Step by step, or How we built your search
In the last post, we looked at examples of the architecture of search engines. Everywhere a key role is played by the database, on which it is convenient to perform certain operations, to investigate and analyze the documents contained in it.
Until the spring of 2012, instead of such a database, we had two databases of different levels - from the side of the spider, which had its own database of URLs, and from the side of the indexer. It was extremely inconvenient: for example, if a user complained that his site was not indexed, then in order to find the cause, with the old architecture, we would have to analyze a lot of data. It took a day or two, sometimes even a week.
Tasks that processed data, such as an antispam or reference graph, were forced to work separately, creating even more confusion. We understood that we need to change something.
')
After thinking about other architectures, it became clear that a platform is needed for distributed task execution. We stopped at Hadoop, a system that allows parallelizing calculations on a large cluster of machines. This solution has enough examples of successful use in major companies, such as Facebook and Yahoo! - so, we could be sure that Hadoop is coping with large amounts of data.
As an alternative, we considered several options. One of these was the Sector / Sphere system. Unfortunately, tests in other departments of our company showed that the system was rather crude at that time, and we could not confidently rely on it.
Another option is to write the solution yourself. Some companies follow this path: for example, it is known that Yandex has its own implementation of both MapReduce and the distributed file system. We analyzed the pros and cons of our own implementation compared to Hadoop. Using a self-written solution would be justified if we found examples of how Hadoop is slower or requires more resources than a self-made implementation.
The only thing that scared us was that Hadoop was written in Java. Programmers in C and C ++ Java often pushes away with a rather imposing attitude to resources: there is a widespread opinion that a program written in Java will work in 2, 3, or even 10 times slower than a program written in C + +. This turned out to be a myth: after we migrated to Hadoop, many of our programmers became acquainted with Java, and it turned out that often writing a Java program is faster than C ++, and it will work at about the same speed as and its counterpart. Of course, there are enough nuances in using Java that are unpleasant for C ++ programmers (for example, the same garbage collector) - but this is the next stage of its application.
Testing Hadoop showed that Java does not frighten us, but based on the results of personal conversations with developers of distributed computing systems, it turned out that Hadoop speed is not too different from the implementations made independently: that a well-functioning C ++ implementation is only one and a half times faster than Hadoop. From this it became clear that it makes no sense to make your own decision - we will spend significantly more energy in order to implement it; so Hadoop has taken root with us.
Of course, programmers who transferred to a sixty-server computing cluster experienced euphoria. Everything that the programmer used to do for a long time and painfully, what was performed on the servers for several weeks, was now programmed in a day and executed for 15-10 minutes. Of course, when almost all programmers migrated to Hadoop, tasks that were started inside the cluster were not completed as quickly. But still having a common platform was very convenient. It became clear that in the end we will use Hadoop.
Then we started to think about how to implement a database with information about obkatannyh URLs. At this stage many questions arose. For example: we have a list of URLs and content URLs - is it worth keeping them in one file or is it better to split them into two? It is logical to break: after all, content, unlike URLs, is not always needed. And if we want to quickly add something to this file, are we going to go through it to copy it to a new place with new changes? This suggests a solution - to create another small file next to it, into which we will add new changes, and to go through two files in parallel.
As a result, thinking in this way, sooner or later you catch yourself thinking “It's BigTable”, so we decided to explore the well-known Open Source counterparts.
There were three freely distributed BigTable clones: the first was HBase, built under the same community that Hadoop made, the second HyperTable, and the third, Cassandra's open source solution, copied from Dynamo’s solution (which, in turn, was created at Amazon based on BigTable).
We were interested in ease of use in our conditions, speed and, of course, stability of work. On the compliance with the last criterion can be judged by how many companies use a particular table. HyperTable dropped almost immediately, because we were not satisfied with its stability: at that time, only the Chinese search engine Baidu used it from large services. Installing it on the stand turned out with great difficulty, which practically guaranteed a huge amount of headache when used (now, according to reviews, it has become much more convenient).
There remained two options - Cassandra and HBase. Cassandra provided more speed, but also gave a higher risk of data loss. HBase, on the contrary, had a lower write speed, but higher reliability. In addition, HBase is closely integrated with Hadoop. This was for us a decisive argument in his favor.
We started testing HBase from a small cluster of 16 machines. The first tests were successful - everything worked stably and at an acceptable speed. Soon the number of servers in the cluster increased to 32, and then to 50.
Then we decided that we would not immediately build a full-fledged search engine that would work alongside the main one. When two versions of a “heavy” web service — early and late — are developed in parallel, the second, as a rule, fails to catch up with the first. In the first version, new features constantly appear, which in the second simply do not have time to implement; as a result, the new version of the search would have the risk of not becoming a release version.
Therefore, we decided to start small: take the task, which is not optimally solved in our main search engine, and solve it with the help of new technologies and focusing on the new architecture. As such a task, we chose a quick and regular round of interesting documents. In fact, in about 3 months we launched next to the existing spider its specialized version, but immediately included in the general operating cycle of the search engine. It took another 3 months to stabilize it, fine-tune and create patches for HBase, after which we turned off the old spider and completely switched to the new system.
According to preliminary estimates, the whole process should have taken about one and a half to two months. However, we underestimated the time frame - it turned out that HBase was far from perfect and the stability of its work in the tasks for which we used it, left much to be desired. Several times we were starting to develop our own solution, but each time we analyzed the situation and came to the conclusion that it would be easier to sharpen HBase for our needs.
In the process of taming Hadoop and HBase, we realized that we needed the help of more experienced people — so we acquired commercial support from Cloudera.
The experience of interaction with support was twofold. Of course, a close acquaintance with Cloudera helped us answer a large number of questions, but some of the answers we received did not suit us. For example, after some time we realized that Cloudera also doesn’t know how to configure HBase to work in our conditions - simply because they have no data clusters with such a volume of support. Companies with similar volumes are the same Facebook or Yahoo! - solved this problem by accepting to the staff of people who developed HBase. Thus, Cloudera could not recommend anything concrete to us, and in many respects we remained where we were. From this point on, we realized that we can only rely on our own strength.
All the problems that we had with HBase and Hadoop were described in detail at the Mail.Ru Group Technology Forum in a report by Maxim Lapan (see here: http://techforum.mail.ru/video/ ). I will outline them briefly.
First: the volume of our table is constantly growing. Initially, we expected that there would be 5–10 billion documents in the table. However, it quickly became clear that this number should be much larger, and 20-40 billion URLs should be placed in the database. This meant that we made a mistake in estimating the size of the cluster: as a result, we had to expand it first to 100, and then to 170 servers. As a result, we became owners of one of the largest clusters on which HBase is deployed; in any case, in Russia, larger clusters are unknown.
The second problem arose with the HBase usage pattern. Every day we pumped about 500 million, or even a billion documents. At that time, we had 5–10 billion documents with content; Thus, about 10-20% of the base volume was updated daily. With this mode of operation, HBase, installed out of the box, is always busy trying to repack this base, which consumes network and disk resources. As a result, tasks are performed extremely slowly. It was impossible to solve this problem by setting up HBase, so we had to patch it. As a result, we posted several patches of varying complexity that helped reduce the time for official operations with HBase.
The third problem was that the daily passes of executing tasks on a large base were very slow, because a careless filter when scanning data caused all values from the table to rise, including the content that was stored there; This led to the fact that the task, instead of the planned 2–3 hours, was carried out in days. Given that at that time our cluster often fell, the task could simply not reach the end. The solution was also implemented in the form of a patch, which allows speeding up the aisles on the table due to “fast scans”. We put it up for discussion in the Apache issue tracker https://issues.apache.org/jira/browse/HBASE-5416 , where most of the active developers of HBase gathered, but since the patch affects a lot of HBase root elements, it hasn’t been integrated into common code. This patch was the largest, and it was with the end of its development that our cluster finally started working.
The fourth big problem that we have not yet overcome is the imbalance of the HBase regions.
There is a closer look at the approach to storing web pages in HBase. A classic example of using HBase is storing the contents of documents with a URL in the form of a key. Domains in the URL are written in reverse order, so that not only the pages of the site, but also the subdomains of one domain are located side by side, for example like this:

Such an approach was tempting with its logic, and we did the same. The problem is that the set of URLs expands over time, and it is likely that we will find many pages from one domain. The corresponding region in HBase will be noticeably “thicker” than the average.
To overcome this problem in HBase, there is a mechanism for dividing regions. But the reverse mechanism - mergers - is unstable. A constant increase in the number of regions in order to balance leads to large overhead costs for their maintenance.
And after writing a set of tasks for Hadoop, we thought again - what does the proximity of the documents in the table give us? This is convenient for a couple of tasks, but in general it creates more problems. And now we are moving towards introducing hashing for URLs. Thus, the documents will be distributed evenly; the execution time of mappers will also become uniform, which means that all tasks working with HBase will be accelerated.
While we were working on solutions, more and more components of our Search moved to Hadoop. Now all components, except indexing, work in Hadoop and in HBase.
Probably, we finally did what we wanted from the very beginning: we had a platform for distributed computing, data analysis. We cannot say that we are completely satisfied with it - simply because in the process of passing the path comes an understanding of what else I would like to receive from the platform. But now from the time of the appearance of the new URL to the moment when it appears in the index, it takes from 2 to 5 days. In the old version of the search engine this could occur from two weeks or more. Our next goal is to reduce the time to minutes. The architecture of the new version of the search engine is likely to be fundamentally different from the existing one.
The MapReduce paradigm and the debugged Hadoop technology make it possible to scale the cluster easily. We increase the number of servers by 1.5 times - tasks start to work [almost] 1.5 times faster. However, not all tasks “fall” on the MapReduce paradigm, and some simply do not experience any improvements from it. This is true, for example, for a web spider: it is unprofitable to occupy a slot for downloading a site - there will always be slow hosting, due to which the precious slot will have to be held longer than necessary.
In addition, the “do everything within MapReduce” approach leads to inefficient use of resources, because a fast network is necessary for downloading pages, and, say, for parsing the contents of pages, a fast CPU.
This is the process of separation that happened in our crawler. Before it was a monolithic task which produced:
Scaling such a spider was extremely difficult: adding new machines meant repartitioning the base, which took several weeks. And it was simply impossible to conduct an experiment with a modification, say, a scheme for determining the language of a document: such a test took months.
The transition to Hadoop saved us from the problems of storing backups and gave a simple scalability for tasks demanding on the CPU and RAM. The crawler itself began to perform only the pumping function and was renamed the fetcher:

Now, when we have all the “business logic” in MapReduce, and the documents themselves in HBase, the introduction of a new language definition has become the task of one day.
We considered the transition to a unified Hadoop computing platform. The introduction of Hadoop for our project was perhaps the most revolutionary architectural solution. The transition to Hadoop and MapReduce continues for components that perform calculations "offline". The architecture of the “online” part that processes user queries, as well as the process of creating a search index, will be discussed further.
Indexing data takes place outside MapReduce, but it is also distributed among individual machines and relatively easily scaled.
Indexing works with so-called. microbase: the entire web set is divided into 2048 pieces, grouped by sites. Indexing data is incremental: new data is indexed over the existing database, and then the data is glued together. On each "indexer" machine, there are several queues distributed among the disks. Each queue processes several microbases.
A typical indexing machine looks like this:

The bottlenecks for indexers are CPUs and disks, which is why indexers are equipped with disks according to the number of cores; so is the number of processing queues.
Data for indexing, i.e. documents and their attributes are taken from HDFS. These are partial dumps of the same HBase table, which was mentioned earlier. As a result of indexing, the updated microbases are added to HDFS, and subsequently copied to search engines.
Despite the fact that the indexers themselves work outside the MapReduce paradigm, Hadoop also helps in this task: the central repository of microbases and the main backup is HDFS. In addition, the heavy parts of the indexers are also transferred to Hadoop, so that the end-users will be more engaged in their direct task - the compilation of a binary data index.
The tasks of a web search are to find documents that match the request, their ranking and the formation of informative output, mainly snippets. These problems are solved by a separate search backend. Issuing the same result for the SERP is formed by combining the answers of the backends. This function is performed by a component, which is usually called a meta-search (about it - in the next section).
The main technical requirement for backend is the response time. Backends have to work with a huge amount of data and a large flow of requests. Spontaneous delay, say, due to blocking on the disk should be an exception, but not a regular rule.
The search base traditionally consists of reverse and forward indexes, as well as auxiliary files: numeric properties of documents, request information, etc. The reverse index is used for document search and ranking. The direct index is used to build snippets. There are many approaches to the fact that this is always stored in memory, what to cache and what to read from the disk.
We were guided by a simple rule: the more transparent our system will be, the more predictable it will work. This does not apply, say, to such a part as the reading of compressed index blocks. Of course, the faster this phase works, the faster the whole search works. And this part of the search engines is traditionally polished and optimized for modern processors. But we don’t have a complicated scheme for caching index blocks.
Instead, we simply block the most requested parts in RAM (Unix, mlock (2)). This also includes parts with an average demand, but an arbitrary access to them, for example, the numerical properties of documents. But we keep the direct index on the disk, hoping for the OS cache. Note that the direct index is much less frequently requested than the opposite, because regardless of the increase in the number of search engines, users still need only a few results in the output.
As for the organization of demon processes, they work in the multi-process master-workers scheme. Given the separation into microbases (mdb), indicated in the previous section, the backend scheme looks like this:

Meta-search first requests a small number of results from all backends, merges them, and then receives snippets of those documents that will be included in the output.
Like the rest of the search engines, we are gluing the results on the fly. So, for example, we remove duplicate descriptions from the issue. Accordingly, we are forced to make additional requests to backends, and to speed up the response - to request with a slight lead.
The traditional search scheme includes many backends and components that combine partial results based on weights (relevance):
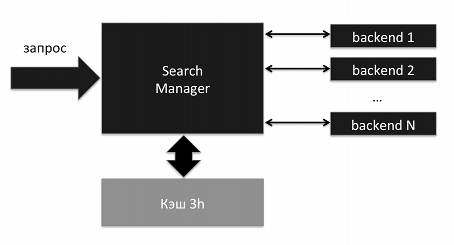
We have a similar scheme applied to the so-called. verticals - search by pictures and video. But in the form of mixes to the main issue of the vertical, they worked in such a way that they fit into the classical scheme: the pictures and videos had their own weights, which were adjusted to documents from the web.
Ensuring that the picture appears in the first place is quite simple. And what to do with the scales, if we want to put it on the 3rd position? I didn’t want to add such logic to the search-manager: nevertheless, its task is a banal combination of results. Therefore, we have made an additional node, the purpose of which is high-level work with the results and embedding podmes. As a result, our “middle-end” scheme mutated into the following:

This scheme also ensured the independence of the development of smanager-meta and the former smanager. Thanks to this, it has become much easier to embed subarrows, and now we are mixing over 20 different verticals.
This change also allowed us to isolate the “fast bases” into a separate block and split the caching of the results. We cache the results from the “fast bases” for 15 minutes, and the results of the “big web” for a day.
The smanager-meta component also switched to the preprocessing phase of the query: the use of synonyms, the reformulation of the query, and the compilation of the search tree. This rather capacious part of the search engine will probably be described in subsequent posts.
We looked at the Mail.Ru Search architecture and how it has changed since the days when we were a GoGo search engine, serving only 10 requests per second. Part of the decisions was dictated by orders of magnitude increased load. The rest is the desire to bring flexibility and accelerate the pace of development.
Separately, I want to say about the choice of tools for the system. Many existing components are not ready for use in an environment where high performance is required with a large amount of data. That is why most of the components are written or refined under our infrastructure. This number includes our refinements regarding Apache HBase. All this makes it possible to use the existing equipment more closely. So, even after we significantly increased the server fleet, the cost of processing a single request remained relatively low.
Undoubtedly, the architecture is in close connection with external requirements. The data volumes or the number of requests changing by orders force to change the schemes of their processing. It is likely that the approaches presented will also undergo changes in a few years. But there is a feeling that we have made a significant step in order to concentrate more on the quality of the search. On how our user will perceive us.
Andrei Kalinin, Project Manager Search
Jan Kisel, Search Infrastructure Team Leader
Until the spring of 2012, instead of such a database, we had two databases of different levels - from the side of the spider, which had its own database of URLs, and from the side of the indexer. It was extremely inconvenient: for example, if a user complained that his site was not indexed, then in order to find the cause, with the old architecture, we would have to analyze a lot of data. It took a day or two, sometimes even a week.
Tasks that processed data, such as an antispam or reference graph, were forced to work separately, creating even more confusion. We understood that we need to change something.
')
Ready solution or own implementation?
After thinking about other architectures, it became clear that a platform is needed for distributed task execution. We stopped at Hadoop, a system that allows parallelizing calculations on a large cluster of machines. This solution has enough examples of successful use in major companies, such as Facebook and Yahoo! - so, we could be sure that Hadoop is coping with large amounts of data.
As an alternative, we considered several options. One of these was the Sector / Sphere system. Unfortunately, tests in other departments of our company showed that the system was rather crude at that time, and we could not confidently rely on it.
Another option is to write the solution yourself. Some companies follow this path: for example, it is known that Yandex has its own implementation of both MapReduce and the distributed file system. We analyzed the pros and cons of our own implementation compared to Hadoop. Using a self-written solution would be justified if we found examples of how Hadoop is slower or requires more resources than a self-made implementation.
The only thing that scared us was that Hadoop was written in Java. Programmers in C and C ++ Java often pushes away with a rather imposing attitude to resources: there is a widespread opinion that a program written in Java will work in 2, 3, or even 10 times slower than a program written in C + +. This turned out to be a myth: after we migrated to Hadoop, many of our programmers became acquainted with Java, and it turned out that often writing a Java program is faster than C ++, and it will work at about the same speed as and its counterpart. Of course, there are enough nuances in using Java that are unpleasant for C ++ programmers (for example, the same garbage collector) - but this is the next stage of its application.
Testing Hadoop showed that Java does not frighten us, but based on the results of personal conversations with developers of distributed computing systems, it turned out that Hadoop speed is not too different from the implementations made independently: that a well-functioning C ++ implementation is only one and a half times faster than Hadoop. From this it became clear that it makes no sense to make your own decision - we will spend significantly more energy in order to implement it; so Hadoop has taken root with us.
Of course, programmers who transferred to a sixty-server computing cluster experienced euphoria. Everything that the programmer used to do for a long time and painfully, what was performed on the servers for several weeks, was now programmed in a day and executed for 15-10 minutes. Of course, when almost all programmers migrated to Hadoop, tasks that were started inside the cluster were not completed as quickly. But still having a common platform was very convenient. It became clear that in the end we will use Hadoop.
BigTable clones: HBase, Hypertable, Cassandra
Then we started to think about how to implement a database with information about obkatannyh URLs. At this stage many questions arose. For example: we have a list of URLs and content URLs - is it worth keeping them in one file or is it better to split them into two? It is logical to break: after all, content, unlike URLs, is not always needed. And if we want to quickly add something to this file, are we going to go through it to copy it to a new place with new changes? This suggests a solution - to create another small file next to it, into which we will add new changes, and to go through two files in parallel.
As a result, thinking in this way, sooner or later you catch yourself thinking “It's BigTable”, so we decided to explore the well-known Open Source counterparts.
There were three freely distributed BigTable clones: the first was HBase, built under the same community that Hadoop made, the second HyperTable, and the third, Cassandra's open source solution, copied from Dynamo’s solution (which, in turn, was created at Amazon based on BigTable).
We were interested in ease of use in our conditions, speed and, of course, stability of work. On the compliance with the last criterion can be judged by how many companies use a particular table. HyperTable dropped almost immediately, because we were not satisfied with its stability: at that time, only the Chinese search engine Baidu used it from large services. Installing it on the stand turned out with great difficulty, which practically guaranteed a huge amount of headache when used (now, according to reviews, it has become much more convenient).
There remained two options - Cassandra and HBase. Cassandra provided more speed, but also gave a higher risk of data loss. HBase, on the contrary, had a lower write speed, but higher reliability. In addition, HBase is closely integrated with Hadoop. This was for us a decisive argument in his favor.
We started testing HBase from a small cluster of 16 machines. The first tests were successful - everything worked stably and at an acceptable speed. Soon the number of servers in the cluster increased to 32, and then to 50.
Then we decided that we would not immediately build a full-fledged search engine that would work alongside the main one. When two versions of a “heavy” web service — early and late — are developed in parallel, the second, as a rule, fails to catch up with the first. In the first version, new features constantly appear, which in the second simply do not have time to implement; as a result, the new version of the search would have the risk of not becoming a release version.
Therefore, we decided to start small: take the task, which is not optimally solved in our main search engine, and solve it with the help of new technologies and focusing on the new architecture. As such a task, we chose a quick and regular round of interesting documents. In fact, in about 3 months we launched next to the existing spider its specialized version, but immediately included in the general operating cycle of the search engine. It took another 3 months to stabilize it, fine-tune and create patches for HBase, after which we turned off the old spider and completely switched to the new system.
According to preliminary estimates, the whole process should have taken about one and a half to two months. However, we underestimated the time frame - it turned out that HBase was far from perfect and the stability of its work in the tasks for which we used it, left much to be desired. Several times we were starting to develop our own solution, but each time we analyzed the situation and came to the conclusion that it would be easier to sharpen HBase for our needs.
Our support experience
In the process of taming Hadoop and HBase, we realized that we needed the help of more experienced people — so we acquired commercial support from Cloudera.
The experience of interaction with support was twofold. Of course, a close acquaintance with Cloudera helped us answer a large number of questions, but some of the answers we received did not suit us. For example, after some time we realized that Cloudera also doesn’t know how to configure HBase to work in our conditions - simply because they have no data clusters with such a volume of support. Companies with similar volumes are the same Facebook or Yahoo! - solved this problem by accepting to the staff of people who developed HBase. Thus, Cloudera could not recommend anything concrete to us, and in many respects we remained where we were. From this point on, we realized that we can only rely on our own strength.
Problems and how we solved them
All the problems that we had with HBase and Hadoop were described in detail at the Mail.Ru Group Technology Forum in a report by Maxim Lapan (see here: http://techforum.mail.ru/video/ ). I will outline them briefly.
First: the volume of our table is constantly growing. Initially, we expected that there would be 5–10 billion documents in the table. However, it quickly became clear that this number should be much larger, and 20-40 billion URLs should be placed in the database. This meant that we made a mistake in estimating the size of the cluster: as a result, we had to expand it first to 100, and then to 170 servers. As a result, we became owners of one of the largest clusters on which HBase is deployed; in any case, in Russia, larger clusters are unknown.
The second problem arose with the HBase usage pattern. Every day we pumped about 500 million, or even a billion documents. At that time, we had 5–10 billion documents with content; Thus, about 10-20% of the base volume was updated daily. With this mode of operation, HBase, installed out of the box, is always busy trying to repack this base, which consumes network and disk resources. As a result, tasks are performed extremely slowly. It was impossible to solve this problem by setting up HBase, so we had to patch it. As a result, we posted several patches of varying complexity that helped reduce the time for official operations with HBase.
The third problem was that the daily passes of executing tasks on a large base were very slow, because a careless filter when scanning data caused all values from the table to rise, including the content that was stored there; This led to the fact that the task, instead of the planned 2–3 hours, was carried out in days. Given that at that time our cluster often fell, the task could simply not reach the end. The solution was also implemented in the form of a patch, which allows speeding up the aisles on the table due to “fast scans”. We put it up for discussion in the Apache issue tracker https://issues.apache.org/jira/browse/HBASE-5416 , where most of the active developers of HBase gathered, but since the patch affects a lot of HBase root elements, it hasn’t been integrated into common code. This patch was the largest, and it was with the end of its development that our cluster finally started working.
The fourth big problem that we have not yet overcome is the imbalance of the HBase regions.
There is a closer look at the approach to storing web pages in HBase. A classic example of using HBase is storing the contents of documents with a URL in the form of a key. Domains in the URL are written in reverse order, so that not only the pages of the site, but also the subdomains of one domain are located side by side, for example like this:
Such an approach was tempting with its logic, and we did the same. The problem is that the set of URLs expands over time, and it is likely that we will find many pages from one domain. The corresponding region in HBase will be noticeably “thicker” than the average.
To overcome this problem in HBase, there is a mechanism for dividing regions. But the reverse mechanism - mergers - is unstable. A constant increase in the number of regions in order to balance leads to large overhead costs for their maintenance.
And after writing a set of tasks for Hadoop, we thought again - what does the proximity of the documents in the table give us? This is convenient for a couple of tasks, but in general it creates more problems. And now we are moving towards introducing hashing for URLs. Thus, the documents will be distributed evenly; the execution time of mappers will also become uniform, which means that all tasks working with HBase will be accelerated.
While we were working on solutions, more and more components of our Search moved to Hadoop. Now all components, except indexing, work in Hadoop and in HBase.
Probably, we finally did what we wanted from the very beginning: we had a platform for distributed computing, data analysis. We cannot say that we are completely satisfied with it - simply because in the process of passing the path comes an understanding of what else I would like to receive from the platform. But now from the time of the appearance of the new URL to the moment when it appears in the index, it takes from 2 to 5 days. In the old version of the search engine this could occur from two weeks or more. Our next goal is to reduce the time to minutes. The architecture of the new version of the search engine is likely to be fundamentally different from the existing one.
MapReduce and spider
The MapReduce paradigm and the debugged Hadoop technology make it possible to scale the cluster easily. We increase the number of servers by 1.5 times - tasks start to work [almost] 1.5 times faster. However, not all tasks “fall” on the MapReduce paradigm, and some simply do not experience any improvements from it. This is true, for example, for a web spider: it is unprofitable to occupy a slot for downloading a site - there will always be slow hosting, due to which the precious slot will have to be held longer than necessary.
In addition, the “do everything within MapReduce” approach leads to inefficient use of resources, because a fast network is necessary for downloading pages, and, say, for parsing the contents of pages, a fast CPU.
This is the process of separation that happened in our crawler. Before it was a monolithic task which produced:
- DNS resolving + download page (requires network)
- Parsing Content (CPU)
- Check and import links (CPU + a lot of RAM)
- Storage of contents and backup (disks)
- Rebuilding pumping queue (CPU + a lot of RAM)
Scaling such a spider was extremely difficult: adding new machines meant repartitioning the base, which took several weeks. And it was simply impossible to conduct an experiment with a modification, say, a scheme for determining the language of a document: such a test took months.
The transition to Hadoop saved us from the problems of storing backups and gave a simple scalability for tasks demanding on the CPU and RAM. The crawler itself began to perform only the pumping function and was renamed the fetcher:
Now, when we have all the “business logic” in MapReduce, and the documents themselves in HBase, the introduction of a new language definition has become the task of one day.
We considered the transition to a unified Hadoop computing platform. The introduction of Hadoop for our project was perhaps the most revolutionary architectural solution. The transition to Hadoop and MapReduce continues for components that perform calculations "offline". The architecture of the “online” part that processes user queries, as well as the process of creating a search index, will be discussed further.
Indexing data
Indexing data takes place outside MapReduce, but it is also distributed among individual machines and relatively easily scaled.
Indexing works with so-called. microbase: the entire web set is divided into 2048 pieces, grouped by sites. Indexing data is incremental: new data is indexed over the existing database, and then the data is glued together. On each "indexer" machine, there are several queues distributed among the disks. Each queue processes several microbases.
A typical indexing machine looks like this:
The bottlenecks for indexers are CPUs and disks, which is why indexers are equipped with disks according to the number of cores; so is the number of processing queues.
Data for indexing, i.e. documents and their attributes are taken from HDFS. These are partial dumps of the same HBase table, which was mentioned earlier. As a result of indexing, the updated microbases are added to HDFS, and subsequently copied to search engines.
Despite the fact that the indexers themselves work outside the MapReduce paradigm, Hadoop also helps in this task: the central repository of microbases and the main backup is HDFS. In addition, the heavy parts of the indexers are also transferred to Hadoop, so that the end-users will be more engaged in their direct task - the compilation of a binary data index.
Search daemon
The tasks of a web search are to find documents that match the request, their ranking and the formation of informative output, mainly snippets. These problems are solved by a separate search backend. Issuing the same result for the SERP is formed by combining the answers of the backends. This function is performed by a component, which is usually called a meta-search (about it - in the next section).
The main technical requirement for backend is the response time. Backends have to work with a huge amount of data and a large flow of requests. Spontaneous delay, say, due to blocking on the disk should be an exception, but not a regular rule.
The search base traditionally consists of reverse and forward indexes, as well as auxiliary files: numeric properties of documents, request information, etc. The reverse index is used for document search and ranking. The direct index is used to build snippets. There are many approaches to the fact that this is always stored in memory, what to cache and what to read from the disk.
We were guided by a simple rule: the more transparent our system will be, the more predictable it will work. This does not apply, say, to such a part as the reading of compressed index blocks. Of course, the faster this phase works, the faster the whole search works. And this part of the search engines is traditionally polished and optimized for modern processors. But we don’t have a complicated scheme for caching index blocks.
Instead, we simply block the most requested parts in RAM (Unix, mlock (2)). This also includes parts with an average demand, but an arbitrary access to them, for example, the numerical properties of documents. But we keep the direct index on the disk, hoping for the OS cache. Note that the direct index is much less frequently requested than the opposite, because regardless of the increase in the number of search engines, users still need only a few results in the output.
As for the organization of demon processes, they work in the multi-process master-workers scheme. Given the separation into microbases (mdb), indicated in the previous section, the backend scheme looks like this:
Meta-search first requests a small number of results from all backends, merges them, and then receives snippets of those documents that will be included in the output.
Like the rest of the search engines, we are gluing the results on the fly. So, for example, we remove duplicate descriptions from the issue. Accordingly, we are forced to make additional requests to backends, and to speed up the response - to request with a slight lead.
Metasearch
The traditional search scheme includes many backends and components that combine partial results based on weights (relevance):
We have a similar scheme applied to the so-called. verticals - search by pictures and video. But in the form of mixes to the main issue of the vertical, they worked in such a way that they fit into the classical scheme: the pictures and videos had their own weights, which were adjusted to documents from the web.
Ensuring that the picture appears in the first place is quite simple. And what to do with the scales, if we want to put it on the 3rd position? I didn’t want to add such logic to the search-manager: nevertheless, its task is a banal combination of results. Therefore, we have made an additional node, the purpose of which is high-level work with the results and embedding podmes. As a result, our “middle-end” scheme mutated into the following:
This scheme also ensured the independence of the development of smanager-meta and the former smanager. Thanks to this, it has become much easier to embed subarrows, and now we are mixing over 20 different verticals.
This change also allowed us to isolate the “fast bases” into a separate block and split the caching of the results. We cache the results from the “fast bases” for 15 minutes, and the results of the “big web” for a day.
The smanager-meta component also switched to the preprocessing phase of the query: the use of synonyms, the reformulation of the query, and the compilation of the search tree. This rather capacious part of the search engine will probably be described in subsequent posts.
Afterword
We looked at the Mail.Ru Search architecture and how it has changed since the days when we were a GoGo search engine, serving only 10 requests per second. Part of the decisions was dictated by orders of magnitude increased load. The rest is the desire to bring flexibility and accelerate the pace of development.
Separately, I want to say about the choice of tools for the system. Many existing components are not ready for use in an environment where high performance is required with a large amount of data. That is why most of the components are written or refined under our infrastructure. This number includes our refinements regarding Apache HBase. All this makes it possible to use the existing equipment more closely. So, even after we significantly increased the server fleet, the cost of processing a single request remained relatively low.
Undoubtedly, the architecture is in close connection with external requirements. The data volumes or the number of requests changing by orders force to change the schemes of their processing. It is likely that the approaches presented will also undergo changes in a few years. But there is a feeling that we have made a significant step in order to concentrate more on the quality of the search. On how our user will perceive us.
Andrei Kalinin, Project Manager Search
Jan Kisel, Search Infrastructure Team Leader
Source: https://habr.com/ru/post/167297/
All Articles