Full text search in MongoDB
This article will discuss one of the new features of MongoDB version 2.4 - full-text search. Most of this article will be a free translation of documentation, which, by the way, is very detailed, but scattered. Here everything will be brought together. Since this seemed to me a little for a full-fledged article, I decided to compare MongoDB with another popular text search program - Sphinx. My comparison will be very superficial, since I have not worked with the Sphinx before. I will create a table with 16,000,000 entries and see who is faster.

If you are interested in a comparison, then it is at the very end, and here I’ll tell you how to create a text index in Mongo and what can be done with it.
')
Previously, you could use either regular expressions or arrays of your own and indexed arrays with words to search for text in a mongee. The main disadvantage of the search for regular expressions was that it could not effectively use indexes for all queries, and nontrivial regular expressions were difficult to write. The index was used well when the regular expression indicated to find something at the very beginning of the line and in several other cases. Another option with an index created by the array of words obtained after the separation of sentences, bypassed this drawback, but was not convenient.
Now there is absolutely nothing to do to get a quick search on the text. We create a text index, make a request, and the system removes the stop words itself, makes tokens, stemming, and puts down a numerical characteristic indicating the relevance of the result. For stemming used by Stemmer Porter . The list of stop words can be viewed on the githaba - for example, for the Russian language .
Let's start with the result that can be obtained:
As you can see, Mongo found sentences where the word “sword” was found most often, as well as a sentence where the word “sword” was changed at the word
Text search is still in test mode, so you need to explicitly specify the appropriate mongod option at startup:
The main command to create an index is:
after which all text in the subject and content fields of the selected collection will be indexed
By default, an index is created for the English language; to change this, the default_language option must be specified:
it is also possible to create an index that will be applied to each document by the language specified in the specified field of the document - documentation
You can also create an index that will search through all the fields in the document.
The command to create an index that will calculate the weight of the result, depending on the weight of the field specified during creation:
Learn more about creating indexes.
A new command has been added that allows you to search by text - “text”:
"Text" - command, "sword" - the desired word
If you specify several words separated by a space for the search, they will be combined by the logical OR operator (options for logical AND not)
To find an exact match with a given word or expression, it is necessary to put in quotes:
If it is necessary to exclude texts with a certain word from the results, then in the query it is enough to put "-" in front of this word, for example:
The limit on the number of results is given by the limit option:
Returned fields are set by the project option:
In order to search documents with a specified field, you need to set the filter option:
Read more
Consider the search result:
cut out part of the brackets
Here:
queryDebugString - the documentation does not say what it is, but probably these are words after stemming
language - the language that was used to search
results - list of results
score - a characteristic that shows how exactly the query matches the result
stats dictionary - additional information
nscanned - how many documents are found using the index
nscannedObjects - documents scanned without using an index (the smaller this parameter is, the better)
n - the number of returned results
nfound - the number of matches
timeMicros - search duration and microseconds
Read more
The text and text2 tables are the same:
As can be seen from the results, the search with a regular expression was completed in 31 milliseconds, and the search by text index in 151 microseconds, which is 200 times smaller.
The comparison was made on Ubuntu 12.10 OS (Core i5, 8GB RAM, Hard drive (without raid)). Candidates: MongoDM 2.4.1 and Sphinx 2.0.6. In Monge and Mysql, tables of the form id, text were created. The tables were identical and contained 16 million records. A text index was created in Monge. The Sphinx also configured an index for text search, additionally included options for using a sheet of stop words and a stemming algorithm. To interact with the contestants, Pythonic clients — sphinxapi and pymongo — were used.
The test was to find thousands of words in the table. A “warm-up” and several re-runs were performed. In the Sphinx, no additional settings were included with the exception of stemming, stop words and an increase in available memory. The memory usage of the programs is approximately identical, 2.2 GB used the Sphinx, 2.5 GB used Mongo.
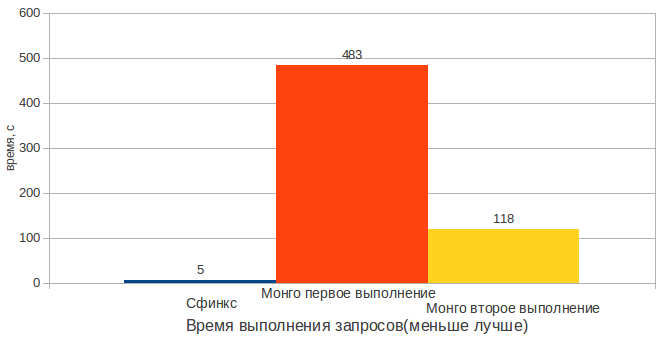
As can be seen from the results Mongo loses. Because of the specific work with the OP, Mongo searches a second time faster than the first. This is due to the fact that Mongo stores in memory only the data in demand. In the first test run, the index has not yet been loaded into memory. But even in the case of a loaded index, Mongo runs more than 20 times slower.
When searching for smaller tables, the gap is narrowing, but still lies in the area of 10 times the advantage of the Sphinx.
It is also worth noting that the text index in Monge uses about 2 times more memory than the indexed data to store itself.
With an impressive margin in the search for text wins Sphinx.
In defense of Mongo, one can say that:
The new function of MongoDB will not significantly change the balance of power in the field of data storage.
If you are interested in a comparison, then it is at the very end, and here I’ll tell you how to create a text index in Mongo and what can be done with it.
')
Previously, you could use either regular expressions or arrays of your own and indexed arrays with words to search for text in a mongee. The main disadvantage of the search for regular expressions was that it could not effectively use indexes for all queries, and nontrivial regular expressions were difficult to write. The index was used well when the regular expression indicated to find something at the very beginning of the line and in several other cases. Another option with an index created by the array of words obtained after the separation of sentences, bypassed this drawback, but was not convenient.
Now there is absolutely nothing to do to get a quick search on the text. We create a text index, make a request, and the system removes the stop words itself, makes tokens, stemming, and puts down a numerical characteristic indicating the relevance of the result. For stemming used by Stemmer Porter . The list of stop words can be viewed on the githaba - for example, for the Russian language .
List of supported languages:
danish
dutch
english
finnish
french
german
hungarian
italian
norwegian
portuguese
romanian
russian
spanish
swedish
turkish
dutch
english
finnish
french
german
hungarian
italian
norwegian
portuguese
romanian
russian
spanish
swedish
turkish
Let's start with the result that can be obtained:
db.text.runCommand( "text" , { search: "",project:{text:1,_id:0},limit: 3 } ) Result
{ "queryDebugString" : "||||||", "language" : "russian", "results" : [ { "score" : 1, "obj" : { "text" : " ; " } }, { "score" : 0.85, "obj" : { "text" : " ; " } }, { "score" : 0.8333333333333334, "obj" : { "text" : " , , - , , " } } ], "stats" : { "nscanned" : 168, "nscannedObjects" : 0, "n" : 3, "nfound" : 3, "timeMicros" : 320 }, "ok" : 1 } As you can see, Mongo found sentences where the word “sword” was found most often, as well as a sentence where the word “sword” was changed at the word
Connect text search
Text search is still in test mode, so you need to explicitly specify the appropriate mongod option at startup:
mongod --setParameter textSearchEnabled=true Creating a text index
The main command to create an index is:
db.collection.ensureIndex( {subject: "text", content: "text"} ) after which all text in the subject and content fields of the selected collection will be indexed
By default, an index is created for the English language; to change this, the default_language option must be specified:
db.collection.ensureIndex( { content : "text" }, { default_language: "russian" }) it is also possible to create an index that will be applied to each document by the language specified in the specified field of the document - documentation
You can also create an index that will search through all the fields in the document.
The command to create an index that will calculate the weight of the result, depending on the weight of the field specified during creation:
db.blog.ensureIndex( {content: "text",keywords: "text", about: "text"}, {weights: { content: 10,keywords: 5, },name: "TextIndex" }) Learn more about creating indexes.
Search query
A new command has been added that allows you to search by text - “text”:
db.collection.runCommand( "text", { search: "" } ) "Text" - command, "sword" - the desired word
If you specify several words separated by a space for the search, they will be combined by the logical OR operator (options for logical AND not)
To find an exact match with a given word or expression, it is necessary to put in quotes:
db.quotes.runCommand( "text", { search: "\" \"" } ) If it is necessary to exclude texts with a certain word from the results, then in the query it is enough to put "-" in front of this word, for example:
db.quotes.runCommand( "text" , { search: " -" } ) The limit on the number of results is given by the limit option:
db.quotes.runCommand( "text", { search: "tomorrow", limit: 2 } ) Returned fields are set by the project option:
db.quotes.runCommand( "text", { search: "tomorrow", project: { "src": 1 } } ) In order to search documents with a specified field, you need to set the filter option:
db.quotes.runCommand( "text", { search: "tomorrow", filter: { speaker : "macbeth" } } ) Read more
Result analysis
Consider the search result:
cut out part of the brackets
{ "queryDebugString" : "||||||||", "language" : "russian", "results" : "score" : 1.25, "obj" : { "text" : "- " "score" : 0.9166666666666667, "obj" : { "text" : " , " "score" : 0.8863636363636365, "obj" : { "text" : " … - " "stats" : { "nscanned" : 145, "nscannedObjects" : 0, "n" : 3, "nfound" : 3, "timeMicros" : 155 }, "ok" : 1 } Here:
queryDebugString - the documentation does not say what it is, but probably these are words after stemming
language - the language that was used to search
results - list of results
score - a characteristic that shows how exactly the query matches the result
stats dictionary - additional information
nscanned - how many documents are found using the index
nscannedObjects - documents scanned without using an index (the smaller this parameter is, the better)
n - the number of returned results
nfound - the number of matches
timeMicros - search duration and microseconds
Read more
Text search vs $ regex + index
db.text.runCommand( "text" , { search: "",project:{text:1,_id:0}} ).stats { "nscanned" : 77, "nscannedObjects" : 0, "n" : 77, "nfound" : 77, "timeMicros" : 153 } db.text2.find( { text: { $regex: ''} }).explain(); { "cursor" : "BtreeCursor text_1 multi", "n" : 5, "nscannedObjects" : 5, "nscanned" : 15821, "nscannedObjectsAllPlans" : 5, "nscannedAllPlans" : 15821, "indexOnly" : false, "millis" : 31, "indexBounds" : { "text" : [["",{}], [ //, // ] ] }, } The text and text2 tables are the same:
their statistics
> db.text.stats ()
{
"Ns": "text_test.text",
"Count": 15821,
"Size": 3889044,
“AvgObjSize”: 245.8153087668289,
"StorageSize": 6983680,
"NumExtents": 5,
"Nindexes": 2,
"LastExtentSize": 5242880,
"PaddingFactor": 1,
"SystemFlags": 0,
"UserFlags": 1,
"TotalIndexSize": 7358400,
"IndexSizes": {
"_id_": 523264,
"Text_text": 6835136
},
"Ok": 1
}
> db.text2.stats ()
{
"Ns": "text_test.text2",
"Count": 15821,
"Size": 2735244,
“AvgObjSize”: 172.8869224448518,
"StorageSize": 5591040,
"NumExtents": 6,
"Nindexes": 2,
"LastExtentSize": 4194304,
"PaddingFactor": 1,
"SystemFlags": 0,
"UserFlags": 0,
"TotalIndexSize": 3008768,
"IndexSizes": {
"_id_": 523264,
"Text_1": 2485504
},
"Ok": 1
}
The difference is due to different indices, and the data is exactly the same.
{
"Ns": "text_test.text",
"Count": 15821,
"Size": 3889044,
“AvgObjSize”: 245.8153087668289,
"StorageSize": 6983680,
"NumExtents": 5,
"Nindexes": 2,
"LastExtentSize": 5242880,
"PaddingFactor": 1,
"SystemFlags": 0,
"UserFlags": 1,
"TotalIndexSize": 7358400,
"IndexSizes": {
"_id_": 523264,
"Text_text": 6835136
},
"Ok": 1
}
> db.text2.stats ()
{
"Ns": "text_test.text2",
"Count": 15821,
"Size": 2735244,
“AvgObjSize”: 172.8869224448518,
"StorageSize": 5591040,
"NumExtents": 6,
"Nindexes": 2,
"LastExtentSize": 4194304,
"PaddingFactor": 1,
"SystemFlags": 0,
"UserFlags": 0,
"TotalIndexSize": 3008768,
"IndexSizes": {
"_id_": 523264,
"Text_1": 2485504
},
"Ok": 1
}
The difference is due to different indices, and the data is exactly the same.
As can be seen from the results, the search with a regular expression was completed in 31 milliseconds, and the search by text index in 151 microseconds, which is 200 times smaller.
MongoDB vs Sphinx
The comparison was made on Ubuntu 12.10 OS (Core i5, 8GB RAM, Hard drive (without raid)). Candidates: MongoDM 2.4.1 and Sphinx 2.0.6. In Monge and Mysql, tables of the form id, text were created. The tables were identical and contained 16 million records. A text index was created in Monge. The Sphinx also configured an index for text search, additionally included options for using a sheet of stop words and a stemming algorithm. To interact with the contestants, Pythonic clients — sphinxapi and pymongo — were used.
The test was to find thousands of words in the table. A “warm-up” and several re-runs were performed. In the Sphinx, no additional settings were included with the exception of stemming, stop words and an increase in available memory. The memory usage of the programs is approximately identical, 2.2 GB used the Sphinx, 2.5 GB used Mongo.
As can be seen from the results Mongo loses. Because of the specific work with the OP, Mongo searches a second time faster than the first. This is due to the fact that Mongo stores in memory only the data in demand. In the first test run, the index has not yet been loaded into memory. But even in the case of a loaded index, Mongo runs more than 20 times slower.
When searching for smaller tables, the gap is narrowing, but still lies in the area of 10 times the advantage of the Sphinx.
It is also worth noting that the text index in Monge uses about 2 times more memory than the indexed data to store itself.
Conclusion
With an impressive margin in the search for text wins Sphinx.
In defense of Mongo, one can say that:
- Mongo has many more functions besides text search.
- its easier to scale horizontally, while improving performance
- text search still in test mode
- text search in Mongo is simpler than in the Sphinx and requires a few hours less to learn
The new function of MongoDB will not significantly change the balance of power in the field of data storage.
Source: https://habr.com/ru/post/174457/
All Articles