Electric field simulation with CUDA
This article is written to demonstrate how CUDA can be used to simulate the simple interaction of charged particles (see Coulomb's Law ). To display a static image, I used the freeglut library.
How often they write on Habré:
Back in the days of Turbo Pascal and Borland C 5.02, I was interested in the process of simulating simple physical phenomena of nature, be it gravitational forces or Coulomb interaction. Unfortunately, the power of a single processor with several hundred MHz was not enough for simple mathematical operations, of which there were a lot of them.
Although I am not a pogrommist, I once wanted to recall a distant childhood, and learn some of the basics of JavaScript, and I somehow modeled the gravitational interaction of any reasonable number of material points. So, for example, the particle below revolves around the "sun" using the Newtonian law:
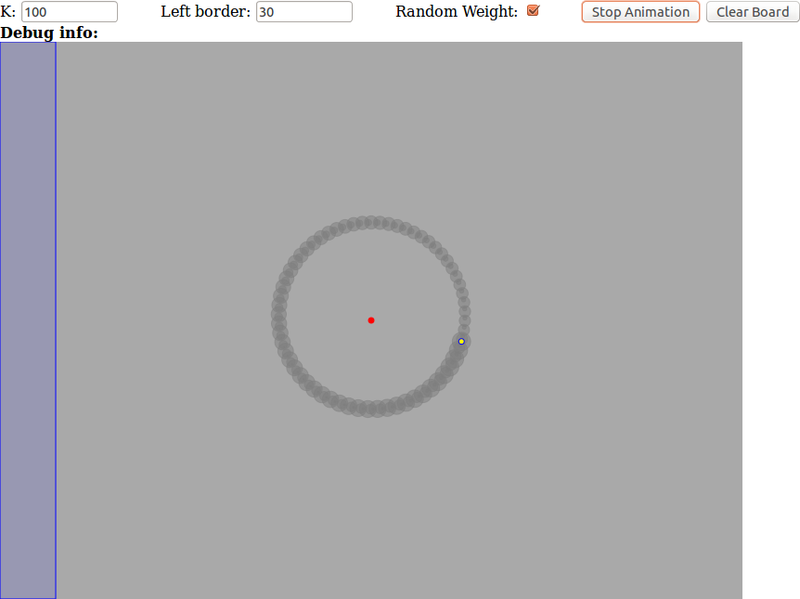
If it will be interesting for you, and I will not leave enthusiasm, then I will describe to you the creation of such a demo, so that you can write your evil birds in a vacuum.
')
So, stop nostalgic, let'spogrom programming. My platform is a laptop with Ubuntu and a GeForce GT 540m video card and CUDA Toolkit 5.0 installed. If you start your acquaintance with CUDA, I can advise you on an interesting book CUDA by Example .
To begin with, create a project from the Nsight template and connect the freeglut to it using the libraries GLU, GL, glut . This will allow us to display the resulting vector field, which we calculate. The approximate structure of our file with the
To begin with, everything looks simple. Let's first display the window of the size we need, and then render a black screen. By the way, I will tell you the obvious thing: if any function is unfamiliar to you, just google it .
Since when I conceived the application, I did not plan to dynamically resize the window, I decided to specify it declaratively using global constants:
Oh yes! Do not judge strictly for mixing styles C ++ and C99. Some things, such as overload, I sometimes find useful, but I did not refuse malloc to at least somehow follow the style of applications with CUDA.
The window display itself, the Escape key processing and the simple render can be done with the following code:
When you run this code, you will not see anything except the black screen. So I will omit the screenshot here. Pay attention to the following points:
Pampering with examples, I was able to figure out for myself what such a thing as a block and a flow represents, and what to do with their dimension. In principle, if we omit the technical details, the block is a cell in which there are a certain number of flows. When a whole grid of blocks is calculated, at some point in time, each block fires its streams, waits for them to complete, and transfers control to another block. So, for example, you can pile up blocks in a one-dimensional strip, or in a two-dimensional grid.
The streams, in turn, can also be located in a block in the form of a one-dimensional band, or a two-dimensional table. By the way, variants with three dimensions are possible, but I will miss them, since they do not yet fit into my task.
I can break the screen into large squares (blocks), inside which the pixels will be rendered as a separate stream. Such a task is the optimal use of a graphics card, but to break the screen into blocks, you have to apply simple arithmetic - I find out the number of flows allowed for me within the block, and then I divide the window size by the number of flows horizontally and vertically.
To find out the number of threads inside a block, we use the
My map returns the number 1024. Unfortunately, I cannot use all the threads, because in debug mode, when dividing the
If you have read my article up to this point, then I am glad that it is not for nothing that I sit at night in front of the computer. And if you know the answer, how to find out exactly what was my mistake, and let me know it, then I will be doubly glad.
Now we will break our field into blocks and streams:
The result will be as follows (I deliberately increased the number of blocks by one in cases where the screen size is not a multiple of the number of streams):
Charges, distances, pendants and odds - that sounds good. But when it comes to modeling, here we can’t use super-small values, because they can disappear in the calculation process. Therefore, we simplify the task:
A charge is a structure with coordinates (as on the screen).
The electric field strength at a point is a vector that we express by the projections and the function that calculates them (it was here that I got my error):
My idea is simple - I will create a two-dimensional array of stress vectors. At each point of the screen, the intensity will be equal to the sum of the vectors of the Coulomb forces. It sounds abstruse, but I could not formulate otherwise. Simply said, the code will be like this (you read it, but do not write it yet in your project):
If we get into a charge, then I miss the calculation of the tension at this point (for it is impossible to divide by zero). So on the screen you should see a black dot - charge.
Now that we have created the infrastructure, let's code under CUDA. First, create the necessary host and device variables and release them!
We will need the following variables:
Create:
We initialize the charges simply. I do not reset the random number generator to get the same picture. If you want a random field each time, you can add a call to
Remember the commented out line rendering screen? Now you can uncomment it:
Now we will create a function that we will call in each stream to render each pixel on the screen. This function will do the following: it will calculate the field strength value, and call another function to match some color to a point.
To call the core ... and yet everything is clear:
Now add some code to the
Often people skip the article because the conclusion is important. I have nothing to say here, except how to publish a picture that I did. A link to an almost empty repository can be found here .

In principle, there is much to develop - for example, you can add an animation showing how the field changes as charges move. But again, if this is interesting.
How often they write on Habré:
Back in the days of Turbo Pascal and Borland C 5.02, I was interested in the process of simulating simple physical phenomena of nature, be it gravitational forces or Coulomb interaction. Unfortunately, the power of a single processor with several hundred MHz was not enough for simple mathematical operations, of which there were a lot of them.
Although I am not a pogrommist, I once wanted to recall a distant childhood, and learn some of the basics of JavaScript, and I somehow modeled the gravitational interaction of any reasonable number of material points. So, for example, the particle below revolves around the "sun" using the Newtonian law:
If it will be interesting for you, and I will not leave enthusiasm, then I will describe to you the creation of such a demo, so that you can write your evil birds in a vacuum.
')
So, stop nostalgic, let's
To begin with, create a project from the Nsight template and connect the freeglut to it using the libraries GLU, GL, glut . This will allow us to display the resulting vector field, which we calculate. The approximate structure of our file with the
main function will be as follows: #include <stdio.h> #include <stdlib.h> int main(int argc, char** argv) { // Initialize freeglut // ... // Initialize Host and Device variables // ... // Launch Kernel to render the image // Display Image // Free resources return 0; } To begin with, everything looks simple. Let's first display the window of the size we need, and then render a black screen. By the way, I will tell you the obvious thing: if any function is unfamiliar to you, just google it .
Window initialization
Since when I conceived the application, I did not plan to dynamically resize the window, I decided to specify it declaratively using global constants:
const int width = 1280; const int height = 720; Oh yes! Do not judge strictly for mixing styles C ++ and C99. Some things, such as overload, I sometimes find useful, but I did not refuse malloc to at least somehow follow the style of applications with CUDA.
The window display itself, the Escape key processing and the simple render can be done with the following code:
#include <GL/freeglut.h> #include <GL/gl.h> #include <GL/glext.h> // ... void key(unsigned char key, int x, int y) { switch (key) { case 27: printf("Exit application\n"); glutLeaveMainLoop(); break; } } void draw(void) { glClearColor(0.0, 0.0, 0.0, 1.0); glClear(GL_COLOR_BUFFER_BIT); // glDrawPixels(width, height, GL_RGBA, GL_UNSIGNED_BYTE, screen); glFlush(); } // ... // Initialize freeglut glutInit(&argc, argv); glutInitDisplayMode(GLUT_SINGLE | GLUT_RGBA); glutInitWindowSize(width, height); glutCreateWindow("Electric field"); glutDisplayFunc(draw); glutKeyboardFunc(key); glutSetOption(GLUT_ACTION_ON_WINDOW_CLOSE, GLUT_ACTION_CONTINUE_EXECUTION); // ... // Display Image glutMainLoop(); When you run this code, you will not see anything except the black screen. So I will omit the screenshot here. Pay attention to the following points:
glutLeaveMainLoop- when Escape is pressed, freeglut allows you to interrupt the main loop so that we can free up application resources. If you want, you can useatexit;glDrawPixels- later I will create a buffer fromunsigned byte, where I will store all the pixels (their colors) and then display them in the window;glutSetOptionis to allow me to continue executing code inmainto clear resources in the form of dynamic memory.
Splitting calculation into blocks and threads
Pampering with examples, I was able to figure out for myself what such a thing as a block and a flow represents, and what to do with their dimension. In principle, if we omit the technical details, the block is a cell in which there are a certain number of flows. When a whole grid of blocks is calculated, at some point in time, each block fires its streams, waits for them to complete, and transfers control to another block. So, for example, you can pile up blocks in a one-dimensional strip, or in a two-dimensional grid.
The streams, in turn, can also be located in a block in the form of a one-dimensional band, or a two-dimensional table. By the way, variants with three dimensions are possible, but I will miss them, since they do not yet fit into my task.
I can break the screen into large squares (blocks), inside which the pixels will be rendered as a separate stream. Such a task is the optimal use of a graphics card, but to break the screen into blocks, you have to apply simple arithmetic - I find out the number of flows allowed for me within the block, and then I divide the window size by the number of flows horizontally and vertically.
To find out the number of threads inside a block, we use the
cudaGetDeviceProperties function: int threadsCount(void) { int deviceCount = 0; cudaGetDeviceCount(&deviceCount); if (deviceCount <= 0) { printf("No CUDA devices\n"); exit(-1); } cudaDeviceProp properties; cudaGetDeviceProperties(&properties, 0); return properties.maxThreadsPerBlock; } My map returns the number 1024. Unfortunately, I cannot use all the threads, because in debug mode, when dividing the
float numbers, I get the error cudaErrorLaunchOutOfResources . I couldn’t find out why I didn’t have enough resources (or registers, as the Internet writes), so the only three solutions I could find were reducing the number of threads per block, using the release mode when compiling, using the maxrregcount option with any number Above zero.If you have read my article up to this point, then I am glad that it is not for nothing that I sit at night in front of the computer. And if you know the answer, how to find out exactly what was my mistake, and let me know it, then I will be doubly glad.
Now we will break our field into blocks and streams:
void setupGrid(dim3* blocks, dim3* threads, int maxThreads) { threads->x = 32; threads->y = maxThreads / threads->x - 2; // to avoid cudaErrorLaunchOutOfResources error blocks->x = (width + threads->x - 1) / threads->x; blocks->y = (height + threads->y - 1) / threads->y; } // ... // Initialize Host dim3 blocks, threads; setupGrid(&blocks, &threads, threadsCount()); printf("Debug: blocks(%d, %d), threads(%d, %d)\nCalculated Resolution: %dx %d\n", blocks.x, blocks.y, threads.x, threads.y, blocks.x * threads.x, blocks.y * threads.y); The result will be as follows (I deliberately increased the number of blocks by one in cases where the screen size is not a multiple of the number of streams):
Debug: blocks(40, 24), threads(32, 30) Calculated Resolution: 1280 x 720 Theory and practice
Charges, distances, pendants and odds - that sounds good. But when it comes to modeling, here we can’t use super-small values, because they can disappear in the calculation process. Therefore, we simplify the task:
A charge is a structure with coordinates (as on the screen).
struct charge { int x, y, q; }; The electric field strength at a point is a vector that we express by the projections and the function that calculates them (it was here that I got my error):
const float k = 50.0f; const float minDistance = 0.9f; // not to divide by zero const float maxForce = 1e7f; struct force { float fx, fy; __device__ force() : fx(0.0f), fy(0.0f) { } __device__ force(int fx, int fy) : fx(fx), fy(fy) { } __device__ float length2() const { return (fx * fx + fy * fy); } __device__ float length() const { return sqrtf(length2()); } __device__ void calculate(const charge& q, int probe_x, int probe_y) { // F(1->2) = k * q1 * q2 / r(1->2)^2 * vec_r(1->2) / abs(vec_r(1->2)) // e = vec_F / q2 fx = probe_x - qx; fy = probe_y - qy; float l = length(); if (l <= minDistance) { return; } float e = k * qq / (l * l * l); if (e > maxForce) { fx = fy = maxForce; } else { fx *= e; fy *= e; } } __device__ force operator +(const force& f) const { return force(fx + f.fx, fy + f.fy); } __device__ force operator -(const force& f) const { return force(fx - f.fx, fy - f.fy); } __device__ force& operator +=(const force& f) { fx += f.fx; fy += f.fy; return *this; } __device__ force& operator -=(const force& f) { fx -= f.fx; fy -= f.fy; return *this; } }; My idea is simple - I will create a two-dimensional array of stress vectors. At each point of the screen, the intensity will be equal to the sum of the vectors of the Coulomb forces. It sounds abstruse, but I could not formulate otherwise. Simply said, the code will be like this (you read it, but do not write it yet in your project):
force temp_f; for (int i = 0; i < chargeCount; i++) { temp_f.calculate(charges[i], x, y); *f += temp_f; } If we get into a charge, then I miss the calculation of the tension at this point (for it is impossible to divide by zero). So on the screen you should see a black dot - charge.
Now that we have created the infrastructure, let's code under CUDA. First, create the necessary host and device variables and release them!
Create and release resources.
We will need the following variables:
- screen - host - color pixels;
- screen - the device - they are the same;
- Charges - device - coordinates and magnitudes of charges in the device’s permanent memory.
Create:
uchar4* screen = NULL; // ... screen = (uchar4*) malloc(width * height * sizeof(uchar4)); memset(screen, 0, width * height * sizeof(uchar4)); uchar4 *dev_screen = NULL; cudaMalloc((void**) &dev_screen, width * height * sizeof(uchar4)); cudaMemset(dev_screen, 0, width * height * sizeof(uchar4)); // ... // Free resources free(screen); screen = NULL; cudaFree(dev_screen); dev_screen = NULL; We initialize the charges simply. I do not reset the random number generator to get the same picture. If you want a random field each time, you can add a call to
srand : const int chargeCount = 10; __constant__ charge dev_charges[chargeCount]; const int maxCharge = 1000; const int minCharge = -1000; // ... void prepareCharges(void) { charge* charges = (charge*) malloc(chargeCount * sizeof(charge)); for (int i = 0; i < chargeCount; i++) { charges[i].x = rand() % width; charges[i].y = rand() % height; charges[i].q = rand() % (maxCharge - minCharge) + minCharge; printf("Debug: Charge #%d (%d, %d, %d)\n", i, charges[i].x, charges[i].y, charges[i].q); } cudaMemcpyToSymbol(dev_charges, charges, chargeCount * sizeof(charge)); } // ... prepareCharges(); Remember the commented out line rendering screen? Now you can uncomment it:
glDrawPixels(width, height, GL_RGBA, GL_UNSIGNED_BYTE, screen); Create a kernel
Now we will create a function that we will call in each stream to render each pixel on the screen. This function will do the following: it will calculate the field strength value, and call another function to match some color to a point.
__device__ uchar4 getColor(const force& f) { uchar4 color; color.x = color.y = color.z = color.w = 0; float l = f.length(); color.x = (l > maxLengthForColor ? 255 : l * 256 / maxLengthForColor); return color; } __global__ void renderFrame(uchar4* screen) { // build the field and render the frame } To call the core ... and yet everything is clear:
// Launch Kernel to render the image renderFrame<<<blocks, threads>>>(dev_screen); cudaMemcpy(screen, dev_screen, width * height * sizeof(uchar4), cudaMemcpyDeviceToHost); Now add some code to the
renderFrame and get what we need: __global__ void renderFrame(uchar4* screen) { int x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y; force f, temp_f; for (int i = 0; i < chargeCount; i++) { temp_f.calculate(dev_charges[i], x, y); f += temp_f; } screen[x + y * width] = getColor(f); } Conclusion
Often people skip the article because the conclusion is important. I have nothing to say here, except how to publish a picture that I did. A link to an almost empty repository can be found here .
In principle, there is much to develop - for example, you can add an animation showing how the field changes as charges move. But again, if this is interesting.
Source: https://habr.com/ru/post/164499/
All Articles