Why lay CloudFlare
Today at 09:47 UTC CloudFlare actually dropped from the Internet. The fall affected all CloudFlare services, including DNS and proxying services. Anyone who tried to open any site using CloudFlare services during a crash received a DNS error. Ping and traceroute to CloudFlare hosts also generated an error "No Route to Host".
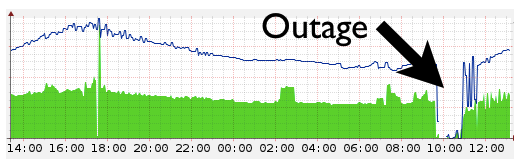
The cause of the fall was an error on the border routers. CloudFlare now has 23 data centers around the world. They are connected to the Internet via routers. These routers made it so that packets sent to us from anywhere on the Internet usually reach our servers. When the router stops working, the network behind it stops being accessible to the Internet.
We regularly turn off one or more of our wonderful routers, for example, during any work. Due to the fact that we use Anycast, the traffic is redirected to the nearest data center. However, this morning we encountered an error that caused all of our routers.
')
All border routers that were prone to error were from Juniper. One of the reasons we like Juniper routers is support for the Flowspec protocol. It allows you to effectively distribute routing rules to a large number of routers. Here at CloudFlare, we are constantly updating the routing rules. This is necessary to protect against attacks and redirect traffic for the fastest possible service.
This morning we noticed a DDoS attack directed at one of our clients. The attack was directed exclusively at the DNS server. We have a special tool for creating attack signatures that are equally well understood for automated systems and for employees. Typically, these signatures are used to create routing rules that will reduce the number of “bad” requests.
In this case, our attack profiler determined that the “bad” packets were from 99.971 to 99.985 bytes in length. This is rather strange, because the length of a regular packet does not exceed 600 bytes, and the largest ones are up to 1,500 bytes. Our network has a limit of 4,470 bytes, but the profiler said that the attacker's packets are exactly that long.
Someone from our team always monitors the network, 24/7. As usual, one of the operators took the profiler output and added a rule according to which all packets ranging in size from 99.971 to 99.985 bytes should be “dropped”. It looked like this in Junos, the Juniper operating system:

Flowspec accepted this rule and distributed it across the entire boundary network. In theory, no packet should fit this rule, because there could not be such large packets on the network. In fact, all routers accepted the rule and began to consume all the available RAM until they were stuck.
In the normal case, the router should automatically restart, but then for some reason this did not happen. We also could not access through the management ports. Even if some data center suddenly got up, he immediately went back, because all the traffic of the entire network was starting to go through it.
Sam Bowne, a professor at City College San Francisco, using BGPlay got this video, which shows how one by one the routers fall:
The CloudFlare network team was aware of the incident from the very beginning. It was unclear why routers crashed, but it was obvious that packets could not find the path to our network. We were able to gain access to several routers and found out that they were falling because of that rule. We deleted it and then called operators in other data centers to reset the routers.
CloudFlare's 23 data centers are located in 14 countries, so the response time was somewhere around 30 minutes. At 10:49 UTC, all CloudFlare services were already running. We continue to investigate cases that our customers are still complaining about. Usually they are related to the fact that a bad DNS response has been cached.
We have already contacted Juniper experts to find out if they know this bug or our first case. We have to conduct several tests of Flowspec and find out whether it is possible to limit the application of the rules to several data centers. We also plan to return money to accounts protected by SLA. We are categorically against an arbitrarily short time of unavailability of services and the CloudFlare team apologizes for this case.
The cause of the fall was an error on the border routers. CloudFlare now has 23 data centers around the world. They are connected to the Internet via routers. These routers made it so that packets sent to us from anywhere on the Internet usually reach our servers. When the router stops working, the network behind it stops being accessible to the Internet.
We regularly turn off one or more of our wonderful routers, for example, during any work. Due to the fact that we use Anycast, the traffic is redirected to the nearest data center. However, this morning we encountered an error that caused all of our routers.
')
Flowspec
All border routers that were prone to error were from Juniper. One of the reasons we like Juniper routers is support for the Flowspec protocol. It allows you to effectively distribute routing rules to a large number of routers. Here at CloudFlare, we are constantly updating the routing rules. This is necessary to protect against attacks and redirect traffic for the fastest possible service.
This morning we noticed a DDoS attack directed at one of our clients. The attack was directed exclusively at the DNS server. We have a special tool for creating attack signatures that are equally well understood for automated systems and for employees. Typically, these signatures are used to create routing rules that will reduce the number of “bad” requests.
In this case, our attack profiler determined that the “bad” packets were from 99.971 to 99.985 bytes in length. This is rather strange, because the length of a regular packet does not exceed 600 bytes, and the largest ones are up to 1,500 bytes. Our network has a limit of 4,470 bytes, but the profiler said that the attacker's packets are exactly that long.
Fatal rule
Someone from our team always monitors the network, 24/7. As usual, one of the operators took the profiler output and added a rule according to which all packets ranging in size from 99.971 to 99.985 bytes should be “dropped”. It looked like this in Junos, the Juniper operating system:
Flowspec accepted this rule and distributed it across the entire boundary network. In theory, no packet should fit this rule, because there could not be such large packets on the network. In fact, all routers accepted the rule and began to consume all the available RAM until they were stuck.
In the normal case, the router should automatically restart, but then for some reason this did not happen. We also could not access through the management ports. Even if some data center suddenly got up, he immediately went back, because all the traffic of the entire network was starting to go through it.
Sam Bowne, a professor at City College San Francisco, using BGPlay got this video, which shows how one by one the routers fall:
Incident response
The CloudFlare network team was aware of the incident from the very beginning. It was unclear why routers crashed, but it was obvious that packets could not find the path to our network. We were able to gain access to several routers and found out that they were falling because of that rule. We deleted it and then called operators in other data centers to reset the routers.
CloudFlare's 23 data centers are located in 14 countries, so the response time was somewhere around 30 minutes. At 10:49 UTC, all CloudFlare services were already running. We continue to investigate cases that our customers are still complaining about. Usually they are related to the fact that a bad DNS response has been cached.
We have already contacted Juniper experts to find out if they know this bug or our first case. We have to conduct several tests of Flowspec and find out whether it is possible to limit the application of the rules to several data centers. We also plan to return money to accounts protected by SLA. We are categorically against an arbitrarily short time of unavailability of services and the CloudFlare team apologizes for this case.
Source: https://habr.com/ru/post/171463/
All Articles