Microsoft HDInsight. The cloudy (and not only) future of Hadoop
The amount of data generated and collected by modern research centers, financial institutions, social networks, is already routinely measured by petabytes. So, more than 15 billion images are already stored in Facebook data centers, the New York Stock Exchange NYSE creates and replicates about 1 TB of data daily, the Large Hadron Collider receives about 1 PB of data per second.
Obviously, the task of processing large amounts of data are increasingly becoming not only to large companies, but also to start-ups and small research groups.
The Hadoop platform, which, in principle, successfully solves the Big Data problem for semi- and unstructured data, in its “pure” form places considerable demands on the qualifications of the administrators of the Hadoop cluster and on the initial financial costs of the hardware of such a cluster.
')
In such a situation, the symbiosis of cloud technologies and the Hadoop platform is increasingly presented as an extremely promising way to solve the Big Data problem , which has an extremely low level of entry (qualification + launch costs).
Today, the largest cloud providers, with varying degrees of proximity to the release version, provide Cloud Computing + Hadoop services. So Amazon in 2009 announced Amazon Elastic MapReduce, Google in 2010 - Google MapperAPI, Microsoft in 2011 - Windows Azure HDInsight.
The service from Microsoft this year showed a high dynamics of development and, in general, provides a wide range of opportunities related to both managing and developing and integrating with Windows Azure cloud services and other Microsoft BI tools .
HDInsight is a Microsoft solution for deploying the Hadoop platform on the Windows Server family of operating systems and on the Windows Azure cloud platform.
HDInsight is available in two versions:
2011
Microsoft's partnership with Hortonworks, aimed at integrating the Hadoop platform into Microsoft products, was announced in October 2011 at the Professional Association for SQL Server (PASS) conference.
On December 14 of the same year, the cloud service “ Hadoop on Azure ” (CTP) was available, available for a limited number of invites.
2012
June 29, 2012 there was an update service Hadoop on Azure (Service Update 2). The most noticeable change compared with the previous version of the service was an increase in the cluster capacity by 2.5 times.
Already after 2 months (August 21), the third update Service Update 3 was released, among the innovations of which were:
On October 25, at the Strata Conference-Hadoop World conference, the HDInsight solution (development of the service, formerly known as Hadoop on Azure) was presented, which allows you to deploy the Hadoop platform both in enterprises ( on-premise ) and on-demand ( on-demand ) .
In October of the same year, the Microsoft .NET SDK for Hadoop project was launched, among whose bright goals are the creation of a Linq-to-Hive, Job Submission API and WebHDFS client.
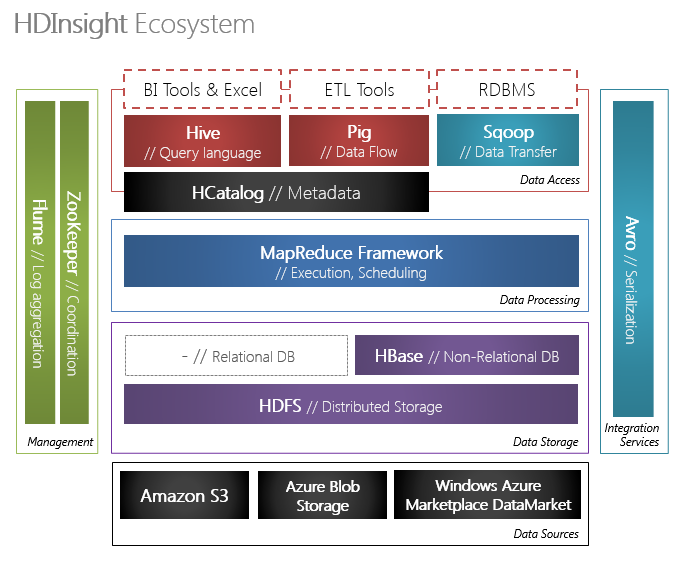
As of December 2012, HDInsight is in the testing phase and, in addition to Hadoop v1.0.1, includes the following components *:
Development under HDInsight can be conducted in C #, Java, JavaScript, Python.
HDInsight has the ability to integrate:
For Microsoft SQL Server 2012 Parallel Data Warehouse in 2013, a connector for SQL Server (for data exchange), integration with SQL Server Integration Services (for data loading) and with SQL Server Analysis Services (analytics) is expected.
In the next part of the article, a practical example of writing a Hadoop task (Hadoop Job) of word counting on a locally installed HDInsight for Windows Server solution will be considered.
2. HDInsight. Practical work
Training
To begin with, we will install the Microsoft HDInsight for Windows Server CTP solution through the Web Platform Installer. After successfully completing the installation of the solution, we will have new websites on the local IIS and useful shortcuts on the desktop.
Javascript wordcounter
We need one of these shortcuts, pointing to a website with the saying name “HadoopDashboard”. When you click this shortcut, the HDInsight control panel opens.
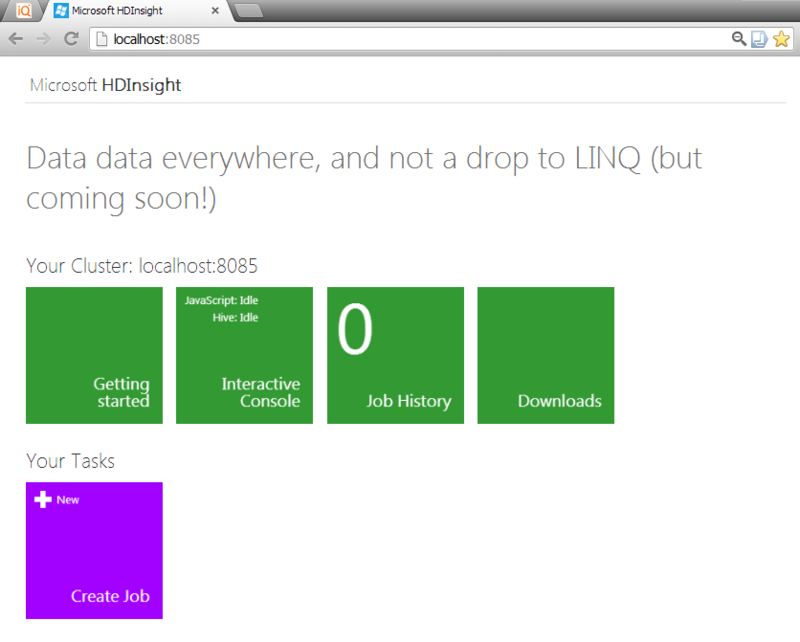
Moving on the “Interactive JavaScript” tile, we proceed to creating a job (Job) for our local cluster. Let's start with the task of classic word counting.
To do this, we will need several files with text (I took the speech of one of Martin Luther King’s speeches) and the javascript counting logic itself in the map and reduce phases (Listing 1). According to this logic, we will divide words when finding a non-letter character (obviously, this is not always the case), besides getting rid of the “noise”, we will not take into account words shorter than 3 characters.
Listing 1. The wordCountJob.js file
The text files created for analysis and javascript saved in the wordCountJob.js file must be transferred to HDFS (Listing 2).
Listing 2.
Done looks like this:

We make a request for getting the first 10 results ordered in descending order:
And so it would look like for Amazon S3 cloud storage:
We start and in the end we get something like:
Let's view the result in the form of a textual output, and then a graphic one.

It is gratifying to note that Martin Luther King so often used such words as “love”, “freedom”, “choice”, “life”.
3. And then what?
According to the subjective opinion of the author, the task of counting the frequency of words in a text fragment (if we do without connecting the morphological analysis) is not distinguished by the complexity of the subject area. And, as a result, it does not cause afading of the heart of wild interest neither in me, nor in the IT community.
The most typical "Big Data" -cases are studies whose purpose is:
I will not go further, since this is the topic of a separate article. Let me just say that cases solved on the Hadoop platform, in general, have the following properties:
Therefore, answering the question presented in the subtitle (“what's next?”), I set the first task to change the subject area . My view fell on the financial sector, in particular, on high-frequency trading ** (High Frequency Trading, HFT).
The second aspect that needs to be looked at in a way different from that presented in the previous example is the automation of calculations .
The Javascript + Pig bundle, available from HDInsight Dashboard, is certainly a powerful tool in the hands of an analyst familiar with the subject area and programming. But still it is a “man in the middle” and this is a manual input. For a trading robot, this approach is obviously unacceptable.
To be fair, I repeat that HDInsight supports task execution via the command line, which can be great at automating the solution to any data analysis task. But for me it’s more of a quantitative improvement than a qualitative one.
A qualitative improvement is the development of one of the high-level programming languages supported by HDInsight. These include Java, Python, and C #.
So, we decided on what needs to be changed in order to show the benefits of using HDInsight, and it was not a shame to show both the boss and the IT conference.
Unfortunately, the description of the tasks of the analysis component of stock ticks and the implementation of these tasks (with the bringing of the source code) besides that far from the final stage, it also goes beyond the scope and scope of the article (but I assure you, this is a matter of time).
Conclusion
HDInsight is a flexible solution that allows a developer to deploy a Hadoop “on-premises” cluster in a fairly short time or order it as an on-demand service in the cloud, while receiving a wide range of programming languages and friends to choose from (for .NET developers) development tools.
Thus, the HDInsight solution unprecedentedly reduces the level of entry into the development of data-intensive applications. That, in turn, will necessarily lead to even greater popularization of the Hadoop platform, MPP applications and the demand for such applications among researchers and businesses.
Source of inspiration
[1] Matt Winkler. Developing Big Data Analytics Applications with .NET and .NET for Windows Azure and Windows . Build 2012 Conference, 2012.
* Component versions listed as of December 2012.
** The author knows that this is not the most typical case for Hadoop (in the first and only turn, due to sensitivity to real-time-calculations). But the eyes are afraid, and thehands - make the head - think.
Obviously, the task of processing large amounts of data are increasingly becoming not only to large companies, but also to start-ups and small research groups.
The Hadoop platform, which, in principle, successfully solves the Big Data problem for semi- and unstructured data, in its “pure” form places considerable demands on the qualifications of the administrators of the Hadoop cluster and on the initial financial costs of the hardware of such a cluster.
')
In such a situation, the symbiosis of cloud technologies and the Hadoop platform is increasingly presented as an extremely promising way to solve the Big Data problem , which has an extremely low level of entry (qualification + launch costs).
Today, the largest cloud providers, with varying degrees of proximity to the release version, provide Cloud Computing + Hadoop services. So Amazon in 2009 announced Amazon Elastic MapReduce, Google in 2010 - Google MapperAPI, Microsoft in 2011 - Windows Azure HDInsight.
The service from Microsoft this year showed a high dynamics of development and, in general, provides a wide range of opportunities related to both managing and developing and integrating with Windows Azure cloud services and other Microsoft BI tools .
1. HDInsight. Review, history, ecosystem
HDInsight is a Microsoft solution for deploying the Hadoop platform on the Windows Server family of operating systems and on the Windows Azure cloud platform.
HDInsight is available in two versions:
- as a cloud service on Windows Azure - Windows Azure HDInsight (for access you need an invite);
- as a local cluster on Windows Server 2008/2012 - Microsoft HDInsight to Windows Server (CTP) (installation is available via WebPI, including on the desktop versions of Windows).
2011
Microsoft's partnership with Hortonworks, aimed at integrating the Hadoop platform into Microsoft products, was announced in October 2011 at the Professional Association for SQL Server (PASS) conference.
On December 14 of the same year, the cloud service “ Hadoop on Azure ” (CTP) was available, available for a limited number of invites.
2012
June 29, 2012 there was an update service Hadoop on Azure (Service Update 2). The most noticeable change compared with the previous version of the service was an increase in the cluster capacity by 2.5 times.
Already after 2 months (August 21), the third update Service Update 3 was released, among the innovations of which were:
- REST API for setting tasks (Job), querying the status of completion and removal of tasks;
- the ability to directly access the cluster through a browser;
- C # SDK v1.0;
- PowerShell cmdlets.
On October 25, at the Strata Conference-Hadoop World conference, the HDInsight solution (development of the service, formerly known as Hadoop on Azure) was presented, which allows you to deploy the Hadoop platform both in enterprises ( on-premise ) and on-demand ( on-demand ) .
In October of the same year, the Microsoft .NET SDK for Hadoop project was launched, among whose bright goals are the creation of a Linq-to-Hive, Job Submission API and WebHDFS client.
As of December 2012, HDInsight is in the testing phase and, in addition to Hadoop v1.0.1, includes the following components *:
- Pig version 0.9.3: high-level data processing language and framework for executing these queries;
- Hive 0.9.0: distributed storage infrastructure that supports data queries;
- Mahout 0.5: machine learning;
- HCatalog 0.4.0: metadata management;
- Sqoop 1.4.2: move large amounts of data between Hadoop and structured data stores;
- Pegasus 2: graph analysis;
- Flume : a distributed, highly accessible service for collecting, aggregating and moving log data to HDFS.
- Business intelligence tools, incl.
- Hive ODBC Driver;
- Hive Add-in for Excel (available for download via HDInsight Dashboard).
Development under HDInsight can be conducted in C #, Java, JavaScript, Python.
HDInsight has the ability to integrate:
- with Active Directory for security management and access control;
- with System Center for cluster management purposes;
- Azure Blob Storage and Amazon S3 cloud storage services as with data sources.
For Microsoft SQL Server 2012 Parallel Data Warehouse in 2013, a connector for SQL Server (for data exchange), integration with SQL Server Integration Services (for data loading) and with SQL Server Analysis Services (analytics) is expected.
In the next part of the article, a practical example of writing a Hadoop task (Hadoop Job) of word counting on a locally installed HDInsight for Windows Server solution will be considered.
2. HDInsight. Practical work
Training
To begin with, we will install the Microsoft HDInsight for Windows Server CTP solution through the Web Platform Installer. After successfully completing the installation of the solution, we will have new websites on the local IIS and useful shortcuts on the desktop.
Javascript wordcounter
We need one of these shortcuts, pointing to a website with the saying name “HadoopDashboard”. When you click this shortcut, the HDInsight control panel opens.
Moving on the “Interactive JavaScript” tile, we proceed to creating a job (Job) for our local cluster. Let's start with the task of classic word counting.
To do this, we will need several files with text (I took the speech of one of Martin Luther King’s speeches) and the javascript counting logic itself in the map and reduce phases (Listing 1). According to this logic, we will divide words when finding a non-letter character (obviously, this is not always the case), besides getting rid of the “noise”, we will not take into account words shorter than 3 characters.
Listing 1. The wordCountJob.js file
// map() implementation var map = function(key, value, context) { var words = value.split(/[^a-zA-Z]/); for (var i = 0; i < words.lenght; i++) { if (words[i] !== "" && words[i].lenght > 3) { context.write(words[i].toLowerCase(), 1); } } }; // reduce() implementation var reduce = function (key, values, context) { var sum = 0; while (values.hasNext()) { sum += parseInt(values.next()); } context.write(key, sum); }; The text files created for analysis and javascript saved in the wordCountJob.js file must be transferred to HDFS (Listing 2).
Listing 2.
#mkdir wordcount // wordcount fs.put("wordcount") // fs.put("wordcount") #ls wordcount // fs.put() // HDFS wordCountJob.js #cat wordCountJob.js // wordCountob.js Done looks like this:
We make a request for getting the first 10 results ordered in descending order:
pig.from("wordcount").mapReduce("wordCountJob.js", "word, count:long").orderBy("count DESC").take(49).to("output"); And so it would look like for Amazon S3 cloud storage:
pig.from("s3n://HDinsightTest/MartinLutherKing").mapReduce("wordCountJob.js", "word, count:long").orderBy("count DESC").take(49).to("output"); We start and in the end we get something like:
[main] INFO org.apache.pig.backend.hadoop.executionengine.mapReduceLayer.MapReduceLauncher - Success! (View Log) Let's view the result in the form of a textual output, and then a graphic one.
js> #ls output // Found 3 items
-rw-r--r-- 1 hadoop supergroup 0 2012-12-12 08:47 /user/hadoop/output/_SUCCESS drwxr-xr-x - hadoop supergroup 0 2012-12-12 08:47 /user/hadoop/output/_logs -rw-r--r-- 1 hadoop supergroup 0 2012-12-12 08:47 /user/hadoop/output/part-r-00000 js> #cat output/part-r-00000 // Result (word / number of occurrences)
that 115
they 65
this 57
their 50
must 50
have 48
with 39
will 38
vietnam 38
them 33
nation 27
from 26
when 23
world 23
which 22
america 22
speak 21
there 20
were 17
into 16
life 15
against 15
those 14
american 14
revolution 14
been 14
make 13
people 13
land 13
government 13
these 13
about 13
what 12
such 12
love 12
peace 12
more 11
over 11
even 11
than 11
great 11
only 10
being 10
violence 10
every 10
some 10
without 10
would 10
choice 10
they 65
this 57
their 50
must 50
have 48
with 39
will 38
vietnam 38
them 33
nation 27
from 26
when 23
world 23
which 22
america 22
speak 21
there 20
were 17
into 16
life 15
against 15
those 14
american 14
revolution 14
been 14
make 13
people 13
land 13
government 13
these 13
about 13
what 12
such 12
love 12
peace 12
more 11
over 11
even 11
than 11
great 11
only 10
being 10
violence 10
every 10
some 10
without 10
would 10
choice 10
js> file = fs.read("output") js> data = parse(file.data, "word, count:long") js> graph.bar(data) // It is gratifying to note that Martin Luther King so often used such words as “love”, “freedom”, “choice”, “life”.
3. And then what?
According to the subjective opinion of the author, the task of counting the frequency of words in a text fragment (if we do without connecting the morphological analysis) is not distinguished by the complexity of the subject area. And, as a result, it does not cause a
The most typical "Big Data" -cases are studies whose purpose is:
- identify complex dependencies in social networks;
- anti-fraud systems (fraud detection) in the financial sector;
- genome research;
- log analysis, etc.
I will not go further, since this is the topic of a separate article. Let me just say that cases solved on the Hadoop platform, in general, have the following properties:
- the solved problem is reduced to the parallel data problem
(with the advent of YARN, the fulfillment of this condition is not critical); - input data does not fit into RAM;
- input data are semi- and / or unstructured;
- input data is not streaming data;
- The result is not realtime-sensitive.
Therefore, answering the question presented in the subtitle (“what's next?”), I set the first task to change the subject area . My view fell on the financial sector, in particular, on high-frequency trading ** (High Frequency Trading, HFT).
The second aspect that needs to be looked at in a way different from that presented in the previous example is the automation of calculations .
The Javascript + Pig bundle, available from HDInsight Dashboard, is certainly a powerful tool in the hands of an analyst familiar with the subject area and programming. But still it is a “man in the middle” and this is a manual input. For a trading robot, this approach is obviously unacceptable.
To be fair, I repeat that HDInsight supports task execution via the command line, which can be great at automating the solution to any data analysis task. But for me it’s more of a quantitative improvement than a qualitative one.
A qualitative improvement is the development of one of the high-level programming languages supported by HDInsight. These include Java, Python, and C #.
So, we decided on what needs to be changed in order to show the benefits of using HDInsight, and it was not a shame to show both the boss and the IT conference.
Unfortunately, the description of the tasks of the analysis component of stock ticks and the implementation of these tasks (with the bringing of the source code) besides that far from the final stage, it also goes beyond the scope and scope of the article (but I assure you, this is a matter of time).
Conclusion
HDInsight is a flexible solution that allows a developer to deploy a Hadoop “on-premises” cluster in a fairly short time or order it as an on-demand service in the cloud, while receiving a wide range of programming languages and friends to choose from (for .NET developers) development tools.
Thus, the HDInsight solution unprecedentedly reduces the level of entry into the development of data-intensive applications. That, in turn, will necessarily lead to even greater popularization of the Hadoop platform, MPP applications and the demand for such applications among researchers and businesses.
Source of inspiration
[1] Matt Winkler. Developing Big Data Analytics Applications with .NET and .NET for Windows Azure and Windows . Build 2012 Conference, 2012.
* Component versions listed as of December 2012.
** The author knows that this is not the most typical case for Hadoop (in the first and only turn, due to sensitivity to real-time-calculations). But the eyes are afraid, and the
Source: https://habr.com/ru/post/165265/
All Articles