Introduction to the development of WinRT applications in HTML / JavaScript. From template to data application
With this article we are opening a series of materials on the basics of developing WinRT applications on HTML / JS for Windows 8. We will consistently go from the starting almost empty template to the full-fledged application with the server part and live tiles.
The first part is devoted to creating a simple version of an application that reads external data through RSS feeds based on a standard template. The result should be a working prototype of the application that can display news from several RSS feeds and display them on three types of pages: hub (first page), group and details.
Open Visual Studio 2012, select create a new project ( File -> New -> Project ... ). Next, in the templates, select the project in JavaScript -> Windows Store . Indicate that you will use the Grid App template.
')
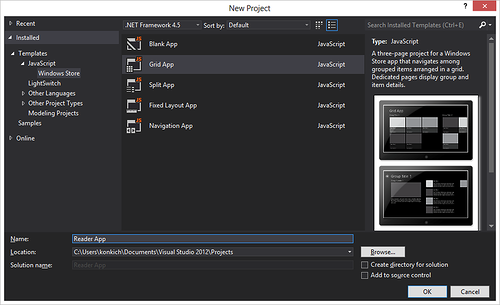
Enter any project name, for example, Reader App .
Study the project structure:
Also, by default, the WinJS library is included in the project, which contains style sets for dark and light themes and auxiliary functions and objects in JavaScript.
Try running the application by pressing F5 , the green arrow or choosing Debug -> Start Debugging .

Examine the operation of the application:
Return to Visual Studio and stop debugging ( Shift + F5 , red square, or select Debug -> Stop Debugging from the menu).
Open the js \ data.js file . It announces several important functions and objects that we will also use.
First of all it is necessary to get rid of the lines of the code generating examples of data. To do this, delete the following lines:
If you start the application, it will continue to work, only there will be no data in it. Stop debugging and return to the data.js file. Let's briefly go through its structure so that further actions are clear:
A list is created that will be used to link the data to the display. In it, we will enter those blocks of information that we want to display.
Based on the list, a grouped collection is created, and when it is created using special functions, it is indicated how to divide the elements of the collection into separate groups.
Through the define function in the WinJS library (Namespace), a global Data object is written, which will be accessible from other parts of the program for working with our data. Inside the object, there are references to the grouped collection, the list of groups inside it, and a number of functions described in the data.js file used to work with the collection and retrieve data.
The remaining 4 functions ( getItemReference , getItemsFromGroup , resolveGroupReference, and resolveItemReference ) are used to compare objects, retrieve subsets of items belonging to one group, define groups by key and item by a set of unique identifiers.
Now is the time to start adding our own data. We will use external RSS feeds as sources.
Go back to the beginning of the file and after the line “use strict” describe the blogs from which you will display information:
For the description of each blog (content group), we specify:
To turn links into data on a computer, information on them must be downloaded. To do this, after the line var list = new WinJS.Binding.List (); Add a new function getBlogPosts , which will just be engaged in the download:
In this function, we loop through all the blogs, create a asynchronous Promise wrapper around an XMLHttpRequest request for each link through the WinJS.xhr function, and after receiving the result (then), we transfer the resulting response to the processRSSFeed function, which we describe below.
To process the stream, add another function to the bottom — processRSSFeed :
In this function, we use the fact that we have an XML file with a known structure (RSS 2.0), which can be navigated using the DOM model, in particular, the querySelector function, which can be used to pull out the necessary data from the received document.
We convert the resulting text value of the latest update date into the required format using the globalization functions available through the WinRT API.
At the end, we pass the document for further processing to the getItemsFromRSSFeed function, which selects individual posts and puts them into the posts collection.
Add the following function below:
In this function, we loop through all posts in the received stream, select the required fields from the XML description (title, publication date, content, etc.), and then collect the necessary information into one object ( postItem ), which we add to list of posts.
Pay attention to the formatting of dates and the binding of each post to the corresponding group. Also note that for increased security, we retrieve the received post content to a static form using the toStaticHTML function.
Add the following line below to start reading blogs:
Run the application for debugging:

As you can see, it already uses our new data, however, there are several “problem” areas that need to be corrected:
We will deal with these tasks in the following articles.
The first part is devoted to creating a simple version of an application that reads external data through RSS feeds based on a standard template. The result should be a working prototype of the application that can display news from several RSS feeds and display them on three types of pages: hub (first page), group and details.
Creating an application from a template
Open Visual Studio 2012, select create a new project ( File -> New -> Project ... ). Next, in the templates, select the project in JavaScript -> Windows Store . Indicate that you will use the Grid App template.
')
Enter any project name, for example, Reader App .
Study the project structure:
- package.appxmanifest - application manifest that describes key settings, used features, application name, tiles, and other parameters;
- default.html - the formal start page of the application;
- pages \ groupedItems - folder with html-, js- and css-files for the page of the content groups (loaded into the start page);
- pages \ groupDetail - folder with html-, js- and css-files for the page of displaying a newsgroup (entries in the rss-stream) corresponding to one stream;
- pages \ itemDetail - a folder with html-, js- and css-files for the page for displaying each news item separately;
- js \ data.js - a js-file describing work with data (contains in-box demonstration data);
- js \ default.js - describes the events required to initialize the application;
- js \ navigator.js - describes the logic of transitions between pages and the necessary events and objects for this;
- images \ logo.png - image used for square tile;
- images \ smalllogo.png - image used when listing an application in the operating system, for example, when searching or selecting applications for search or sharing;
- images \ splashscreen.png - boot image shown when opening an application;
- images \ storelogo.png - image used in the application store interface (Windows Store).
Also, by default, the WinJS library is included in the project, which contains style sets for dark and light themes and auxiliary functions and objects in JavaScript.
Try running the application by pressing F5 , the green arrow or choosing Debug -> Start Debugging .
Examine the operation of the application:
- Try clicking on a single gray tile or group title.
- Try clicking on the back button in the internal pages.
- Try to transfer the application to Snapped-mode.
Return to Visual Studio and stop debugging ( Shift + F5 , red square, or select Debug -> Stop Debugging from the menu).
Replacing data sources
Open the js \ data.js file . It announces several important functions and objects that we will also use.
First of all it is necessary to get rid of the lines of the code generating examples of data. To do this, delete the following lines:
- Insert data into the list:
// You can add data from asynchronous sources whenever it becomes available. generateSampleData().forEach(function (item) { list.push(item); }); - Generating sample data:
// Returns an array of sample data that can be added to the application's // data list. function generateSampleData() { var itemContent = "<p>Curabitur class … "; var itemDescription = "Item Description: Pellente…"; var groupDescription = "Group Description: Lorem …"; … return sampleItems; }
If you start the application, it will continue to work, only there will be no data in it. Stop debugging and return to the data.js file. Let's briefly go through its structure so that further actions are clear:
var list = new WinJS.Binding.List(); A list is created that will be used to link the data to the display. In it, we will enter those blocks of information that we want to display.
var groupedItems = list.createGrouped( function groupKeySelector(item) { return item.group.key; }, function groupDataSelector(item) { return item.group; } ); Based on the list, a grouped collection is created, and when it is created using special functions, it is indicated how to divide the elements of the collection into separate groups.
WinJS.Namespace.define("Data", { items: groupedItems, groups: groupedItems.groups, getItemReference: getItemReference, getItemsFromGroup: getItemsFromGroup, resolveGroupReference: resolveGroupReference, resolveItemReference: resolveItemReference }); Through the define function in the WinJS library (Namespace), a global Data object is written, which will be accessible from other parts of the program for working with our data. Inside the object, there are references to the grouped collection, the list of groups inside it, and a number of functions described in the data.js file used to work with the collection and retrieve data.
The remaining 4 functions ( getItemReference , getItemsFromGroup , resolveGroupReference, and resolveItemReference ) are used to compare objects, retrieve subsets of items belonging to one group, define groups by key and item by a set of unique identifiers.
Now is the time to start adding our own data. We will use external RSS feeds as sources.
Important : in this article, in order to simplify the code, we will use only RSS feeds for data retrieval, however, adding support for Atom feeds should not be difficult, since they have a similar structure and the key difference will be in addressing the desired data fields.
Go back to the beginning of the file and after the line “use strict” describe the blogs from which you will display information:
var blogs = [ { key: "ABlogging", url: "http://blogs.windows.com/windows/b/bloggingwindows/rss.aspx", title: 'Blogging Windows', rsstitle: 'tbd', updated: 'tbd', dataPromise: null }, { key: "BExperience", url: 'http://blogs.windows.com/windows/b/windowsexperience/rss.aspx', title: 'Windows Experience', rsstitle: 'tbd', updated: 'tbd', dataPromise: null }, { key: "CExtreme", url: 'http://blogs.windows.com/windows/b/extremewindows/rss.aspx', title: 'Extreme Windows', rsstitle: 'tbd', updated: 'tbd', dataPromise: null }]; For the description of each blog (content group), we specify:
- key - key (since the sorting of groups will be by key, we also added Latin letters at the beginning of the group for an explicit sorting task - in a real project this can be done in a more elegant way),
- link to the RSS feed - url ,
- stream title - title ,
- several stubs:
- The real name of the blog is rsstitle ,
- update date ( updated )
- pointer to dataPromise - “promise” to load this stream and process it.
To turn links into data on a computer, information on them must be downloaded. To do this, after the line var list = new WinJS.Binding.List (); Add a new function getBlogPosts , which will just be engaged in the download:
function getBlogPosts(postsList) { blogs.forEach(function (feed) { // Promise feed.dataPromise = WinJS.xhr( { url: feed.url } ).then( function (response) { if (response) { var syndicationXML = response.responseXML || (new DOMParser()).parseFromString(response.responseText, "text/xml"); processRSSFeed(syndicationXML, feed, postsList); } } ); }); return postsList; } In this function, we loop through all the blogs, create a asynchronous Promise wrapper around an XMLHttpRequest request for each link through the WinJS.xhr function, and after receiving the result (then), we transfer the resulting response to the processRSSFeed function, which we describe below.
Note : for the blogs we use there is no need for additional verification that we received a response in the form of XML (the presence of responseXML), however, in general, this is incorrect: some blogs due to incorrect settings of the server / engine give the RSS feed as text content, which needs to be further processed if we want to work with it as with an XML file.
To process the stream, add another function to the bottom — processRSSFeed :
function processRSSFeed(articleSyndication, feed, postsList) { // feed.rsstitle = articleSyndication.querySelector("rss > channel > title").textContent; // var published = articleSyndication.querySelector("rss > channel > item > pubDate").textContent; // var date = new Date(published); var dateFmt = new Windows.Globalization.DateTimeFormatting.DateTimeFormatter( "day month.abbreviated year.full"); var blogDate = dateFmt.format(date); feed.updated = ": " + blogDate; // getItemsFromRSSFeed(articleSyndication, feed, postsList); } In this function, we use the fact that we have an XML file with a known structure (RSS 2.0), which can be navigated using the DOM model, in particular, the querySelector function, which can be used to pull out the necessary data from the received document.
We convert the resulting text value of the latest update date into the required format using the globalization functions available through the WinRT API.
At the end, we pass the document for further processing to the getItemsFromRSSFeed function, which selects individual posts and puts them into the posts collection.
Add the following function below:
function getItemsFromRSSFeed(articleSyndication, feed, postsList) { var posts = articleSyndication.querySelectorAll("item"); // var length = posts.length; for (var postIndex = 0; postIndex < length; postIndex++) { var post = posts[postIndex]; // var postPublished = post.querySelector("pubDate").textContent; var postDate = new Date(postPublished); var monthFmt = new Windows.Globalization.DateTimeFormatting.DateTimeFormatter("month.abbreviated"); var dayFmt = new Windows.Globalization.DateTimeFormatting.DateTimeFormatter("day"); var yearFmt = new Windows.Globalization.DateTimeFormatting.DateTimeFormatter("year.full"); var timeFmt = new Windows.Globalization.DateTimeFormatting.DateTimeFormatter("shorttime"); var postContent = toStaticHTML(post.querySelector("description").textContent); var postItem = { index: postIndex, group: feed, // title: post.querySelector("title").textContent, // postDate: postDate, month: monthFmt.format(postDate).toUpperCase(), day: dayFmt.format(postDate), year: yearFmt.format(postDate), time: timeFmt.format(postDate), // content: postContent, // link: post.querySelector("link").textContent }; postsList.push(postItem); } } In this function, we loop through all posts in the received stream, select the required fields from the XML description (title, publication date, content, etc.), and then collect the necessary information into one object ( postItem ), which we add to list of posts.
Pay attention to the formatting of dates and the binding of each post to the corresponding group. Also note that for increased security, we retrieve the received post content to a static form using the toStaticHTML function.
Note : in general, working with RSS feeds from uncontrolled sources needs to be carefully monitored (and investigated) the data obtained. In practice, part of the data on the required fields may be absent, so before extracting text content (textContent), you must make sure that the previous operation returned a non-null value. In some cases, the full content of the post may be hidden behind elements of encoded or full-text or be completely absent. There are also cases when the server gives the date in the wrong format, with the result that the standard parser throws an exception.
Add the following line below to start reading blogs:
list = getBlogPosts(list); Run the application for debugging:
As you can see, it already uses our new data, however, there are several “problem” areas that need to be corrected:
- no pictures
- Strange "undefined" is displayed in separate lines,
- the main page displays the entire list from the stream at once, but I want to limit it to several entries.
We will deal with these tasks in the following articles.
Continuation
Source: https://habr.com/ru/post/163443/
All Articles