The exceptional beauty of Doom 3 source code

Today you will find a story about the source code of Doom 3 and how beautiful it is.
Yes, beautiful . Let me explain.
After the release of my video game Dyad, I decided to take a short break. I finally read a few books and watched films that I had been putting in a long box for so long. Then I worked on the European version of Dyad , but all this time I mostly waited for feedback from Sony's quality department, so I had more than enough time. After a month of such a pastime, I seriously thought about what to do next. I remembered that I was going to separate pieces of source code from Dyad a long time ago that I wanted to use in my new project.
When I first started working on Dyad , it was a “transparent” game engine with good functionality, and it turned out that thanks to my experience in previous projects. Toward the end of the development of the game, he turned into a hopeless mess.
')
Over the last 6 weeks of developing Dyad, I have added 13k lines of code. The main menu source MainMenu.cc alone expanded to 25,501 lines. Once a beautiful code turned into a real mess from all #ifdef, function pointers, ugly SIMDs and assembler inserts - and I discovered the new term "code entropy". Sadly looking at all this, I went on a journey through the Internet in search of other projects that would help me understand how other developers beautifully managed with hundreds of thousands of lines of code. But after I looked at the code for a couple of big game engines, I was just discouraged; my “terrible” source code compared to the rest was even clearer!
I continued my search, dissatisfied with this result. In the end, I came across an interesting analysis of the Doom 3 source code from id Software , written by Fabian Sangard .
I spent several days studying the source code of Doom 3 and reading Fabian's articles, after which I tweeted:
I spent some time studying the Doom3 source code. This is probably the most understandable and cutest code I've ever seen.
And it was true. Up to this point, I have never cared about the source code. Yes, I, in fact, do not like too much to call myself a "programmer." I'm good at it, but for me, programming lasts exactly until everything starts working. After viewing the source code of Doom 3, I really learned to appreciate good programmers.
***
So that you get some idea: Dyad contains 193k lines of code, all in C ++. Doom 3 is 601k, Quake III is 229k and Quake II is 136k. These are big projects.
When I was asked to write this article, I used this as an excuse to read some more source code for other games and articles on programming standards. After a few days of my research, I would be embarrassed by my own tweet and it made me think - so what should be considered a “beautiful” source code? I asked several of my fellow programmers what they thought it meant. Their answers were obvious, but it still makes sense to bring them here:
- The code must be grouped locally and uniformly functional: One function must do exactly one thing. It should be clear what a particular function is doing.
- Local code should explain or at least point to the architecture of the entire system.
- The code must be documented "by itself". Comments should be avoided in all possible situations. Comments duplicate work for both reading and writing code. If you need to comment on something, then most likely it should be rewritten from scratch.
For idTech 4, code standards are publicly available ( .doc ) and I can recommend them as worthy reading. I will go over most of these standards and try to explain how they make the Doom 3 code so beautiful.
Universal parsing and lexical parsing
One of the smartest things I saw in Doom is using their lexical analyzer and parser throughout the program. All resource files are ascii files with a single syntax including: scripts, animation files, configs, etc .; everything is the same. This allows you to read and process all files with the same piece of code. The parser is especially reliable, and supports the main subset of C ++. The commitment to a single parser and lexical analyzer helps the rest of the engine components not to worry about data serialization, since the code responsible for this part of the application has already been written. Due to this, the rest of the code becomes much clearer.
Const and strict parameters (Rigid Parameters)
The Doom code is rather strict, but (in my opinion) not strict enough with respect to const. Const serves several reasons, which I am sure are ignored by too many programmers. My rule is this: "const should be used everywhere, except in cases where it cannot be used." I dream that all variables in C ++ will be const by default. Doom almost always follows the “no input-output” policy for parameters; meaning that all parameters passed to a function are either input or output, and never combine this role in one person. This simple trick allows you to see how much faster what happens to any variable when you pass it to a function. For example:

The mere definition of this function already makes me happy!
Only from a few things that immediately strike my eyes, very much already becomes clear:
- idPlane is passed to the function as an immutable argument. I can safely use the same plane after calling this function without checking for idPlane changes.
- I know that epsilon will not be changed inside the function (although it can be copied to another variable without problems and used to initialize it - this method will be unproductive)
- front, back, frontOnPlaneEdges and backOnPlaceEdges are OUTPUT variables. They will be recorded.
- the final const modifier after the parameter list is my favorite. It indicates that idSurface :: Split () cannot change the surface itself. This is one of my favorite features in C ++, which I miss so much in other languages. She lets me do something like this:
void f (const idSurface & s) {
s.Split (....);
}
if Split would not have been defined as Split (...) const; this code would not compile. Now I will always know that any call to f () will not change the surface, even if f () is passed to the surface by another function or calls any of the Surface :: method () methods. Const tells me a lot about this feature and also gives hints about the overall system architecture. One reading of the declaration of this function makes it clear that the surfaces can be separated by planes dynamically. Instead of changing the original surface, we will be returned new surfaces - front and back, and also, possibly, the side frontOnPlaneEdges and backOnPlaneEdges.
The rule of using const and the absence of "input-output" parameters in my assessment is one of the most important things separating good code from delightful code. Such an approach makes it easier not only to understand the system itself, but also to change or refactor it.
Minimalist comments
This item, of course, is more concerned with the style of writing code, but nevertheless - there is such a wonderful thing in Doom as the absence of excessive commenting. I have seen in my practice too much code, very similar to similar:

Such techniques, in my opinion, very, very annoying thing. Why? Because I can already name what this code does, you just have to look at its name. If the purpose of the method from its name is not clear to me, then its name should be changed. If the name is too long, shorten it. If it cannot be changed and is already reduced - well, then you can use the comment. All programmers from school are taught that commenting is good; but it is not so. Comments are bad until they are needed. But they are extremely rare. The creators of Doom did a responsible job in order to keep the number of comments to a minimum. Using idSurface :: Split () as an example, let's look at how it is commented out:
// splits the surface into front and back surfaces, the surface itself remains unchanged
// frontOnPlaneEdges and backOnPlaneEdges optionally store the indexes of the vertices that lie on the edges of the dividing plane
// returns SIDE_?
The first line is completely redundant. We already know all this from the definition of a function. The second and third lines carry some new information. We could remove the second line, but this could cause a potential ambiguity.
For the most part, the Doom code is very harsh with respect to your own comments, which makes it much easier to read. I know that this may be a matter of style for some people, but it seems to me that there definitely is a “right” way to do it. For example, what should happen if someone changes the function and removes the constant at the end? In this case, for the external code, the function call will change, and now the comment will be unrelated to the code. Unauthorized comments harm the readability and accuracy of the code, so the code gets worse.
Indentation
Doom is not inclined to waste free vertical screen space.
Here is an example from t_stencilShadow :: R_ChopWinding ():

I can read the whole algorithm without problems, because it fits on 1/4 of my screen, leaving the other 3/4 to figure out how this code can relate to the surrounding it. I've seen too much of this in my life:
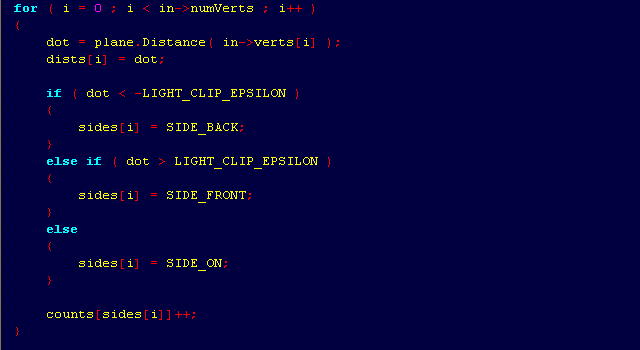
There will be one more remark falling under the category "style". I have been programming in the style of the last example for more than 10 years, and forced myself to switch to a more compact code only six years ago while working on one of the projects. I'm glad I switched in time.
The second method takes 18 lines relative to the 11 lines in the first. Almost twice as many lines of code with the same functionality. In addition, the next piece of code clearly does not fit on my screen. And what's in it?
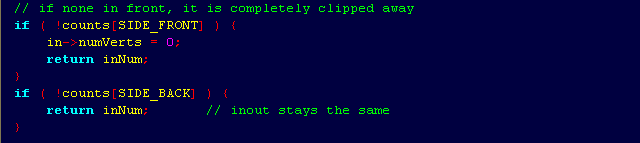
This code does not make any sense without a previous piece with a loop. If id didn't save vertical space, then their code would become much harder to read, support and immediately lose in beauty.
The other thing that id decided to accept as a permanent rule, I also strongly support - this solution is always to use {}, even when it is not necessary. I have seen too much code like this:

I could not find a single example in the id code, where they would at least once miss {}. If you omit the additional {}, then the analysis of the while () block will take several times longer than it should. In addition, any revision turns into real suffering - it’s enough to imagine that I will need to insert an if-condition on the else if (c> d) path.
Minimal pattern usage
id broke one of the greatest bans in the C ++ world. They rewrote all the required STL functions. Personally, I am in the STL relationship “from love to hate one step”. In Dyad, I used it in debug builds to manage dynamic resources. In the release, I packed all the resources so that they could be loaded as quickly as possible, and they stopped using the STL functionality. STL is quite a handy thing because it gives access to basic data structures; its main problem is that its use leads to ugly code and is error prone. For example, take a look at the std :: vector class. Let's say if I need to sort through all the elements:

In C ++ 11, the same thing looks a lot easier:

Personally, I do not like the use of auto, it seems to me that it makes the code easier to write, but harder to read. I sometimes used auto in past years, but now it seems to me that this was the wrong decision. I'm not even going to start discussing the absurdity of some of the algorithms on STL, such as std: for_each or std :: remove_if.
Removing a value from std :: vector is also a horror:

Imagine, each programmer must type this line correctly each time!
id removes all ambiguity: they roll out their own base containers, string class, etc. They try to make them more specific than their STL counterparts — perhaps to make them easier to understand. They are minimally template-based and use their own memory allocators. And the STL code is littered with the constant use of templates so that it is simply impossible to read.
C ++ code quickly becomes unmanageable and ugly, so programmers constantly have to make their efforts to get the opposite effect. And so that you understand how far things can go, look at this STL source code. Microsoft's implementation of STL and GCC is one of the worst source codes I've ever seen. Even if the programmer blows away any specks of dust from the template code, the code still turns into a complete mess. For an example, take a look at the Loki library from Andrei Alexandrescu, or the boost libraries - these lines are written by one of the best C ++ programmers in the world, and even his efforts to make them as beautiful as possible were able to degenerate only into ugly and completely unreadable code.
How does id solve this problem? They simply do not try to bring everything to a “common denominator” by over-generalizing their functions. They have classes HashTable and HashIndex, the first requires the type of the key to be const char *, and the second - a pair of int-> int. In the case of C ++, such a decision is considered to be bad - “should” create a single class HashTable, and write two different processing in it for KeyType = const char * and <int, int>. But what made the id , also correctly, and moreover - made their code many times more beautiful.
It is not difficult to verify this; it is enough to trace the contrast between the “good C ++ programming style” to generate the hash and the way id handled it.
To many, it seems like a good idea to create a special class of calculations that can be passed as a parameter to the HashTable:

it can be specified as a specific type:

Now you can pass ComputeHashForType as a HashComputer for HashTable:

Similarly, I did at home. It looks like a smart decision, but ... how ugly! What if we end up with a large number of parameters in the template? With memory allocator? With debugging? Then we will have something like this:

Brutal definition of a function, isn't it?

So what is this all about? I could hardly find the name of the method without a bright syntax highlighting. It is likely that the definition of a function will take up more space than its body. Definitely hard to read and not too beautiful.
I have seen how other engines manage with a similar disorder method of offloading the assignment of function arguments using billions of typedefs. This is even worse! Maybe the code “right in front of you” will become clearer, but there will be an even greater gap between the system and the current code than it was before, and this code will no longer indicate the design of the entire system - which violates our principle of beauty. For example, we have the code:

and

and you used them together and did something like this:

Perhaps the StringHashTable memory allocator named StringAllocator does not contribute to global memory, which can confuse you. You will have to look through all the code, find out that the StringHashTable is in fact typedef from confusing patterns, go through the source code of the pattern, find another allocator, find its description ... a nightmare, just a nightmare.
Doom goes against the principles of C ++ logic: the code is written as specific as possible, using generalizations only where it makes sense. What does the HashTable of Doom do when it needs to generate a hash or something else? It calls idStr :: GetHash (), because the only type of key it accepts is const char *. What happens if another key is needed? It seems to me that they template the key and simply force the call to key.getHash (), and the compiler ensures that the key types have an int getHash () method.
Remains in the "inheritance" from C
I don’t know exactly how many of the id programmers in the 90s are working for the company now, but at least John Carmack himself has a lot of programming experience in C. All the id games before Quake III were written in C. I met C ++ programmers who don’t had a lot of programming experience in C, so their code was too C ++ zipper. The last example was just one of many - here are others that I meet quite often:
- Frequent use of get / set methods
- use stringstream
- operator overloading.
id strictly follows all these cases.
It often happens that someone creates a class in this way:

This is a waste of lines of code and the subsequent time to read it. This option will eat more of your time than

And what if you often have to increase var by some number n?

in comparison with

The first example is much easier to write and read.
id does not use stringstream. stringstream contains one of the most important "bastardization" operator overload, which I have ever met: <<.
For example,

It's not beautiful. This method has a strong advantage: you can define the equivalent of the toString () function from Java for a particular class that will affect class variables, but the syntax will become too inconvenient, and id decides not to use this method. The choice to printf () instead of stringstream makes the code easier to read, and I think this choice is the right one.

Much better!
The syntax of the << operator for SomeClass is ridiculous:

[Note: John Carmack once remarked that statistical code analysis programs helped to find out that their common bug was caused by incorrect parameters in printf (). I wonder if they switched to stringstream in Rage because of this? .. GCC and clang both They report such an error when using the -Wall flag, so that you can all see for yourself without resorting to costly analyzers to look for these errors.]
Another principle that makes the Doom code so beautiful is the minimal use of operator overloading. This is a very popular and convenient feature, introduced in C ++, that allows you to do something like this:

Without overloading, these operations will become less obvious and take longer to write and read. This is where Doom stops. I saw the code that goes on. I’ve seen code that overloads the '%' operator to denote the scalar product of vectors, or the Vector * Vector operator that performs vector multiplication. It makes no sense to start the operator * for such an action, which will be feasible only in 3D. After all, if you want to do some_2d_vec * some_2d_vec, then what would you do? What about 4d or more? That is why the principle of minimal intervention from id is correct - it does not leave us any discrepancies.
Horizontal indents
One of the most important things I learned from the Doom source code was a simple style change. I'm used to my classes look something like this:

According to the standard code for Doom 3 , id uses a real tab, which corresponds to 4 spaces. The same default tab allows all programmers to align the definitions of their classes horizontally without any hesitation:

They prefer not to make the definition of inline functions inside the class definition. The only case I met was when the code was written on the same line as the function declaration. Most likely, this practice is not the norm and is not approved. This way of organizing class definitions makes them easy to read. It may take you a little more time to reprint the ones already entered to define the methods:

I myself am against excessive typing on the keyboard. The main thing that I need is to do my job as quickly as possible - but in this situation, a small bust of typing in the definition of a class pays off more than once or twice in the case when the programmer has to view the definition of the class. There are a few more examples of coding style that are described in the Doom 3 Coding Standards ( .doc ) document, which is responsible for all the beauty of the Doom 3 source code.
Method Names
In my opinion, the rules for naming methods in Doom still lack something. Personally, I like to use this rule in my work: all method names must begin with verbs, and exceptions are only those cases where this cannot be implemented.
For example:

much better than:

Yes, he is incredibly beautiful.
I am glad that this article saw the light, because it allowed me to reflect on the topic of what we mean by the beauty of the code. To be honest, I'm not sure that I understood anything. It is possible that all my assessments are too subjective. Personally for myself, I noted at least a couple of very important things - the style of indents and the constant use of constants.
Many of the choices in the code style are my personal preferences; I have no doubt that other programmers will be completely different. In my opinion, the burden of choosing the style of writing code rests entirely on the shoulders of the one who is going to write and read it, but even this should be thought about from time to time.
I would like to advise everyone to take a look at the source code of Doom 3 , because you will not see such source code every day: here you have a complete set, from the design of the system architecture to tabulation between characters.
Shawn McGrath is a game developer living in Toronto, the creator of the popular psychedelic game for the Playstation 3 - Dyad puzzle-race. We advise you to take a look at his game and follow him on Twitter .
Notes
Note John Carmack
Thank! A few comments:
I continue to think that in a certain way, the Quake 3 code is still better, because it became the top of the evolution of my C-style - unlike the first attempt at programming the C ++ engine, but this can only be my illusion due to the small number of lines in the first , or due to the fact that I have not looked into him for a dozen years.I think that “good C ++” is better than “good C” in terms of readability, while otherwise languages are equivalent.
I was doing it with C ++ in Doom 3 - the fact is that I was an experienced C programmer with OOP skills from the time of NeXT and Objective-C, so I started writing C ++ code without full learning all the principles of using language. Looking back, I can notice that I strongly regret that I did not read Effective C ++ and something else on this subject. A couple of other programmers had enough experience in C ++, but for the most part they followed my stylistic choices.
I didn’t trust templates for many years, and now I use them cautiously, but I somehow decided that the charms of strong typing outweigh the balance in the direction opposite to the strange code in the header files. So the controversy surrounding the STL still does not subside with us in id, and now they have received an additional “spark”. Returning to the days when the development of Doom 3 began, I can almost certainly say that using STL would definitely be a bad idea, but now ... there are many reasonable arguments for, even in the case of games.
Now I have become a terrible "const nazi", and I report to any programmer who does not make a variable or parameter a constant, if they could be it.
With regards to me personally, my own evolution directs me towards a more functional programming style, which means weaning off from a large number of old habits and a departure from some OOP techniques.
[www.altdevblogaday.com ]
Note Translation
I myself came across Fabien blog about fifteen years ago, and I can safely recommend it to all who are interested - if not for the thoughtful reading, at least for the sake of inspiration.
Regarding the "clean" code - on Twitter, I asked Carmack not so long ago what he would recommend to read on the topic. He strongly advised the book "Art of the Readable Code" ( Amazon ).
Source: https://habr.com/ru/post/166113/
All Articles