How we did our last amateur translation
 I already wrote an article on the subject of amateur translation, where I tried to describe the cuisine of this process. But, in my opinion, this experience was not entirely successful. Due to the large number of approaches it is impossible to describe everything, but an excessive generalization of the essence does not reflect. Therefore, I decided to describe one particular case, quite indicative, in my opinion.
I already wrote an article on the subject of amateur translation, where I tried to describe the cuisine of this process. But, in my opinion, this experience was not entirely successful. Due to the large number of approaches it is impossible to describe everything, but an excessive generalization of the essence does not reflect. Therefore, I decided to describe one particular case, quite indicative, in my opinion.To be honest, this is not really about our last translation. The fact is that the idea to write this article came to me when our business was in decline and the word “last” really meant our final work on this scene. But, having applied the professional approach to the project and the experience gained as a result of real work experience, I realized that you can live with this and firmly decided that we should complete another translation, which we have been looking forward to for more than two years. So under current circumstances, this word means rather "the last at the time of this writing."
This is not about playing on a PC, it would be too boring - because there is not that exotic and romance reverse engineering that is inherent in the insides of console games. It's about playing on the Nintendo Wii.
')
I apologize in advance for an overblown article and a boring second half, but, as they say, you can’t throw words out of a song.
Prehistory
 It all started somewhere in 2010, the exact date is not even remember. When I was still a student, and Dangaard (the author of the articles about wild geese and Little Red Riding Hood that many people liked) had been doing amateur translations for quite a long time: I wrote tools, and he translated. And we had one bad habit - to start translating any toy you like, which is why the number of abandoned projects we have quite a lot exceeds the number of completed ones. One of our favorite gaming series was and still is the notorious Metroid, a two-dimensional walker, the founder of the Metroidvania genre, and I always wanted to see how well this genre was transferred to 3D in the games of the Metroid Prime series that went on the Nintendo GameCube and Wii.
It all started somewhere in 2010, the exact date is not even remember. When I was still a student, and Dangaard (the author of the articles about wild geese and Little Red Riding Hood that many people liked) had been doing amateur translations for quite a long time: I wrote tools, and he translated. And we had one bad habit - to start translating any toy you like, which is why the number of abandoned projects we have quite a lot exceeds the number of completed ones. One of our favorite gaming series was and still is the notorious Metroid, a two-dimensional walker, the founder of the Metroidvania genre, and I always wanted to see how well this genre was transferred to 3D in the games of the Metroid Prime series that went on the Nintendo GameCube and Wii.And at some point I became the proud owner of the Wii, and, of course, immediately decided to satisfy my curiosity. I don’t know why, but in the first minutes of the gameplay, the first part of Metroid Prime didn’t impress me very much - apparently, the unusual control had an effect, and I didn’t have time to get to it, because rather I wanted to try out other games. However, taking into account the fact that the first two parts were only a port with the GameCube, unlike the third, which initially went on the Wii, I decided to look at it. I stopped looking at it in about six hours, and was very impressed with the amount of information in the game - literally every object could be scanned, having received brief information or even a whole article.
His eyes lit up with the idea, and his hands had already begun to perform the already familiar initiation ceremony - the launch of the right toolkit. So the project of this translation was born.
Unfortunately, I can’t tell you about the difficulties of translating game texts, so the technical and organizational aspects of the process will be mainly considered.
Looking for resources
So, the first thing was to get to the game files for the purpose of reverse engineering. It was necessary to do this in any available way, so I already drove the corresponding request into Google. First, the WiiScrubber program, designed to block unused areas of the game disc image with zeros, turned up first, so that it could be better compressed (more precisely, because of its encryption, it was compressed at least somehow), which also knows how to open it. It is worth noting that this program played its role during the project, but more on that later.
Opening the image and examining its contents, I first noticed the large files with the extension * .pak. Undoubtedly, they were prime suspects for storing game resources, and one of the copies was already being prepared for preparation in a hex editor.
Hidden screenshot
At the beginning of the file, a primitive header was visible, starting with a record of the form:
struct PakHeader { uint32 unknown; // version? uint32 totalHeaderSize; uint64 unknown; // hash? }; The following useful data began at an offset of 0x40, which made it possible to draw conclusions about the alignment of data to a block size of 64 bytes. Some identifiers were clearly distinguished from this data: STRG, RSHD and DATA. I didn’t have to go to the fortuneteller - it became obvious that the archive was divided into segments, or sections. After each identifier followed by a value that is a multiple of 64, there were two obvious options: either size or offset.
Hidden screenshot
Since the next block of data had a size of 0x800 bytes, and the same value followed the identifier of the first segment, it became obvious that these were all sizes.
struct SectionRecord { char name[4]; uint32 size; }; With sections everything is clear, it remains to determine their purpose. Here, on an intuitive level, identifiers helped - in the head the abbreviations themselves lined up in the words " str in g s", " r e s ource h ea d ers" and, oddly enough, " data ". Having scrolled through everything and considering that the STRG section in some archives is empty, I decided to familiarize myself with the RSHD section first.
Hidden screenshot
Again, it is completely self-evident that this section is a table with information about files stored in the archive. In the data file itself, identifiers were viewed - TXTR, SCAN, STRG, etc., i.e. files are typed and that is good. Based on the intuition and structure of the section table, I assumed that the first 4 bytes are their number. To verify this, I acted standard: I calculated the size of the record, calculating the distances between the beginnings of neighboring identifiers (24 bytes) and multiplying by this very value (0x1CA). I rounded the resulting value (0x2AF0) to the multiplicity of 0x40, getting 2B00. As expected, it matched the size shown in the section table.
Now it remains to make out the format of the file entry itself. With the identifier everything is clear - it indicates the type of file. In addition to it, I expected to find at least some identifier of the file itself, as well as its size and offset in the archive.
Hidden screenshot
By visual analysis, I identified some patterns. The first number is always 0 or 1, therefore it is most likely that this is a boolean value. Given that this is an archive, it is quite possible that this is a compression flag. Next came the ID, which I figured out. Behind it - 8 bytes of chaotic information, very similar to a certain hash and, it seems, is the file identifier. The last two values were: both multiples of 0x40, but the latter increased with the number of records. The conclusion asked for himself: the size and offset of the file. Since the offset of the first file is zero, it is clear that it is indicated relative to the beginning of the segment.
Having jumped on the specified displacements and popribavlja to them the sizes, I was convinced of the guesses and it was necessary only to write it in the form of structure:
struct FileRecord { uint32 packed; char type[4]; uint8 hash[8]; uint32 size; uint32 offset; }; Then I was interested in the data files themselves. Information about their position in the archive and the size was known, so I quickly sketched a simple extractor and took out the contents of one of the archives as is. After reviewing a couple of files, I realized that they are really packed. But I already knew the algorithm - many years of experience in such activities made themselves felt, and one glance at the hex editor was enough. It only remained to make sure that the experience does not deceive me, and I fed one of the files to the STUNS program, which perfectly revealed some common compression algorithms. I was not mistaken, it was LZO .
Before writing the unpacker, it was necessary not only to determine the compression algorithm, but also to find out the data structure. I took one of these files and began to pick it. Thanks to STUNS, I knew the position of the compressed data stream, but other than that, there was other information in the packed file.
Hidden screenshot
First of all, it was obvious that all such files have a signature - CMPD. It was followed by the value that occurs in three variants - 1, 2, and very rarely - 3. I decided that this was some type or version of the format, without first attaching this value. The next byte kept an unknown value in itself, and the next three - the file size minus 16. This gave me a reason to believe that the first 16 bytes of the file are the header. After analyzing the values of the unknown byte, I saw that only one or two bits often differ, and decided that these are some flags. Then there were four more bytes, equal to the size of the unpacked file, spit out to me by STUNS, the conclusions are obvious, this is the size of the source data.
16 bytes came to an end, according to STUNS, after another two bytes, the compressed stream itself began. I was sure that this was one of the classic schemes: the size of the data portion is indicated in two bytes, then the portion of the packed data itself follows, and so on until the stream ends. And indeed, the values of these two bytes coincided with the size of the stream.
Having processed the received information, I have made structure of heading.
struct CompressedFileHeader { char signature[4]; uint32 type; unsigned flags : 8; unsigned lzoSize : 24; uint32 dataSize; }; Now it was clear how to read these files, and I climbed behind the good old miniLZO . Thanks to its mini-framework and the widespread use of self-made abstractions for threads, the implementation of unpacking the LZO stream did not take much time or code lines.
Show code
while (streamSize > 0) { const uint16 chunkSize = input->readUInt16(); streamSize -= 2; input->read(inBuf, chunkSize); streamSize -= chunkSize; uint32 size = 0; lzo_decompress(inBuf, chunkSize, outBuf, &size); output->write(outBuf, size); } Having raised my primitive extractor in rank to the distributor, I first made sure that I correctly understood the purpose of the Boolean field in the archive file table. It turned out that, in fact, the files for which it is false were not packaged. Reassured, I took it into account in the code, set the program on one of the large files and began to look at the progress with satisfaction ...
But successfully complete the work of the program was not destined. An attempt to unpack the first TXTR file was crowned. It was then that I realized that it was not for nothing that there was some kind of versioning of these files. Having opened one of the compressed textures in the hex editor, I began to look for differences.
Hidden screenshot
Of course, as a type there was no longer one. The first thing that caught my eye was the difference in the size of the header: it became more than 20 bytes. In this case, now in the header there were two values 12 and another 12 new bytes. I had one guess and I climbed to look for an example of an uncompressed texture. Having found one, I looked at its beginning and saw that it was very similar to those 12 bytes, which, along with other things, were added to the header.
Everything became clear: compressed files of this type allow you to read a certain amount of information without resorting to unpacking - part of the data is simply stored in its original form right before the beginning of the stream. In the case of textures, their title remained unpacked, i.e. it was possible without extra calculations to find out the width, height, and type of such a texture. Very resourceful, worth noting. But I was embarrassed that the size of this data is given in duplicate. Having gone through all the available compressed textures, I didn’t see any other option, and I realized that it doesn’t play a role, but I assumed for myself that the second number is either the amount of data taking into account alignment by 4 bytes or the position from which to start unpacking flow.
I launched the unpacker again, and this time it managed, but due to the large number of files, it took quite a long time. Then I added the option of selective unpacking to it, by file type, and began to run through all the files. I was expecting another crash, because of one more type of compressed files, but it turned out that none of the files of interest were packaged in such a way and I decided not to waste time on unnecessary research - there was still a lot of work ahead and so much more.
The final version (pseudocode)
enum CompressedFileType { typeCommon = 1, typeTexture = 2, typeUnknown = 3 }; struct StreamHeader { unsigned flags : 8; unsigned lzo_size : 24; uint32 file_size; }; struct CompressedFileHeader { char signature[4]; uint32 type; if (commonHeader.type == typeTexture) { uint32 uncompressedChunkSize; uint32 uncompressedChunkSize2; // always equals to uncompressedChunkSize } StreamHeader streamHeader; if (commonHeader.type == typeTexture) { uint8 uncompressedData[uncompressedChunkSize]; } }; All that remains is to deal with the STRG section. It began with a value of 0x4C, then the data alternated cyclically: a null-terminated string, a type identifier, and a hash present in the file table. Of course, counting the number of such cycles, I received 0x4C. Of course, these were the names of some files - apparently, for those files that are requested not by hash, but by name.
struct NameRecord { char name[]; // C-string char type[4]; uint8 hash[8]; }; In essence, this entire section is a serialized display of hashes (or pairs [hash, type]) in the file name.
Now I had access to all the necessary resources, and it was time to explore them.
Chasing the text
Next, it was first necessary to extract the text, so that Dangaard began to translate it while I continue to deal with the technical part. Even before I figured out the archives, I tried to find signs of text in files like TXTR, but as it turned out later, TXTR does not mean “text resource”, but only derived from the word “texture”. Of course, the text was stored in files of type STRG.
I saw a lot when analyzing text data serialization techniques, therefore, opening one of these files in the hex editor, I was ready for anything. And not for nothing, as it turned out, because the case turned out not trivial.
Hidden screenshot
My view immediately attracted the line "ENGLJAPNGERMFRENSPANITAL" - an enumeration of the six languages supported by the game. Through the text in the second half of the file, it was clear that the file actually contains lines in all these languages. All that followed before the identifiers of languages looked like a painful title, and the other files had the same picture, so I agreed on that: the first 24 bytes are the title.
Then I began to compare the facts known to me with the values of this heading. For example, it was obvious that the file contains two lines of data for six languages, so the semantics of the values 6 and 2 did not cause questions. Similarly, everything was obvious with the first four bytes: signatures are common. However, the next 4 bytes, although they seemed to be an innocuous version of the format due to the lack of communication with any other data in the file, but after the experience with compressed files, I was still suspicious. Just in case, I looked at a couple of dozens of files, and everywhere I saw the same three, calming down on it. The title finished with two null values, which I wrote off to reserved fields, which are quite common in binary formats.
struct Header { uint32 signature; uint32 version; uint32 langCount; uint32 stringsCount; uint32 reserved1; uint32 reserved2; }; I dealt with the list of language identifiers. Further, logically, followed by a table of offsets of lines, and then the lines themselves. Well, it is necessary to pick it up. There are six languages and two lines in the file, but there are not 12, but 18 values in the table - it means for each language there is one more value in addition to the offsets for two lines.
By cyclically increasing the values, it can be seen that the offsets for each language are grouped together, and not, for example, alternate with offsets of other languages. But each such group is preceded by an incomprehensible value, and then followed by the offset of the lines relative to the beginning of the first line. The lines themselves are stored in the same way as is done in Delphi: first comes the length of the string, then its data. In this case, the string is null-terminated. Returning to an unknown value, I could not help but check one guess and summed up the lengths of all the strings of the first language. But this is really the sum of the lengths of the lines of a language! Now everything has become very clear.
struct OffsetTable { uint32 totalStringsLength; uint32 stringOffsets[header.stringCount]; }; Hidden screenshot
It's time to write a deserializer. From the text of European languages, it was obvious that UTF-8 was used. At that time, I didn’t jump from Delphi to C ++ not very long ago, and because of the presence of some developments in Delphi, and also because of VCL knowledge and only superficial knowledge of STL, I often sinned because I wrote some of the Delphi toolkit. Since on the same Delphi I had an old proven library for serializing text into a readable and easily editable format, I decided to resort to this technique. To my shame, although I tried to resort to OOP and other benefits of civilized code descriptions, I often sinned with a LAP code, so I had trouble writing this article, recalling some details.
In general, the section of WinApi documentation required for decoding UTF-8 was studied, the deserializer was written and, after a brief debugging, tested on the prepared file. Great, it's time to extract the game script! I extracted all the existing STRG files from the archives and set a deserializer on them ... Of course, I was waiting for a trick, and he was. Something I did not take into account, and again caught the crash.
I opened the problem file, and saw that I got excited, designating some header fields as reserved.
Hidden screenshot
Choice0, choice1 ... Why, it's the string identifiers! This means that some lines can be assigned such identifiers in order to access them not by the index, but by these identifiers. The first “reserved” field turned out to be the number of these identifiers, and then the size of the section that was placed next followed.
struct Header { uint32 signature; uint32 version; uint32 langCount; uint32 stringCount; uint32 idCount; uint32 idsSectionSize; }; At the beginning of the section there was a table, which turned out to be a simple array of offsets and row indices for which these identifiers are intended. The table was followed by the identifiers themselves in the form of null-terminated strings.
struct IdRecord { uint32 offset; uint32 index; }; It's time to fix the deserializer according to the new data and start the process again. This time, the problem files were swallowed without any problems and the progress went further. I was already preparing to celebrate the victory, but my sense of satisfaction with the work done was suddenly interrupted by another crash ... Well, no stranger. I repeat the standard procedure again, opening the problem file in the hex editor.
Hidden screenshot
Still, I was not mistaken with the header field that stores the format version. But I did not think that the other versions are generally used by the game. I had to disassemble this version as well, since it was quite simple.
The first 16 bytes of the header were identical to the previously investigated format. Then immediately followed information about languages, but in a slightly different form.
struct LangSectionRecord { char langId[4]; uint32 offset; uint32 size; }; But then just followed the last 8 bytes of the header and section identifiers in the same format. So, in that format, these 8 bytes were not part of the header.
The latter were followed by sections with linguistic data. At the beginning of each section was a list of row offsets. The lines themselves this time were stored in unicode and were simply null-terminated, without specifying the length.
struct LangData { uint32 offsetTable[header.langCount]; uint32 size; }; Hidden screenshot
I added support for this format and re-launched the deserialization process ... for the last time. Now everything worked smoothly and I had an extracted game script in my hands.
Fonts
The texts were sent to Dangaard for review, and it was the turn of the fonts. I have previously noticed a couple of files with the FONT type, and I have no doubt that they are the ones that store the fonts.
Hidden screenshot
Typically, fonts consist of two components: a raster and information on how to display this raster. But, after reviewing the file, I realized that there was no raster in it. And this means that it should be stored separately - for example, in texture. So, it was necessary to find signs of any reference to the raster.
The first thing I began to visually analyze the contents of the file. In the beginning, the font name “Deface” was well looked through, as well as the hash following it. I decided to look for files with such a hash and really stumbled upon the texture. Remarkably, the raster is now at hand, but you should first deal with this file.
The title was tricky, and I decided to leave it for later. A little further than the name of the font and texture hash noted earlier, there was data in which some periodicity was traced. Looking more closely, I picked up the desired width of the window of the hex editor and saw that it was an array of structures.
Hidden screenshot
Judging by the first field, where, without doubt, character codes were stored, this is information about the glyphs. Classically, before the array itself was its size. I began to look for characteristic elements in this array of structures, and the first thing that I noticed was the four clearly distinguishable float values in the standard IEEE 754 format. They are distinguished, due to the structure of the format, by the presence of 3D bytes, 3E, 3F, and other similar values with an interval of 4 bytes — it is difficult not to notice this pattern with a large accumulation of floating-point numbers. The values themselves ranged from 0 to 1, and it became obvious that these were texture coordinates. I could not determine the semantics of the remaining values without seeing the texture, so I began to decode the raster.
Having postponed the analysis of the TXTR structure for later, I decided to just detect and process the raster. In such cases, I always first check to see if the raster is an ordinary array of colors or indexes in the case of an image with indexed colors. And so, opening the file in the editor and picking up color, I saw an interesting picture.
Hidden screenshot
The image was four-bit, but it is obvious that there were two pictures. Since the values of the selected width and height were found at the very beginning of the file, i.e. in fact, something like the texture itself should look like that, then I didn’t have to go far to the conclusion: there are two layers in the texture in a sly way. Those. in each pixel, instead of storing a four-bit pixel value, two different colors are stored — one for every two bits. The layers themselves, respectively, four-color.


Each layer was a textural atlas - i.e. there were many glyphs on it, and the uv-coordinates of the glyphs corresponding to the characters were shown in the records .
For font editors, I have long had a blank on Delphi, inherited from a year ago in 2006 from one “colleague”. I quickly sketched a raster decoder and started trying to load the font, interpreting the fields in glyph structures in different ways. After a few days of experiments, I had some idea and even quite successfully downloaded the font.
Hidden screenshot
Starting to convert fonts one by one, I came across another type of texture. This time, they contained as many as four layers instead of two, but on the same principle. The difference was that the layers were not four-color, but binary .
In general, the picture gradually cleared up, and almost everything became known about the glyphs.
struct Rect { float left; float top; float right; float bottom; }; struct CharRecord { wchar_t code; Rect glyphRect; uint8 layerIndex; uint8 leftIdent; uint8 ident; uint8 rightIdent; uint8 glyphWidth; uint8 glyphHeight; uint8 baselineOffset; uint16 unknown; }; Hidden screenshot
With this knowledge, it became realistic to make out the unjustly forgotten headline. Comparing the facts known to me, I could not figure out the purpose of the majority of its fields, but it was not important, it was possible to edit the font without them.
struct Header { uint32 maxCharWidth; uint32 fontHeight; uint32 unknown1; uint32 unknown2; uint32 unknown3; uint32 unknown4; uint16 unknown5; uint32 unknown6; char fontName[]; uint64 textureHash; uint32 textureColorCount; uint32 unknown7; }; It seems to be all, it's time to work on preserving the font, but then I noticed not a strange addition, stored at the end of the file.
Hidden screenshot
With some pairs of characters, there were some mapped values, most often 0, 1 and -1 ... Connoisseurs of typography probably already guessed what it was about, but I didn’t immediately understand and even raised the topic on a thematic forum. But soon, I began to guess, and, by running it, I came across the definition I was looking for ... Yes, it was kerning in pixels.
struct KerningRecord { wchar_t first; wchar_t second; int32 kerning; }; All these entries were sorted in ascending character codes. Now, the purpose of the last field in the glyph record has become known - it was the index of the first kerning record for this character.
Now you could do the organization save this font. I did not take risks and increase the size of texture atlases, so the main problem here was the placement of all the glyphs in a limited area. I asked in the topic about kerning, if anyone knows a simple algorithm for this, and in response I was given a link to an article on gamedev.ru about the packaging of lighting maps. This was what was needed, and after the implementation of the algorithm, the fonts could be saved.
But after changing the fonts, it turned out that even with this algorithm it is not so easy to place all the characters on the available space - some of the glyphs simply did not fit. The way out, however, was found right away: I screwed up an optimization that used the same part of the texture for characters with the same glyphs. A little poshamaniv, I eliminated the insignificant differences between some similar characters of Cyrillic and Latin, and they began to have common glyphs, so that the fonts began to be successfully preserved.
So the next format fell to my fingers, and on this one could come to grips with the study of textures.
Acquaintance with textures
The game did not contain a large number of textures that needed translation, but at that time I did not know this and worked with regard to the worst scenario. After a bit of digging into the extracted TXTR files, I realized that font textures are a degenerate case, and most textures do not use indexed colors.
Hidden screenshot
Parse header size of 12 bytes was not difficult. The first value was probably the texture type number, since textures with indexed colors had a different texture. Values of 640 and 480 followed, definitely very familiar numbers, didn't they? In general, I did not doubt that there was permission in the header, but the purpose of the latter value is not so obvious. But I was ready to swear that this is the number of mipmap-levels , which are so often found in such cases.
struct TextureHeader { uint32 type; uint16 width; uint16 height; uint32 mipmapCount; }; The title was studied, but the main problem was the definition of the raster format. Fortunately, visually this structure was very familiar to me - it was definitely an algorithm from the S3TC family , familiar to many of them in DDS containers and DXTn algorithms. These formats are designed to use compressed textures in video memory, and it seems that both Wii and Gamecube are hardware supported. So, despite the emergence of associations with DirectX, there is nothing surprising here.
It was easy to determine the specific algorithm: all of these formats have a strictly fixed compression ratio, and, based on the ratio of the size of the source raster to the compressed 8: 1 (or 6: 1 without alpha channel), it could only be DXT1. The time has come just to make guesses, and I created a DDS image of the same format and resolution, replacing the raster borrowed from the texture. But what I got when I opened the file I received was not a very meaningful image ...
Latent image
It is time to poraskinat brains. Once the output turned out to be something remotely resembling an image, it was obvious that it was still DXT1, but modified. Two factors came to mind that could affect the format: the byte order and the tile texture structure. But in order to verify this, I had to manage the decoding procedure myself, and for this purpose I began to look for a library.
Fortunately, I just stumbled upon a great open source library - NVIDIA Texture Tools. Not without problems, but I was still able to adjust its code for my own purposes, and began experimenting. First of all, the first guess turned out to be true, with not whole bytes, but whole words, as well as bits in them, in a different order. After some manipulations with their rearrangement, the image became more adequate.
Latent image
I realized that I was not mistaken about the tiled structure. But, considering that DXT1 itself is encoded by 4x4 blocks, I was only partially correct: a certain swizzling of tiles was used here, i.e. they were swapped by a certain matrix. And, of course, the image was flipped.
I was too lazy to strain the brain and restore the matrix, and I went a long way to try to find formulas for the translation of coordinates. Honestly, I don’t know how I did it, but I acted by intuition and due to the presence of regularities in this matrix that my subconscious could feel without my participation, it eventually rolled. And then, finally, I got the original image.
Latent image
Write the encoding procedure was not a problem - the copy-paste decoding functions and, in fact, the replacement of r-value by l-value did their job. At this all the main formats were disassembled and you could breathe a little more freely.
First samples
I could not wait to try out something in action, and I began to think about how to ensure the replacement of resources in the game. Of course, the first thing to think about repacking archives. It would be stupid to waste our time and resort to repacking unmodified files, so I started writing the reassembly function with packing only the necessary data.
The bottom line was this: the archive was opened and iterated over all its files. The input was a list of directories where they should look for their modified versions. If it was, then it was packed and recorded in the output file, otherwise the original packed file was copied unchanged.
By the way, in the process of implementing this functionality, I noticed an interesting thing: not only were the same files often present in several archives, they were also often present in the plural and within the same archive! However, I was not surprised, because it is easily explained - this way you can reduce the number of movements of the drive head above the disk surface. In search of a file for reading, the game chooses the one that is closest in the direction of movement of the head, thereby reducing the wear of the drive and faster loading. In other games, for example, a technique is used when all the resources of a level are simply packed into a separate archive, which is then used within it. Of course, this leads to large amounts of duplication of data, but the language will not call it redundant, because everything is more than justified.
When the necessary functionality was ready, I decided to try my luck by feeding the archive with the changed data to the game. Taking the previously mentioned WiiScrubber and rebuilding one of the least significant archives, I tried to replace it. But I was disappointed: the size of the original file was exceeded. What I wanted the least was to tackle the problems of rebuilding the image, so I began to look for workarounds. And I found them: the solution turned out to be similar to what I used in the case of fonts. Since I was not interested in data from other languages, I added the ability to set mappings of some files to others in the reassembly function. Those.if the next processed file was marked for display, its contents were not written anywhere, but only its entry in the file table was affected - the offset and size were changed to the offset and size of the target file. Thus, for example, I “zamapal” all versions of the images of the initial screens in different languages into one - English-language, which was destined to become Russian-speaking.
I rebuilt the archive again, and this time it fit. And so I made the first trial run of the game with changed resources ... I can’t say that everything worked out simply and without freezing - I didn’t use that order of bytes, I forgot about portions when packing in LZO, and problems with fonts and text but in the end everything was fine-tuned and the game finally swallowed the reassembled archive without obvious problems. Hurray, earned: I saw the Russian text. But this was not the end of the road, much more was to be done.
Organization of the process
It was very important to adjust the translation process and create at least some semblance of a civilized approach. At that time, I knew about version control systems only by hearsay, and we decided to use Dropbox , creating a shared folder for the project. Meanwhile, Dangaard completed the first version of the glossary, and it was time to think about automating the process of inserting data into the game.
The main problem was the replacement of files in the image. There was no question of using any script that was jerking external programs - I did not know such programs with command line support, and aesthetically I would not accept such an approach with regard to this particular operation. Moreover, from the very beginning I planned to create an executable patch for the image, so in any case I would have to resort to the software implementation of such an opportunity.
Well, if so, then we need to look for a project with open source code and the closest to the necessary capabilities. At first my gaze fell on Dolphin.- A wonderful and simply the only existing Gamecube and Wii emulator. Of course, he knows how to work with images, so I downloaded his sources and began to study them. But the architecture turned out to be quite complicated, and I decided to look for alternatives. Suddenly, I had one idea, and I drove into Google's WiiScrubber sources ... Bingo! They exist!
I must say, this was the beginning of one of the most difficult stages in the history of the project. If I knew this, I would have sat down better and wrote everything myself. There is nothing worse than adapting a very, very focused code to your needs. That's when I practically fully felt the importance and necessity of following patterns and observing a culture of code. After all, I literally had to surgically cut the functionality from the graphical interface. The code was written using MFC, and the logic was integrated into the GUI, where, in addition, some data was stored - for example, file offsets were parsed from text nodes TreeCtrl. I had to replace entities and write fake classes of controls so that everything would somehow get together and work. Coupled with a code that is not entirely clean, it turned into a bloody mess of crutches, dirty hacks and antipatterns,which sooner or later would have to rake.
However, the goal was achieved. The code was bleeding, but it performed its task - I got the opportunity to programmatically replace the files in the game. Now I had to write an internal utility to quickly insert data into the game. And since not only I had to use it, I had to make it with a simple and clear graphical interface. I didn’t really like to deal with all kinds of frameworks or go into the wilds of MFC or WinApi, so I decided to use my knowledge again in VCL. I took Borland C ++ Builder 6.0 and started writing.
 It should be said that little was received from this IDE in the process. I do not know what is to blame, but without a complete reassembly of the project, every time the program did not even start. Plus, the permanent "shrödingbags" did not allow to localize the place of the error, as a result of which I constantly had to revise all the horror that had to be created earlier. I had to work on the code so that Borland could understand it.
It should be said that little was received from this IDE in the process. I do not know what is to blame, but without a complete reassembly of the project, every time the program did not even start. Plus, the permanent "shrödingbags" did not allow to localize the place of the error, as a result of which I constantly had to revise all the horror that had to be created earlier. I had to work on the code so that Borland could understand it.Having dealt with the problems of compilation, I returned to the problems of functionality. To make the process of replacing files as fast and less redundant, it was necessary to fasten the ability to select specific files for replacement. Based on the contents of the archives, I determined which of them was used in which location, and created a list of archives with corresponding marks. Now, in order to check the text in the game menu, it was not necessary to resort to a complete reassembly of everything and everything.
Next, I sketched a script that serialized resources into game formats and put them into a folder, which was then specified as an input to the program that I just developed. Now it was possible at any time to replace the resources in the game, without exerting excessive effort.
At the very least, the translation assembly process was automated. Now it was necessary to make life easier for the translator. I noticed that many files with different names (more precisely, hashes) have the same content, i.e. the text was very often duplicated. Therefore, in the output text files, I “slammed” all such duplicates into one, giving them composite names. And when serializing it was just a bunch of files instead of one.
Then I drew attention to the abundance of technical data in the text. It was simply unreadable for the human eye due to the huge number of tags.
Hidden text
&push;&main-color=#E67E00FF;Energy Cell ID:&pop;
SN-3871S-7
&push;&main-color=#E67E00FF;Status:&pop;
&if=hasitem:Fuse7Used;Used&else;&if=hasitem:Fuse7;Acquired&else;Unknown&endif;&endif;&if=scan:SCAN,0x6479E69556A56AC8;
&if=(hasitem:Fuse7Used)|(hasitem:Fuse7);
&push;&main-color=#E67E00FF;Previous Coordinates:&pop;&else;
&push;&main-color=#E67E00FF;Coordinates:&pop;&endif;
&if=mapped:PirateCommand;04P-MET, Pirate Homeworld&else;04P-MET, Unknown&endif;
&just=left;Data indicates Energy Cell is connected to &push;&main-color=#FF6705B3;processing&pop; containment core.&endif;
Fortunately, such problems had to be solved before, and I sketched an xml file describing the syntax for Notepad ++. It was very opportune that Dangaard translated the text exactly in it, because Word and other text-based combines with its autochange and other things are capable of delivering many problems. After these manipulations, it became very easy to perceive the text - the problem was solved.
Hidden screenshot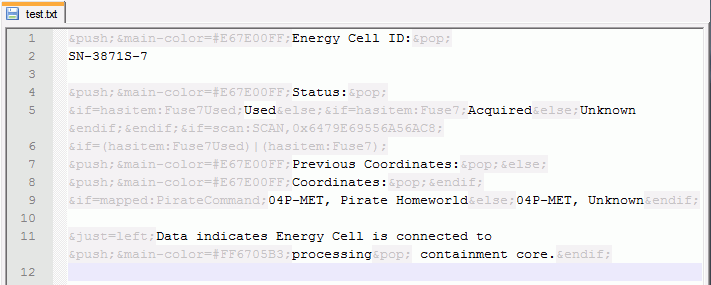
Later it took a little more confusion with the text. Dangaard asked me - it was incredibly tedious to keep a glossary of location names and use it everywhere in translation, so I was required to automate this process. I sketched a program that read the glossary file, parsed the text files, and if the line fully corresponded to the glossary element, I replaced it with the translated version.
The translation went at full speed and the baton of the load intercepted Dangaard, translating large volumes of text of a technical nature.
Imaginary finish
Time passed, progress also did not stand still. And so, at some point, Dangaard reported on the completion of the translation of the game magazine - the most complex and voluminous part of the text, because there were descriptions of almost all game objects and an extensive collection of mini-articles with more detailed consideration. This undoubtedly meant a shift in progress towards completing the transfer.
At about this point, I began to look for ways to create a low-weight executable patch. The main problem was to find the means for the smooth development of a GUI application, while maintaining the small size and solidity of the executable file and decent design. In the process, I met a lot of criticism - many believed that nowadays you should not pay such attention to file size, and in general, it is better to just distribute the patched image through torrents. But for me it was a matter of principle, because the fact that the user interface of a patch takes up more memory than the patch data itself hurt my sense of aesthetics, so it became a kind of challenge. In addition, an important role was played by the legal side of the issue: I did not want to violate anyone's copyright by distributing an illegal copy of the game.For the same reason, I even bought a license disk.
A little more time passed, and it was already possible to anticipate the not so far end of work. Pretty tired of the project, we decided to pre-announce a set of testers. The fact is that we discovered some problem: our translated text does not always fit in the screen space allotted to it, and therefore we decided that the earlier we begin to detect and correct such places, the better it will be for everyone. After all, the more time passed, the less enthusiasm remained in our bins.
It was disappointing that only one person responded to the call. Nothing demotivates as the realization that your work is not so in demand, and the work continued with less pleasure. The situation was aggravated by the need to refactor the problem code to replace the images in the game, because if this was suitable for internal use, then releasing this into production did not allow conscience. Another stopping factor was the need to create a patcher that meets the requirements.
No one else responded, and under the weight of the circumstances, our affairs declined and everything fell, as is often the case. There have been many attempts to return the translation to the system, but there was not enough enthusiasm for long. Once, in the dreams of voice acting, I even made out the format in which the sound of speech was stored - it was the container of one of the versions of the FMOD library . However, I didn’t succeed in achieving a full-fledged sounding, but the point is not complexity, but lack of necessity - I initially knew that you couldn’t do a good dubbing on the knee.
Second wind
Two years have passed since then. During this time I got a job, graduated from the university and got a lot of new experience in my specialty. Unfortunately, carefree times are gone, and there was too little time and effort left for their hobbies after work. But all this time, the conscience was tormented by the thought that we have unfinished projects that were once promised to society. In the head of the vital the thought “it is necessary”, but as soon as it reached the point, it became clear that this thought was not enough. Dangaard occasionally translated something and poked me with a wand, which also made me worry.
At some point, I again looked at my work, and decided that something had to be changed. And I began to change everything, trying to bring everything in accordance with the requirements of any adequate business process. First of all, the reorganization touched our method of data consistency. To use Dropbox for these purposes was no good, and I began to look towards version control systems. No matter what they say, but I like Subversion, so I created an svn repository on one of the hosting sites and started transferring data there.
Immediately the problem surfaced. The text was stored in unicode, since Notepad ++ did not always correctly save UTF-8, which periodically led to the corruption of some characters. Possibly due to BOMSVN recognized the files as binary, so I had to manually set the text content type. After these manipulations, the text was perceived without problems, but then again and again there were problems - then the version comparison utilities did not perceive Unicode, then in the event of conflicts, the corresponding text labels were written to files as ANSI text. But it was too late to change something, and problems of this kind did not arise so often, so everything was left as it was.
As soon as the migration to SVN was completed, I was surprised to see that I enjoyed the process. Working with ordered data at a higher level of organization turned out to be one pleasure compared to previous experience, so I decided not to stop at this and turned my gaze to the toolkit. I decided to rewrite everything that is impossible to refactor.
For one and a half years of practical experience, I really liked Qt, so it was decided to use it here. Here all the necessary projects were created and the work began to boil. At first, I even covered everything rewritten by tests, but then I got tired of it and I decided to focus on the correctness of the output, and not on the correctness of the code.
All the tools were rewritten, with the exception of the font editor and the text serializer - they worked and worked fine, and there was no need to implement this functionality anywhere. After a while, the hands reached even the bloody mess that I had to generate to be able to replace the files in the image. After a couple of dozen commits, this code found at least some form, and I could already afford to use it to create a patcher. Following and inserting data has been completely rewritten using Qt instead of VCL.
Hidden screenshot
I decided that I would use Qt for the patcher, and killed a lot of time, trying to build it in a static configuration with the minimum size of the resulting libraries. However, at least “fine tuning” is maintained in the Qt build system, but in reality either my hands turned out to be crooked, or this possibility simply did not work.
Thoughts have already begun to come to me, and can I just cut out the code and data I do not need? And I asked a question here on Habré. The hopes were justified - MikhailEdoshin saved me by telling me that there were flags in MSVC that would allow us to compile the code in a special way, and tell the linker to cut out unused data. After trying this method, I realized that it works fine.
I created a patcher project and started developing it. If two years ago I wanted to see in its quality something resembling a hacker craft, now it was the desire to see a solid installer, maximally protecting the authors from potential legal problems. So I took the QWizard and started on the basis of it to make a patcher in the best traditions of the installer.
Hidden screenshot
It seems that everything went well, but soon there was one unpleasant problem ...
Unexpected hang
At some point, the game just began to hang after the main menu. It was terrible, because before that everything worked and anything could have caused the hang. Replacing archives via WiiScrubber gave the same effect, so I could not blame specifically the patcher.
It took a lot of time to search for possible junk files using the dichotomy method, but in the end it turned out that it wasn’t time to do it and if there were any changes, the game would be hung by another file. And then I decided to check one guess, which, in principle, from the very beginning kept in my head, but was rejected as unlikely.
To uncover the essence, you must first tell a little about the device disk Wii. While a regular DVD is divided into sectors of 2048 bytes in size, the Wii disk is divided into clusters of 0x8000 bytes. Clusters, in turn, consist of a header with a size of 0x400 bytes and data with a size of 0x7C00 bytes. The clusters themselves are grouped into eight groups, which are then grouped into groups of eight groups. The cluster header stores hashes, hashes, hashes, and hashes, hashes, hashes ... well, first things first.
typedef uint8 Hash[20]; struct ClusterHeader { Hash h0[31]; uint8 padding0[20]; Hash h1[8]; uint8 padding1[32]; Hash h2[8]; uint8 padding2[32]; }; struct Cluster { ClusterHeader header; uint8 data[0x7C00]; }; First of all, the header contains the table from the 31st SHA1 hash, called H0. It stores hashes of every 1024-byte data block in a cluster.
The second table, H1, stores the hashes of the H0 tables of each cluster in the subgroup. Since this table is in the header of each cluster, then within the same subgroup, all clusters have the same contents.
There is also a table H2, which stores hashes of tables H1 of all subgroups in a group. Therefore, it, in turn, is the same for all clusters in a group.
And finally, each partition on the disk has a global hash table that stores the hashes of the H2 tables of each cluster group. This table, along with the rest of the section header information, is protected by a digital signature, which along the chain also de facto protects the tables of the other levels, including eventually the cluster data themselves. By the way, they are also encrypted.
For any change in the image, you must recalculate all the hashes and re-sign the global hash table. But the private key for signing is unknown to anyone other than Nintendo, so the workaround, known as the signing bug, is used .
The fact is that a bug was detected in the Wii firmware: when verifying the digital signature, the hashes were compared using the strncmp function. This function is designed for strings and has one feature: if there is a zero byte at the beginning of both compared data strings, they are taken as empty strings, and, as a result, are considered equal. Therefore, to launch the modified content on the Wii, a previously prepared digital signature is used, the hash of which starts from zero. To ensure that the content hash also starts from zero, the data is adjusted by changing the reserved fields.
Knowing this, I wrote a validation function that counted the hashes and compared them with the specified ones. And indeed - at some point the check failed due to an invalid hash. The problem with the hang was that the source of the WiiScrubber had a bug, which in some cases did not update the hashes of the last processed cluster. After removing the bug, everything began to work, and I was very pleased.
Considering this unpleasant experience, I have built in the internal assemblies of the patches a mandatory check of the validity of the image and the reassembled archives themselves. In which case the patch would simply not apply.
Testing and release
The problem with the hang was fixed, the patch build process was automated, the translation was now really nearing completion, and we decided to re-recruit volunteers for testing. This time, quite a few people responded, although in the end only three of them actually participated, including me. I distributed the patches and the process started ...
Before that, I tried to prevent most technical errors by adding several tests to the patch build process. If they collapsed, the patch just was not going to.
But problems still flowed like a river. I barely had time to handle the bug reports, as new ones appeared. At the same time, it was reported not only about errors, but also about any sentences that cut ear to ear, so testing soon turned into a detailed reworking of the entire text.
It turned out that the problem with the text that did not fit had a much larger scale than we could have imagined. Due to the peculiarities of the Russian language, the translation was longer and simply did not fit on the screen. Therefore, gritting my teeth, I sat down and wrote a game script editor with the possibility of approximate text visualization.
Hidden screenshot
One of the testers, a man under the nickname SonyLover, was previously a co-translator in one of our projects. He offered his help in bringing the translation to the end, and together we began to rule literally every sentence.
Meanwhile, there was one unpleasant problem with fonts: some characters seemed to be higher than others, which created the effect of “jumping” text. Looking closely, I saw this problem in the original, but there it was less pronounced and therefore not so noticeable.
Hidden screenshot
The reason turned out to be simple and something similar was already described on Habré: the characters adjacent to the edges of the texture were not interpolated from the adjacent side, and therefore looked clearer than the characters that were further from the edge. Visually, this created the effect of a difference in character height. However, the problem was solved by simply adding a frame of transparent pixels so that no other character would lie adjacent to the edges of the texture.
At this pace, we worked for a month and a half, polishing all unpleasant moments and arguing over every little thing. And so, we are very close to the release. Although at the last moment we had to resort to fairly global changes, such as changing a couple of glossary elements or finding untranslated system messages embedded in the executable game file, but there is no longer enough to check them.
And finally, a solemn day came for us. On January 26, 2013, I made the last edits, reposted in repositories, compiled a patch with the release configuration, and announced the release of the translation. To say that the mountain fell from my shoulders - to say nothing. Of course, I did not feel indescribable joy, but then conscience had one less reason to pester me.
Of course, the translation did not come out perfect - there is no limit to perfection, and immediately after the release a couple of unpleasant, but not critical moments with text formatting came to light. But to release a new version is a matter of five minutes, so this did not upset me greatly. The main thing is that we were satisfied with our work, as well as our target audience.
Afterword
Returning to the title, I want to talk a little about our plans. Not long ago, I was sure that I would no longer return to translation, but, apparently, I was wrong. Then I thought that this translation will most likely be my last, but then I decided that we should complete at least one more unfinished project that hundreds of people have been waiting for from us for two years - the translation of Silent Hill: Shattered Memories . And there it will be seen whether the soul will still lie to the amateur translations. Still, it’s not for nothing that very many, growing up, leave this scene.
, , . , - . , , . , - .
, .
UPDATE : github .
Source: https://habr.com/ru/post/167827/
All Articles