Generic and hybrid storage of records in the Teradata DBMS
Until recently, all DBMS working with structured data (and not only them) could be divided into 2 categories: storing records in a row format and storing records in a row format. This is a fundamental difference that affects how the rows of tables look at the level of the internal database storage mechanisms. For a long time, Teradata DBMS belonged to the first group, but with the release of the 14th version, it was possible to determine how to store data of a particular table - in the form of columns or rows. Thus, hybrid storage appeared. In this article we want to talk about why it is needed, how it is implemented and what benefits it gives.
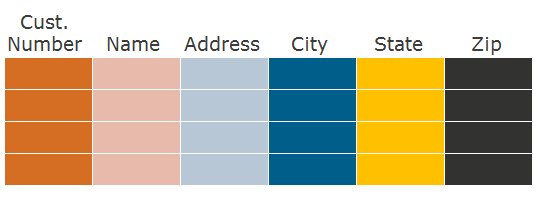
Before we talk about the format of storage by columns, let's say a few words about how we usually store data by rows. Take a relational table with columns and rows:
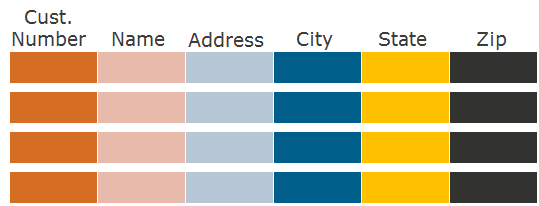
How do we write the data of this table to disk in the case of its line format? First, we write the first line, then the second, third, and so on:
How to minimize the load on the disk system when reading this table? You can use different methods to access it:
That is, minimizing the load on the disk system is based on the fact that we do not need to read the entire table, but only its individual rows.
What about the speakers? If the SQL query does not use all the columns of the table, but only some of them? When reading lines, we read every line from the disk completely. If there are 100 columns in the table, and only 5 of them are needed for a specific SQL query, then we are forced to read 95 columns from the disk that the SQL query does not use.
')
This is where the idea of storing data not in rows but in columns comes to mind. In the case of the storage format for columns - columnar - the approach is as follows: first, we write the first column on the disk, then the second, third, and so on:
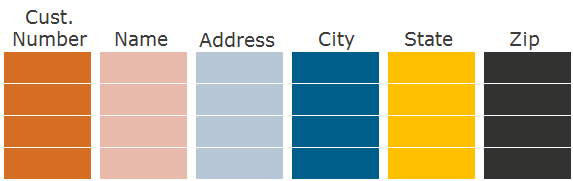
Such a partitioning of the table into columns creates partitions by columns . If the query needs only separate columns, then we read only the necessary partitions by column from the disk, significantly reducing the number of I / O operations when reading data that is needed by the SQL query.
An interesting feature of this approach is that partitions by rows and partitions by columns can be used simultaneously in the same table, in other words - partitions within partitions. First we go into the necessary partitions in columns, then inside them we read only the necessary partitions in rows.
Summarizing the above, Teradata Columnar is a data storage method in the Teradata DBMS, which allows tables to simultaneously use two partitioning methods:
The advantages are as follows:
Both of these points lead to a reduction in the load on the disk system. In the first case, we read a smaller amount of data, so we perform fewer I / O operations. In the second case, the table takes up less disk space, and as a result, fewer I / O operations are required to read it.
Reducing the load on the disk system reduces the response time in applications, since requests are executed faster. And it also increases the performance of the Teradata system as a whole — individual requests consume a smaller percentage of the system capacity for I / O operations, so the system can execute more such requests.
Storing data in columns significantly changes the mechanics of reading data from such a table. In fact, we need to “collect” data from separate column partitions to get the rows that the SQL query should return.
It looks like this. If the query has a WHERE condition for a column, then first scan this column. We filter the data, and for those rows that satisfy the WHERE condition, go to the neighboring partitions in columns and read the values of the remaining columns for these rows.
Example: What customers live in Sochi?
The format of rows (for comparison) reads the values of all columns when filtering by the City column (WHERE City condition = 'Sochi').
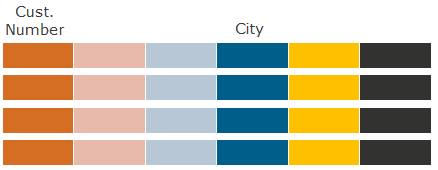
In the format of columns only the data of the columns City and Cust are read. Number - first filter the City column, then search for the corresponding Cust values. Number.

If there are several columns in the WHERE condition, first the most selective one is selected, the filter by which will lead to the largest clipping of rows, then the next WHERE column, etc. And then all the other columns involved in the request.
As for the mechanics of the transition between partitions of columns for “assembling” one row from separate columns, such a transition is carried out “positionally”. When reading a specific line, we know that in each column partition the value of the line we need is in the Nth position relative to the beginning of the table. To search for a string, a special rowid address row structure is used, which contains the partition number and the row number. This allows you to switch between partitions of columns, replacing the partition number within the rowid for the same row number. Thus, we collect the values of the columns for a single row together.
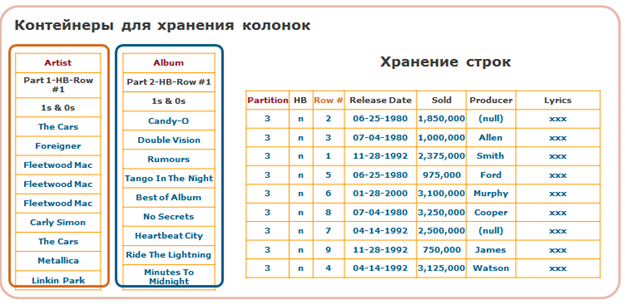
And if there are a lot of columns in the table? Then it will take more overhead to collect rows from individual columns. This effect can be avoided by creating separate partitions not for each column, but for groups of columns. If we know that some columns are often used together and rarely separately, then we place these columns in one partition. Then inside such a partition, the data of these columns can be stored in rows, as if it were a subtable. This method of storage is called hybrid: part of the data in the table is stored in columns, and part of the data in the same table is stored in rows.
Example (another table than before):
The only thing we can say is that the term “hybrid data storage” can be used not only for the above method of data storage, but also for storing data blocks on disks of different speeds, which we had a separate article about in Habrahabr.
We told about the exclusion of partitions in more detail than about data compression. Let us give him due attention.
Partitions by columns mean that the values of a single column are next to each other. This is very convenient for data compression. For example, if a column has slightly different values, then you can create a “dictionary” of frequently used column values and use it to compress data. Moreover, for one column there can be several such dictionaries - separately for different “containers”, into which the column is divided when it is stored on disk (by analogy with data blocks when stored in rows).
What is convenient - Teradata selects dictionaries automatically based on the data that is loaded into the table, and if the data changes over time, the dictionaries for data compression also change.
In addition to dictionaries, there are other data compression methods, such as run length encoding encoding, trimming, Null compression, delta storage, UNICODE in UTF8. We will not go into the details of each of them - let us just say that they can be used both separately and in combination with each other for the same data. Teradata can dynamically change the compression mechanism for a column if it brings the best result.
The goal of compression is to reduce the amount of data (in gigabytes) that the table occupies on disk. This allows you to store more data (in terms of the number of rows of the table) on the same hardware, as well as more data on fast SSD disks, if any.
Teradata Columnar is a great feature that allows you to increase query performance and compress data. However, it should not be considered as an ideal solution. The win will be obtained only for the corresponding data and SQL queries with certain characteristics. In other cases, the effect may even be negative - for example, when all queries use all the columns in a table and the data does not compress well.
Successful candidates for column storage are tables in which there are many columns, but each SQL query uses a relatively small number of them. In this case, different queries can use different columns, as long as each individual query uses only a small number of columns. In these cases, there is a significant reduction in the number of I / O operations and an improvement in I / O performance.
Splitting row data into separate columns when inserting data (insert) and then “collecting” column values back into rows when selecting data (select) - these operations consume more CPU for column tables than for normal ones. Therefore, it should be borne in mind that if the system has a significant shortage of CPU resources (the so-called CPU-bound-systems), then for them Teradata Columnar should also be used with care, as this can reduce the overall system performance due to lack of CPU resources.
One of the requirements for column tables is that the data is loaded into the table in large chunks of INSERT-SELECT. The reason is as follows: if you insert data "line by line", then for column tables it is very inconvenient, since instead of one row record (one input-output operation), as it would be for a regular table, here you need to write the values of the columns into different columns separately - dramatically increasing the number of input-output operations. However, this is typical for inserting just one line. If multiple rows are inserted at once, then writing a large set of rows is comparable in laboriousness in order to break up the same amount of data into columns and write these columns into the necessary partitions by columns.
For the same reason, in the column tables, the UPDATE and DELETE operations are time consuming, because you need to go into different partition partitions of the columns in order to perform these operations. However, laborious - this does not mean impossible. If the volume of such changes is relatively small, then Teradata Columnar is quite suitable for such tasks.
Another feature of the column tables is the absence of a primary index - a column that ensures the distribution of rows by AMPs in the Teradata system. Access by primary index is the fastest way to get rows in Teradata. There is no such index for the column tables, the No-Primary Index (No-PI) mechanism is used instead - when the data is evenly distributed by Teradata itself, but without the possibility of accessing this data by the primary index. This means that column tables should not be used for tables whose specific use implies the presence of a primary index.
These rules are not straightforward. Each situation should be analyzed separately. For example, you can create additional indexes to mitigate the effect of the absence of a primary index. Or another example: you can create a table in a row format, and on top of it a join index in a column format (a join index is a materialized view in Teradata, it can also be stored in a column format). Then queries that use many columns will refer to the table itself, and queries that have few columns will use the materialized view.
What is convenient - it is not at all necessary to declare all tables to be columnar. It is possible to create only a part of the tables in the format of columns, and the remaining tables in the format of rows.
In summary, Teradata Columnar is used for tables that have the following properties:
If you look closely, many very large tables that grow over time, just have these properties. Do you want them to take up less disk space and query them faster? Then the functionality of the Teradata Columnar is worth paying attention to.
To help those who perform physical modeling, determine which tables should or should not be created in column format, there is a special tool - the Columnar Analysis Tool. This tool analyzes the use of a particular table by SQL queries and gives recommendations on the applicability of the storage format by columns. There is also a lot of useful information, of course, in the Teradata 14 documentation.
What is Teradata Columnar?
Before we talk about the format of storage by columns, let's say a few words about how we usually store data by rows. Take a relational table with columns and rows:
How do we write the data of this table to disk in the case of its line format? First, we write the first line, then the second, third, and so on:
How to minimize the load on the disk system when reading this table? You can use different methods to access it:
- Access by index - if you need to read only a few lines.
- Access to its individual partitions (sections) - if the table is very large (for example, there are transactions for several years, but you need to read the data only for the last few weeks). These are partitions in rows .
- Full table reading - if you need to read a large percentage of the number of its rows.
That is, minimizing the load on the disk system is based on the fact that we do not need to read the entire table, but only its individual rows.
What about the speakers? If the SQL query does not use all the columns of the table, but only some of them? When reading lines, we read every line from the disk completely. If there are 100 columns in the table, and only 5 of them are needed for a specific SQL query, then we are forced to read 95 columns from the disk that the SQL query does not use.
')
This is where the idea of storing data not in rows but in columns comes to mind. In the case of the storage format for columns - columnar - the approach is as follows: first, we write the first column on the disk, then the second, third, and so on:
Such a partitioning of the table into columns creates partitions by columns . If the query needs only separate columns, then we read only the necessary partitions by column from the disk, significantly reducing the number of I / O operations when reading data that is needed by the SQL query.
An interesting feature of this approach is that partitions by rows and partitions by columns can be used simultaneously in the same table, in other words - partitions within partitions. First we go into the necessary partitions in columns, then inside them we read only the necessary partitions in rows.
Summarizing the above, Teradata Columnar is a data storage method in the Teradata DBMS, which allows tables to simultaneously use two partitioning methods:
- Horizontal partitions - in the lines
- Vertical partitions - by columns
Benefits of Teradata Columnar
The advantages are as follows:
- Increase query performance - by reading only individual partitions in columns, eliminating the need to read all the data in the rows of the table. This is exactly where we started our article.
- Efficient automatic data compression using an automatic compression mechanism. But this is an additional pleasant opportunity that opens when storing data by columns: in this case, the data is much more convenient to compress. Some even put this advantage in the first place, and rightly so.
Both of these points lead to a reduction in the load on the disk system. In the first case, we read a smaller amount of data, so we perform fewer I / O operations. In the second case, the table takes up less disk space, and as a result, fewer I / O operations are required to read it.
Reducing the load on the disk system reduces the response time in applications, since requests are executed faster. And it also increases the performance of the Teradata system as a whole — individual requests consume a smaller percentage of the system capacity for I / O operations, so the system can execute more such requests.
Reading data from a table stored in columns
Storing data in columns significantly changes the mechanics of reading data from such a table. In fact, we need to “collect” data from separate column partitions to get the rows that the SQL query should return.
It looks like this. If the query has a WHERE condition for a column, then first scan this column. We filter the data, and for those rows that satisfy the WHERE condition, go to the neighboring partitions in columns and read the values of the remaining columns for these rows.
Example: What customers live in Sochi?
The format of rows (for comparison) reads the values of all columns when filtering by the City column (WHERE City condition = 'Sochi').
In the format of columns only the data of the columns City and Cust are read. Number - first filter the City column, then search for the corresponding Cust values. Number.
If there are several columns in the WHERE condition, first the most selective one is selected, the filter by which will lead to the largest clipping of rows, then the next WHERE column, etc. And then all the other columns involved in the request.
As for the mechanics of the transition between partitions of columns for “assembling” one row from separate columns, such a transition is carried out “positionally”. When reading a specific line, we know that in each column partition the value of the line we need is in the Nth position relative to the beginning of the table. To search for a string, a special rowid address row structure is used, which contains the partition number and the row number. This allows you to switch between partitions of columns, replacing the partition number within the rowid for the same row number. Thus, we collect the values of the columns for a single row together.
Hybrid data storage in one table
And if there are a lot of columns in the table? Then it will take more overhead to collect rows from individual columns. This effect can be avoided by creating separate partitions not for each column, but for groups of columns. If we know that some columns are often used together and rarely separately, then we place these columns in one partition. Then inside such a partition, the data of these columns can be stored in rows, as if it were a subtable. This method of storage is called hybrid: part of the data in the table is stored in columns, and part of the data in the same table is stored in rows.
Example (another table than before):
The only thing we can say is that the term “hybrid data storage” can be used not only for the above method of data storage, but also for storing data blocks on disks of different speeds, which we had a separate article about in Habrahabr.
Saving disk space
We told about the exclusion of partitions in more detail than about data compression. Let us give him due attention.
Partitions by columns mean that the values of a single column are next to each other. This is very convenient for data compression. For example, if a column has slightly different values, then you can create a “dictionary” of frequently used column values and use it to compress data. Moreover, for one column there can be several such dictionaries - separately for different “containers”, into which the column is divided when it is stored on disk (by analogy with data blocks when stored in rows).
What is convenient - Teradata selects dictionaries automatically based on the data that is loaded into the table, and if the data changes over time, the dictionaries for data compression also change.
In addition to dictionaries, there are other data compression methods, such as run length encoding encoding, trimming, Null compression, delta storage, UNICODE in UTF8. We will not go into the details of each of them - let us just say that they can be used both separately and in combination with each other for the same data. Teradata can dynamically change the compression mechanism for a column if it brings the best result.
The goal of compression is to reduce the amount of data (in gigabytes) that the table occupies on disk. This allows you to store more data (in terms of the number of rows of the table) on the same hardware, as well as more data on fast SSD disks, if any.
When to use Columnar?
Teradata Columnar is a great feature that allows you to increase query performance and compress data. However, it should not be considered as an ideal solution. The win will be obtained only for the corresponding data and SQL queries with certain characteristics. In other cases, the effect may even be negative - for example, when all queries use all the columns in a table and the data does not compress well.
Successful candidates for column storage are tables in which there are many columns, but each SQL query uses a relatively small number of them. In this case, different queries can use different columns, as long as each individual query uses only a small number of columns. In these cases, there is a significant reduction in the number of I / O operations and an improvement in I / O performance.
Splitting row data into separate columns when inserting data (insert) and then “collecting” column values back into rows when selecting data (select) - these operations consume more CPU for column tables than for normal ones. Therefore, it should be borne in mind that if the system has a significant shortage of CPU resources (the so-called CPU-bound-systems), then for them Teradata Columnar should also be used with care, as this can reduce the overall system performance due to lack of CPU resources.
One of the requirements for column tables is that the data is loaded into the table in large chunks of INSERT-SELECT. The reason is as follows: if you insert data "line by line", then for column tables it is very inconvenient, since instead of one row record (one input-output operation), as it would be for a regular table, here you need to write the values of the columns into different columns separately - dramatically increasing the number of input-output operations. However, this is typical for inserting just one line. If multiple rows are inserted at once, then writing a large set of rows is comparable in laboriousness in order to break up the same amount of data into columns and write these columns into the necessary partitions by columns.
For the same reason, in the column tables, the UPDATE and DELETE operations are time consuming, because you need to go into different partition partitions of the columns in order to perform these operations. However, laborious - this does not mean impossible. If the volume of such changes is relatively small, then Teradata Columnar is quite suitable for such tasks.
Another feature of the column tables is the absence of a primary index - a column that ensures the distribution of rows by AMPs in the Teradata system. Access by primary index is the fastest way to get rows in Teradata. There is no such index for the column tables, the No-Primary Index (No-PI) mechanism is used instead - when the data is evenly distributed by Teradata itself, but without the possibility of accessing this data by the primary index. This means that column tables should not be used for tables whose specific use implies the presence of a primary index.
These rules are not straightforward. Each situation should be analyzed separately. For example, you can create additional indexes to mitigate the effect of the absence of a primary index. Or another example: you can create a table in a row format, and on top of it a join index in a column format (a join index is a materialized view in Teradata, it can also be stored in a column format). Then queries that use many columns will refer to the table itself, and queries that have few columns will use the materialized view.
What is convenient - it is not at all necessary to declare all tables to be columnar. It is possible to create only a part of the tables in the format of columns, and the remaining tables in the format of rows.
In summary, Teradata Columnar is used for tables that have the following properties:
- SQL queries are performed on separate sets of table columns.
OR
SQL queries are performed on a separate subset of table rows.
> The best result is when both - Data can be loaded with large INSERT-SELECTs.
- No or few update / delete operations
If you look closely, many very large tables that grow over time, just have these properties. Do you want them to take up less disk space and query them faster? Then the functionality of the Teradata Columnar is worth paying attention to.
To help those who perform physical modeling, determine which tables should or should not be created in column format, there is a special tool - the Columnar Analysis Tool. This tool analyzes the use of a particular table by SQL queries and gives recommendations on the applicability of the storage format by columns. There is also a lot of useful information, of course, in the Teradata 14 documentation.
Source: https://habr.com/ru/post/170321/
All Articles