A little philosophical post about how we looked into the eyes
In the article I will tell a small story about a small technical puzzle and how it was solved by various people around. Perhaps this story will help the reader to learn a few lessons about what mistakes sometimes occur.
A little bit of matan incl.
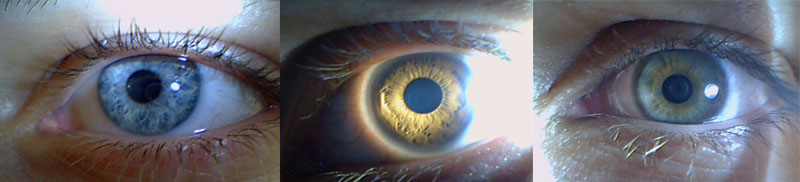
The idea to recognize people by the iris appeared in distant 1987 with Dr. John Dougman and was patented in 1989. At about the same time, a prototype appeared. At that time, it was the pinnacle of technology. A couple of years before the first commercial digital camera + image processing algorithm on computers of the i386 / i486 level. Until now, I have no idea how to get a stable result on such equipment.
The task about which I want to tell came into the world somewhere in 2006-2009. By this time, the processors were somewhat accelerated, good cameras appeared, the 1989 patent had expired, and eye recognition systems were now granted the right to make everyone. People who decided to make a clone of the system wanted to use modern technology and improve the algorithm. The very first thing that caught the eye - the old eye comparison algorithm used an image of the eye in the near IR range. The fact that the eyes are colored is not taken into account.
The iris of the eye is a unique characteristic of a person. The drawing of the iris is formed in the eighth month of intrauterine development, finally stabilizes at the age of about two years and practically does not change during life, except as a result of severe injuries or abrupt pathologies. The method is one of the most accurate among biometric methods.
The classic recognition algorithm for black and white eyes, consists of two parts - segmentation and comparison .
Segmentation is the selection of the eye itself in a photograph or in a video stream. The segmentation algorithm is highly dependent on the equipment used and the optical configuration. Unlike comparison, which is a mathematically rigorous problem, segmentation is a problem with too many variables. You always have to invent and customize something. Dougman in his patent proposed to look for the eye during segmentation as a circle for which the maximum gradient:

Here G is the operator of Gaussian image blur, and I (x, y) is the image itself. The number of hypotheses that need to be iterated is approximately equal to W ∙ H ∙ (R max -R min ), where W is the image width, H is its height, R max and R min are the maximum and minimum radii, respectively. The Dougman algorithm is an inside-out Hough transformation for circles. In its pure form, it is not applicable. The conversion of Hough itself is unstable, moreover, on modern Intel i7 processors, this operation for a 1.3 megapixel image without prior optimization is of the order of several seconds. There are many tricks and tricks to achieve work in real time.
One of the most beautiful is to use the lighting that gives a characteristic highlight on the pupil and look for this highlight. Such highlights are clearly visible here:

The task of searching for a highlight is computationally much simpler than the task of searching for an eye. And then the eye is searched for in the vicinity of the flare.
As a result of segmentation, the pupil and iris are detected. On the iris there are areas of interest for further use. The segmented area is obtained:

The second is often a comparison . After isolating the iris, it should be normalized for easy comparison with other irises. The iris unfolds from the polar coordinates into a rectangle and is filtered. As a filter, Dougman suggested using the Gabor filter , which allows emphasizing characteristic regions and reducing high-frequency noise:

Although, of course, the filter used is customized depending on the equipment. Transformed iris is called Iris Code . These irises look something like this:
 -An unfolded colored iris.
-An unfolded colored iris.
__________________________________________________________________________
 -An open black and white iris with a mask on top.
-An open black and white iris with a mask on top.
__________________________________________________________________________
 - Pure Iris Code .
- Pure Iris Code .
In order to compare two irises, for the received Iris Code, the Hamming distance is constructed, which in this case is a measure of the correlation of objects. The smaller the Hamming distance between the two codes, the closer they are to each other. If we compare a fairly large database of images with each other, calculate the Hamming distance for it, and construct the resulting histogram, we get the following distribution:

A left hump painted white will form a comparison of identical eyes with identical ones. The right hump drawn by black will form the comparison of different eyes between themselves. From this graph, a number is taken that separates the two humps well. Usually he is chosen closer to the left hump: to prevent a person is better than to miss a spy. For this chart it is something like 0.32.
Further, the system decides that a person can be skipped if the code of his eye has a distance of less than 0.32 with some other code from the database.
I and two other friends (one - Vasyutka , the second - Strepetarh ) started the topic of recognition in the eyes at the 4th year of MIPT. We needed to make a course project on information security. Then we made a simple eye recognition system using a webcam, a column case, a key fob and a clothes peg. Seeing how well it works (we won the institute competition and got a lot of positive feedback), we decided to finish it in a full system. Over the next year of unhurried programming, we brought the system to a completely working product. That's when investors came. But they wanted a strange one.
At the same time, when we looked into the eyes of our future investors, we came across the fact that the idea of recognizing eyes not from a black and white picture, but from a color one, was never patented anywhere. And being people who are technically savvy and possessing a commercial spirit they decided to get a patent. True, they did not know how to program, and even more so they did not understand the inherent mathematics.
')
Let's return to our sheep. At first, investors did not come to us, but to the only company that in Russia was engaged in eye recognition and had a finished product (ready-made scanner + algorithms). Investors have ordered a study on how color image recognition will improve statistics. The approach to the task of the company was terribly technical. They built the Iris Code for each RGB channel separately and compared three elements for the same person. In fact, we took the existing technology and invested new data into it.
Let's see what they did in reality. Lay the image into channels:

As mentioned above, to underline the image texture, it is customary to use a Gabor filter or some other mid-range filter that emphasizes the boundaries. He turns these pictures into:

As you can see, the structure for all colors is almost identical. The results of comparing eyes in different colors will almost always coincide. In a report written by that firm, this conclusion was brilliantly confirmed. Moreover, statistics with this recognition significantly deteriorates. After all, the color camera uses Bayer filter :

So, in order to have a color image of the same resolution as a black and white one needs to use four times smaller pixels, which, because of the filter, will collect three times less light. Which significantly reduces the signal-to-noise ratio.
The second problem with this approach is black eyes. In order to see something in them under white light, everything must be burned out.

In general, based on the above, the guys said that recognition by color eyes is impossible.
Thought 1. Well-proven methods will not always work in new conditions. If you are faced with a research task and known methods did not work - this does not mean that the problem is not solved.
If you follow the plot, then there would have to be a section on how we came and quickly resolved everything. I do not like linear narration. I'll tell you better first about how the rest of the world approached this problem in various institutions. We came across these studies after we had made a working algorithm for color recognition. And they looked with interest at the jungle of people that their scientific approach was able to bring.
The fact that when using color as RGB information is duplicated in each layer - it occurred to many. It would be logical to use a color space where the brightness information would be independent of the color. This is possible if the color of each pixel is considered as a kind of one-dimensional characteristic, so that two pixels can be compared. I think that almost all readers are familiar with the HSL ( HSV ) color space. In it, the color coordinates are specified in terms of brightness, saturation and hue (an analogue of wavelength).

The first work on this topic, I think, was this one . After it was a series of studies conducted at the Portuguese Institute . The researchers experimented with translating into different color spaces and comparing the images in them. They honestly checked all the standard color spaces: Lab , CMYK , HSV, etc. ... They isolated the irises and correlated them with each other. We constructed the distribution of FAR and FRR for all colors, as well as their statistical dependence on each other. Drew many beautiful plates. Painted the advantages and disadvantages of different color spaces. And it turned out that the wave is too unstable sign. Too much noise in it compared to the rest. And it's true! If you look at how the above eye looks in HSL space, you will notice that there are horrible noises in the H channel.

If you try to compare two images of the eye, the correlation will be much worse than in other channels. As a result, studies have shown that the only statistically independent brightness characteristic is eye color. After that, they happily dismounted it, as too noisy and unreliable.
Thought 2 . If the new research task is similar to the old one, then when solving it, first of all it is worth focusing on the differences. If the differences are insignificant, then does the new task make sense?
It must be admitted that they still received good statistics with their approach. For example, here in this article. True to reality, it no longer has any relation. In contrast to the previous study, it was not the real base of the eyes that was used, but the base obtained approximately as follows:

When shooting such a base, the head is fixed and a strong flash hits in the eye. The resolution is several times better than in any of the existing normal scanners.
In reality, the resolutions of the used eye scanners allow you to capture the eyes with an iris radius of 70-100 pixels. This is due to the strength of the permissible illumination and the depth of field of the system.
Thought 3 . Solving the real problem should be repelled primarily on the characteristics of the equipment used, and not on a beautiful mathematical model.
After the developers from the first company, where the investor had addressed, explained that color recognition is worse than recognition by B & W, the investor got worried. The patent is not cheap and required additional infusions of funds for its maintenance. The investor found us three days before they had to make a decision whether to leave the project or merge it. And already during these three days we have found the first solution, which allows us to improve the statistics. As always, an approach is implemented in such situations: “What would be faster to come up with in order for it to work.” Need to compare colored eyes? So let's compare BW and add a comparison for the average color of the eye. It turned out that the probability that the color of your eye coincides with a randomly taken eye is about 10% with 90% coincidence with yourself.
This was enough to improve the statistics by 3 times, which was not achieved by any of the above studies.
Satisfying the investor and pushing him to the fact that he remained in the subject and entered into an agreement with us, we began a real study. And already from the first step we went a different way than all the above works. Instead of solving the mathematical problem of comparing colored eyes, we began by solving a purely technical problem: “How do color cameras shoot eyes and how much light is required. Already after the first Asian with a practically black iris, we realized that we could not abandon the infrared spectrum. To do this, we had to use a color camera with an IR filter removed and with two backlight systems: infrared and color. The infrared part was supposed to provide a classic comparison, and the color part was to add an additional component that would make the system “stronger” than all the existing ones.
Having received a sufficient base of images of the eyes, we began to try to draw out additional information from the colored eyes. Of course, we tried the comparison in the RGB spectrum, making sure almost immediately that it does not give anything. And right after that, we came to a comparison in the HSL spectrum. By the way, an eye decomposed into HSL space above was obtained by a “good” method of photographing. The real eyes received by the camera look like this:

Over similar pictures we stupid a few days. Indeed, on the one hand, in the H and S channel contains new information. But on the other hand, it is very noisy, and slightly spatially correlated with BW eyes. The solution was simple and elegant. If we need information only about color, then we need to score on spatial information. Construct a histogram of color distribution for the eye. Such a histogram aligns the noise, averaging over them. According to such histograms, you can quickly compare, and most importantly, the result of recognition by such histograms for the H and S channels does not correlate with each other and does not correlate with the classical method of recognition of the black-and-white eyes:

Only twenty points of the histogram H give the intersection of the false tolerance curve and the false non-admission at the level of 6 percent. Approximately 10% gives S histogram. Of course, such percentages do not add up, they must be taken into account in a more cunning way. For example SVM .
All this research took us about 15 days and a half people. What is very funny to compare with scientific activities, which for several years have been around this subject in the articles above.
This story had two goals. The first is to tell a story with a small amount of matane, and kill your ten minutes to read it. The second is to pay attention to several problems in the development of algorithms that are often found around and which I myself regularly get into.
The first problem is overreliance on existing patterns. Often, when solving a new task, they try to reduce it to the existing algorithms. And you cannot say that it is bad. But the desire to go on the beaten track often devalues the entire work. The most enchanting example is the phrase I once met in some report: “This problem cannot be solved using OpenCV methods, which means it is insoluble.”
The second problem is excessive perfectionism. When a task is a little bit scientific, it gives rise to a whole tree of branching possibilities for its development. Far from every peak is something useful. It is often difficult, almost impossible, to focus on the goal that lies at the core of the task. Endless explorations of empty spaces begin. And the worst thing is that the modern scientific community encourages such an approach. And if in mathematics or theoretical physics it makes even a little sense, then in technical sciences it generates more and more “British scientists”. Index Hirsch witness. The feeling that this is already some kind of simulacrum, where even Popper with his tambourine is powerless ...
This is how you go between Scylla and Charybdis, solving the next task. And you can not repeat and dig. And what do you do in such cases?
A little bit of matan incl.
The idea to recognize people by the iris appeared in distant 1987 with Dr. John Dougman and was patented in 1989. At about the same time, a prototype appeared. At that time, it was the pinnacle of technology. A couple of years before the first commercial digital camera + image processing algorithm on computers of the i386 / i486 level. Until now, I have no idea how to get a stable result on such equipment.
The task about which I want to tell came into the world somewhere in 2006-2009. By this time, the processors were somewhat accelerated, good cameras appeared, the 1989 patent had expired, and eye recognition systems were now granted the right to make everyone. People who decided to make a clone of the system wanted to use modern technology and improve the algorithm. The very first thing that caught the eye - the old eye comparison algorithm used an image of the eye in the near IR range. The fact that the eyes are colored is not taken into account.
Little theory
The iris of the eye is a unique characteristic of a person. The drawing of the iris is formed in the eighth month of intrauterine development, finally stabilizes at the age of about two years and practically does not change during life, except as a result of severe injuries or abrupt pathologies. The method is one of the most accurate among biometric methods.
The classic recognition algorithm for black and white eyes, consists of two parts - segmentation and comparison .
Segmentation is the selection of the eye itself in a photograph or in a video stream. The segmentation algorithm is highly dependent on the equipment used and the optical configuration. Unlike comparison, which is a mathematically rigorous problem, segmentation is a problem with too many variables. You always have to invent and customize something. Dougman in his patent proposed to look for the eye during segmentation as a circle for which the maximum gradient:
Here G is the operator of Gaussian image blur, and I (x, y) is the image itself. The number of hypotheses that need to be iterated is approximately equal to W ∙ H ∙ (R max -R min ), where W is the image width, H is its height, R max and R min are the maximum and minimum radii, respectively. The Dougman algorithm is an inside-out Hough transformation for circles. In its pure form, it is not applicable. The conversion of Hough itself is unstable, moreover, on modern Intel i7 processors, this operation for a 1.3 megapixel image without prior optimization is of the order of several seconds. There are many tricks and tricks to achieve work in real time.
One of the most beautiful is to use the lighting that gives a characteristic highlight on the pupil and look for this highlight. Such highlights are clearly visible here:
The task of searching for a highlight is computationally much simpler than the task of searching for an eye. And then the eye is searched for in the vicinity of the flare.
As a result of segmentation, the pupil and iris are detected. On the iris there are areas of interest for further use. The segmented area is obtained:
The second is often a comparison . After isolating the iris, it should be normalized for easy comparison with other irises. The iris unfolds from the polar coordinates into a rectangle and is filtered. As a filter, Dougman suggested using the Gabor filter , which allows emphasizing characteristic regions and reducing high-frequency noise:
Although, of course, the filter used is customized depending on the equipment. Transformed iris is called Iris Code . These irises look something like this:
-An unfolded colored iris.__________________________________________________________________________
-An open black and white iris with a mask on top.__________________________________________________________________________
- Pure Iris Code .In order to compare two irises, for the received Iris Code, the Hamming distance is constructed, which in this case is a measure of the correlation of objects. The smaller the Hamming distance between the two codes, the closer they are to each other. If we compare a fairly large database of images with each other, calculate the Hamming distance for it, and construct the resulting histogram, we get the following distribution:
A left hump painted white will form a comparison of identical eyes with identical ones. The right hump drawn by black will form the comparison of different eyes between themselves. From this graph, a number is taken that separates the two humps well. Usually he is chosen closer to the left hump: to prevent a person is better than to miss a spy. For this chart it is something like 0.32.
Further, the system decides that a person can be skipped if the code of his eye has a distance of less than 0.32 with some other code from the database.
Prehistory
I and two other friends (one - Vasyutka , the second - Strepetarh ) started the topic of recognition in the eyes at the 4th year of MIPT. We needed to make a course project on information security. Then we made a simple eye recognition system using a webcam, a column case, a key fob and a clothes peg. Seeing how well it works (we won the institute competition and got a lot of positive feedback), we decided to finish it in a full system. Over the next year of unhurried programming, we brought the system to a completely working product. That's when investors came. But they wanted a strange one.
At the same time, when we looked into the eyes of our future investors, we came across the fact that the idea of recognizing eyes not from a black and white picture, but from a color one, was never patented anywhere. And being people who are technically savvy and possessing a commercial spirit they decided to get a patent. True, they did not know how to program, and even more so they did not understand the inherent mathematics.
')
The first call to the problem
Let's return to our sheep. At first, investors did not come to us, but to the only company that in Russia was engaged in eye recognition and had a finished product (ready-made scanner + algorithms). Investors have ordered a study on how color image recognition will improve statistics. The approach to the task of the company was terribly technical. They built the Iris Code for each RGB channel separately and compared three elements for the same person. In fact, we took the existing technology and invested new data into it.
Let's see what they did in reality. Lay the image into channels:
As mentioned above, to underline the image texture, it is customary to use a Gabor filter or some other mid-range filter that emphasizes the boundaries. He turns these pictures into:
As you can see, the structure for all colors is almost identical. The results of comparing eyes in different colors will almost always coincide. In a report written by that firm, this conclusion was brilliantly confirmed. Moreover, statistics with this recognition significantly deteriorates. After all, the color camera uses Bayer filter :
So, in order to have a color image of the same resolution as a black and white one needs to use four times smaller pixels, which, because of the filter, will collect three times less light. Which significantly reduces the signal-to-noise ratio.
The second problem with this approach is black eyes. In order to see something in them under white light, everything must be burned out.
In general, based on the above, the guys said that recognition by color eyes is impossible.
Thought 1. Well-proven methods will not always work in new conditions. If you are faced with a research task and known methods did not work - this does not mean that the problem is not solved.
Research approach, aka approach of British scientists
If you follow the plot, then there would have to be a section on how we came and quickly resolved everything. I do not like linear narration. I'll tell you better first about how the rest of the world approached this problem in various institutions. We came across these studies after we had made a working algorithm for color recognition. And they looked with interest at the jungle of people that their scientific approach was able to bring.
The fact that when using color as RGB information is duplicated in each layer - it occurred to many. It would be logical to use a color space where the brightness information would be independent of the color. This is possible if the color of each pixel is considered as a kind of one-dimensional characteristic, so that two pixels can be compared. I think that almost all readers are familiar with the HSL ( HSV ) color space. In it, the color coordinates are specified in terms of brightness, saturation and hue (an analogue of wavelength).
The first work on this topic, I think, was this one . After it was a series of studies conducted at the Portuguese Institute . The researchers experimented with translating into different color spaces and comparing the images in them. They honestly checked all the standard color spaces: Lab , CMYK , HSV, etc. ... They isolated the irises and correlated them with each other. We constructed the distribution of FAR and FRR for all colors, as well as their statistical dependence on each other. Drew many beautiful plates. Painted the advantages and disadvantages of different color spaces. And it turned out that the wave is too unstable sign. Too much noise in it compared to the rest. And it's true! If you look at how the above eye looks in HSL space, you will notice that there are horrible noises in the H channel.
If you try to compare two images of the eye, the correlation will be much worse than in other channels. As a result, studies have shown that the only statistically independent brightness characteristic is eye color. After that, they happily dismounted it, as too noisy and unreliable.
Thought 2 . If the new research task is similar to the old one, then when solving it, first of all it is worth focusing on the differences. If the differences are insignificant, then does the new task make sense?
It must be admitted that they still received good statistics with their approach. For example, here in this article. True to reality, it no longer has any relation. In contrast to the previous study, it was not the real base of the eyes that was used, but the base obtained approximately as follows:
When shooting such a base, the head is fixed and a strong flash hits in the eye. The resolution is several times better than in any of the existing normal scanners.
In reality, the resolutions of the used eye scanners allow you to capture the eyes with an iris radius of 70-100 pixels. This is due to the strength of the permissible illumination and the depth of field of the system.
Thought 3 . Solving the real problem should be repelled primarily on the characteristics of the equipment used, and not on a beautiful mathematical model.
Our appearance
After the developers from the first company, where the investor had addressed, explained that color recognition is worse than recognition by B & W, the investor got worried. The patent is not cheap and required additional infusions of funds for its maintenance. The investor found us three days before they had to make a decision whether to leave the project or merge it. And already during these three days we have found the first solution, which allows us to improve the statistics. As always, an approach is implemented in such situations: “What would be faster to come up with in order for it to work.” Need to compare colored eyes? So let's compare BW and add a comparison for the average color of the eye. It turned out that the probability that the color of your eye coincides with a randomly taken eye is about 10% with 90% coincidence with yourself.
This was enough to improve the statistics by 3 times, which was not achieved by any of the above studies.
Satisfying the investor and pushing him to the fact that he remained in the subject and entered into an agreement with us, we began a real study. And already from the first step we went a different way than all the above works. Instead of solving the mathematical problem of comparing colored eyes, we began by solving a purely technical problem: “How do color cameras shoot eyes and how much light is required. Already after the first Asian with a practically black iris, we realized that we could not abandon the infrared spectrum. To do this, we had to use a color camera with an IR filter removed and with two backlight systems: infrared and color. The infrared part was supposed to provide a classic comparison, and the color part was to add an additional component that would make the system “stronger” than all the existing ones.
Having received a sufficient base of images of the eyes, we began to try to draw out additional information from the colored eyes. Of course, we tried the comparison in the RGB spectrum, making sure almost immediately that it does not give anything. And right after that, we came to a comparison in the HSL spectrum. By the way, an eye decomposed into HSL space above was obtained by a “good” method of photographing. The real eyes received by the camera look like this:
Over similar pictures we stupid a few days. Indeed, on the one hand, in the H and S channel contains new information. But on the other hand, it is very noisy, and slightly spatially correlated with BW eyes. The solution was simple and elegant. If we need information only about color, then we need to score on spatial information. Construct a histogram of color distribution for the eye. Such a histogram aligns the noise, averaging over them. According to such histograms, you can quickly compare, and most importantly, the result of recognition by such histograms for the H and S channels does not correlate with each other and does not correlate with the classical method of recognition of the black-and-white eyes:
Only twenty points of the histogram H give the intersection of the false tolerance curve and the false non-admission at the level of 6 percent. Approximately 10% gives S histogram. Of course, such percentages do not add up, they must be taken into account in a more cunning way. For example SVM .
All this research took us about 15 days and a half people. What is very funny to compare with scientific activities, which for several years have been around this subject in the articles above.
Afterword
This story had two goals. The first is to tell a story with a small amount of matane, and kill your ten minutes to read it. The second is to pay attention to several problems in the development of algorithms that are often found around and which I myself regularly get into.
The first problem is overreliance on existing patterns. Often, when solving a new task, they try to reduce it to the existing algorithms. And you cannot say that it is bad. But the desire to go on the beaten track often devalues the entire work. The most enchanting example is the phrase I once met in some report: “This problem cannot be solved using OpenCV methods, which means it is insoluble.”
The second problem is excessive perfectionism. When a task is a little bit scientific, it gives rise to a whole tree of branching possibilities for its development. Far from every peak is something useful. It is often difficult, almost impossible, to focus on the goal that lies at the core of the task. Endless explorations of empty spaces begin. And the worst thing is that the modern scientific community encourages such an approach. And if in mathematics or theoretical physics it makes even a little sense, then in technical sciences it generates more and more “British scientists”. Index Hirsch witness. The feeling that this is already some kind of simulacrum, where even Popper with his tambourine is powerless ...
This is how you go between Scylla and Charybdis, solving the next task. And you can not repeat and dig. And what do you do in such cases?
A pair of small additions
- Someday, I hope, I will fill in an article on the subject of iris scanners and the process of their development. There will be a lot of funny monstrous pictures.
- The devices with the algorithms that we developed for the investor were never released to the market for a variety of reasons. And we keep the algorithms for BW in a more or less alive state.
- The developers, to whom the investor came first, must be said, although they tried to solve the problem to be extremely drastic, but they took out very valuable material from the work. Ever since their scanners have a white light, which causes the pupil to shrink, increasing the working field.
Source: https://habr.com/ru/post/167849/
All Articles