Ranking in Yandex: how to put machine learning on stream (post # 2)
From this post you will learn:
- Why do we need to select a new ranking formula very often, and how exactly does FML help us in this;
- How we develop new factors and evaluate their effectiveness.


Selection of ranking formula
It's one thing to pick up a formula once, and quite another to do it very often. And we will talk about the reasons why the second is so necessary in our realities.
')
As already mentioned , the Internet is changing rapidly and we need to constantly improve the quality of search. Our developers are constantly looking for new factors that could help us with this. Our assessors evaluate thousands of documents every day in order to promptly teach algorithms for new types of patterns appearing on the Internet and take into account changes in the usefulness of previously evaluated documents. The search robot collects a lot of fresh documents on the Internet, which constantly changes the average values of factors. Values can change even with fixed documents, as the algorithms for calculating factors and their implementation are constantly being improved.
To quickly take into account in the ranking formula this stream of changes, we need a whole technological conveyor. It is desirable that he did not require the participation of a person or was as simple as possible for him. And it is very important that making some changes does not interfere with the assessment of the usefulness of others. This is the pipeline that became FML. While MatrixNet acts as the “brain” of machine learning, FML is a convenient service based on it, the use of which requires much less specialized knowledge and experience. This is due to what is achieved.
Firstly, for each specific task with which the developer comes to us, the FML recommends the launch parameters of MatrixNet, which best suit the conditions and constraints of the task. The service itself selects settings that are optimal for a specific scope of assessments — for example, it helps to select the objective function ( pointwise or pairwise ) depending on the size of the training sample.
Secondly, FML provides transparent multitasking. Each iteration of formula selection is a multi-hour calculation that requires a full load of several dozen servers. As a rule, a dozen different formulas are selected at the same time, and the FML controls the load and ensures that each developer isolates his calculations from those of his colleagues so that they do not interfere with each other.
Thirdly, unlike Matriksnet, which needs to be started manually, FML provides distributed execution of resource-intensive tasks on a cluster. This includes the use of a single and most recent version of machine learning libraries by everyone, the layout of the program for all machines, the handling of failures that have occurred, the preservation of calculations already performed, and verification of the results in case of restarting calculations.
Finally, we took advantage of the fact that on computationally demanding tasks, you can get very significant performance gains if you run them on graphics processors (GPUs) instead of general purpose processors (CPUs). To do this, we adapted Matriksnet for GPU, due to which we received more than 20-fold gain in speed of calculations per unit cost of equipment. The features of our implementation of the decision tree construction algorithm allow us to use the high degree of parallelism available on the GPU. Due to the fact that we retained the software interfaces used by FML, we were able to provide our colleagues working on the factors with new computational capabilities without changing the usual development processes.
A few words about the GPU
In general, the advantage of GPU processors over the CPU is revealed on tasks with a large proportion of floating-point calculations, and machine learning is not distinguished from them. Computational performance is measured in IOPS for integer calculations and FLOPS for floating point calculations. And, if we take out for brackets all the costs of I / O, including communication with memory, it is precisely in the FLOPS parameter that the graphics processors have long gone far ahead compared to conventional ones. On some classes of tasks, the performance gain compared to general-purpose processors (CPUs) is hundreds of times.
But precisely because not all popular algorithms are suitable for the computing architecture of the GPU and not all programs need a large number of floating point calculations, the entire industry continues to use the CPU, and does not switch to the GPU.
But precisely because not all popular algorithms are suitable for the computing architecture of the GPU and not all programs need a large number of floating point calculations, the entire industry continues to use the CPU, and does not switch to the GPU.

About our GPU cluster and supercomputers
Right now, the performance of a GPU cluster in Yandex is 80 Tflops, but soon we plan to expand it to 300 Tflops. We do not call our cluster a supercomputer , although in essence it is one. For example, in terms of element base, it is very close to the Lomonosov supercomputer, the most powerful in Russia and Eastern Europe. A number of components in our case, even more modern. And although we are inferior to Lomonosov in the number of compute nodes (and therefore performance), after expansion, our cluster is likely to be included in the first hundred of the most powerful in the world TOP500 Supercomputer Sites world ranking and in the top five of the most powerful supercomputers in Russia .
Development of new factors and assessment of their effectiveness
Factors in ranking play an even more important role than the ability to select a formula. After all, the more diverse the signs will be to distinguish between different documents, the more effective the ranking function can be. In an effort to improve the quality of the search, we are constantly looking for what new factors could help us.
Their creation is a very complicated process. Not every idea stands the test of practice in it. Sometimes it can take several months to develop and set up a good factor, and the percentage of hypotheses that have been proven by practice is extremely small. Like Mayakovsky: "In gram production, in the year of labor . " For the first year of operation, FML for tens of thousands of checks of various factors with different combinations of parameters were allowed to be implemented only a few hundred.
For a long time in Yandex, in order to work on the factors, it was necessary, firstly, to deeply understand the search device in general and ours in particular, and, secondly, to have a good knowledge of machine learning and information search in general. The emergence of FML allowed to get rid of the first requirement, significantly reducing the threshold for entering the development of factors. The number of specialists who can now deal with it has increased by an order of magnitude.
But in a large team, the transparency of the development process was required. Previously, each was limited to only checks that he himself considered sufficient, and the quality was measured by eye. As a result, obtaining a good factor turned out to be rather an object of art. And if the factor hypothesis was rejected, then after the passage of time it was impossible to get acquainted with the tests for which the decision was made.
With the advent of FML, development of factors has become a standard, measurable and controllable process in a large team. There was a cross-transparency, when everyone could see what their colleagues were doing, and the ability to control the quality of previous experiments. In addition, we received such a quality control system of the produced factors, which allows for a poor result with a much lower probability than at the world's leading conferences in the field of information retrieval.
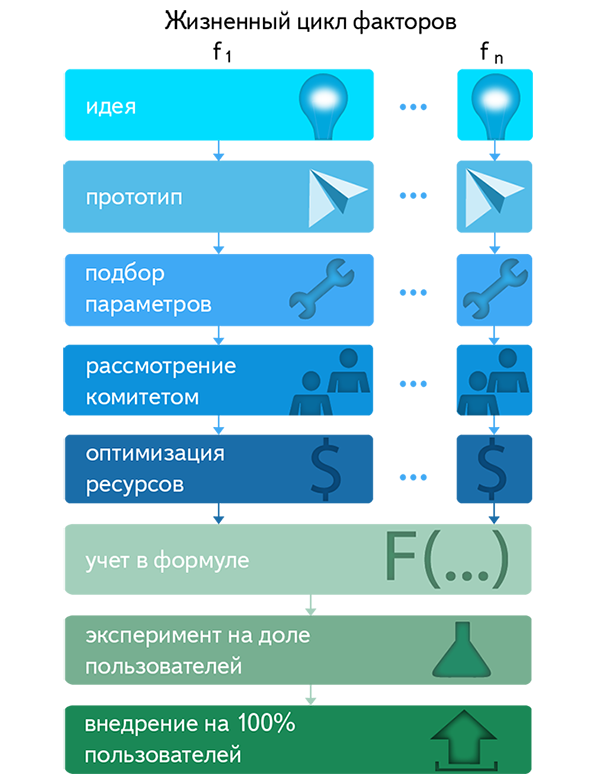
To assess the quality of the factor, we do the following. We divide (each time in a new random way) the set of assessments we have into two parts: the training and the test. According to the training estimates, we select two formulas - the old one (without the tested factor) and the new one (with it), and by the test formulas - we see which of these formulas is better. The procedure is repeated many times on a large number of different partitions of our estimates. In statistics, this process is called cross-validation . It allows us to make sure that the quality of the new formula is better than the old one. In machine learning, this method is known as dimension reduction using wrappers . If it turns out that, on average, a new formula gives a noticeable improvement in quality compared to the old one, a new factor may become a candidate for implementation.
But even if the factor has proved its usefulness, you need to understand what the price of its implementation and use. It includes not only the time that the developer spent on the elaboration of the idea, its implementation and customization. Many factors need to be calculated directly at the time of the search - for each of the thousands of documents found on request. Therefore, each new factor is a potential slowdown in the speed of the response of the search engine, and we make sure that it remains in a very rigid framework. This means that the introduction of each new factor should be ensured by an increase in the power of the cluster that responds to user requests. There are other hardware resources that cannot be used endlessly. For example, the cost of storing in memory of each additional byte per document on the search cluster is about $ 10,000 per year.
Thus, it is important for us to select from many potential factors only those in which the ratio of quality gains to equipment costs will be the best - and discard the rest. It is precisely in the measurement of the increase in quality and the assessment of the volume of additional costs that the task of the FML following the selection of formulas consists.
Price of measurement and its accuracy
According to our statistics, the assessment of the quality of factors before their introduction takes significantly more computational time than the selection of the formulas themselves. Including because the ranking formula needs to be repeatedly picked up for each factor. For example, over the past year, about 10 million machine hours were spent on about 50,000 checks, and about 2 million on the selection of ranking formulas. That is, most of the cluster time is spent on research, rather than on regular reassignment of formulas.
As in any mature market, each new improvement is given much harder than the previous one, and each next “nine” in quality is multiply more expensive than the previous one. We account for tenths and hundredths of a percent of the target quality metric (in our case, this is pFound ). In such conditions, quality measurement devices must be sufficiently accurate to confidently record even such small changes.
As in any mature market, each new improvement is given much harder than the previous one, and each next “nine” in quality is multiply more expensive than the previous one. We account for tenths and hundredths of a percent of the target quality metric (in our case, this is pFound ). In such conditions, quality measurement devices must be sufficiently accurate to confidently record even such small changes.
Speaking of hardware resources, we estimate three components: the computational cost, the disk size and the amount of RAM. Over time, we even developed “exchange rates”: how much we can degrade performance, how many bytes of disk or RAM are willing to pay for quality improvement by 1%. Memory consumption is estimated experimentally, the quality gain is taken from FML, and the decrease in performance is estimated from the results of individual load testing. However, some aspects cannot be estimated automatically - for example, does the factor not bring in a strong feedback. For this reason, there is expert advice, which has the right of veto on the introduction of the factor.
When it comes time to implement a formula built using new factors, we conduct A / B testing - an experiment on a small percentage of users. It is needed to make sure that the new rankings “like” them more than the current one. The final implementation decision is made based on custom quality metrics . Dozens of experiments are being conducted at Yandex at any time, and we are trying to make this process invisible to search engine users. Thus, we achieve not only the mathematical validity of the decisions made, but also the usefulness of innovations in practice.
So, FML allowed putting on stream development of factors in Yandex and enabled their developers to get an answer to the question of whether a new factor is good enough for consideration for implementation in a understandable and regulated manner and relatively small efforts. How we make sure that the quality of the factor does not degrade over time, we will tell in the next - last - post . From it you will learn about where our machine learning technology is still applicable .
Source: https://habr.com/ru/post/174975/
All Articles