Parsing shopping sites. Personal experience and a little how-to
Let's divide parsing (scrapping) of sites into two subtasks.
We first describe the application:
There are a lot of parsing methods, regular expressions and a banal search for substrings. All these methods have one big drawback - with minor changes on the site, you need to edit the parser itself.
For myself personally (I write under .net on c #) I stopped at the HtmlAgilityPack library, for example , the description on Habré .
What it gives is that it reads HTML (even many not valid documents) and builds a DOM tree. And then the power of XPATH queries comes into play. With properly written XPATH requests, there is no need to edit the parser for changes on the site.
Example:
Classes are often used for orientation in the DOM, but more often minor changes in the site design are performed by adding the appropriate classes to the elements (it was class = ”productInfo” became class = ”productInfo clearfix”). Therefore, in XPATH it is better to write:
instead
Yes, it can affect performance, but not much. Universality of code is more important.
')
Similarly, when targeting in the tree using id elements, I, as a rule, use “//” (i.e. search across the entire subtree) instead of “/” (search only among child elements). This saves in situations where the designer wraps any tags (as a rule, for fixing some bug in the display):
instead
Parse we need basic information about the goods: name, picture and, most importantly, the list of properties. We will store the obtained data in a database with a primitive structure:

Those. for each product there will be a list of value pairs: property name (propertyName) and its value (propertyValue).
Suppose we wrote a parser, disassembled all the data from the site and now we want to create a database and a site to search for products by parameters. To do this, we need to structure the data.
Create a couple of tables in the database to store the structured data.
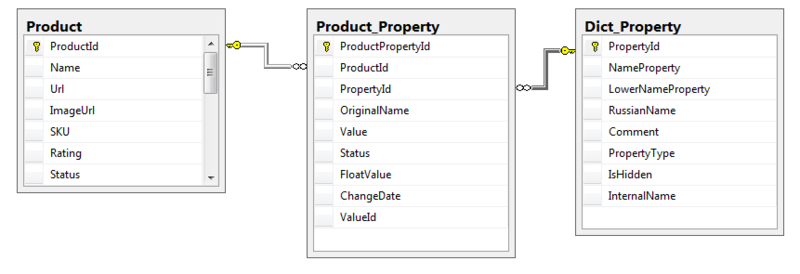
Dict_Property - a directory of properties (color, size, weight, etc., i.e. all the properties we will look for later)
Product_Property - the values of these properties for a particular product.
A small “trick” - the FloatValue field - for numeric properties, is formed by trying to convert the Value field to float:
It will be needed for the search (for example: the “weight” field, the query from 100 to 300 grams, the search by the “Value” text field will be slow and not correct, and by floatValue - fast and correct).
Now everything is ready to begin to structure the data.
Practice has shown that even the most poorly designed Chinese stores are trying to unify descriptions of goods.
Example: dx.com, parsed 1267 products. In total they have 49398 properties. If we group by name we get only 580 values, which in principle is not much.
We group the properties by name and by value, get a label (property, value, how many times it occurs) and sort them by frequency of occurrence.

It makes no sense to bring the whole table, we note a few points:
To structure the data, we will write an application for creating “parsing rules”. We introduce 2 types of rules:
- Actually parsing itself is a search for data that we are interested in on the pages.
- Comprehension of the data.
We first describe the application:
- Parser "constant" information about products from the site. This parser will be launched rarely (only to check for the availability of new products), it will parse the pages and extract information about the product from them: name, photos, properties.
- Parser conditionally variable information. This application will be launched frequently and automatically, it will parse the pages of the site to search for prices and availability in stock to update this information in the database (we will not consider it, there is nothing unusual here).
- Admin, structuring the data. This application will be launched after the parser of "permanent" information and allows the admin to parse / structure the data.
So, let's talk about parsers
There are a lot of parsing methods, regular expressions and a banal search for substrings. All these methods have one big drawback - with minor changes on the site, you need to edit the parser itself.
For myself personally (I write under .net on c #) I stopped at the HtmlAgilityPack library, for example , the description on Habré .
What it gives is that it reads HTML (even many not valid documents) and builds a DOM tree. And then the power of XPATH queries comes into play. With properly written XPATH requests, there is no need to edit the parser for changes on the site.
Example:
Classes are often used for orientation in the DOM, but more often minor changes in the site design are performed by adding the appropriate classes to the elements (it was class = ”productInfo” became class = ”productInfo clearfix”). Therefore, in XPATH it is better to write:
div[contains(@class,'productInfo')] instead
div[@class='productInfo'] Yes, it can affect performance, but not much. Universality of code is more important.
')
Similarly, when targeting in the tree using id elements, I, as a rule, use “//” (i.e. search across the entire subtree) instead of “/” (search only among child elements). This saves in situations where the designer wraps any tags (as a rule, for fixing some bug in the display):
div[@id='productInfo']//h1 instead
div[@id='productInfo']/h1 The next question is “what to parse?”
Parse we need basic information about the goods: name, picture and, most importantly, the list of properties. We will store the obtained data in a database with a primitive structure:
Those. for each product there will be a list of value pairs: property name (propertyName) and its value (propertyValue).
Suppose we wrote a parser, disassembled all the data from the site and now we want to create a database and a site to search for products by parameters. To do this, we need to structure the data.
Structuring data
Create a couple of tables in the database to store the structured data.
Dict_Property - a directory of properties (color, size, weight, etc., i.e. all the properties we will look for later)
Product_Property - the values of these properties for a particular product.
A small “trick” - the FloatValue field - for numeric properties, is formed by trying to convert the Value field to float:
update product_property set floatvalue = CASE WHEN ISNUMERIC(value + 'e0') = 1 THEN CAST(value AS float) ELSE null END It will be needed for the search (for example: the “weight” field, the query from 100 to 300 grams, the search by the “Value” text field will be slow and not correct, and by floatValue - fast and correct).
Now everything is ready to begin to structure the data.
Practice has shown that even the most poorly designed Chinese stores are trying to unify descriptions of goods.
Example: dx.com, parsed 1267 products. In total they have 49398 properties. If we group by name we get only 580 values, which in principle is not much.
We group the properties by name and by value, get a label (property, value, how many times it occurs) and sort them by frequency of occurrence.
It makes no sense to bring the whole table, we note a few points:
- The first 100 rows of the table (the most common property values) cover about 35-40% of all property values.
- A lot of properties and values that differ from each other only in the register or / and spaces / typos.
- Digital data - usually in the same format - for example, weight, size, amount of RAM.
To structure the data, we will write an application for creating “parsing rules”. We introduce 2 types of rules:
- Exact match. For example: the property "Color", the value "Black"
- Regular expression match. For example: the Weight property, the value
(?\d*\.?\d+)g
Source: https://habr.com/ru/post/169409/
All Articles