Functional monitoring in Yandex
Do you monitor your production in production? Whose responsibility do you have?
Often, when it comes to monitoring, server developers, system administrators, and DBAs come to mind, who need to keep track of data processing queues, free disk space, the viability of individual hosts, and the load.
Such monitoring really gives a lot of information about the service, but it does not always show how the service works for a real user. Therefore, as a supplement to system monitoring, we have created in Yandex a system of functional monitoring that monitors the status of the service through the target interfaces - through how the application looks and works in the browser, and how it works at the API level.
What is functional monitoring in our understanding? To better understand this, let's look at how things developed.
It all began, of course, with autotests for regression testing. These autotests were also launched after release in production to test the serviceability of the service under combat conditions. The fact that the regression tests launched in production sometimes find bugs made us think.
Why are functional tests written for regression testing and successfully tested, find problems in production?
We identified several reasons:
')
If such tests can find problems, we decided that we should try to run them regularly in production and monitor the status of services.
Let's take a closer look at the problems and tasks that functional monitoring can help with.
A good example of a page that depends on data providers is Yandex’s main page.
Weather and News, Poster and TV program, even a photo of the day with the search helmets - this is data from external and internal suppliers.
For example, in Arkhangelsk, the Billboard block once looked like this:

Whereas in Murmansk everything was in order.
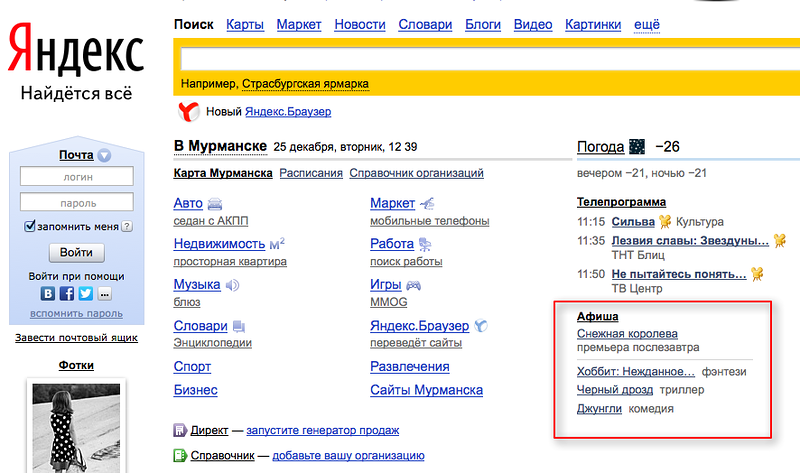
This happened because the supplier did not send data for Arkhangelsk (or the import was not updated on our side). Sometimes this problem is one-time in nature, and in some cases KPIs can be formulated according to the percentage of data available and their freshness.
Resiliency and performance play an important role in our services. Therefore, teams create services with a distributed architecture and load balancing mechanisms. The failure of individual “hardware”, as a rule, does not affect the users, however, large-scale problems with data centers or routing between them are noticeable in the end interfaces.
Functional monitoring, which supplement the system monitoring in this work, allows to track the connection of "iron" problems and functionality.
For example, in Yandex.Direct, there was a case when a slowly “perishing” server caused a gradual degradation of the service and its inaccessibility from certain regions. Functional monitoring in this case served as a trigger for urgent investigation and identification of the root of the problem.
Another interesting example is the teachings that are held in our company. During the exercise, one of the data centers is deliberately disconnected to make sure that this does not affect the performance of the services and to identify possible problems in time. Shutting down one data center is not detrimental to services, and functional monitoring helps to monitor the situation during such outages.
Actual operating conditions of an application in production sometimes create unforeseen situations. The cause of the problems may be an unexpected combination of volume, duration and type of load, or, for example, the accumulation of system errors that were not detected at the testing stage. The reason may also be errors in setting up the infrastructure, leading to a slowdown of the system or its failure.
If such problems cannot be identified at the testing stage, it is necessary to quickly recognize them if they occur in production. Here, system and functional monitoring can, complementing each other, find problems and report them.
So, functional monitoring is a functional autotest, “sharpened” to search for certain problems and constantly run in production.
There is a second component of functional monitoring - how the flow of results is processed.
A large stream of results coming from constantly running tests in production should be streamlined and filtered. It is necessary to promptly report problems and at the same time minimize false alarms. Also, there is the task of integrating information from functional monitoring into the overall system for assessing the serviceability of the service.
To prevent false positives, our system, implemented on the basis of the Apache Camel framework, allows us to aggregate several consecutive results from one test into one event. For example, you can configure filtering 3 out of 5, which allows you to notify about a breakdown only if the test generated an error 3 times in 5 consecutive runs (similarly, you can set, for example, filtering 2 of 2 or remove filtering - 1 of 1). It is also important how often the test is run, so that the delay with such filtering is acceptable.
On different projects, the consumers of these monitoring are different: somewhere, the results of monitoring are locked in by testers, it is interesting for managers to know about individual monitoring, somewhere the results are integrated into the overall system.
The idea of functional monitoring is very simple, and such monitoring can be very effective in work.
Recipe:
1. Analyze which parts of your service may break in production and why.
2. Write (or select from available) autotests for this functionality.
3. Run these tests in production as often as you need and as the test run systems allow.
4. Process the results and notify about breakdowns, compare with other sources of information about the life of the service.
PS: For a long time, we have been wondering how widespread the idea of functional monitoring is and how it is applied in other companies. Someone speaks about such an approach as a matter of course, someone, having learned, decides to implement it, and someone considers such monitoring as superfluous in the presence of systemic monitoring.
And how do you track the status of your services in production, what tools and their combinations do you use?
Often, when it comes to monitoring, server developers, system administrators, and DBAs come to mind, who need to keep track of data processing queues, free disk space, the viability of individual hosts, and the load.
Such monitoring really gives a lot of information about the service, but it does not always show how the service works for a real user. Therefore, as a supplement to system monitoring, we have created in Yandex a system of functional monitoring that monitors the status of the service through the target interfaces - through how the application looks and works in the browser, and how it works at the API level.
What is functional monitoring in our understanding? To better understand this, let's look at how things developed.
It all began, of course, with autotests for regression testing. These autotests were also launched after release in production to test the serviceability of the service under combat conditions. The fact that the regression tests launched in production sometimes find bugs made us think.
What is it and why
Why are functional tests written for regression testing and successfully tested, find problems in production?
We identified several reasons:
')
- Differences in the configuration of the test environment from the production.
- Problems with internal or external data providers.
- "Iron" problems affecting functionality.
- Problems manifested with time and / or under a specific load.
If such tests can find problems, we decided that we should try to run them regularly in production and monitor the status of services.
Let's take a closer look at the problems and tasks that functional monitoring can help with.
Data providers
A good example of a page that depends on data providers is Yandex’s main page.
Weather and News, Poster and TV program, even a photo of the day with the search helmets - this is data from external and internal suppliers.
For example, in Arkhangelsk, the Billboard block once looked like this:
Whereas in Murmansk everything was in order.
This happened because the supplier did not send data for Arkhangelsk (or the import was not updated on our side). Sometimes this problem is one-time in nature, and in some cases KPIs can be formulated according to the percentage of data available and their freshness.
"Iron" problems
Resiliency and performance play an important role in our services. Therefore, teams create services with a distributed architecture and load balancing mechanisms. The failure of individual “hardware”, as a rule, does not affect the users, however, large-scale problems with data centers or routing between them are noticeable in the end interfaces.
Functional monitoring, which supplement the system monitoring in this work, allows to track the connection of "iron" problems and functionality.
For example, in Yandex.Direct, there was a case when a slowly “perishing” server caused a gradual degradation of the service and its inaccessibility from certain regions. Functional monitoring in this case served as a trigger for urgent investigation and identification of the root of the problem.
Another interesting example is the teachings that are held in our company. During the exercise, one of the data centers is deliberately disconnected to make sure that this does not affect the performance of the services and to identify possible problems in time. Shutting down one data center is not detrimental to services, and functional monitoring helps to monitor the situation during such outages.
Service degradation over time
Actual operating conditions of an application in production sometimes create unforeseen situations. The cause of the problems may be an unexpected combination of volume, duration and type of load, or, for example, the accumulation of system errors that were not detected at the testing stage. The reason may also be errors in setting up the infrastructure, leading to a slowdown of the system or its failure.
If such problems cannot be identified at the testing stage, it is necessary to quickly recognize them if they occur in production. Here, system and functional monitoring can, complementing each other, find problems and report them.
So, functional monitoring is a functional autotest, “sharpened” to search for certain problems and constantly run in production.
What's inside
There is a second component of functional monitoring - how the flow of results is processed.
A large stream of results coming from constantly running tests in production should be streamlined and filtered. It is necessary to promptly report problems and at the same time minimize false alarms. Also, there is the task of integrating information from functional monitoring into the overall system for assessing the serviceability of the service.
To prevent false positives, our system, implemented on the basis of the Apache Camel framework, allows us to aggregate several consecutive results from one test into one event. For example, you can configure filtering 3 out of 5, which allows you to notify about a breakdown only if the test generated an error 3 times in 5 consecutive runs (similarly, you can set, for example, filtering 2 of 2 or remove filtering - 1 of 1). It is also important how often the test is run, so that the delay with such filtering is acceptable.
On different projects, the consumers of these monitoring are different: somewhere, the results of monitoring are locked in by testers, it is interesting for managers to know about individual monitoring, somewhere the results are integrated into the overall system.
Recipe
The idea of functional monitoring is very simple, and such monitoring can be very effective in work.
Recipe:
1. Analyze which parts of your service may break in production and why.
2. Write (or select from available) autotests for this functionality.
3. Run these tests in production as often as you need and as the test run systems allow.
4. Process the results and notify about breakdowns, compare with other sources of information about the life of the service.
PS: For a long time, we have been wondering how widespread the idea of functional monitoring is and how it is applied in other companies. Someone speaks about such an approach as a matter of course, someone, having learned, decides to implement it, and someone considers such monitoring as superfluous in the presence of systemic monitoring.
And how do you track the status of your services in production, what tools and their combinations do you use?
Source: https://habr.com/ru/post/170797/
All Articles