Windows Azure Storage - Architecture
Good afternoon, dear colleagues!
WAS is a cloud storage system that provides customers with the ability to store virtually unlimited amounts of data for any period of time. WAS was introduced in the production version in November 2008. Previously, it was used for internal Microsoft purposes for applications such as storing video, music and games, storing medical records, etc. The article is based on the principles of working with storage services and is devoted to the principles work of these services.
WAS customers have access to their data from anywhere at any time and only pay for what they use and store. Data stored in WAS uses both local and geographic replication to realize recovery from serious failures. At the moment, the WAS repository consists of three abstractions - blobs (files), tables (structured storage) and queues (message delivery). These three data abstractions cover the need for different types of stored data for most applications. The usual use case is to save data in blobs, while using queues, data is transferred to these blobs, while intermediate data, status, and similar temporary data are stored in tables or blobs.
')
During the development of WAS, the wishes of customers were taken into account, and the most significant characteristics of the architecture were:
Let's take a closer look at the global partitions namespace. The key goal of the Windows Azure storage system is to provide one global namespace that would allow customers to place and scale any amount of data in the cloud. To provide a global namespace, WAS uses DNS as part of the namespace, and the namespace consists of three parts: the name of the storage account, the name of the partition, and the name of the object.
Example:
http (s): //AccountName..core.windows.net/PartitionName/ObjectName
AccountName — The storage account name selected by the client is part of the DNS name. This part is used to find the main storage cluster and, in fact, the data center where the necessary data is stored and where all requests for data for this account should be sent. A client in one application can use several account names and store data in completely different places.
PartitionName - the name of the partition, which determines the location of the data when a storage cluster receives a request. PartitionName is used to vertically scale data access across multiple storage nodes depending on traffic.
ObjectName - if there is a set of objects in the partition, ObjectName is used to uniquely identify an object. The system supports atomic transactions for objects within the same PartitionName. The ObjectName value is optional; for some data types, PartitionName can uniquely identify an object within an account.
In WAS, you can use the blob's full blob name as PartitionName for blobs. In the case of tables, it is necessary to take into account that each entity in the table has a primary key consisting of PartitionName and ObjectName, which allows grouping entities into one partition to perform an atomic transaction. For queues, PartitionName is the value of the name of the queue, but each message placed in the queue has its own ObjectName, which uniquely identifies the message within the queue.
The fabric controller manages, monitors, provides fault tolerance and many other tasks in the data center. This is a mechanism that knows about everything that happens in the system, starting from the network connection and ending with the state of the operating systems on the virtual machines. The controller constantly communicates with its own agents installed on operating systems and sending full information about what is happening with this operating system, including OS version, service configuration, configuration packages, and so on. For storage, the Fabric Controller allocates resources and manages the replication and distribution of data across disks, as well as load and traffic balancing. The architecture of Windows Azure Storage is presented in Figure 1.
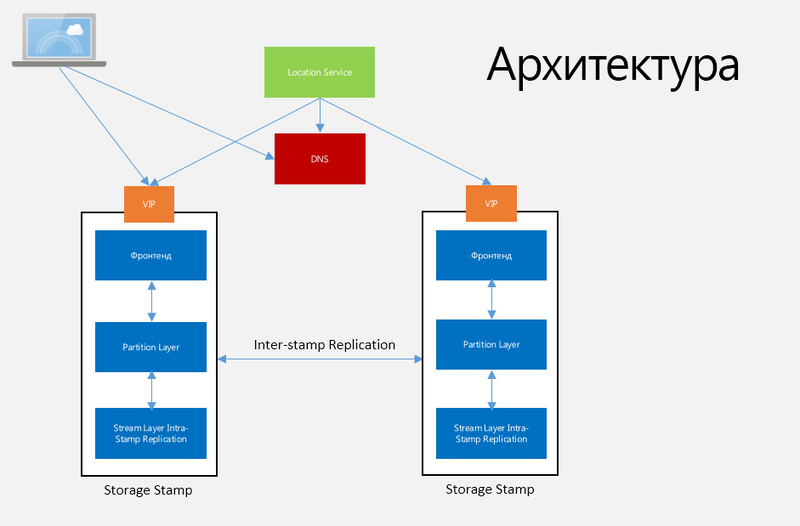
Fig. 1. Windows Azure Storage Architecture
Storage Stamp (SS). This term refers to a cluster consisting of N rivers (rack) of storage nodes, where each river is in its own error domain with excess network and power supply. Clusters typically have from 10 to 20 rivers with 18 nodes on the rivers, with the first generation of Storage Stamps containing about 2 petabytes. The following is up to 30 petabytes. Storage Stamp also try to make the most used, that is, the percentage of each SS should be equal to about 70 in terms of capacity use, number of transactions and bandwidth, but not more than 80, as there should be a reserve for more efficient disk operations. As soon as the use of SS reaches 70%, the Location Service migrates accounts to other SSs using inter-SS replication.
Location Service (LS). This service manages all SS and namespaces for accounts for all SS. LS distributes accounts by SS and implements load balancing and other management tasks. The very same service is distributed in two geographically separated locations for their own security.
Stream Layer (SL). This layer stores data on disk and is responsible for distributing and replicating data across servers to store data within the SS. SL can be viewed as a distributed file system layer within each SS that understands files (“streams”), how to store these files, replicate, and so on. Data is stored on SL, but available with Partition Layer. SL provides, in essence, some interface used only by PL, and a file system with an API that allows you to perform only Append-Only write operations, which allows PL to open, close, delete, rename, read, add parts and merge large files. ” streams ”, ordered lists of large pieces of data, called“ extents ”(Fig. 2).

Fig. 2. Visual image of extents Stream
A stream can contain multiple pointers to extents, and each extent contains a set of blocks. In this case, the extents can be sealed (sealed), that is, you cannot add new data pieces to them. If attempts are made to read data from the Stream, then the data will be received sequentially from the E1 extent to the E4 extent. Each stream is viewed by Partition Layer as one large file, and the content of the Stream can be modified or read in random mode.
Block The minimum unit of data available for writing and reading, which can be up to a certain N bytes. All recorded data is written to the extent in the form of one or more combined blocks, and the blocks do not have to be the same size.
Extent. The extents are replication units on the Stream Layer, and by default the Storage Stamp stores three replicas for each extent stored in the NTFS file and consisting of blocks. The extent size used by Partition Layer is 1 GB, while smaller objects are complemented by Partition Layer to one extent, and sometimes to one block. To store very large objects (for example, blobs), the object is partitioned by Partition Layer into several extents. In this case, of course, Partition Layer keeps track of which extents and blocks which objects belong to.
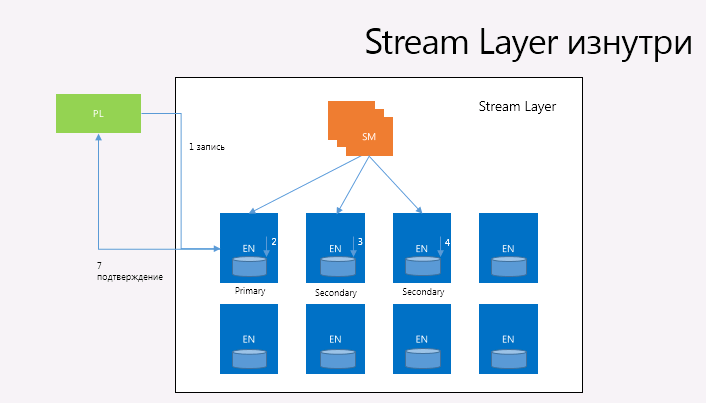
Stream Manager (SM). The Stream Manager tracks the namespace of the streams, manages the state of all active stream and extents and their location between the Extend Node, monitors the health of all the Extend Node, creates and distributes extents (but not blocks - the Stream Manager knows nothing about them), and performs lazy re-replication of extents whose replicas were lost due to hardware errors or simply inaccessible and collects "garbage extents". The Stream Manager periodically polls and synchronizes the status of all Extend Node and the extents that they store. If the SM detects that the extent has been loosened to less than the expected number of ENs, the SM performs a replication. At the same time, the volume of the state, if you can call it that, can be small enough to fit in the memory of one Stream Manager. The only consumer and customer of the Stream Layer is the Partition Layer, and they are so designed that they cannot use more than 50 million extents and no more than 100,000 Stream for a single Storage Stamp (the blocks are not taken into account, since there may be an innumerable number) that Fits perfectly in 32 gigabytes of memory Stream Manager.
Extent Nodes (EN). Each EN manages the repository for the set of extents replicas assigned to them by the SM. EN has N mapped drives, which are under its full control to save extents replicas and their blocks. At the same time, EN does not know anything about the Stream (unlike the Stream Manager, which knows nothing about blocks) and manages only extents and blocks that (extents) are, in fact, files on disks containing data blocks and their checksums + the map of associations of extents to the corresponding blocks and their physical location. Each EN contains some idea of its extents and where the replicas for particular extents are located. When any of the Streams no longer refers to specific extents, the Stream Manager collects these junk extents and notifies EN of the need to free up space. In this case, the data in the Stream can only be added, the existing data cannot be modified. Atomic add operations — either the entire data block is added, or nothing is added. At the same time, several blocks can be added within one atomic operation “adding several blocks”. The minimum size that can be read from Stream is one block. The operation of adding several blocks allows the client to record large amounts of sequential data in a single operation.
Each extent, as already mentioned, has a certain ceiling for the size, and when it is filled, the extent is sealed (sealed) and further write operations operate on new extents. Data cannot be added to a sealed extent, and it is immutable.
There are a few rules regarding extents:
1. After adding a record and confirming the operation to the client, all further read operations of this record from any replica should return the same data (the data is immutable).
2. After sealing the extent, all read operations from any sealed replica must return the same extent content.
For example, when a Stream is created, SM assigns to the first extent three replicas (one primary and two secondary) for three Extent Nodes, which, in turn, are chosen by the SM for random distribution between different update and error domains and taking into account the possibility of load balancing. In addition, the SM decides which replica will be Primary for the extent and all write operations to the extent are performed first on the primary EN, and only after that from the primary EN the record is made on two secondary EN. Primary EN and the location of the three replicas does not change to extent. When the SM allocates an extent, the extent information is sent back to the client, who then knows which EN contain three replicas and which of them is primary. This information becomes part of the Stream metadata and is cached on the client. When the last extent in the Stream is sealed, the process repeats. SM allocates one more extent, which now becomes the last extent in Stream, and all new recording operations are performed on the new last extent. For an extent, each add operation is replicated three times across all replicas of the extent, and the client sends all write requests to the primary EN, but read operations can be performed from any replica, even for unsealed extents. The add operation is sent to the primary EN, and the primary EN is responsible for determining the shift in the extent, as well as organizing all write operations in the event that concurrent recording occurs in one extent, sending the add operation with the necessary shift by two secondary EN and sending confirmation of the operation to the client that is sent only when the add operation was confirmed on all three replicas. If one of the replicas does not respond or a hardware error occurs (or has occurred), a write error is returned to the client. In this case, the client is associated with the SM and the extent in which the write operation occurred is sealed by the SM.
SM then places a new extent with replicas on other available ENs and marks this extent as the last one in stream, and this information is returned to the client, who continues to perform operations to add to the new extent. It should be mentioned that the entire sequence of actions for sealing and placing a new extent is performed on average of only 20 milliseconds.
As for the sealing process itself. In order to seal the extent, the SM polls all three ENs about their current length. In the process of sealing two scenarios - either all replicas of the same size, or one of the replicas longer or shorter than the others. The second situation occurs only when an add operation fails, when some of the EN (but not all) were not available. When sealing the extent, the SM selects the shortest length based on the available ENs. This allows you to seal the extents so that all changes confirmed for the client will be sealed. After sealing, the confirmed extent length no longer changes and, if the SM cannot reach EN during sealing, but then EN becomes available, the SM forces this EN to synchronize to the confirmed length, which results in an identical set of bits.
However, a different situation may arise here - SM cannot communicate with EN, however Partition Server, which is a client, can. Partition Layer, about which a little later, has two read modes - reading records in known positions and using iteration over all records in stream. As for the first - Partition layer uses two types of Stream - recording and blob. For these Stream, read operations always occur for certain positions (extent + shift, length). Partition Layer performs read operations for these two types using the position information returned after a previous successful add operation on the Stream Layer, which only happens when all three replicas have reported that the add operation was successful. In the second case, when all the records in the Stream are iterated sequentially, each partition has two separate Stream (metadata and confirmation log), which the Partition Layer will read sequentially from beginning to end.
In Windows Azure Storage, a mechanism has been introduced that allows saving on disk space and traffic, while not reducing the level of data availability, and is called erasure codes. The essence of this mechanism is that the extent is divided into N fragments of approximately equal size (in practice, these are files again), after which, according to the Reed-Solomon algorithm, M code fragments are added to correct the error. What does it mean? Any X of N fragments are equal in size to the original file, to restore the original file, it is enough to collect X any fragments and decode, the other NX fragments can be deleted, broken, and so on. As long as there are more than M error-correcting code fragments in the system, the system can fully restore the original extent.
This optimization of sealed extents is very important with huge amounts of data stored in the cloud storage, as it reduces the cost of storing data from three full replicas of the source data to 1.3-1.5 of the source data depending on the number of fragments used, and also increases the "stability" of the data compared to storing three replicas inside the Storage Stamp.
When performing write operations for an extent that has three replicas, all operations are put to execution with a specific time value and, if the operation was not completed during this time, this operation should not be performed. If the EN determines that the read operation cannot be completely completed within a certain time, he immediately informs the client. This mechanism allows the client to access a different EN with a read operation.
Similarly with data for which erasure coding is applied - when a read operation does not have time to execute over a time period due to heavy load, this operation may not be used to read the full data fragment, but it can use the opportunity of data reconstruction and in this case the read operation refers to all extent fragments with an erasure code, and the first N responses will be used to reconstruct the required fragment.
Paying attention to the fact that the WAS system can serve very large Streams, the following situation may occur: some physical disks are servicing and become locked into servicing large read or write operations, starting to cut throughput for other operations. To prevent such a situation, WAS does not assign new I / O operations to the disk when it has already been assigned operations that can be performed for more than 100 milliseconds or when already assigned operations have been assigned but not performed in 200 milliseconds.
When data is determined by the Stream Layer as writeable, an additional whole disk or SSD is used as storage for the log of all write operations to EN. The journaling disk is fully allocated for one journal, in which all write operations are sequentially logged. When each EN performs an add operation, it writes all the data to the journaling disk and starts writing the data to the disk. If the log disk returns a successful operation code earlier, data will be buffered in memory, and until all data is written to the data disk, all read operations will be serviced from memory. Using a journaling disk provides important advantages, since, for example, adding operations should not “compete” with data disk read operations in order to confirm the operation for a client. The log allows adding operations with Partition Layer to be more consistent and have lower delays.
Partition Layer (PL). This layer contains special Partition Servers (daemon processes) and is designed to manage the storage abstractions themselves (blobs, tables, queues), namespace, transaction order, strict object consistency, data storage on SL and data caching to reduce the number of I / O operations to disk. PL is also engaged in partitioning data objects within SS according to PartitionName and further load balancing between partition servers. Partition Layer provides an internal data structure called the Object Table (OT), which is a large table capable of growing to a few petabytes. OT, depending on the load, is dynamically split into RangePartitions and distributed across all Partition Servers inside the Storage Stamp. A RangePartition is a range of OT entries starting from the smallest key provided to the largest key.
There are several different types of OT:
• The Account Table stores the metadata and configuration for each storage account associated with the Storage Stamp.
• Blob Table stores all blob objects for all accounts associated with the Storage Stamp.
• The Entity Table stores all the entity records for all storage accounts associated with the Storage Stamp and is used for the Windows Azure table storage service.
• The Message Table stores all messages for all queues for all storage accounts associated with the Storage Stamp.
• Schema Table keeps track of schemas for all OT.
• Partition Map Table keeps track of all current RangePartitions for all Object Tables and which Partition Server services which RangePartition services. This table is used by FE servers to redirect requests to the required Partition Server.
All table types have fixed schemas that are stored in the Schema Table.
For all OT schemes, there is a standard set of property types - bool, binary, string, DateTime, double, GUID, int32 and int64; in addition, the system supports two special DictionaryType and BlobType properties, the first of which allows you to add properties without a specific scheme as a record . These properties are stored inside the dictionary type as
(name, type, value). The second special property is used to store large amounts of data and is currently used only for the Blob Table, while blob data is not stored in the general stream of records, but in a separate stream for blob data, in essence, only the link to blob data is stored (list links "extent + shift length"). OT supports standard operations — insert, update, delete, and read, as well as batch transactions for records with a single PartitionName value.Transactions in one batch are confirmed as one transaction. OT also supports snapshot isolation mode to allow read operations to be performed in parallel with write operations.
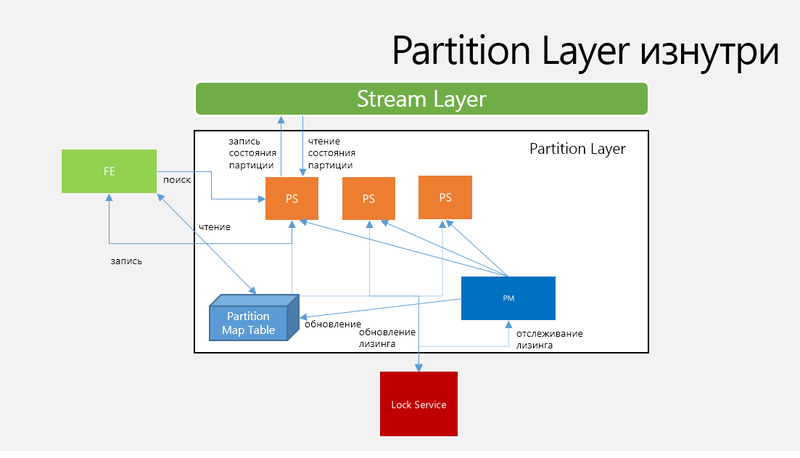
Fig.4. Architecture and Workflow Partition The Layer
Partition Manager (PM) tracks and splits large OTs onto an N RangePartition within the Storage Stamp and assigns the RangePartition to a specific Partition Server. Information about where it is stored is stored in the Partition Map Table. One RangePartition is assigned to one active Partition Server, which guarantees that two RangePartition will not overlap.
Each Storage Stamp has several PM instances and they all "compete" for one Leader Lock stored in the Lock Service.
Partition Server (PS)serves requests for RangePartitions assigned to this PM server and stores all partition state in Streams and manages the cache in memory. PS is able to serve several RangePartitions from several OTs, possibly up to a dozen on average. The PS maintains the following components, keeping them in memory:
• Memory Table , a version of the confirmation log for the RangePartition, containing all recent changes that have not yet been confirmed by the test point.
• Index Cache , a cache containing positions by the checkpoint of the data flow of records.
• Row Data Cache, in-memory cache for checkpoint data entry pages. This cache is read only. When the cache is accessed, the Row Data Cache and Memory Table are checked with a preference for the second.
• Bloom Filters - if the data is not found in the Row Data Cache and Memory Table, then the positions and control points in the data stream are inspected, and their rough search will be ineffective, therefore special bloom filters are used for each control point, which indicate whether access to the record in the checkpoint.
Lock service PM. PS Lock Service . PS N RangePartitions, PS, PS. PM N PS, , PM RangePartitions PS Partition Map Table , Front-End Layer RangePartitions, Partition Map Table. RangePartition Log-Structured Merge-Tree, RangePartition Streams Stream Layer Stream RangePartition.
RangePartition Streams:
• Metadata Stream- This Stream is central to the RangePartition. PM assigns a PS partition, providing the Metadata Stream name of this PS.
• Commit Log Stream — This Stream is intended to store logs of confirmed insert, update, and delete operations applied to a RangePartitions from the last point generated for a RangePartition.
• Row Data Stream saves record data and position for RangePartitions
• Blob Data Stream is used only for Blob Table to save blob data.
Stream Stream Stream Layer, OT RangePartition. RangePartition OT , Blob Table – RangePartition Blob Table ( ) BlobType.
To perform load balancing between Partition Servers and determine the total number of partitions in the Storage Stamp, PM performs three operations:
• Load balancing. With this operation, it is determined when a particular PS is experiencing an excessive load, and then one or more RangePartitions are reassigned to less loaded PS.
• Split. , RangePartition , RangePartition , RangePartitions PS. PM Split, , , PS, AccountName PartitionName. , , RangePartition B RangePartitions C D :
o PM PS B C D.
o PS B .
o PS MultiModify, Streams B (, ) Streams C D , B ( , , , ). PS Partition Key C D .
o PS C D.
o PS PM , Partition Map Table , PS.
• Merge. «» RangePartitions , OT. PM RangePartitions PartitionName, , :
o PM C D , PS, PS C D E.
o PS C D C D.
o PS MultiModify . C D.
o PS creates an E metadata stream containing the confirmation log and data stream names, a combined range of keys for E, and pointers (extent + offset) for the confirmation log (from C and D).
o The traffic for RangePartition E starts.
o PM updates the Partition Map Table and the metadata.
The following metrics are monitored for load balancing:
• The number of transactions per second.
• The average number of pending transactions.
• CPU load.
• Network load.
• Delayed requests.
• Size of the RangePartition data.
PM heartbeat- PS, PM heartbeat. PM , RangePartition ( ), PS Split. PS , RangePartition, PM PS RangePartitions PS. RangePartition PM PS, RangePartition, , PS PM PM RangePartition PS Partition Map Table.
( RangePartition) ( ) , Performance Isolation, RangePartitions, , . , . – , , RangePartition . . PartitionNames, RangePartitions , .
Front-End (FE). The frontend layer consists of a set of stateless servers that accept incoming requests. Upon receiving the request, the FE reads the AccountName, authenticates and authorizes the request, and then transfers it to the partition server on PL (based on the received PartitionName). The servers belonging to the FE cache the so-called Partition Map, in which the system manages some tracking of the PartitionName ranges and which partition server which PartitionNames serves.
Intra-Stamp Replication (stream layer).This mechanism controls synchronous replication and data integrity. It stores enough replicas for different nodes in different error domains in order to save this data in case of any error, and it runs completely on the SL. In the case of a write operation received from a client, it is confirmed only after full successful replication.
Inter-Stamp Replication (partition layer). This replication mechanism produces asynchronous replication between SSs, and it performs this replication in the background. Replication occurs at the object level, that is, either the whole object is replicated, or its change is replicated (delta).
These mechanisms differ in that intra-stamp provides resistance against "iron" errors that periodically occur in large-scale systems, whereas inter-stamp provides geographical redundancy against various catastrophes that occur rarely. One of the main scenarios for this type of replication is the geographical replication of storage account data between two data centers in order to recover from natural disasters.
( – ). , . LS Storage Stamp AccountName Storage Stamp, «» , , secondary, inter-stamp replication ( ). LS DNS AccountName.service.core.windows.net, VIP . , - , . , intra-stamp replication Stream Layer, . Partition Layer.
, . , . , , – , DNS- (account.service.core.windows.net). , DNS- - , URL. ( , ). . , , , , , ( , ).
The process of geographic replication is much more interesting if only because it affects our actions more and more often than the ephemeral dinosaur that ate the data center, which led to geo-failover.
, , ( ), foo bar. PartitionKey. A B foo, X Y bar. , B, , , X Y. – , foo bar. , - , , , A X, B Y . , X Y . ( , PartitionKey , ).
Windows Azure storage services are an essential part of the platform, providing services for storing data in the cloud and implementing a combination of characteristics such as strict consistency, global namespace, and high data fault tolerance in a multi-tenancy environment.
WAS is a cloud storage system that provides customers with the ability to store virtually unlimited amounts of data for any period of time. WAS was introduced in the production version in November 2008. Previously, it was used for internal Microsoft purposes for applications such as storing video, music and games, storing medical records, etc. The article is based on the principles of working with storage services and is devoted to the principles work of these services.
WAS customers have access to their data from anywhere at any time and only pay for what they use and store. Data stored in WAS uses both local and geographic replication to realize recovery from serious failures. At the moment, the WAS repository consists of three abstractions - blobs (files), tables (structured storage) and queues (message delivery). These three data abstractions cover the need for different types of stored data for most applications. The usual use case is to save data in blobs, while using queues, data is transferred to these blobs, while intermediate data, status, and similar temporary data are stored in tables or blobs.
')
During the development of WAS, the wishes of customers were taken into account, and the most significant characteristics of the architecture were:
- Strong consistency - a lot of customers want to have strict consistency, especially for corporate customers, transferring infrastructure to the cloud. They also want to be able to perform read, write, and delete operations according to certain conditions for optimistic control over strictly consistent data — for this, Windows Azure Storage provides what the CAP theorem (Consistency, Availability, Partition-tolerance) describes as difficult to achieve in one moment Time: strict consistency, high availability and Partition Tolerance.
- Global and highly scalable namespaces - to simplify the use of storage in WAS, a global namespace has been implemented, which allows you to store and access data from anywhere in the world. Since one of the main goals of WAS is to provide the ability to store large amounts of data, this global namespace must be able to address exabytes of data.
- Disaster recovery - WAS stores customer data in several data centers that are located several hundred kilometers apart, and this redundancy provides effective protection against data loss due to various situations, such as earthquakes, fires, tornadoes, and so on.
- Multi-tenancy and storage costs — to reduce storage costs, many clients are served from the same shared storage infrastructure, and WAS using this model, when the storages of many different customers with different storage volumes they need are grouped in one place, significantly reducing the total required storage capacity than if WAS allocated separate equipment to each client.
Let's take a closer look at the global partitions namespace. The key goal of the Windows Azure storage system is to provide one global namespace that would allow customers to place and scale any amount of data in the cloud. To provide a global namespace, WAS uses DNS as part of the namespace, and the namespace consists of three parts: the name of the storage account, the name of the partition, and the name of the object.
Example:
http (s): //AccountName..core.windows.net/PartitionName/ObjectName
AccountName — The storage account name selected by the client is part of the DNS name. This part is used to find the main storage cluster and, in fact, the data center where the necessary data is stored and where all requests for data for this account should be sent. A client in one application can use several account names and store data in completely different places.
PartitionName - the name of the partition, which determines the location of the data when a storage cluster receives a request. PartitionName is used to vertically scale data access across multiple storage nodes depending on traffic.
ObjectName - if there is a set of objects in the partition, ObjectName is used to uniquely identify an object. The system supports atomic transactions for objects within the same PartitionName. The ObjectName value is optional; for some data types, PartitionName can uniquely identify an object within an account.
In WAS, you can use the blob's full blob name as PartitionName for blobs. In the case of tables, it is necessary to take into account that each entity in the table has a primary key consisting of PartitionName and ObjectName, which allows grouping entities into one partition to perform an atomic transaction. For queues, PartitionName is the value of the name of the queue, but each message placed in the queue has its own ObjectName, which uniquely identifies the message within the queue.
WAS architecture
The fabric controller manages, monitors, provides fault tolerance and many other tasks in the data center. This is a mechanism that knows about everything that happens in the system, starting from the network connection and ending with the state of the operating systems on the virtual machines. The controller constantly communicates with its own agents installed on operating systems and sending full information about what is happening with this operating system, including OS version, service configuration, configuration packages, and so on. For storage, the Fabric Controller allocates resources and manages the replication and distribution of data across disks, as well as load and traffic balancing. The architecture of Windows Azure Storage is presented in Figure 1.
Fig. 1. Windows Azure Storage Architecture
Storage Stamp (SS). This term refers to a cluster consisting of N rivers (rack) of storage nodes, where each river is in its own error domain with excess network and power supply. Clusters typically have from 10 to 20 rivers with 18 nodes on the rivers, with the first generation of Storage Stamps containing about 2 petabytes. The following is up to 30 petabytes. Storage Stamp also try to make the most used, that is, the percentage of each SS should be equal to about 70 in terms of capacity use, number of transactions and bandwidth, but not more than 80, as there should be a reserve for more efficient disk operations. As soon as the use of SS reaches 70%, the Location Service migrates accounts to other SSs using inter-SS replication.
Location Service (LS). This service manages all SS and namespaces for accounts for all SS. LS distributes accounts by SS and implements load balancing and other management tasks. The very same service is distributed in two geographically separated locations for their own security.
Stream Layer (SL). This layer stores data on disk and is responsible for distributing and replicating data across servers to store data within the SS. SL can be viewed as a distributed file system layer within each SS that understands files (“streams”), how to store these files, replicate, and so on. Data is stored on SL, but available with Partition Layer. SL provides, in essence, some interface used only by PL, and a file system with an API that allows you to perform only Append-Only write operations, which allows PL to open, close, delete, rename, read, add parts and merge large files. ” streams ”, ordered lists of large pieces of data, called“ extents ”(Fig. 2).
Fig. 2. Visual image of extents Stream
A stream can contain multiple pointers to extents, and each extent contains a set of blocks. In this case, the extents can be sealed (sealed), that is, you cannot add new data pieces to them. If attempts are made to read data from the Stream, then the data will be received sequentially from the E1 extent to the E4 extent. Each stream is viewed by Partition Layer as one large file, and the content of the Stream can be modified or read in random mode.
Block The minimum unit of data available for writing and reading, which can be up to a certain N bytes. All recorded data is written to the extent in the form of one or more combined blocks, and the blocks do not have to be the same size.
Extent. The extents are replication units on the Stream Layer, and by default the Storage Stamp stores three replicas for each extent stored in the NTFS file and consisting of blocks. The extent size used by Partition Layer is 1 GB, while smaller objects are complemented by Partition Layer to one extent, and sometimes to one block. To store very large objects (for example, blobs), the object is partitioned by Partition Layer into several extents. In this case, of course, Partition Layer keeps track of which extents and blocks which objects belong to.
Stream Manager (SM). The Stream Manager tracks the namespace of the streams, manages the state of all active stream and extents and their location between the Extend Node, monitors the health of all the Extend Node, creates and distributes extents (but not blocks - the Stream Manager knows nothing about them), and performs lazy re-replication of extents whose replicas were lost due to hardware errors or simply inaccessible and collects "garbage extents". The Stream Manager periodically polls and synchronizes the status of all Extend Node and the extents that they store. If the SM detects that the extent has been loosened to less than the expected number of ENs, the SM performs a replication. At the same time, the volume of the state, if you can call it that, can be small enough to fit in the memory of one Stream Manager. The only consumer and customer of the Stream Layer is the Partition Layer, and they are so designed that they cannot use more than 50 million extents and no more than 100,000 Stream for a single Storage Stamp (the blocks are not taken into account, since there may be an innumerable number) that Fits perfectly in 32 gigabytes of memory Stream Manager.
Extent Nodes (EN). Each EN manages the repository for the set of extents replicas assigned to them by the SM. EN has N mapped drives, which are under its full control to save extents replicas and their blocks. At the same time, EN does not know anything about the Stream (unlike the Stream Manager, which knows nothing about blocks) and manages only extents and blocks that (extents) are, in fact, files on disks containing data blocks and their checksums + the map of associations of extents to the corresponding blocks and their physical location. Each EN contains some idea of its extents and where the replicas for particular extents are located. When any of the Streams no longer refers to specific extents, the Stream Manager collects these junk extents and notifies EN of the need to free up space. In this case, the data in the Stream can only be added, the existing data cannot be modified. Atomic add operations — either the entire data block is added, or nothing is added. At the same time, several blocks can be added within one atomic operation “adding several blocks”. The minimum size that can be read from Stream is one block. The operation of adding several blocks allows the client to record large amounts of sequential data in a single operation.
Each extent, as already mentioned, has a certain ceiling for the size, and when it is filled, the extent is sealed (sealed) and further write operations operate on new extents. Data cannot be added to a sealed extent, and it is immutable.
There are a few rules regarding extents:
1. After adding a record and confirming the operation to the client, all further read operations of this record from any replica should return the same data (the data is immutable).
2. After sealing the extent, all read operations from any sealed replica must return the same extent content.
For example, when a Stream is created, SM assigns to the first extent three replicas (one primary and two secondary) for three Extent Nodes, which, in turn, are chosen by the SM for random distribution between different update and error domains and taking into account the possibility of load balancing. In addition, the SM decides which replica will be Primary for the extent and all write operations to the extent are performed first on the primary EN, and only after that from the primary EN the record is made on two secondary EN. Primary EN and the location of the three replicas does not change to extent. When the SM allocates an extent, the extent information is sent back to the client, who then knows which EN contain three replicas and which of them is primary. This information becomes part of the Stream metadata and is cached on the client. When the last extent in the Stream is sealed, the process repeats. SM allocates one more extent, which now becomes the last extent in Stream, and all new recording operations are performed on the new last extent. For an extent, each add operation is replicated three times across all replicas of the extent, and the client sends all write requests to the primary EN, but read operations can be performed from any replica, even for unsealed extents. The add operation is sent to the primary EN, and the primary EN is responsible for determining the shift in the extent, as well as organizing all write operations in the event that concurrent recording occurs in one extent, sending the add operation with the necessary shift by two secondary EN and sending confirmation of the operation to the client that is sent only when the add operation was confirmed on all three replicas. If one of the replicas does not respond or a hardware error occurs (or has occurred), a write error is returned to the client. In this case, the client is associated with the SM and the extent in which the write operation occurred is sealed by the SM.
SM then places a new extent with replicas on other available ENs and marks this extent as the last one in stream, and this information is returned to the client, who continues to perform operations to add to the new extent. It should be mentioned that the entire sequence of actions for sealing and placing a new extent is performed on average of only 20 milliseconds.
As for the sealing process itself. In order to seal the extent, the SM polls all three ENs about their current length. In the process of sealing two scenarios - either all replicas of the same size, or one of the replicas longer or shorter than the others. The second situation occurs only when an add operation fails, when some of the EN (but not all) were not available. When sealing the extent, the SM selects the shortest length based on the available ENs. This allows you to seal the extents so that all changes confirmed for the client will be sealed. After sealing, the confirmed extent length no longer changes and, if the SM cannot reach EN during sealing, but then EN becomes available, the SM forces this EN to synchronize to the confirmed length, which results in an identical set of bits.
However, a different situation may arise here - SM cannot communicate with EN, however Partition Server, which is a client, can. Partition Layer, about which a little later, has two read modes - reading records in known positions and using iteration over all records in stream. As for the first - Partition layer uses two types of Stream - recording and blob. For these Stream, read operations always occur for certain positions (extent + shift, length). Partition Layer performs read operations for these two types using the position information returned after a previous successful add operation on the Stream Layer, which only happens when all three replicas have reported that the add operation was successful. In the second case, when all the records in the Stream are iterated sequentially, each partition has two separate Stream (metadata and confirmation log), which the Partition Layer will read sequentially from beginning to end.
In Windows Azure Storage, a mechanism has been introduced that allows saving on disk space and traffic, while not reducing the level of data availability, and is called erasure codes. The essence of this mechanism is that the extent is divided into N fragments of approximately equal size (in practice, these are files again), after which, according to the Reed-Solomon algorithm, M code fragments are added to correct the error. What does it mean? Any X of N fragments are equal in size to the original file, to restore the original file, it is enough to collect X any fragments and decode, the other NX fragments can be deleted, broken, and so on. As long as there are more than M error-correcting code fragments in the system, the system can fully restore the original extent.
This optimization of sealed extents is very important with huge amounts of data stored in the cloud storage, as it reduces the cost of storing data from three full replicas of the source data to 1.3-1.5 of the source data depending on the number of fragments used, and also increases the "stability" of the data compared to storing three replicas inside the Storage Stamp.
When performing write operations for an extent that has three replicas, all operations are put to execution with a specific time value and, if the operation was not completed during this time, this operation should not be performed. If the EN determines that the read operation cannot be completely completed within a certain time, he immediately informs the client. This mechanism allows the client to access a different EN with a read operation.
Similarly with data for which erasure coding is applied - when a read operation does not have time to execute over a time period due to heavy load, this operation may not be used to read the full data fragment, but it can use the opportunity of data reconstruction and in this case the read operation refers to all extent fragments with an erasure code, and the first N responses will be used to reconstruct the required fragment.
Paying attention to the fact that the WAS system can serve very large Streams, the following situation may occur: some physical disks are servicing and become locked into servicing large read or write operations, starting to cut throughput for other operations. To prevent such a situation, WAS does not assign new I / O operations to the disk when it has already been assigned operations that can be performed for more than 100 milliseconds or when already assigned operations have been assigned but not performed in 200 milliseconds.
When data is determined by the Stream Layer as writeable, an additional whole disk or SSD is used as storage for the log of all write operations to EN. The journaling disk is fully allocated for one journal, in which all write operations are sequentially logged. When each EN performs an add operation, it writes all the data to the journaling disk and starts writing the data to the disk. If the log disk returns a successful operation code earlier, data will be buffered in memory, and until all data is written to the data disk, all read operations will be serviced from memory. Using a journaling disk provides important advantages, since, for example, adding operations should not “compete” with data disk read operations in order to confirm the operation for a client. The log allows adding operations with Partition Layer to be more consistent and have lower delays.
Partition Layer (PL). This layer contains special Partition Servers (daemon processes) and is designed to manage the storage abstractions themselves (blobs, tables, queues), namespace, transaction order, strict object consistency, data storage on SL and data caching to reduce the number of I / O operations to disk. PL is also engaged in partitioning data objects within SS according to PartitionName and further load balancing between partition servers. Partition Layer provides an internal data structure called the Object Table (OT), which is a large table capable of growing to a few petabytes. OT, depending on the load, is dynamically split into RangePartitions and distributed across all Partition Servers inside the Storage Stamp. A RangePartition is a range of OT entries starting from the smallest key provided to the largest key.
There are several different types of OT:
• The Account Table stores the metadata and configuration for each storage account associated with the Storage Stamp.
• Blob Table stores all blob objects for all accounts associated with the Storage Stamp.
• The Entity Table stores all the entity records for all storage accounts associated with the Storage Stamp and is used for the Windows Azure table storage service.
• The Message Table stores all messages for all queues for all storage accounts associated with the Storage Stamp.
• Schema Table keeps track of schemas for all OT.
• Partition Map Table keeps track of all current RangePartitions for all Object Tables and which Partition Server services which RangePartition services. This table is used by FE servers to redirect requests to the required Partition Server.
All table types have fixed schemas that are stored in the Schema Table.
For all OT schemes, there is a standard set of property types - bool, binary, string, DateTime, double, GUID, int32 and int64; in addition, the system supports two special DictionaryType and BlobType properties, the first of which allows you to add properties without a specific scheme as a record . These properties are stored inside the dictionary type as
(name, type, value). The second special property is used to store large amounts of data and is currently used only for the Blob Table, while blob data is not stored in the general stream of records, but in a separate stream for blob data, in essence, only the link to blob data is stored (list links "extent + shift length"). OT supports standard operations — insert, update, delete, and read, as well as batch transactions for records with a single PartitionName value.Transactions in one batch are confirmed as one transaction. OT also supports snapshot isolation mode to allow read operations to be performed in parallel with write operations.
Partition Layer Architecture
Fig.4. Architecture and Workflow Partition The Layer
Partition Manager (PM) tracks and splits large OTs onto an N RangePartition within the Storage Stamp and assigns the RangePartition to a specific Partition Server. Information about where it is stored is stored in the Partition Map Table. One RangePartition is assigned to one active Partition Server, which guarantees that two RangePartition will not overlap.
Each Storage Stamp has several PM instances and they all "compete" for one Leader Lock stored in the Lock Service.
Partition Server (PS)serves requests for RangePartitions assigned to this PM server and stores all partition state in Streams and manages the cache in memory. PS is able to serve several RangePartitions from several OTs, possibly up to a dozen on average. The PS maintains the following components, keeping them in memory:
• Memory Table , a version of the confirmation log for the RangePartition, containing all recent changes that have not yet been confirmed by the test point.
• Index Cache , a cache containing positions by the checkpoint of the data flow of records.
• Row Data Cache, in-memory cache for checkpoint data entry pages. This cache is read only. When the cache is accessed, the Row Data Cache and Memory Table are checked with a preference for the second.
• Bloom Filters - if the data is not found in the Row Data Cache and Memory Table, then the positions and control points in the data stream are inspected, and their rough search will be ineffective, therefore special bloom filters are used for each control point, which indicate whether access to the record in the checkpoint.
Lock service PM. PS Lock Service . PS N RangePartitions, PS, PS. PM N PS, , PM RangePartitions PS Partition Map Table , Front-End Layer RangePartitions, Partition Map Table. RangePartition Log-Structured Merge-Tree, RangePartition Streams Stream Layer Stream RangePartition.
RangePartition Streams:
• Metadata Stream- This Stream is central to the RangePartition. PM assigns a PS partition, providing the Metadata Stream name of this PS.
• Commit Log Stream — This Stream is intended to store logs of confirmed insert, update, and delete operations applied to a RangePartitions from the last point generated for a RangePartition.
• Row Data Stream saves record data and position for RangePartitions
• Blob Data Stream is used only for Blob Table to save blob data.
Stream Stream Stream Layer, OT RangePartition. RangePartition OT , Blob Table – RangePartition Blob Table ( ) BlobType.
RangePartitions
To perform load balancing between Partition Servers and determine the total number of partitions in the Storage Stamp, PM performs three operations:
• Load balancing. With this operation, it is determined when a particular PS is experiencing an excessive load, and then one or more RangePartitions are reassigned to less loaded PS.
• Split. , RangePartition , RangePartition , RangePartitions PS. PM Split, , , PS, AccountName PartitionName. , , RangePartition B RangePartitions C D :
o PM PS B C D.
o PS B .
o PS MultiModify, Streams B (, ) Streams C D , B ( , , , ). PS Partition Key C D .
o PS C D.
o PS PM , Partition Map Table , PS.
• Merge. «» RangePartitions , OT. PM RangePartitions PartitionName, , :
o PM C D , PS, PS C D E.
o PS C D C D.
o PS MultiModify . C D.
o PS creates an E metadata stream containing the confirmation log and data stream names, a combined range of keys for E, and pointers (extent + offset) for the confirmation log (from C and D).
o The traffic for RangePartition E starts.
o PM updates the Partition Map Table and the metadata.
The following metrics are monitored for load balancing:
• The number of transactions per second.
• The average number of pending transactions.
• CPU load.
• Network load.
• Delayed requests.
• Size of the RangePartition data.
PM heartbeat- PS, PM heartbeat. PM , RangePartition ( ), PS Split. PS , RangePartition, PM PS RangePartitions PS. RangePartition PM PS, RangePartition, , PS PM PM RangePartition PS Partition Map Table.
( RangePartition) ( ) , Performance Isolation, RangePartitions, , . , . – , , RangePartition . . PartitionNames, RangePartitions , .
Front-End (FE). The frontend layer consists of a set of stateless servers that accept incoming requests. Upon receiving the request, the FE reads the AccountName, authenticates and authorizes the request, and then transfers it to the partition server on PL (based on the received PartitionName). The servers belonging to the FE cache the so-called Partition Map, in which the system manages some tracking of the PartitionName ranges and which partition server which PartitionNames serves.
Intra-Stamp Replication (stream layer).This mechanism controls synchronous replication and data integrity. It stores enough replicas for different nodes in different error domains in order to save this data in case of any error, and it runs completely on the SL. In the case of a write operation received from a client, it is confirmed only after full successful replication.
Inter-Stamp Replication (partition layer). This replication mechanism produces asynchronous replication between SSs, and it performs this replication in the background. Replication occurs at the object level, that is, either the whole object is replicated, or its change is replicated (delta).
These mechanisms differ in that intra-stamp provides resistance against "iron" errors that periodically occur in large-scale systems, whereas inter-stamp provides geographical redundancy against various catastrophes that occur rarely. One of the main scenarios for this type of replication is the geographical replication of storage account data between two data centers in order to recover from natural disasters.
( – ). , . LS Storage Stamp AccountName Storage Stamp, «» , , secondary, inter-stamp replication ( ). LS DNS AccountName.service.core.windows.net, VIP . , - , . , intra-stamp replication Stream Layer, . Partition Layer.
, . , . , , – , DNS- (account.service.core.windows.net). , DNS- - , URL. ( , ). . , , , , , ( , ).
The process of geographic replication is much more interesting if only because it affects our actions more and more often than the ephemeral dinosaur that ate the data center, which led to geo-failover.
, , ( ), foo bar. PartitionKey. A B foo, X Y bar. , B, , , X Y. – , foo bar. , - , , , A X, B Y . , X Y . ( , PartitionKey , ).
Summary
Windows Azure storage services are an essential part of the platform, providing services for storing data in the cloud and implementing a combination of characteristics such as strict consistency, global namespace, and high data fault tolerance in a multi-tenancy environment.
Source: https://habr.com/ru/post/173661/
All Articles