Processing and classification of requests. Part One: Query Parser
What does the request processing department do in Mail.Ru Search? If in one sentence, we try to “understand” the request, that is, we prepare the request for the search, we bring it into a form suitable for interacting with our index, ranking, mixes and other components. If you want to know more about our work - welcome under cat. In this post I will talk about one of the areas of our work - the query parser.
The figure shows the structure of the search service. The parts of the system in which we work are highlighted in pink.

')
Fig. 1. Our place in the search
The frontend provides the user with a form for entering a request, when ready, the request is sent to MetaSM, where it falls into the Query Parser, which analyzes it and classifies it. Then the query, enriched with additional parameters, is transmitted in the form of a tree to the backends, where, on the basis of this tree, the relevant query data is extracted from the index to the final processing of the ranking.
Before the request is submitted to the search system, it is processed by two more components. The first is sadzhesty, a service that responds to virtually every keystroke, suggesting suitable, in his opinion, options for continuing the query. The second is a spell checker to whom the request is sent after sending: it analyzes the request for typos.
The navigation base is shown separately based on the functionality; in fact, it is integrated into the query parser, but more on that later.
Why do we need any classification of the request and preliminary analysis? The reason is that different classes of queries require different data, different ranking formulas, different visual representations of the results.
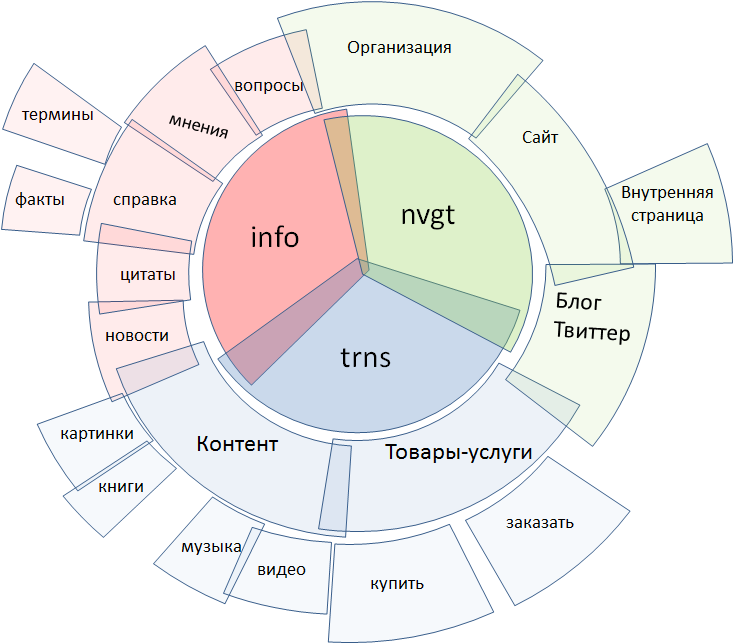
Fig. 2. Varieties of requests
Traditionally, all search queries are divided into three classes:
● informational
● navigation
● transactional
Each of them, in turn, breaks up into smaller classes. This diagram does not pretend to be complete, the process of segmentation of the entire set of requests is, in fact, fractal - it is rather a matter of patience and resources. Here are only the most basic elements.
Transactional requests include searching for content contained on the Internet and searching for objects that are "offline", that is, above all, various goods and services. Navigation queries - search for explicitly specified sites, blogs and microblogs, personal pages, organizations. Informational is the broadest class of queries in terms of meaning, everything else applies to it: news, reference queries on facts and terms, a search for opinions and feedback, answers to questions, and much more.
Immediately, I note that a single request often has signs of several classes at once. Therefore, classification is not the creation of a tree structure, in each cell of which a part of the request falls, but rather tagging, that is, endowing the request with additional properties.

Fig. 3. Frequency distribution of different classes of queries
By estimating the sizes of various classes of queries, it is clear that a small number of classes contain a large proportion of the query flow, followed by a long tail of decreasing fragments of the query flow. The narrower the topic, the fewer requests for it and the more such topics.
From a practical point of view, this means that we do not strive to classify absolutely all requests - rather, we are trying to pinch the most important requests from the general flow of requests. As a rule, the criterion for choosing a class is its frequency, but not only: it can be requests that we can process, it is interesting to visualize the results, and so on.
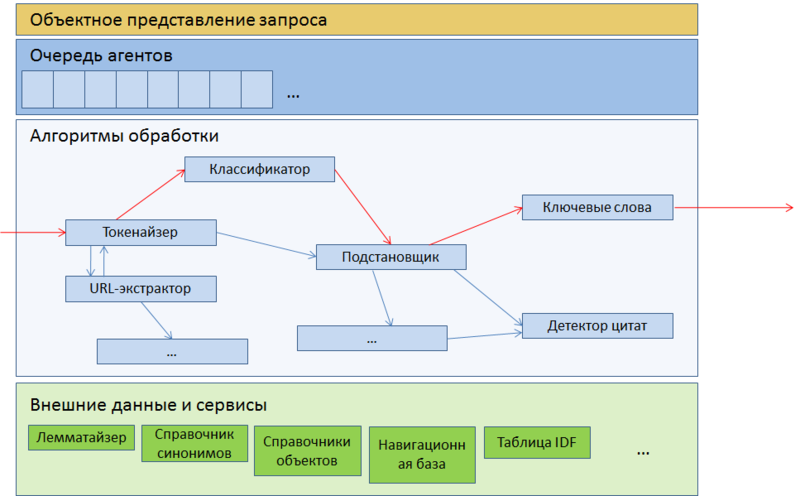
Fig. 4. Architecture of the query parser
A parser is a queue of agents, each of which performs some more or less atomic action on the request, starting from breaking it up into words and other regular entities like URLs and phone numbers, and ending with complex classifiers like a citation detector.
Agents lined up. Each request is run through this queue, and the results of the work of each agent affect the further logical path of the request — for example, a request classified as navigational does not fall into the processing of a citation detector. The request itself is presented here as a kind of message board on which each agent can leave a message, read the messages of other agents and, if necessary, change or cancel them. Upon completion, the request is sent to additional submasters, and is ultimately sent to backends, where all additional parameters written by agents are used as ranking factors.
The main data provider for the query parser are dictionaries. These are huge files containing grouped arrays of strings, each of which has a specific meaning.

Fig. 5. Dictionaries: a life example
The figure shows a fragment of one of the dictionaries, which contains the words most typical for the requests of the “Films” class. Each of these groups of words can be associated with a marker (in the figure it is surrounded by a green frame). It means that if the request contains such a fragment, the entire request will be flagged indicating that the movie is the subject of this request.
In the same dictionaries are synonyms (red frame in the figure). Thanks to them, if, for example, the query has the word “soundtrack”, then the query will be expanded with the phrases “audio track”, “sound track” and the abbreviation OST.
There are dozens of such dictionaries. The size of some of them is hundreds of thousands, even millions of similar lines. Based on them, the initial processing of the request, its colorization takes place, after which the more complex logic works.
Take three queries:
● Pirates of the Caribbean
● depth of the Caribbean
● consequences of the Caribbean crisis
From the point of view of text search, all of them are simply strings containing three words each, while from the point of view of the user, each of them has completely different meanings. Our goal is to inform the system as much as possible about these differences.
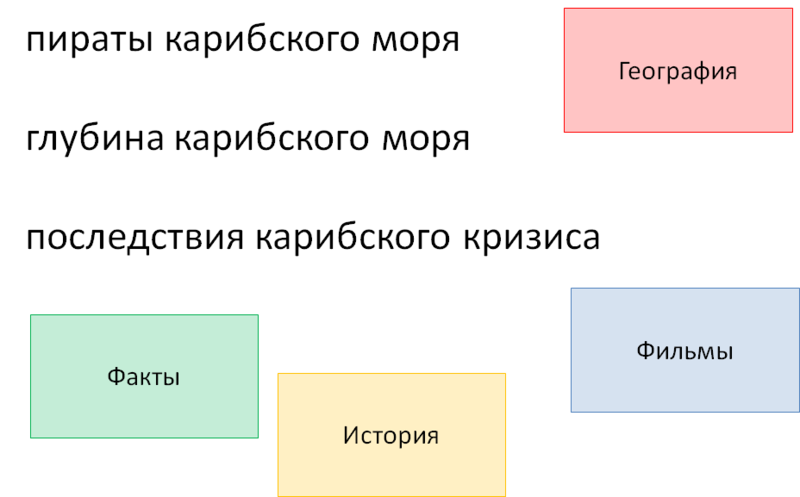
Fig. 6. Dictionaries and markers
The four dictionaries in the figure are chosen for clarity and do not quite correspond to the real ones. These dictionaries contain facts suitable for mixing, a dictionary with historical events, a dictionary with films and a dictionary with geographical objects. All the words and phrases of the query are run through these dictionaries, resulting in the following fragments:
● Pirates of the Caribbean is tagged as a movie with some kind of geography inside.
● The depth of the Caribbean is a certain objective fact.
● The aftermath of the Caribbean crisis contains a marker of fact, as evidenced by the word “aftermath”, and a historical event - the Caribbean crisis.
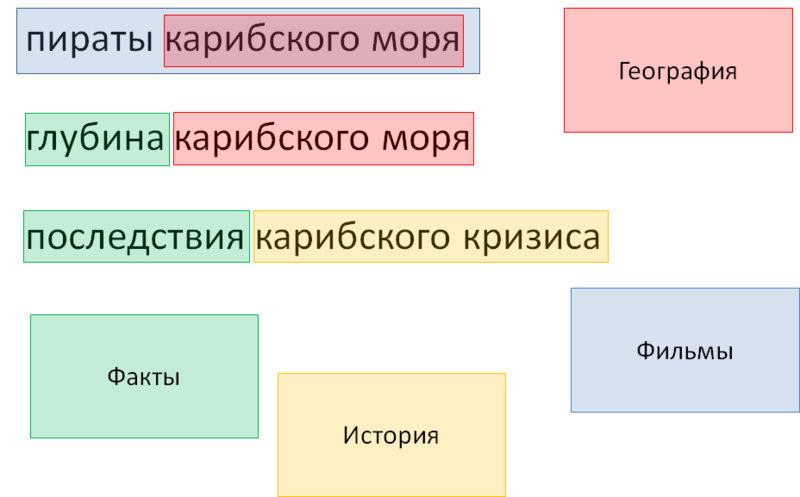
Fig. 7. Dictionaries and markers: intermediate result
At the final stage, we remove the geographical object included in the film so that it does not interfere with the sample. The need for such a deletion is also configured by syntax in the dictionary. This is called marker greed: as a rule (but not always), a large number of markers and the inclusion of one in the other means that the internal marker should be ignored.
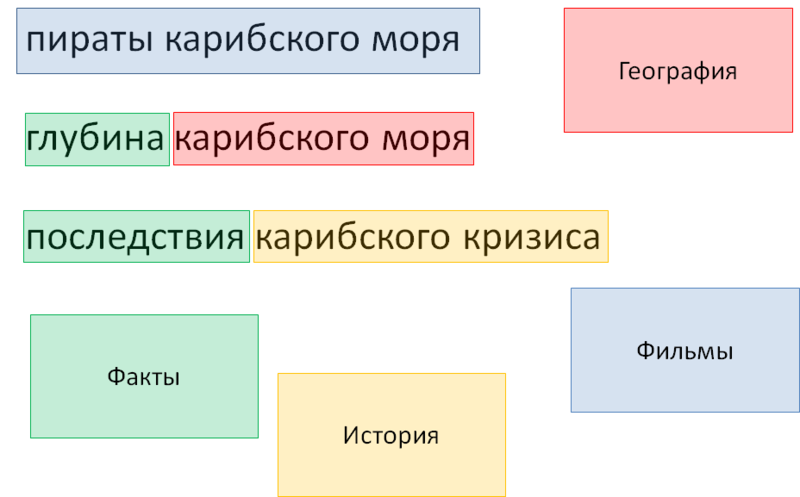
Fig. 8. Dictionaries and markers: summary
The contents of the dictionaries are divided into two large classes:
● Frequency expressions markers, describing a specific theme or intention of the user. Such dictionaries are compiled manually.
● Objects (movies, recipes, dishes, famous personalities, place names, etc.).
From the point of view of filling dictionaries, objects are of the greatest interest. There are several approaches here. The first is, again, to compile them manually. This is the best way to get data, but also the most time consuming.
Automatic creation of a dictionary of objects is a topic for a separate post, but briefly described, this is an intricate set of simple algorithms that, based on a small training sample of objects of a given type, selects from the log all queries containing objects of the same type, breaking each of these requests on the object and its context.

It should be noted that many requests are ambiguous: for example, on the request “download the hobbit” it is absolutely impossible to say exactly what the user wants to download — a film, a cartoon, a book or a game.
The final stage of the query parser is to transfer the received information to the ranking. Before this, there is an intersection of data about the request and about the structure and data from the index. In short, for each word of the query, lists of documents are extracted from the reverse index, which are then intersected by the rules specified by the structure of the query tree. The difficulty lies in the fact that all words have different weights, some words can be considered optional, the order of words, their forms in the query, the distances between them, and other properties matter. All the data received along with all the query flags are transferred to the ranking, where they become part of a multitude of factors determining the final search result.

Fig. 9. Request tree: Moscow Tel Aviv flights
Quotation queries are an example of a more complex classification that cannot be done qualitatively on the basis of dictionaries alone. Initially, when processing quotes, the query log was simply analyzed: it was revealed what quotations are there, how they differ. The main, most obvious signs of a quotation request are a large length, grammatical consistency of words, the presence of capital letters and punctuation marks. On the basis of these signs, the first agent was implemented, which, using manually selected coefficients and primitive if-then-else logic, calculated the probability that the request is a quote.
However, when there are a lot of factors, and it is no longer possible or even harmful to assess the influence of each of them manually, various machine inclusion algorithms are applied. When identifying quotes using the same code that is used in the ranking. The response to a quote query is not only the influence of this factor on the ranking, but also a change in the algorithm for gluing similar documents. In the case of a false trigger of the classifier, the result of which is an unsuccessful search as a whole, it is necessary to do a re-request, in which the request is no longer considered a quotation. Thus, the parser also affects the search algorithm as a whole.
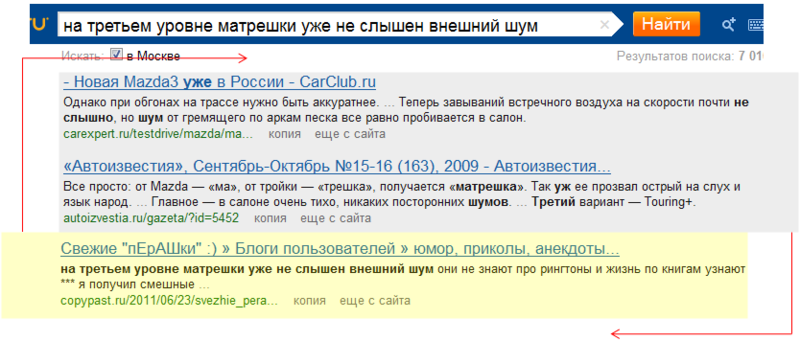
Fig. 10. Quotes inquiries
For machine learning, decision trees and methods based on Markov models are used. More complex methods are prohibitively expensive for real-time. Therefore, the clustering of requests or selection of objects is made in the preliminary processing, and not done on the fly.
I will tell you about navigation queries separately - wait for the continuation in the coming days. In addition, in the next series I will focus on spellchecker and sagesta.
If you have questions or useful experience that you would like to share, welcome to comments.
Mikhail Dolinin,
search request manager
Where are we, who are we and where is the parser?
The figure shows the structure of the search service. The parts of the system in which we work are highlighted in pink.
')
Fig. 1. Our place in the search
The frontend provides the user with a form for entering a request, when ready, the request is sent to MetaSM, where it falls into the Query Parser, which analyzes it and classifies it. Then the query, enriched with additional parameters, is transmitted in the form of a tree to the backends, where, on the basis of this tree, the relevant query data is extracted from the index to the final processing of the ranking.
Before the request is submitted to the search system, it is processed by two more components. The first is sadzhesty, a service that responds to virtually every keystroke, suggesting suitable, in his opinion, options for continuing the query. The second is a spell checker to whom the request is sent after sending: it analyzes the request for typos.
The navigation base is shown separately based on the functionality; in fact, it is integrated into the query parser, but more on that later.
Classes and query types
Why do we need any classification of the request and preliminary analysis? The reason is that different classes of queries require different data, different ranking formulas, different visual representations of the results.
Fig. 2. Varieties of requests
Traditionally, all search queries are divided into three classes:
● informational
● navigation
● transactional
Each of them, in turn, breaks up into smaller classes. This diagram does not pretend to be complete, the process of segmentation of the entire set of requests is, in fact, fractal - it is rather a matter of patience and resources. Here are only the most basic elements.
Transactional requests include searching for content contained on the Internet and searching for objects that are "offline", that is, above all, various goods and services. Navigation queries - search for explicitly specified sites, blogs and microblogs, personal pages, organizations. Informational is the broadest class of queries in terms of meaning, everything else applies to it: news, reference queries on facts and terms, a search for opinions and feedback, answers to questions, and much more.
Immediately, I note that a single request often has signs of several classes at once. Therefore, classification is not the creation of a tree structure, in each cell of which a part of the request falls, but rather tagging, that is, endowing the request with additional properties.
Distribution of topics
Fig. 3. Frequency distribution of different classes of queries
By estimating the sizes of various classes of queries, it is clear that a small number of classes contain a large proportion of the query flow, followed by a long tail of decreasing fragments of the query flow. The narrower the topic, the fewer requests for it and the more such topics.
From a practical point of view, this means that we do not strive to classify absolutely all requests - rather, we are trying to pinch the most important requests from the general flow of requests. As a rule, the criterion for choosing a class is its frequency, but not only: it can be requests that we can process, it is interesting to visualize the results, and so on.
Parser architecture
Fig. 4. Architecture of the query parser
A parser is a queue of agents, each of which performs some more or less atomic action on the request, starting from breaking it up into words and other regular entities like URLs and phone numbers, and ending with complex classifiers like a citation detector.
Agents lined up. Each request is run through this queue, and the results of the work of each agent affect the further logical path of the request — for example, a request classified as navigational does not fall into the processing of a citation detector. The request itself is presented here as a kind of message board on which each agent can leave a message, read the messages of other agents and, if necessary, change or cancel them. Upon completion, the request is sent to additional submasters, and is ultimately sent to backends, where all additional parameters written by agents are used as ranking factors.
Dictionaries
The main data provider for the query parser are dictionaries. These are huge files containing grouped arrays of strings, each of which has a specific meaning.
Fig. 5. Dictionaries: a life example
The figure shows a fragment of one of the dictionaries, which contains the words most typical for the requests of the “Films” class. Each of these groups of words can be associated with a marker (in the figure it is surrounded by a green frame). It means that if the request contains such a fragment, the entire request will be flagged indicating that the movie is the subject of this request.
In the same dictionaries are synonyms (red frame in the figure). Thanks to them, if, for example, the query has the word “soundtrack”, then the query will be expanded with the phrases “audio track”, “sound track” and the abbreviation OST.
There are dozens of such dictionaries. The size of some of them is hundreds of thousands, even millions of similar lines. Based on them, the initial processing of the request, its colorization takes place, after which the more complex logic works.
Markers
Take three queries:
● Pirates of the Caribbean
● depth of the Caribbean
● consequences of the Caribbean crisis
From the point of view of text search, all of them are simply strings containing three words each, while from the point of view of the user, each of them has completely different meanings. Our goal is to inform the system as much as possible about these differences.
Fig. 6. Dictionaries and markers
The four dictionaries in the figure are chosen for clarity and do not quite correspond to the real ones. These dictionaries contain facts suitable for mixing, a dictionary with historical events, a dictionary with films and a dictionary with geographical objects. All the words and phrases of the query are run through these dictionaries, resulting in the following fragments:
● Pirates of the Caribbean is tagged as a movie with some kind of geography inside.
● The depth of the Caribbean is a certain objective fact.
● The aftermath of the Caribbean crisis contains a marker of fact, as evidenced by the word “aftermath”, and a historical event - the Caribbean crisis.
Fig. 7. Dictionaries and markers: intermediate result
At the final stage, we remove the geographical object included in the film so that it does not interfere with the sample. The need for such a deletion is also configured by syntax in the dictionary. This is called marker greed: as a rule (but not always), a large number of markers and the inclusion of one in the other means that the internal marker should be ignored.
Fig. 8. Dictionaries and markers: summary
Types of dictionaries
The contents of the dictionaries are divided into two large classes:
● Frequency expressions markers, describing a specific theme or intention of the user. Such dictionaries are compiled manually.
● Objects (movies, recipes, dishes, famous personalities, place names, etc.).
From the point of view of filling dictionaries, objects are of the greatest interest. There are several approaches here. The first is, again, to compile them manually. This is the best way to get data, but also the most time consuming.
Automatic creation of a dictionary of objects is a topic for a separate post, but briefly described, this is an intricate set of simple algorithms that, based on a small training sample of objects of a given type, selects from the log all queries containing objects of the same type, breaking each of these requests on the object and its context.
It should be noted that many requests are ambiguous: for example, on the request “download the hobbit” it is absolutely impossible to say exactly what the user wants to download — a film, a cartoon, a book or a game.
The final stage of the query parser is to transfer the received information to the ranking. Before this, there is an intersection of data about the request and about the structure and data from the index. In short, for each word of the query, lists of documents are extracted from the reverse index, which are then intersected by the rules specified by the structure of the query tree. The difficulty lies in the fact that all words have different weights, some words can be considered optional, the order of words, their forms in the query, the distances between them, and other properties matter. All the data received along with all the query flags are transferred to the ranking, where they become part of a multitude of factors determining the final search result.
Fig. 9. Request tree: Moscow Tel Aviv flights
Quotes inquiries
Quotation queries are an example of a more complex classification that cannot be done qualitatively on the basis of dictionaries alone. Initially, when processing quotes, the query log was simply analyzed: it was revealed what quotations are there, how they differ. The main, most obvious signs of a quotation request are a large length, grammatical consistency of words, the presence of capital letters and punctuation marks. On the basis of these signs, the first agent was implemented, which, using manually selected coefficients and primitive if-then-else logic, calculated the probability that the request is a quote.
However, when there are a lot of factors, and it is no longer possible or even harmful to assess the influence of each of them manually, various machine inclusion algorithms are applied. When identifying quotes using the same code that is used in the ranking. The response to a quote query is not only the influence of this factor on the ranking, but also a change in the algorithm for gluing similar documents. In the case of a false trigger of the classifier, the result of which is an unsuccessful search as a whole, it is necessary to do a re-request, in which the request is no longer considered a quotation. Thus, the parser also affects the search algorithm as a whole.
Fig. 10. Quotes inquiries
For machine learning, decision trees and methods based on Markov models are used. More complex methods are prohibitively expensive for real-time. Therefore, the clustering of requests or selection of objects is made in the preliminary processing, and not done on the fly.
To be continued
I will tell you about navigation queries separately - wait for the continuation in the coming days. In addition, in the next series I will focus on spellchecker and sagesta.
If you have questions or useful experience that you would like to share, welcome to comments.
Mikhail Dolinin,
search request manager
Source: https://habr.com/ru/post/174321/
All Articles