Recommender system: text mining as a means of fighting a cold start
In the previous article I have already outlined the main directions for solving the cold start problem in the recommender system of web pages. Let me remind you that the problem of a cold start is divided into a cold start for users (what to show to new users) and a cold start for sites (who should recommend newly added sites). Today I will focus on the method of semantic analysis of texts (text mining) as a basic approach to solving the problem of cold start for new sites.
As we have already discussed , preprocessing of the text of a web page consists in highlighting the useful content of the page, rejecting stop words and lemmatization. This standard "gentleman's" set somehow appears in almost all tasks of text mining, and can be found in many ready-made software solutions , choosing what is needed for your particular application and development environment.
So, the first step in preprocessing is to build a dictionary of all the various words W found in the corpus D of texts, and to calculate the statistics of the occurrence of these words in each of the documents. Immediately I will note that all the methods described in this article will be based on the “bag of words” model, when the order of the words in the text is not taken into account. The context of the word can be taken into account at the stage of lemmatization. For example, in the sentence “we ate strawberries, and sprawling spruces grew along the edge”, the word “spruce” in the first case should be lemmatized as “is”, and in the second - as “spruce”. However, keep in mind that context support during lemmatization is a difficult task of natural language processing, not all lemmatizers are ready for this. With further analysis, the word order will not be taken into account at all.
The next step in word processing is calculating the TF-IDF weights for each word w in each d document:
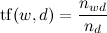
Where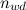 - the number of occurrences of the word in the document
- the number of occurrences of the word in the document  - the total number of words in this text;
- the total number of words in this text;
 ,
,
where | D | - the number of texts in the corpus, and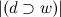 - the number of texts in which w occurs. Now
- the number of texts in which w occurs. Now
 .
.
Or a slightly more complicated option:
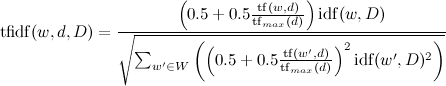 ,
,
Where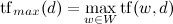 .
.
TF-IDF weights are needed to achieve two goals. Firstly, for too long texts, only words with the maximum TF-IDF are selected, and the rest are discarded, which reduces the amount of stored data. For example, for the methods of relevance feedback and LDA, which will be described below, it was enough for us to take N = 200 words with maximum weights of TF-IDF. Secondly, these weights will be further used for recommendations in the relevance feedback algorithm.
')
The relevance feedback algorithm brings us closely to the solution of the original problem and is designed to build recommendations based on the textual content of the pages and user likes (but without taking into account the likes of web pages). I’ll just say that the algorithm is suitable for recommendations of new sites, but it essentially loses to traditional methods of collaborative filtering if there are enough likes (10-20 likes and more).
The first step of the algorithm is to automatically search for keywords (tags) for each user by the history of his ratings (likes). To do this, calculate the weights of all words from web pages that are rated by the user:
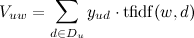 ,
,
Where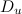 - all web pages that the user has liked / disliked,
- all web pages that the user has liked / disliked, 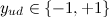 - rating that the user affixed. As a user profile, the specified number of words with the maximum weight (for example, 400 words) is selected.
- rating that the user affixed. As a user profile, the specified number of words with the maximum weight (for example, 400 words) is selected.
The distance from the user to the site is calculated as the scalar product of the weights vectors of the words of the user and the site:
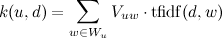 ,
,
Where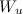 - words from the user profile.
- words from the user profile.
As a result, the algorithm allows to evaluate the similarity of any user who has likes, and any web page that has textual content. In addition, the algorithm is quite simple to implement and allows you to build an interpretable user profile, consisting of the key tags of his interests. When registering, you can ask the user to specify their key interests, which will make it possible to make recommendations for new users.
The LDA method in our blog has already been described in sufficient detail by Sergey Nikolenko. The algorithm is designed to describe texts in terms of their topics. The main assumption of the LDA model is that each document has several topics, mixed in some proportion. LDA is a probabilistic model of text generation, the training of which allows revealing for each document a probabilistic distribution by subject, which further allows solving a number of applied tasks, including the task of recommendations.
The specificity of our task is the availability of categories for each web page and for each user (total categories 63). The question arises: how to reconcile the received LDA topics with known categories? If you teach LDA without taking into account the division into categories, then you need to take a sufficiently large number of topics (more than 200), otherwise the LDA topics actually repeat the categories, and the result of the algorithm is the division into the same categories (music, science, religion, etc.) which we already know. End-to-end training can be useful for the task of identifying classification errors and recommending categories for new sites. For recommendations, however, it is better to train LDA in each category separately with a small number of LDA topics (5-7) per category. In this case, each category is automatically divided into subcategories, like this:

Once the LDA topics have been received for all sites, recommendations for each user can be made. For this, a logistic regression is learned for each user on the LDA topics of the sites that he has rated. Positive event here is Like, negative - dizlike. The length of the vector of regression parameters for the user is equal to the product of the number of LDA topics and the number of categories that have ever been marked by the user in the profile (if the user has disabled a category in his profile, then information on his preferences in this category will not be lost). The recommendation is based on the likelihood rating of the likes of the trained user regression parameters and the LDA topics of the sites in a standard way.
The quality of recommendations on the LDA topics is superior to the RF method. However, RF is simple to implement and allows you to get an interpreted user profile. In addition, RF works better with a very small number of words in the text (the threshold is 10-20 words). On the other hand, the LDA method allows to solve a number of side problems, namely:
Therefore, the combination of these two methods seems optimal. Both of them operate at the stage of “promotion” of new pages (until the site has gained enough likes for collaborative filtering to work at full capacity). If a page has all the content - it is 5-10 words (for example, a page with photos is often all textual content - this is a caption or caption), then it is advisable to use RF, otherwise LDA. For the above additional tasks, LDA topics are indispensable.
Good luck further studying text mining methods!
Preprocessing text content (preprocessing)
As we have already discussed , preprocessing of the text of a web page consists in highlighting the useful content of the page, rejecting stop words and lemmatization. This standard "gentleman's" set somehow appears in almost all tasks of text mining, and can be found in many ready-made software solutions , choosing what is needed for your particular application and development environment.
So, the first step in preprocessing is to build a dictionary of all the various words W found in the corpus D of texts, and to calculate the statistics of the occurrence of these words in each of the documents. Immediately I will note that all the methods described in this article will be based on the “bag of words” model, when the order of the words in the text is not taken into account. The context of the word can be taken into account at the stage of lemmatization. For example, in the sentence “we ate strawberries, and sprawling spruces grew along the edge”, the word “spruce” in the first case should be lemmatized as “is”, and in the second - as “spruce”. However, keep in mind that context support during lemmatization is a difficult task of natural language processing, not all lemmatizers are ready for this. With further analysis, the word order will not be taken into account at all.
TF-IDF (TF - term frequency, IDF - inverse document frequency)
The next step in word processing is calculating the TF-IDF weights for each word w in each d document:
Where
- the number of occurrences of the word in the document - the total number of words in this text; ,where | D | - the number of texts in the corpus, and
- the number of texts in which w occurs. Now .Or a slightly more complicated option:
,Where
.TF-IDF weights are needed to achieve two goals. Firstly, for too long texts, only words with the maximum TF-IDF are selected, and the rest are discarded, which reduces the amount of stored data. For example, for the methods of relevance feedback and LDA, which will be described below, it was enough for us to take N = 200 words with maximum weights of TF-IDF. Secondly, these weights will be further used for recommendations in the relevance feedback algorithm.
')
Relevant feedback (relevance feedback, RF)
The relevance feedback algorithm brings us closely to the solution of the original problem and is designed to build recommendations based on the textual content of the pages and user likes (but without taking into account the likes of web pages). I’ll just say that the algorithm is suitable for recommendations of new sites, but it essentially loses to traditional methods of collaborative filtering if there are enough likes (10-20 likes and more).
The first step of the algorithm is to automatically search for keywords (tags) for each user by the history of his ratings (likes). To do this, calculate the weights of all words from web pages that are rated by the user:
,Where
- all web pages that the user has liked / disliked, - rating that the user affixed. As a user profile, the specified number of words with the maximum weight (for example, 400 words) is selected.The distance from the user to the site is calculated as the scalar product of the weights vectors of the words of the user and the site:
,Where
- words from the user profile.As a result, the algorithm allows to evaluate the similarity of any user who has likes, and any web page that has textual content. In addition, the algorithm is quite simple to implement and allows you to build an interpretable user profile, consisting of the key tags of his interests. When registering, you can ask the user to specify their key interests, which will make it possible to make recommendations for new users.
Dirichlet latent distribution (latent Dirichlet allocation, LDA)
The LDA method in our blog has already been described in sufficient detail by Sergey Nikolenko. The algorithm is designed to describe texts in terms of their topics. The main assumption of the LDA model is that each document has several topics, mixed in some proportion. LDA is a probabilistic model of text generation, the training of which allows revealing for each document a probabilistic distribution by subject, which further allows solving a number of applied tasks, including the task of recommendations.
The specificity of our task is the availability of categories for each web page and for each user (total categories 63). The question arises: how to reconcile the received LDA topics with known categories? If you teach LDA without taking into account the division into categories, then you need to take a sufficiently large number of topics (more than 200), otherwise the LDA topics actually repeat the categories, and the result of the algorithm is the division into the same categories (music, science, religion, etc.) which we already know. End-to-end training can be useful for the task of identifying classification errors and recommending categories for new sites. For recommendations, however, it is better to train LDA in each category separately with a small number of LDA topics (5-7) per category. In this case, each category is automatically divided into subcategories, like this:
Once the LDA topics have been received for all sites, recommendations for each user can be made. For this, a logistic regression is learned for each user on the LDA topics of the sites that he has rated. Positive event here is Like, negative - dizlike. The length of the vector of regression parameters for the user is equal to the product of the number of LDA topics and the number of categories that have ever been marked by the user in the profile (if the user has disabled a category in his profile, then information on his preferences in this category will not be lost). The recommendation is based on the likelihood rating of the likes of the trained user regression parameters and the LDA topics of the sites in a standard way.
Let's sum up
The quality of recommendations on the LDA topics is superior to the RF method. However, RF is simple to implement and allows you to get an interpreted user profile. In addition, RF works better with a very small number of words in the text (the threshold is 10-20 words). On the other hand, the LDA method allows to solve a number of side problems, namely:
- automatically recommend categories when adding a new site;
- identify incorrectly classified sites;
- find duplicate websites, plagiarism, etc .;
- display the tags of the main topics of the site;
- display the main tags in one category or another.
Therefore, the combination of these two methods seems optimal. Both of them operate at the stage of “promotion” of new pages (until the site has gained enough likes for collaborative filtering to work at full capacity). If a page has all the content - it is 5-10 words (for example, a page with photos is often all textual content - this is a caption or caption), then it is advisable to use RF, otherwise LDA. For the above additional tasks, LDA topics are indispensable.
Good luck further studying text mining methods!
Source: https://habr.com/ru/post/170081/
All Articles