Recommender system: we get user tags from social networks
Today I will talk about how you can use data about users from social networks to recommend web pages on a cold start . All the results in this article are purely experimental in nature and are not currently implemented in production. Here, as in the previous article , text-based elements will be used to analyze the text content of web pages.
First, some statistics to show the importance of this study. About 50% of users of our system are registered with the linking of social networking accounts vkontakte (VK) and facebook (FB). Moreover, of the registered via social networks, 71% fall on VK and 29% on FB.
The FB API and the VK API allow you to extract some data about the interests and preferences of the user. But not everything is as simple as it may seem. To obtain user data, you need to obtain special rights, the consent to which gives the user during registration in the system. This is where a subtle moment arises. On the one hand, we go to extract as much information about the user as possible. On the other hand, asking for too many rights is an arrogance that can scare a user away. We need to find a compromise - a delicate balance between the usefulness of the data obtained to improve the recommendations and the "amount" of credit of trust from the user who agrees so that we can get into his personal data.
Through long trials and mistakes for ourselves, we have found such a compromise, but this task is purely individual for each project, as many pros and cons are taken into account that are specific to the system.
')
In this article, I will discuss how user tags from the following categories can be used: games, books, music, movies and television. Such a choice of fields was due to the fact that tags are stored in their pure form and you can link each of these fields to the corresponding categories of Surfingbird. Probably, in the near future I will also tell you how you can handle other, not so obvious fields, such as languages (what languages the user speaks), devices (hardware and sofware, which he uses), education (place and level of education), bio or about (information about yourself), feeds (user posts).
I just want to make a reservation that the first problem we face is the strong sparseness of the data. Information in the games, books, music, movies or television fields is currently available for about 15% of users. But here you can say that, firstly, the ways to get user tags are not limited to the FB and VK APIs. For example, in the future we can also give the opportunity to specify them during registration and adjust in your profile. Secondly, even if for a small fraction of those who honestly indicated their interests, we can give recommendations from the first shows that “pleasantly surprise”, this will increase the overall loyalty to the system and this means our efforts are not in vain.
There are some differences in the data structure returned by API FB and VK. FB data is better structured. For example, each artist or film is stored in separate fields. On VK, they are written in an arbitrary text field, which makes tag selection difficult:
Example of JSON from FB:
Example of JSON from VK:
After some effort, the tags still manage to extract from unstructured VK data. Here is the top of the list of the most popular tags:
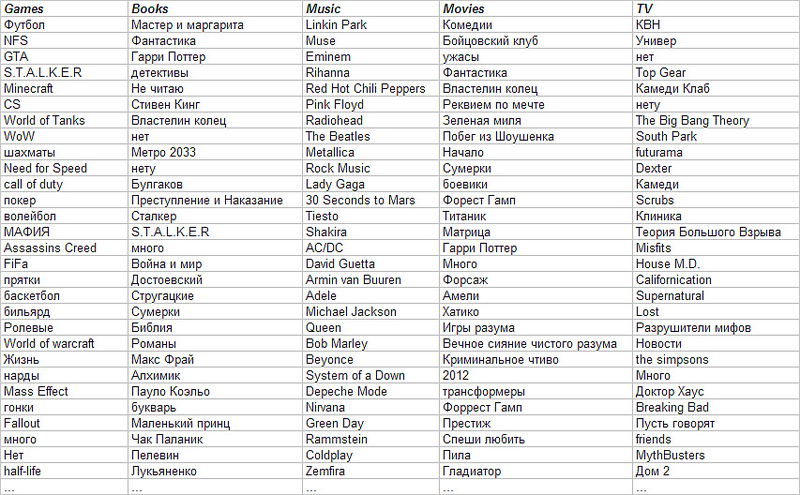
Next, from the tags that occur more than twice, a dictionary of tags is built. Now you need to learn how to find the relevant pages for each tag in the dictionary. The most natural way is to learn how to count the number of tag entries in the text content of pages. However, it is wrong to recommend only in terms of the frequency of occurrence, since words like “all”, “I don’t read”, “I don’t like games” and so on are often found in tags. To solve this problem, TF-IDF weights are calculated for tags, and on many users and on the body of text of web pages separately, since the end-to-end calculation of TF-IDF will not allow to take into account the distribution among users due to the inadequate difference in the amount of text information in the profiles users and texts of web pages.
As a result of calculating the weights of the TF-IDF, we get known for each user and for each web page of the weights vector for all tags from the dictionary. If the tag is not found in the user or in the content of the page, then the weight is considered to be zero.
In order to assess the similarity of the interests of the user and the content of the web page, it is sufficient to calculate the scalar product of the corresponding weights vectors TF-IDF. Another more lazy option is to use the full-text search function built into the database you use. For example, PostgreSQL successfully copes with the task of finding relevant texts by user tags, and also numerically evaluates the similarity, which makes it possible to solve the ranking problem. In fact, the full-text search engine will perform all the same actions that were described above, using only a few other methods. The disadvantage of this approach is the need to build a full-text index in the database for all content. The advantage of the full-text search in this problem is the absence of the need to build a tag dictionary and recalculate the occurrence of tags in texts.
Below is an example of a recommendation for a user with the following tags in the game category: Assassins Creed, Mass Effect, Dragon Age: Origins, Heavy Rain .
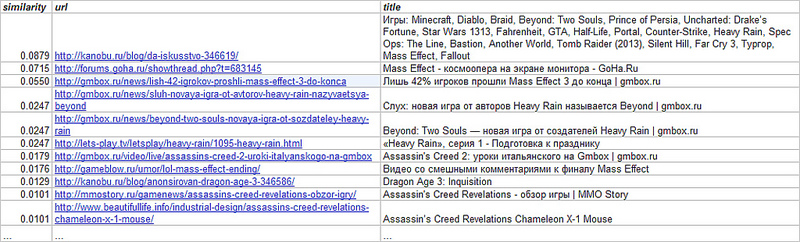
So, we learned to evaluate the similarity of a user (based on his tags) and a web page (based on its content). This is the main building block for building recommendations. However, this is not all. We did not consider web page ratings here. After all, I don’t want to recommend highly unpopular pages, even if they are suitable for the content. Then, it is necessary to correctly combine the resulting algorithm with those already working in the system, but more on that in the next series ...
First, some statistics to show the importance of this study. About 50% of users of our system are registered with the linking of social networking accounts vkontakte (VK) and facebook (FB). Moreover, of the registered via social networks, 71% fall on VK and 29% on FB.
The FB API and the VK API allow you to extract some data about the interests and preferences of the user. But not everything is as simple as it may seem. To obtain user data, you need to obtain special rights, the consent to which gives the user during registration in the system. This is where a subtle moment arises. On the one hand, we go to extract as much information about the user as possible. On the other hand, asking for too many rights is an arrogance that can scare a user away. We need to find a compromise - a delicate balance between the usefulness of the data obtained to improve the recommendations and the "amount" of credit of trust from the user who agrees so that we can get into his personal data.
Through long trials and mistakes for ourselves, we have found such a compromise, but this task is purely individual for each project, as many pros and cons are taken into account that are specific to the system.
')
In this article, I will discuss how user tags from the following categories can be used: games, books, music, movies and television. Such a choice of fields was due to the fact that tags are stored in their pure form and you can link each of these fields to the corresponding categories of Surfingbird. Probably, in the near future I will also tell you how you can handle other, not so obvious fields, such as languages (what languages the user speaks), devices (hardware and sofware, which he uses), education (place and level of education), bio or about (information about yourself), feeds (user posts).
I just want to make a reservation that the first problem we face is the strong sparseness of the data. Information in the games, books, music, movies or television fields is currently available for about 15% of users. But here you can say that, firstly, the ways to get user tags are not limited to the FB and VK APIs. For example, in the future we can also give the opportunity to specify them during registration and adjust in your profile. Secondly, even if for a small fraction of those who honestly indicated their interests, we can give recommendations from the first shows that “pleasantly surprise”, this will increase the overall loyalty to the system and this means our efforts are not in vain.
There are some differences in the data structure returned by API FB and VK. FB data is better structured. For example, each artist or film is stored in separate fields. On VK, they are written in an arbitrary text field, which makes tag selection difficult:
Example of JSON from FB:
{ "books" : { "data" : [ { "category" : "Book", "created_time" : "2013-02-17T17:41:14+0000", "id" : "110451202473491", "name" : "« » " }, { "category" : "Book", "created_time" : "2013-02-04T20:40:10+0000", "id" : "165134073508051", "name" : " . \" \"" }, ... "television" : { "data" : [ { "category" : "Tv show", "created_time" : "2012-06-12T04:52:42+0000", "id" : "184917701541356", "name" : "- " } ], ... } ... } Example of JSON from VK:
{ "books" : " , \" , \", \" \", \" \", \" \", \" \", \" \", \" \", \"\", \" \"", "games" : "Sims 1, 2, 3, 2 ", "movies" : " , , , , , , icarli, , 3, , Sponge Bob, , , , , 2, 3, , !!!!!", ... } After some effort, the tags still manage to extract from unstructured VK data. Here is the top of the list of the most popular tags:
Next, from the tags that occur more than twice, a dictionary of tags is built. Now you need to learn how to find the relevant pages for each tag in the dictionary. The most natural way is to learn how to count the number of tag entries in the text content of pages. However, it is wrong to recommend only in terms of the frequency of occurrence, since words like “all”, “I don’t read”, “I don’t like games” and so on are often found in tags. To solve this problem, TF-IDF weights are calculated for tags, and on many users and on the body of text of web pages separately, since the end-to-end calculation of TF-IDF will not allow to take into account the distribution among users due to the inadequate difference in the amount of text information in the profiles users and texts of web pages.
As a result of calculating the weights of the TF-IDF, we get known for each user and for each web page of the weights vector for all tags from the dictionary. If the tag is not found in the user or in the content of the page, then the weight is considered to be zero.
In order to assess the similarity of the interests of the user and the content of the web page, it is sufficient to calculate the scalar product of the corresponding weights vectors TF-IDF. Another more lazy option is to use the full-text search function built into the database you use. For example, PostgreSQL successfully copes with the task of finding relevant texts by user tags, and also numerically evaluates the similarity, which makes it possible to solve the ranking problem. In fact, the full-text search engine will perform all the same actions that were described above, using only a few other methods. The disadvantage of this approach is the need to build a full-text index in the database for all content. The advantage of the full-text search in this problem is the absence of the need to build a tag dictionary and recalculate the occurrence of tags in texts.
Below is an example of a recommendation for a user with the following tags in the game category: Assassins Creed, Mass Effect, Dragon Age: Origins, Heavy Rain .
So, we learned to evaluate the similarity of a user (based on his tags) and a web page (based on its content). This is the main building block for building recommendations. However, this is not all. We did not consider web page ratings here. After all, I don’t want to recommend highly unpopular pages, even if they are suitable for the content. Then, it is necessary to correctly combine the resulting algorithm with those already working in the system, but more on that in the next series ...
Source: https://habr.com/ru/post/174245/
All Articles