Recommender system: useful text mining tasks
I continue the cycle of articles on the use of text-mining methods for solving various problems arising in the recommender system of web pages. Today I will talk about two tasks: the automatic determination of categories for pages from RSS feeds and the search for duplicates and plagiarism among web pages. So, in order.
The usual scheme of adding web pages (or rather, links to them) in Surfingbird is as follows: when adding a new link, the user must specify up to three categories to which this link belongs. It is clear that in such a situation the task of automatically determining categories is not worth it. However, besides the manual addition, the links get into the database and from RSS feeds, which are provided by many popular sites. Since there are a lot of links coming through RSS feeds, often moderators (and in this case they are forced to put down categories) simply cannot cope with such a volume. The challenge is to create an intelligent system of automatic classification by categories. For a number of sites (for example, lenta.ru or sueta.ru) categories can be pulled out directly from rss-xml and manually linked to our internal categories:
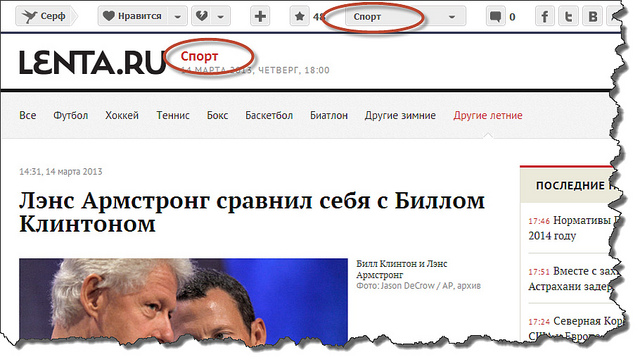
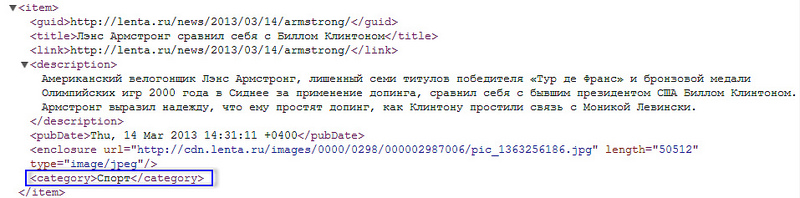
Things are worse for RSS feeds that do not have fixed categories, but instead indicate custom tags. Tags entered randomly (a typical example - tags in LJ posts) cannot be manually linked to our categories. And here more subtle mathematics is included. Text content (title, tags, useful text) is extracted from the page and the LDA model is used , a brief description of which can be found in my previous article . As a result, the vector of probabilities of the web page belonging to thematic LDA topics is calculated. The resulting vector of LDA topics of the site is used as a feature vector to solve the classification problem by category. In this case, the objects of classification are sites, classes are categories. Logistic regression was used as a classification method, although any other method can be used, for example, a naive Bayes classifier .
')
To test the method, models were trained on 5,000 sites classified by the moderator from RSS feeds, for which the distribution by LDA topics was also known. The results of training on the test sample are presented in the table:
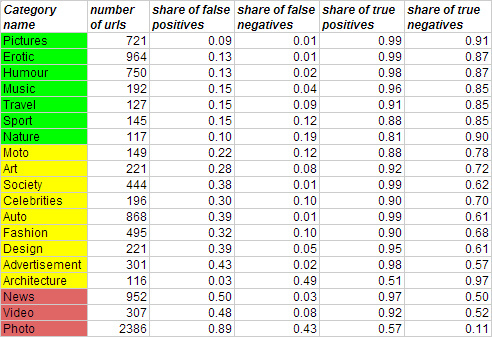
As a result, an acceptable quality of classification (by the proportion of false detections and the proportion of false omissions) was obtained only in the following categories: Pictures, Erotic, Humor, Music, Travel, Sport, Nature. For too general categories, such as Photo, Video, News, large errors.
In conclusion, it can be said that if, in the case of rigid binding to external categories, the classification is in principle possible in a fully automatic mode, then textual classification inevitably has to be carried out in semi-automatic mode, when the most likely categories are then offered to the moderator. Our goal here is to simplify the work of the moderator as much as possible.
Another task that text mining allows to solve is the search and filtering of links with repetitive content. Repeat content is possible for one of the following reasons:
The first and second paragraphs are technical and are solved by obtaining final links and literal comparison of useful content for all pages in the database. However, even with a full copy-paste, a formal comparison of useful text may not pass for obvious reasons (for example, random characters or words from the site menu are included), and the text may be slightly modified. This third option we consider in more detail. A typical twin might look like this:
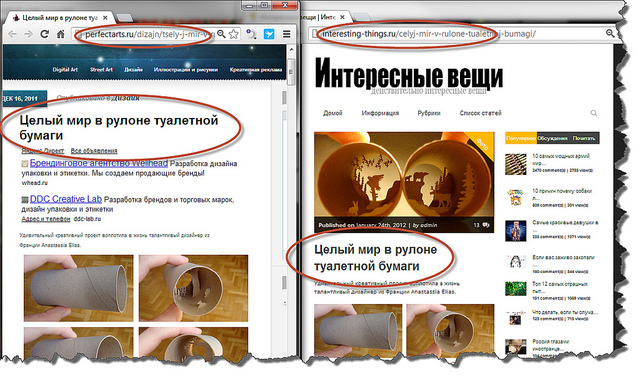
The task of determining borrowing in the broad sense of the word is quite complex. She is interested in us in a narrower setting: we do not need to look for plagiarism in every phrase of the text, but we just need to compare the documents on the content as a whole.
For this, one can effectively use the already existing “bag of words” model and the calculated TF-IDF weights of all the site terms. There are several different techniques.
First we introduce the notation:
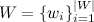 - dictionary of all different words;
- dictionary of all different words;
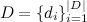 - corpus of texts (content of web pages);
- corpus of texts (content of web pages);
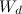 - many words in the document.
- many words in the document.
To compare two documents and
and 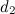 you first need to build a combined vector of words
you first need to build a combined vector of words 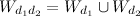 from words that appear in both documents:
from words that appear in both documents:
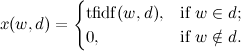
The similarity of the texts is calculated as a scalar product with normalization:
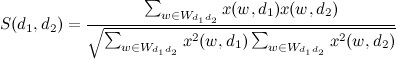
If a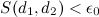 (threshold of similarity), then the pages are considered doubles.
(threshold of similarity), then the pages are considered doubles.
The other approach does not take into account the weight of the TF-IDF, but builds similarity on binary data (is there a word in the document or not). To estimate page differences, the Jacquard coefficient is used :
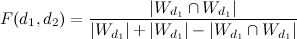 ,
,
Where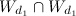 - A lot of common words in the documents.
- A lot of common words in the documents.
As a result of the application of these methods, several thousand twins have been identified. For a formal quality assessment, it is necessary to mark out the twins on the training set in an expert manner.
On this for now, I hope the article will be useful to you. And we will welcome new ideas on how to apply text mining to improve the recommendations!
Automatic category detection for web pages from RSS feeds
The usual scheme of adding web pages (or rather, links to them) in Surfingbird is as follows: when adding a new link, the user must specify up to three categories to which this link belongs. It is clear that in such a situation the task of automatically determining categories is not worth it. However, besides the manual addition, the links get into the database and from RSS feeds, which are provided by many popular sites. Since there are a lot of links coming through RSS feeds, often moderators (and in this case they are forced to put down categories) simply cannot cope with such a volume. The challenge is to create an intelligent system of automatic classification by categories. For a number of sites (for example, lenta.ru or sueta.ru) categories can be pulled out directly from rss-xml and manually linked to our internal categories:
Things are worse for RSS feeds that do not have fixed categories, but instead indicate custom tags. Tags entered randomly (a typical example - tags in LJ posts) cannot be manually linked to our categories. And here more subtle mathematics is included. Text content (title, tags, useful text) is extracted from the page and the LDA model is used , a brief description of which can be found in my previous article . As a result, the vector of probabilities of the web page belonging to thematic LDA topics is calculated. The resulting vector of LDA topics of the site is used as a feature vector to solve the classification problem by category. In this case, the objects of classification are sites, classes are categories. Logistic regression was used as a classification method, although any other method can be used, for example, a naive Bayes classifier .
')
To test the method, models were trained on 5,000 sites classified by the moderator from RSS feeds, for which the distribution by LDA topics was also known. The results of training on the test sample are presented in the table:
As a result, an acceptable quality of classification (by the proportion of false detections and the proportion of false omissions) was obtained only in the following categories: Pictures, Erotic, Humor, Music, Travel, Sport, Nature. For too general categories, such as Photo, Video, News, large errors.
In conclusion, it can be said that if, in the case of rigid binding to external categories, the classification is in principle possible in a fully automatic mode, then textual classification inevitably has to be carried out in semi-automatic mode, when the most likely categories are then offered to the moderator. Our goal here is to simplify the work of the moderator as much as possible.
Search for duplicates and plagiarism among web pages
Another task that text mining allows to solve is the search and filtering of links with repetitive content. Repeat content is possible for one of the following reasons:
- several different links are redirected to the same final link;
- the content is completely copied on various web pages;
- Content copied partially or slightly modified.
The first and second paragraphs are technical and are solved by obtaining final links and literal comparison of useful content for all pages in the database. However, even with a full copy-paste, a formal comparison of useful text may not pass for obvious reasons (for example, random characters or words from the site menu are included), and the text may be slightly modified. This third option we consider in more detail. A typical twin might look like this:
The task of determining borrowing in the broad sense of the word is quite complex. She is interested in us in a narrower setting: we do not need to look for plagiarism in every phrase of the text, but we just need to compare the documents on the content as a whole.
For this, one can effectively use the already existing “bag of words” model and the calculated TF-IDF weights of all the site terms. There are several different techniques.
First we introduce the notation:
- dictionary of all different words; - corpus of texts (content of web pages); - many words in the document.To compare two documents
and you first need to build a combined vector of words from words that appear in both documents:The similarity of the texts is calculated as a scalar product with normalization:
If a
(threshold of similarity), then the pages are considered doubles.The other approach does not take into account the weight of the TF-IDF, but builds similarity on binary data (is there a word in the document or not). To estimate page differences, the Jacquard coefficient is used :
,Where
- A lot of common words in the documents.As a result of the application of these methods, several thousand twins have been identified. For a formal quality assessment, it is necessary to mark out the twins on the training set in an expert manner.
On this for now, I hope the article will be useful to you. And we will welcome new ideas on how to apply text mining to improve the recommendations!
Source: https://habr.com/ru/post/172417/
All Articles