Java: keyed executor
There is a typical problem in a large class of tasks that occurs when processing a message flow:
- you can not push through a big elephant through a small pipe, or in other words, the processing of messages does not have time to "swallow" all the messages.
')
However, there are some restrictions on the data flow:
- the flow is not uniform and consists of events of different types.
- the number of event types is not known in advance, but some finite number
- each type of event has its own relevance in time
- all event types have equal priority
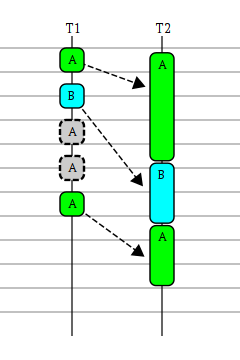
The diagram shows an example of resolving the problem: a rake (tm) running on a T 1 string, while a rake (tm) runs on a T 2 string
- during the processing of event type A, new events both type B and A have time to arrive.
- after processing an event of type B, you must handle the most current event of type A
So the task is to perform tasks by key, so that only the most current of all tasks on this key is performed.
The ThrottlingExecutor created by us is presented to the public.
Terminology note: stream is a data stream , while thread is a thread or a thread of execution . And do not confuse threads with threads.
Note 1: the problem is further complicated by the fact that there may be several Nagrebator (tm) , while each Nagrebator (tm) can only generate events of the same type; on the other hand, there is a need for several (of course, for simplicity, you can choose N = 1 ) diggers (tm) .
Note 2: not only does this code have to work in a multi-threaded (competitive) environment - that is, the set of diggers (tm) - diggers (tm) , the code should work with maximum performance and low latency. It is reasonable to add all these qualities to the garbage less property.
And in almost every project this problem somehow arises, and each one solves it differently, but all of them are either not effective, or slow, or both of them taken together.
A small lyrical digression.
In my opinion, the task is very interesting, quite practical and, moreover, from our specific work. And that's why we ask our candidates for an interview. However, we are not asking to literally code everything inside and out, but to build a general design of the solution, if possible highlighting the key points of the solution with pieces of code. After several months of interviews, we decided to put the ideas into code in java.
However, the code cannot yet be opened publicly, therefore ideas are general and can be applied and implemented in many other programming languages.
Since everything is already set, and perhaps it remains to bring a little marafet, I will describe the key points of the decision.
So, looking around, we didn’t find how to do what we want with the high-level data structures available in jdk , so we will construct from the most basic blocks.
Picture of the design as a whole:
- because there is no need to store all obtained values, but only the most relevant ones are needed - then it would be good to store key-value pairs in some associative array, rubbing the old values with new ones
- run on an associative array, take (marking a cell with a special value, for example, null ) the most recent values and return to the handler.
Associative array
Key aspect: storing key-value pairs. You can neglect the order of storage, while winning at the rate of update - so This suggests the use of a hash structure, the complexity of which is O (1) .
A negative effect on the performance of the hash structure is caused by the collision of hash codes on the selected size. The two most common methods for resolving collisions are:
- chains - each element of the array is a linked list that stores elements with the same (up to the module size of the array) hash codes
- open addressing - when a collision occurs, the first free cell is searched for (or in front of) the cell of the corresponding hash code. As a rule, in favor of productivity limit the number of samples of the free cell. When the number of samples to find a free cell to insert a new element is exceeded, the array is expanded.
The chain method is more stable, since It does not stumble over the problem of poor distribution of hash codes , while open addressing will clearly not survive if all the keys have a hash code equal, for example, to some constant . On the other hand, open addressing has significantly less memory overhead.
Another plus in favor of open addressing is the cache locality, the data in the array are sequentially in memory and will also be sequentially loaded into cpu cache, so fast sequential iteration as opposed to chaining , where pointers to linked lists are somehow scattered in memory.
Based on the general principles of adequacy of application, we can safely assume that the function hash codes will not be degenerate and the choice falls on the public addressing .
Now consider the array element:
atomic refs
Since there is a requirement to work in a multi-threaded and high-loaded environment, you don’t bother with synchronized blocks and work through Compare-And-Swap , so each element is an AtomicReference extension with a key :
static class Entry<K> extends AtomicReference { final K key; public Entry(final K key){ this.key = key; } } atomic array ref
Another way to ensure the consistency and atomicity of the memory is to use not the AtomicReference array, but AtomicReferenceArray .
Motives - less additional overhead for the occupied memory, the sequence in memory. At the same time, the scheme for expansion / compression of the array becomes much more complicated.
Card mark
The basic idea: not to iterate over all elements, but only over the modified elements (ideally), or segments (consisting of a small reasonable number of elements) that contain modified elements.
Simple card mark
An easy-to-implement approach using AtomicLong as a mask allows you to cover up to 64 modified segments.
However, with an array already in 4096 elements, the segment consists of 64 elements, so potentially, you can do a lot of empty readings.
Binary heap card mark
The next step I wanted to expand the number of segments, while maintaining the compactness of storage in memory and ease of traversal. In this case, the selected data structure should be convenient from the point of view of the wait strategy .
From these points of view, the binary heap is very convenient - the zero element indicates whether there were any changes at all or not (if not, you can gnaw a stone / fall asleep = apply a waiting strategy ) and already subsequent elements indicate changed segments of the original array.
So, if there is a second level and the size of the array is 4096 elements, the segment contains exactly one element.
So simple card mark should be good for small sizes of the array, and binary heap card mark for large sizes.
Wait Strategy
Another aspect and direct reference to D. , which should not be mentioned in conjunction with the card mark , is the application of the waiting strategy for changed segments: you should not immediately fall into a state of passive waiting (that is, call wait on the monitor) if there are no changes, it is possible That will be able to get a change actively poll'ya card mark.
For example, busy spin polls the root element card card mark in the loop - if there are changes, we exit - we process the elements. If not, continue the cycle. By limiting the cycle, for example, by hundreds of attempts, we fall into a state of passive waiting for the wait , and let us wake up the nagbator (tm) , seeing that the card mark was crystal clear and empty.
However, the strategy may change in each case.
tricks and tricks
- maintaining the sizes of the array and binary heap as 2 K, you can avoid using division , multiply and mod operations and use cheaper bit analogues: right shift K , left shift K and use bit masks ( & ((1 << K) - 1) )
- the main and most frequent operation in the stable phase - the replace / replace operation occurs only at the expense of CAS for the found array element without capturing any monitor
- subtracting the value from a cell or card mark instead of an unconditional get-and-set (0) sometimes (when the array is very low) it is more sensible to do test-n-get-n-set to avoid unnecessary (and more expensive) volatile write
- array expansion / contraction (in the context of JMM correctness) refers to the initial phase
- volatile array reference - fast volatile read
- updating volatile links with AtomicReferenceFieldUpdater magic
- Given that the number of keys is limited, you can scale the array to produce under the monitor
At the end of the latency distribution graphics:
- 1 rake (tm) - 1 rake (tm)
- 700 unique keys, hash collisions <1%
- warming up jvm: 20,000 first iterations ignored when measuring latency
- The task transferred to the executor: fix the time (in ms) of passing through the executor - that is, fix the latency
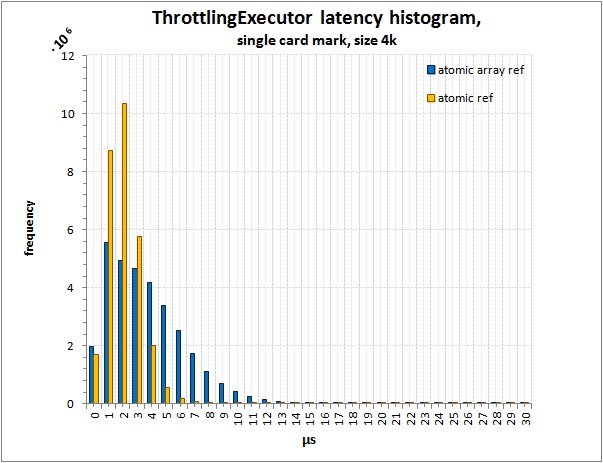
Histogram of latency distribution in ThrottlingExecutor,
simple card mark, size 4096
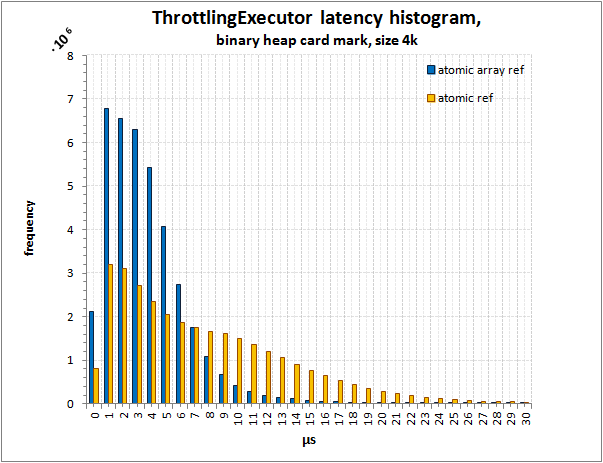
Histogram of latency distribution in ThrottlingExecutor,
card mark on binary heap, size 4096
In a highly sparse array:
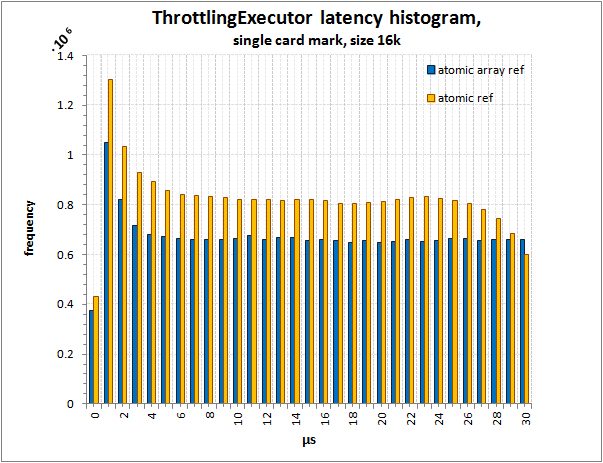
Histogram of latency distribution in ThrottlingExecutor,
simple card mark, size 16384
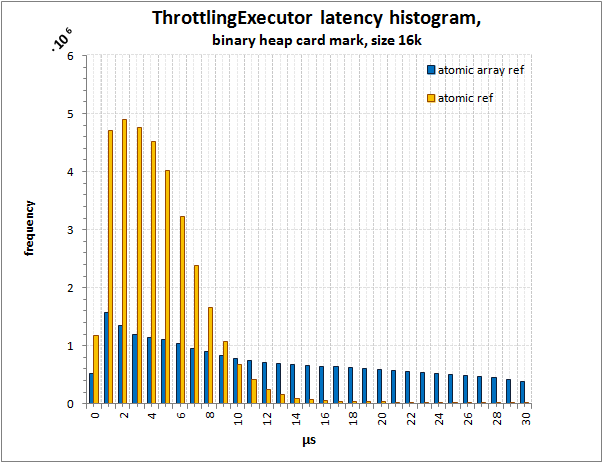
Histogram of latency distribution in ThrottlingExecutor,
card mark on binary heap, size 16384
Until the end, I could not find all the reasons for such a different behavior of the array of atomic references and the atomic array (we expected rather to see that an atomic array with a binary heap would work much better).
It is possible, and I hope very much, when we can open the code, we will find errors or get answers.
PS It is worth noting that by testing existing ThrottlingExecutor solutions in this benchmark , they gave an almost even distribution of up to 300 µs.
Source: https://habr.com/ru/post/172209/
All Articles