Past performance growth: the end of the frequency race, multi-core and why progress is bogged down in one place

KDPV: one of the attempts of Intel to create a demotivator :)
Almost 10 years ago, Intel announced the closure of Tejas and Jayhawk projects — successors to the NetBurst architecture (Pentium 4) in the direction of increasing the clock frequency. This event actually marked the transition to the era of multi-core processors. Let's try to understand what caused it, and what brought results.
In order to understand the causes and extent of what happened with this transition, I suggest looking at the following graph. It shows the number of transistors, clock frequency, power consumption and the degree of parallelism at the instruction level ( ILP ).
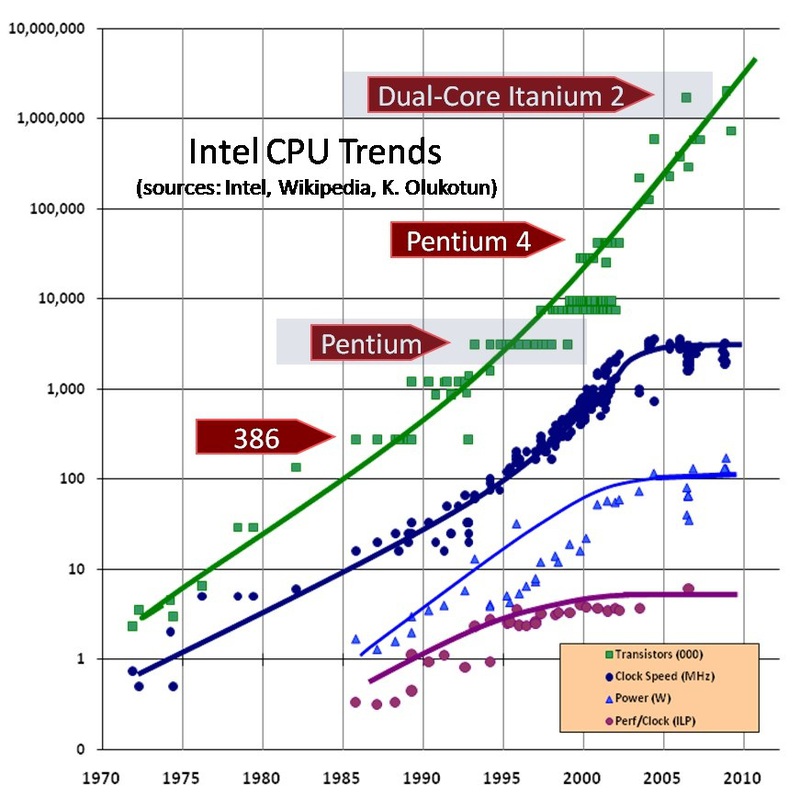
Doubling the number of transistors every few years, known as Moore's law, is not the only pattern. You can see that before the 2000th year, the clock frequency and power consumption grew according to similar laws. The implementation of Moore’s law over the decades was possible because the size of transistors kept decreasing and decreasing, following another law known as Dennard's scaling . According to this law, in ideal conditions, such a decrease in transistors with a constant processor area did not require an increase in power consumption.
')
As a result, if the first 8086 processor with a frequency of 8MHz consumed less than 2W, then a Pentium 3 operating at 1GHz consumed 33W. That is, the power consumption increased 17 times, and the clock frequency during the same time increased 125 times. Note that the performance during this time has grown much stronger, because Comparison of frequencies does not take into account such things as the appearance of L1 / L2 cache and out-of-order execution, as well as the development of superscalar architecture and pipelining. This time can rightly be called the golden age: the scaling of the technical process (reducing the size of transistors) turned out to be an idea that ensured a steady increase in productivity for several decades.
The combination of technological and architectural achievements led to the fact that Moore's law was carried out until the mid-2000s, where the turning point occurred. At 90nm, the gate of the transistor becomes too thin to prevent leakage current, and the power consumption has already reached all imaginable limits. The power consumption up to 100W and the cooling system weighing up to half a kilogram I associate more with a welding machine, but with anything, but not with a complex computing device.
Intel and other companies have been able to make some progress in terms of increasing productivity and reducing energy consumption thanks to innovative solutions, such as using hafnium oxide, switching to Tri-Gate transistors, etc. But each such improvement was only a one-time, and could not even closely compare with what was achieved simply by reducing the transistors. If from 2007 to 2011 the processor clock speed increased by 33%, from 1994 to 1998 this figure was 300%.
Turn towards Multicore
For the past 8 years, Intel and AMD have focused their efforts on multi-core processors as a solution for increasing performance. But there are a number of reasons for believing that this line of action has practically been exhausted. First of all, an increase in the number of cores never gives an ideal increase in performance. The performance of any parallel program is limited to the part of the code that cannot be parallelized. This limitation is known as Amdal’s law and is illustrated in the following graph.

One should also not forget about such reasons as, for example, the difficulty of effectively loading a large number of cores, which also worsen the picture.
A good example of how using more cores results in lower performance could be the AMD Bulldozer. This microprocessor was designed with the expectation that shared cache and logic would save chip space and ultimately place more cores. But in the end it turned out that when using all the cores, the power consumption of the chip forces to significantly reduce the clock frequency, and the slow shared cache reduces performance even more. Despite the fact that, overall, it was a good processor, an increase in the number of cores didn’t even yield the expected performance. And AMD is not the only ones who have encountered this problem.
Another reason why adding new kernels doesn’t help solve the problem - application optimization. There are not many tasks that, like processing bank transactions, for example, can be easily parallelized to virtually any number of cores.
Some scientists (with arguments of varying degrees of persuasiveness) believe that the tasks of the real world, like iron, have a natural parallelism, and all that remains is to create a parallel model of computation and architecture. But most of the known algorithms used for practical tasks are consistent in nature. Their parallelization is not always possible, expensive and does not give the desired high results. This is especially noticeable if you look at computer games. Game developers, although they are making progress in the direction of loading multi-core processors, but they are moving in this direction very slowly. There are not many games that, like the last parts of Battlefield, can load all cores with work. And, as a rule, such games were created from the very beginning with the possibility of using multi-core as the main goal.
(I admit, I cannot verify the information about Battlefield. I have neither the game itself nor the computer on which to play it. :))
We can say that now for Intel or AMD, adding new cores is a simpler task than using them for software developers .

Appearances and restrictions Manycore
The end of the era of scaling technical process led to the fact that a large number of companies engaged in the development of specialized processor cores. If earlier, in an era of rapid productivity growth, general-purpose processor architectures practically crowded out specialized co-processors and expansion cards from the market, then with a slowdown in productivity growth, specialized solutions began to gradually win back their positions.
Despite the statements of a number of companies, specialized manycore chips in no way violate Moore's law and are no exception to the realities of the semiconductor industry. The limitations of power consumption and parallelism are relevant for them just as they are for any other processors. What they offer is a choice in favor of a less universal, more specialized architecture capable of showing better performance on a narrow circle of tasks. Also, such solutions are less burdened with restrictions on power consumption - the limit for Intel's CPUs is 140W, while the older models of Nvidia video cards are in the region of 250W.
Intel's MIC (Many Integrated Cores) architecture is partly an attempt to take advantage of a separate memory interface and create a giant ultra-parallel number processor. AMD, meanwhile, is focusing its efforts on less demanding tasks, developing the architecture of GCN (Graphics Core Next). Despite what market segment these solutions are tagged in, they all inherently offer specialized co-processors for a number of tasks, one of which is graphics.
Unfortunately, this approach will not solve the problem. The integration of specialized units into a processor chip or their placement on expansion cards can improve performance per watt of power consumption. But the fact that the size of transistors decreased and decreased, while their power consumption and clock frequency did not, led to the emergence of a new concept - dark silicon (dark silicon). This term is used to refer to a large part of the microprocessor, which can not be used, while remaining within the framework of the permissible power consumption.
Research into the future of multi-core devices shows that regardless of how a microprocessor is structured and what its topology is, the increase in the number of cores is seriously limited by power consumption. Given the low productivity gains, the addition of new cores does not provide sufficient advantages to justify the need and recoup the further improvement of the technical process. And if you look at the scale of the problem and how long it has required a solution, it becomes clear that there is no need to expect a radical or even incremental solution to this problem from typical academic or industrial research.
We need to find a new idea how to use the huge number of transistors that Moore’s law provides. Otherwise, the economic component of the development of a new process technology will collapse, and Moore's law will cease to be fulfilled even before it reaches its technological limit.
Over the next few years, we will probably still see 14nm and 10nm chips. Most likely, 6-8 cores will become commonplace for any computer user, quad-core processors will penetrate almost everywhere, and we will see even closer integration of CPU and GPU.
But it is unclear what happens next. Each successive improvement in performance appears to be extremely insignificant compared with the growth that took place in past decades. Due to the growth of leakage currents, the Dennard law has ceased to be implemented, and a new technology capable of providing an equally steady increase in productivity is not observed.
In the following sections, I will talk about how developers are trying to solve this problem, about their short-term and more distant plans.
Source: https://habr.com/ru/post/174719/
All Articles