Judy arrays in php
 Badoo uses many services in C and C ++, most of which work with huge amounts of data. As a rule, services act as a “fast cache” or “fast database”, i.e. perform various operations with arrays of the same type. For quick access to data, we have long and successfully used Judy arrays (eng. Judy arrays). But once we wanted a strange one: to process large arrays of integers in PHP, and we immediately remembered Judy.
Badoo uses many services in C and C ++, most of which work with huge amounts of data. As a rule, services act as a “fast cache” or “fast database”, i.e. perform various operations with arrays of the same type. For quick access to data, we have long and successfully used Judy arrays (eng. Judy arrays). But once we wanted a strange one: to process large arrays of integers in PHP, and we immediately remembered Judy.A bit of history
Judy arrays were invented by Douglas Baskins in the early 2000s. The project of their development was funded by HP, but after about two years it was closed. During this time, four versions were released, and the development of the latter took more than a year, and in it the developers were able to double the speed of Judy, reduce memory consumption by half, although it was a difficult price: the amount of code increased 5 times and its complexity - on order.
The algorithm of the Judy-arrays is patented , but the original implementation in C is available on the official site under the LGPL license.
The project was named after the sister of Baskins, because the developers could not come up with a better option.
Tree-trees
In truth, Judy arrays are not actually arrays. Judy is the development of trie , i.e. prefix tree, using different compression techniques. Judy arrays compare favorably with C arrays and standard implementations of hash arrays: sparse Judy arrays use memory efficiently and scale well, while showing comparable read and write speeds (see benchmarks ).
A detailed description of Judy’s work algorithm is unlikely to fit into the article format for Habr, so we’ll just leave the links to the official documentation: 1 and 2 .
')
There are several types of judy arrays:
- Judy1 - bitmap (bitmap), the index is an integer (integer-> bit);
- JudyL - an array with an integer as an index (integer-> integer / pointer);
- JudySL - an array of pointers with a string as an index (string-> integer / pointer);
- JudyHS is an array of pointers with a byte set as an index (array of bytes-> integer / pointer).
Judy arrays do not require initialization, and an empty array is a simple NULL pointer. The consequence of this is that Judy arrays are conveniently nested. So convenient that JudySL and JudyHS are actually nested arrays of JudyL.
Benchmarks
Embedded arrays in PHP are universal and, as a result, extremely inefficient in some cases. Compared to Judy, they are rather trivially implemented: these are hash arrays with a doubly linked list inside each element in case of hash collisions. PHP arrays are stored in PHP variables, i.e. pointers to zval structures. In most cases, this is exactly what is required of them, but there are exceptions.
To demonstrate why we decided to use Judy, we will conduct comparative testing of Judy and PHP arrays. As an interface to Judy from PHP, we use the php-judy module , which implements the Judy class with the implementation of the ArrayAccess interface. In the test, create arrays of the form integer -> integer (array (), Judy :: INT_TO_INT, Judy :: INT_TO_MIXED) or integer-> boolean (Judy :: BITSET) and fill them with elements with sequential keys.
To begin, measure the write speed to arrays with the help of a similar code:
<?php $arr = array(); for ($i = 0; $i < 10000000; $i++) { $arr[] = 1; } ?> 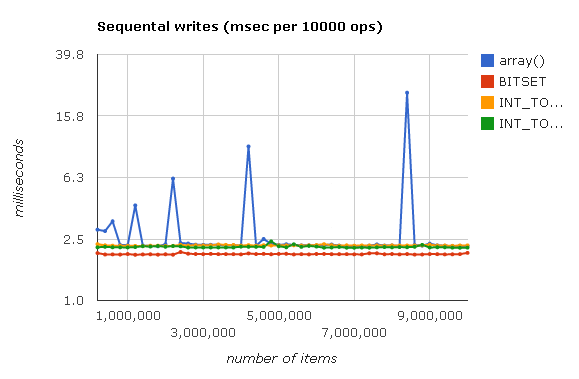
See interactive schedule here .
Peaks when writing array () are caused by doubling the size of the array and rebuilding it when filling all the elements of the hash. The small elevations in the Judy graphs can be explained by the measurement error.
From the graph it is clear that different types of judy are approximately equal in speed to the built-in array. The only exception is BITSET (Judy1), which is slightly faster.
Then measure the sequential read speed from arrays:
<?php /* …*/ /* , */ $arr = array(); for ($i = 0; $i < 10000000; $i++) { $val = $arr[$i]; } ?> 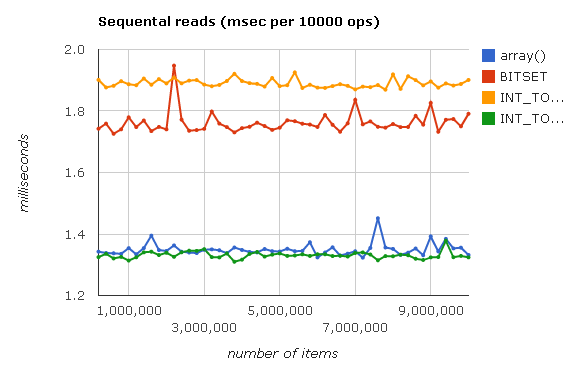
See interactive schedule here .
It can be seen from the graph that when reading Judy :: BITSET and Judy :: INT_TO_INT, they slightly lose to the built-in PHP array. This is because these arrays store bits and integers, respectively, and not PHP variables (i.e., zval). It is the overhead of creating and filling out variables that robs us of the performance gain.
On the other hand, array () and Judy :: INT_TO_MIXED both have PHP variables inside, and they don’t have to waste time creating them, so they are roughly equal in speed.
Finally, measure the memory consumption when filling in arrays and get the following graph:
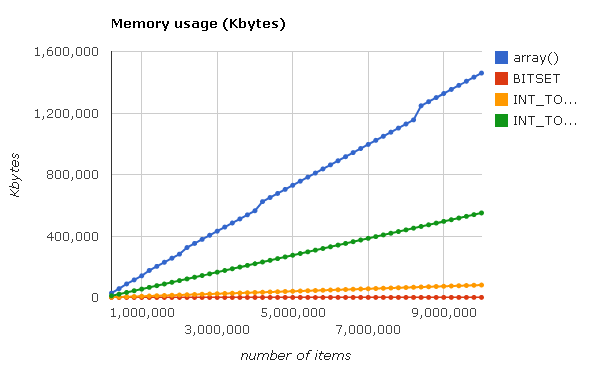
See interactive schedule here .
As you can see from the graph, the difference in memory consumption between PHP arrays and Judy1 / JudyL is huge, and for us this is the main criterion in this case, because we can easily sacrifice some of the speed when reading from the array, having received in return the opportunity to work with much larger arrays that previously did not fit into the server’s RAM at all.
Thus, the use of Judy-arrays in PHP is justified when solving problems associated with processing large data arrays, especially integers and bits. In terms of read and write speeds, Judy arrays are not too different from the built-in arrays, but because of the differences in implementation, they use memory much more efficiently.
Anticipating your questions, we note that, despite its clear advantages, Judy arrays are unlikely to be able to replace regular arrays in PHP, if only because the latter can contain both integer indices and lowercase ones, while in Judy this is implemented using two different types of arrays.
Source: https://habr.com/ru/post/175085/
All Articles