And, I think, this growth will not stop for a long time.
I think the main task in the last ten years was to integrate information into the search, which is increasingly created by the users themselves. If you look at how the web search started, at the first search engines like Excite and AltaVista, you will see that they used traditional information retrieval tools. That is, they tried to understand how well indexed web pages respond to search queries.
Google's innovation was that they began to consider whether there are links to a web page somewhere else. The next technique, which began to use the largest search engines, including Yandex, Google, Bing, was the analysis of user behavior. For this purpose, requests, clicks, data about exactly how a person views the pages were used. So the users themselves have become an important link in information retrieval, search on the Internet.
Vertical searches are increasingly integrated into it. When you, for example, look for a restaurant, a search engine even today shows you its menu, opening hours, reviews, location. The same is in the search for airlines. If you are looking for a flight, the search engine will, among other things, show you that the flight in question is delayed by half an hour. Starting to take into account different vertical search scenarios is one part of this step.
There is a more general solution. Notice that all the scripts mentioned meant an answer without having to follow the link. You enter a request and get an answer right away. There is a movement towards generalizing this practice to other areas. So that the search engine will not only point you to the relevant documents, but load them into his mind and synthesize the answer. This is possible for any query in which ... this is a conversation about factoids. If you set a request for a Yandex profit, the search engine could give you a ready answer based on five articles that mentioned the size of this profit.
What do you think will be the most interesting area of information retrieval in the next five years?
Oh, not an easy question. I think - a better understanding of semantics and meaning in documents. Perhaps we will stop treating them like bags of words. We will extract the structure and meaning of the pages.
I started searching in the late 90s. He worked at Compaq Computer Corporation, in which AltaWista was developed. Engaged in search robots, which later began to be used in it.
You get amazed when you see how fast the web has grown, what scale it has acquired, how the search engines coped with it. I remember when Alta Vista was launched, in my opinion, from 20 million pages in the index. Today, such large search engines like Google, Bing or Yandex have indexed around tens of billions of pages. The scale of growth is a thousandfold. And, I think, this growth will not stop for a long time.
I think the main task in the last ten years was to integrate information into the search, which is increasingly created by the users themselves. If you look at how the web search started, at the first search engines like Excite and AltaVista, you will see that they used traditional information retrieval tools. That is, they tried to understand how well indexed web pages respond to search queries.
Google's innovation was that they began to consider whether there are links to a web page somewhere else. The next technique, which began to use the largest search engines, including Yandex, Google, Bing, was the analysis of user behavior. For this purpose, requests, clicks, data about exactly how a person views the pages were used. So the users themselves have become an important link in information retrieval, search on the Internet.
Vertical searches are increasingly integrated into it. When you, for example, look for a restaurant, a search engine even today shows you its menu, opening hours, reviews, location. The same is in the search for airlines. If you are looking for a flight, the search engine will, among other things, show you that the flight in question is delayed by half an hour. Starting to take into account different vertical search scenarios is one part of this step.
There is a more general solution. Notice that all the scripts mentioned meant an answer without having to follow the link. You enter a request and get an answer right away. There is a movement towards generalizing this practice to other areas. So that the search engine will not only point you to the relevant documents, but load them into his mind and synthesize the answer. This is possible for any query in which ... this is a conversation about factoids. If you set a request for a Yandex profit, the search engine could give you a ready answer based on five articles that mentioned the size of this profit.
What do you think will be the most interesting area of information retrieval in the next five years?
Oh, not an easy question. I think - a better understanding of semantics and meaning in documents. Perhaps we will stop treating them like bags of words. We will extract the structure and meaning of the pages.
Mor Naaman, Rutgers University SMIL, Mahaya, Inc.
Mora's story opened the conference. He is currently developing a startup Mahaya.co . The service aggregates social data and tries to help look through them at events in which many people were involved, from different angles. Sometimes literally:
Decryption for those who prefer to read
I really love the IR community. And although I have not published in the framework of conferences on information retrieval, but in what I do, I largely intersect with it. I know a lot of people whose research topics have something in common with my work. Interest in social media, which obviously excites me, is growing. And I think it will be very important to understand what information retrieval tools will be useful for working with social data.
My presentation was about how social media changes the way we see and understand the world. Especially, if we talk about events - everything that happens now is documented by social media. You can constantly see people taking pictures and tweeting something. And thanks to this, we have a record of society and culture, which was not previously available. I talked about the different tools that are needed to understand all this information. How can we collect, find, organize, present and save it in a more accessible way. So that we can record the world in such a way as to interact with what happened.
In general, my presentation on social media and how they document the world, how we do it ourselves and how we help people understand it.
My presentation was about how social media changes the way we see and understand the world. Especially, if we talk about events - everything that happens now is documented by social media. You can constantly see people taking pictures and tweeting something. And thanks to this, we have a record of society and culture, which was not previously available. I talked about the different tools that are needed to understand all this information. How can we collect, find, organize, present and save it in a more accessible way. So that we can record the world in such a way as to interact with what happened.
In general, my presentation on social media and how they document the world, how we do it ourselves and how we help people understand it.
Mora's presentation can be viewed on SlideShare and on video.
Paul Ogilvy, LinkedIn
Information Retrieval is not just a search. LinkedIn's Paul Ogilvy understands this more than many others. Within the framework of Industry day, he talked about how you can evaluate the quality of the proposed search in the case when conventional metrics like Cranfield style evaluations or A / B testing methods are not quite applicable:
Decryption for those who prefer to read
Tell us a little about your presentation, please.
I will talk about how many details of the problem can be lost in the tasks of information retrieval with the evaluation methods that are now commonly used. For example, measurements based on static collections. As a result of this, sometimes we solve the wrong task. This is because we do not have the necessary data types to collect all the details. I give some examples of things that we miss when we work with traditional collections. And some examples of what data can be collected and which metrics to use to avoid some common distortion.
We are busy with very applied tasks. We do not have pure research groups. Everyone who does research also works on production systems. And it ensures that everything that we invent and study is based on the problems that we actually face. And one of the biggest problems we faced on LinkedIn is that when we try to evaluate quality, we may not have enough measurements to predict what will happen on real data. So we put a lot of emphasis on understanding this. Because the ability to predict well from correctly collected data helps to develop much faster.
I will talk about how many details of the problem can be lost in the tasks of information retrieval with the evaluation methods that are now commonly used. For example, measurements based on static collections. As a result of this, sometimes we solve the wrong task. This is because we do not have the necessary data types to collect all the details. I give some examples of things that we miss when we work with traditional collections. And some examples of what data can be collected and which metrics to use to avoid some common distortion.
We are busy with very applied tasks. We do not have pure research groups. Everyone who does research also works on production systems. And it ensures that everything that we invent and study is based on the problems that we actually face. And one of the biggest problems we faced on LinkedIn is that when we try to evaluate quality, we may not have enough measurements to predict what will happen on real data. So we put a lot of emphasis on understanding this. Because the ability to predict well from correctly collected data helps to develop much faster.
Arjen de Vries, Chairman of the Best Articles Awards Committee
Summing up the conference, Arjen de Vries, member of the jury of the Best Paper Awards and the ECIR 2013 organizing committee, explained why the articles recognized as better than they are so important for the industry were cool and shared their impressions of the conference:
Decryption for those who prefer to read
Hello. What do you think about ECIR in Moscow, what are your impressions?
Well, in my opinion, the conference was very good. A very wide range of topics was covered, very good articles were presented. As you know, I was the head of the committee that selected the best articles. And we could not even choose one - I had to give three prizes. And on topics from controversial interdisciplinary to extremely clear and applied. I really liked the student article from a researcher from Yandex. It is important to pay attention to her - I think she will benefit in her field. So, if we talk about quality, the conference was very good.
And what else can you say about the best articles? For example, there was a study by Yashar about fMRI. Is this type of research something new to ECIR? It is not only about Computer Science, but also about the structure of the human brain.
As far as I think, this is the first research in information retrieval, where they used fMRI scanners to understand what happens in people's brains when they look at the images and decide whether they are suitable as an answer to a question or not. It is difficult to say what this will lead to. So far we only know that we can measure something related to relevance, but we don’t know if any generalization can be made from this. And it will be quite difficult to create a method that could be used without forcing people to lie in a huge tomograph. However, as far as I know, this is, in fact, the first work in this direction with clear results. So I am glad to raise attention to her.
And about the second best article, if you want. It is exceptional because there is a big problem: companies collect data that they absolutely need to make a good search engine. And scientists would like to work with approximately the same data - to test their hypotheses. But every attempt to openly publish such an archive of data is hindered by the question of privacy. And this work dramatically increases the percentage of search logs that can be published, by violating anyone's privacy. And this is done beautifully, using very complex mathematics, which is perfectly applied. With very clear goals and results.
Well, in my opinion, the conference was very good. A very wide range of topics was covered, very good articles were presented. As you know, I was the head of the committee that selected the best articles. And we could not even choose one - I had to give three prizes. And on topics from controversial interdisciplinary to extremely clear and applied. I really liked the student article from a researcher from Yandex. It is important to pay attention to her - I think she will benefit in her field. So, if we talk about quality, the conference was very good.
And what else can you say about the best articles? For example, there was a study by Yashar about fMRI. Is this type of research something new to ECIR? It is not only about Computer Science, but also about the structure of the human brain.
As far as I think, this is the first research in information retrieval, where they used fMRI scanners to understand what happens in people's brains when they look at the images and decide whether they are suitable as an answer to a question or not. It is difficult to say what this will lead to. So far we only know that we can measure something related to relevance, but we don’t know if any generalization can be made from this. And it will be quite difficult to create a method that could be used without forcing people to lie in a huge tomograph. However, as far as I know, this is, in fact, the first work in this direction with clear results. So I am glad to raise attention to her.
And about the second best article, if you want. It is exceptional because there is a big problem: companies collect data that they absolutely need to make a good search engine. And scientists would like to work with approximately the same data - to test their hypotheses. But every attempt to openly publish such an archive of data is hindered by the question of privacy. And this work dramatically increases the percentage of search logs that can be published, by violating anyone's privacy. And this is done beautifully, using very complex mathematics, which is perfectly applied. With very clear goals and results.
Links to all the studies described at the conference are already available.
Such a seemingly investigated area, as an information search, finds more and more new incarnations and measurements. As you understand, this is happening because our life on the Internet is constantly changing and saturated. We are overgrown with connections, data, devices, social networks. Search and assistance in the organization of this information acquire a completely different sound and value.
Source: https://habr.com/ru/post/175349/
All Articles