High Frequency Trading (HFT) using FPGA
This article talks about the development of a highly specialized hardware device for HFT purposes. His specialization is aimed at achieving the lowest possible time delays for processing market data and, consequently, at reducing the round-trip time when executing transactions. The implementation described in this paper parses Ethernet, IP, and UDP packets, as well as the FAST protocol, which is most common in the transmission of market information. For such purposes, a custom microcode engine was developed, with support for the instruction set and a compiler, thereby achieving support for a wide range of protocols used in trading. The final system was implemented in RTL code and executed on the FPGA. This approach shows the advantage of 4 times, compared with fully software solutions.
High-frequency trading (HFT) has received much attention recently, and it is becoming a major player in the financial markets. The term HFT is understood as a set of techniques for trading stocks and derivatives, when a large flow of orders is sent to the market with a round trip less than a millisecond [1]. The goal of the high frequencies is to come to the end of the day without any positions of securities available, and to get a profit from your strategies by buying and selling stocks at a very high speed. Studies show that HFT traders hold an average share of just 22 seconds [2]. Aite Group claims that HFT has a significant impact on the market, more than 50% of transactions in US stocks were completely HFT in 2010, while the growth in 2009 alone was 70% [3].
HFT traders use several strategy options, such as liquidity strategy, statistical arbitrage strategy, and liquidity search strategy [2]. In a strategy to ensure liquidity, the high frequency traders are trying to make money on a bid-ask spread, which reflects the difference that sellers are willing to sell and buyers to buy. High volatility and a wide bid-ask spread can turn into a profit for the HFT trader, and at the same time it becomes a liquidity provider and narrows the bid-ask spread, as if playing the role of a market maker. Liquidity and a small ask-bid spread are important because they reduce trading costs and allow you to more accurately determine the value of an asset [4]. Traders who use arbitrage strategies use a correlation between the prices of derivatives and their underlying assets [5]. Liquidity strategies explore the market in search of large bids by sending small orders that help locate large hidden bids. All strategies are united by one thing; they require uncompromisingly low time delays to work, since only the fastest HFT companies are able to take advantage of the opportunities arising in the market.
Electronic stock trading occurs by sending requests in electronic form to the exchange. Purchase and sale applications are then matched on the exchange and the transaction is executed. Exhibited bids are visible to all bidders through the so-called feeds. A feed is a compressed or uncompressed data stream, delivered in real time by some independent organization, such as the Options Price Reporting Authority (OPRA). The feed contains financial information on stocks and is transmitted via multicast to market participants via standardized protocols, mainly via Ethernet via UDP. The standard market data delivery protocol is the Financial Information Exchange (FIX) Adapted for Streaming (FAST), which is used on most exchanges [18].
')
In order to achieve a minimum delay time, the HFT engine must be optimized at all levels. To reduce the delay time for transmission over the network, collocation is used when the HFT server is installed next to the exchange gateway. The data feed should be distributed with minimal delay to the HFT servers. Efficient processing of UDP and FAST packets is also necessary. Finally, the decision to create an application and its transfer should be carried out with the lowest possible delay. To achieve these goals, a new HFT engine was developed, implemented on the FPGA board. Through the use of FPGA, it became possible to remove the load on processing UDP and FAST from the central processor and transfer it to specially optimized blocks of the board. In the presented system, the entire processing cycle is implemented at the hardware level, with the exception of trading decisions, including an extremely flexible microcode engine for processing FAST messages. The approach gives a significant reduction in delays by more than 70% compared to software solutions and at the same time makes it much easier to modify or add processing of new protocols than integrated application-specific integrated circuits.
The current section talks about the basic concepts and implementation of the exchange infrastructure. In addition, the basic properties of the FAST protocol will be discussed to determine the hardware implementation requirements.
A typical trading infrastructure consists of several components controlled by various participants. This is the exchange, the feed provider and market participants, as shown in Figure 1. The engine for matching applications (the match), the data center router, and the gateway are controlled by the exchange. The feed mechanism is provided by another organization. A router for access by market participants is the property of these participants, in this case HFT firms.

The procedure is as follows:
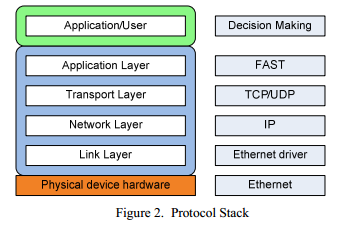
E-commerce has to involve several layers of the network stack. An illustration of these layers is shown in Figure 2.
The FAST protocol is used by the feed provider to transfer financial information to market participants. To reduce the load, several FAST messages can be combined in one UDP packet. These messages do not use framing and do not contain information about the size of the message. Instead, each type of message is described in a template that must be known to properly process the data stream. Most feed providers declare their own implementation of the protocol by supplying their own independent specifications for templates. Processing must be carried out with due care, as an error in one message will result in the loss of the entire UDP packet. Patterns describe a set of fields, sequences, and groups. Groups are a set of fields where each field can be contained only once, and sequences can contain sets of repeating fields.

Each message begins with a presence map (PMAP) and a template identifier (TID) as shown in Figure 3. PMAP is a mask, and indicates which of the declared fields, groups, and sequences are contained in the current thread. Fields can be either mandatory or optional, and can also contain an operator associated with them. Moreover, this fact depends on the presence attribute, as well as on the bit flag in PMAP, if an operator is attached to the field. This adds additional complexity, since it is not known in advance whether PMAP processing is required or not.
The TID is used to identify the template that will be required to process the message. Patterns are described in XML, for example,
In this example, the TID is 1, and the pattern consists of two fields and one group. The field type can be a string, an integer, a fractional number, 32 or 64 bit, as well as a decimal type, where 32 bits will be allocated to the exponent and 64 bits per mantissa.
To reduce the load on the network, only those bytes are transmitted that contain explicit values. For example, only one byte will be transmitted for a 64-bit integer with the value '1', despite the fact that in memory this number takes 64 bits.
Only the first seven bits of each transmitted byte are used to record payload data, the eighth bit is used as a stop bit and serves to separate the fields. The stop bit must be deleted, and the remaining 7 bits must be combined if the field consists of more than one byte.
Suppose the following binary stream was received:
1 0000111 0 0101010 1 0111111
Based on the underlined stop bits, it follows that these three bytes contain two fields. To get the value of the first field, replace the eighth bit with the value 0. The result will be:
Binary value: 0 0111111
Hexadecimal value: 0x63
The second field consists of 2 bytes. To get the real value, it is required to replace the eighth bit with 0 in each byte and combine the remaining parts. The result will be:
Binary value: 00 000011 10101010
Hexadecimal value: 0x03 0xAA
In fact, it is still more complicated, for example, the fields must be processed differently, depending on their presence attribute. An optional integer should be decremented by one, but not a mandatory one.
Operators prescribe the execution of an action with a field after it has been received, or if the field is not represented at all in the stream. The available operators are constant, copy, default, delta, and increment. For example, constant, says that the field always contains the same value, and, therefore, is never passed in the feed.
The FAST specification also provides for the declaration of a byte array in which no stop bits are used, and all eight bits in a byte are used to transmit payload data. This array in turn contains a field in which the total number of bytes is specified. This part of the specification was not implemented due to the high complexity and the fact that it is not used on the target exchange, in this case in Frankfurt.
Recently, a lot of literature has appeared on the topic, but still, most of the work is done inside organizations and is not published. A very good overview of HFT optimization is given in [6]. Moreover, a system is provided to optimize the processing of the ORPA FAST feed using the Myrinet MX device. The multithreaded “faster FAST” engine, for use on multicore systems, is presented in [7]. Although both systems are focused on optimizing FAST processing, the approach from this article is the first one that uses FPGA. Morris [8] describes a HFT system that uses FPGA to optimize UDP / IP processing, similar to [9]. Other related topics are the use of FPGA for algorithmic trading techniques based on the Monte Carlo method [10], [11], [12]. Sadoghi [13] uses FPGA-based technologies for efficient event processing in algorithmic trading. Mittal introduces a software FAST decoder, which runs on a PowerPC 405, which is embedded in several FPGA boards [13]. Lastly, Tandon published the work “A Programmable Architecture for Real-time Derivative Trading” [14].
Three different approaches are proposed for reducing delay times in HFT applications. The first is UDP optimization, the second is the hardware implementation of FAST message processing, and the third is the use of parallel hardware structures for simultaneous processing of several threads.
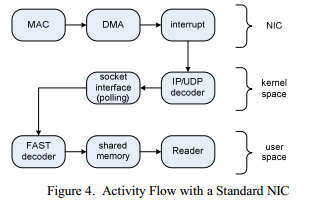
In normal systems, UDP data comes to the network interface card (NIC) as raw ETH packets. The NIC then sends the packets to the OS kernel, which checks the checksum and processes the packet. The execution flow for this process is shown in Figure 4. This approach shows high time delays, due to the fact that interrupts are used to inform the OS about incoming packets, as well as due to the introduction of another additional layer that serves to transfer data to the user space — sockets . Moreover, the OS kernel may be occupied by other activities, which also adversely affects the processing times. A detailed list of the various time delays that appear during TCP / IP processing can be found in [15]. In the case of UDP, the situation is very similar, since the difference with TCP begins to appear only at higher levels.
The first and most effective approach to reducing latency is bypassing the OS kernel and processing incoming packets in hardware, as shown in Figure 5. Consequently, the Address Resolution Protocol (ARP) will be required to correctly receive and send packets. ARP is used to match IP addresses with the participants' physical MAC addresses.
To obtain a multicast, you also need the support of the Internet Group Management Protocol (IGMP), which is required to connect and disconnect multicast groups. Other protocols that will require implementation are ETH, IP and UDP. All of these protocols are effectively implemented, with a focus on the lowest possible latency for ETH, IP, and UDP. The implementation of IGMP and ARP protocols is not critical to speed, since they do not participate in direct data transmission during trading. All checksums of the headers of the various protocols and the ETH CRC are calculated in parallel, while checking these checksums at the very last stage.

The checked package is then transmitted to the FAST processor or to the DMA engine, which is able to write raw data to the address space of the trading software. An example of when FAST processing is done on an FPGA, and then transmitted through the DMA engine to the user application, is shown in Figure 6.

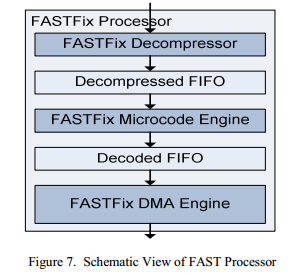
Due to the high complexity of the FAST decoder is divided into three independent parts. As shown in Figure 7, all three parts are decoupled through FIFO buffers to compensate for different and sometimes unforeseen delays in each of the modules. Since decompression increases the amount of data to be processed, the FAST processor can operate at a higher frequency than the ETH core, which will increase the throughput and compensate for the high amount of data.
The FAST protocol is strictly sequential, since the beginning of each field in the stream depends on the previous field. Even after the FAST decoder aligns the data, it will still not be possible to process the stream in parallel. These are protocol limitations.
Fortunately, exchanges deliver data to several feeds at once. Therefore, you can increase bandwidth and reduce delays by parallel processing of FAST feeds by the processor. Each FAST processor operates with a separate FAST thread. Throughput can be significantly increased due to this approach. Each FAST processor uses a schema of 5620 lookup tables.

To further reduce latency when nanoseconds count, the HyperTransport interface offered by AMD for Opetron processors is used. This technology allows for much shorter delays than PCI Express due to the fact that the FPGA is directly connected to the central processor, bypassing various intermediate buses [16]. This technology uses the HTX slot in AMD Opetron systems.
The device was implemented using synthesized constructs verilog RTL code and tested on an FPGA card based on Xilinx Virtex-4 FX100.
Figure 8 schematically illustrates the architecture of an HFT device. The one on the left is the HT core operating at 200 MHz. Next comes HTAX, connecting FAST processors, UDP, and RegisterFile with the HT core. This part works at a maximum frequency of 160 MHz. In the right part, the infrastructure for processing network packets connected to the Gigabit Ethernet MAC, which operates at 125 MHz, is shown in red. The entire architecture, including 4 FAST processors, uses 77 slices.
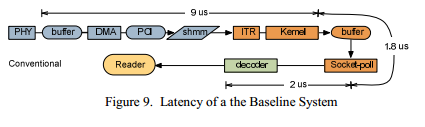
For the measurements, the recorded data supplied by the feed provider was sent to the standard server network card, located first, to determine the starting point for subsequent calculations. Figure 9 shows the message flow in a similar system. The measured delay for a NIC of 9 µs, for a kernel space of 1.8 µs and for a user space of 2 µs. The total delay is 12.8 µs.
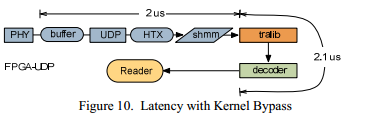
The same feed was then sent to the FPGA device. In the first experiment, only the passage of the feed through the nuclear space was removed, as shown in Figure 10. The measured delay in passing the network stack on the FPGA board is 2 μs, the delay in user space is 2.1 μs. Thus, the delay value has already decreased to 4.1 µs, which reduces the execution time by 62 percent, compared with the standard implementation.
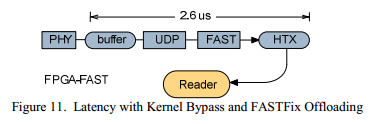
In the second experiment, the FAST processor was turned on, which allowed processing the messages in the hardware device and then transferring the result to the software address space, this process is shown in Figure 11. The measured delay value when both the network stack and FAST processing are delivered to the FPGA is 28 percent less and is only 2.6 µs. As a result, a reduction in the delay of 4 times, compared with the standard solution.
An implementation of a device aimed at optimizing HFT was shown, which can significantly reduce the amount of time required to receive and process trade information based on FAST. In particular, the delays were reduced four times, which significantly reduced the round-trip time for transactions.
The special nature of the FAST protocol, which does not allow its efficient processing on standard CPUs, makes it very attractive for implementation on FPGAs, with a significant reduction in time delays. The successful implementation of this approach was shown in this article.
[1] JA Brogaard, “High Frequency Trading,” 5th Annual Conference on Employment Law, 2010.
[2] M. Chlistalla, “High-frequency trading Better than its reputation ?,” Deutsche Bank research report, 2011.
[3] A. Group, 2009.
[4] KH Chung and Y. Kim, “Volatility, Market Structure, and the Bid-Ask Spread,” Asia-Pacific Journal of Financial Studies, vol. 38, Feb. 2009
[5] J. Chiu, D. Lukman, K. Modarresi, and A. Velayutham, “High frequency trading,” Stanford University Research Report, 2011.
[6] H. Subramoni, F. Petrini, V. Agarwal, and D. Pasetto, “Streaming, low-level communication,” International Symposium on Parallel & Distributed Processing, Workshops (IPDPSW), 2010.
[7] V. Agarwal, D. a Bader, L. Dan, L.-K. Liu, D. Pasetto, M. Perrone, and F. Petrini, “Faster FAST: multicore acceleration of streaming financial data,” Computer Science - Research and Development, vol. 23, May. 2009
[8] GW Morris, DB Thomas, and W. Luk, “FPGA Accelerated LowLatency Market Data Feed Processing,” 2009 17th IEEE Symposium on High Performance Interconnects, Aug. 2009
[9] F. Herrmann and G. Perin, “An UDP / IP Network Stack in FPGA,” Electronics, Circuits, and Systems (ICECS), 2009.
[10] GL Zhang, PHW Leong, CH Ho, KH Tsoi, CCC Cheung, D. Lee, RCC Cheung, and W. Luk, “IEEE International Conference on Field-Programmable Technology,” 2005.
[11] DB Thomas, “Acceleration of Financial Monte-Carlo Simulations using FPGAs,” Workshop on High Performance Computational Finance (WHPCF), 2010.
[12] N. a. Woods and T. VanCourt, “FPGA acceleration of quasi-Monte Carlo finance,” 2008 International Conference on Field Programmable Logic and Applications, 2008, pp. 335-340.
[13] M. Sadoghi, M. Labrecque, H. Singh, W. Shum, and H.-arno Jacobsen, “Efficient Event Processing for Reconfigurable Hardware for Algorithmic Trading,” Journal of Proceedings of the VLDB Endowment, 2010.
[14] S. Tandon, “A Programmable Architecture for Real-Time Derivative Trading,” Master Thesis, University of Edinburgh, 2003.
[15] S. Larsen and P. Sarangam, “Architectural Breakdown of the End-to-End Latency in a TCP / IP Network,” International Journal of Parallel Programming, Springer, 2009.
[16] D. Slogsnat, A. Giese, M. Nüssle, and U. Brüning, “An open-source HyperTransport core,” ACM Transactions on Reconfigurable Technology and Systems, vol. 1, Sep. 2008, pp. 1-21.
[17] G. Mittal, DC Zaretsky, P. Banerjee, “FPGA,“ International Symposium on Field Programmable Gate Arrays - FPGA09, 2009.
[18] FIX adapted for Streaming, www.fixprotocol.org/fast
Introduction
High-frequency trading (HFT) has received much attention recently, and it is becoming a major player in the financial markets. The term HFT is understood as a set of techniques for trading stocks and derivatives, when a large flow of orders is sent to the market with a round trip less than a millisecond [1]. The goal of the high frequencies is to come to the end of the day without any positions of securities available, and to get a profit from your strategies by buying and selling stocks at a very high speed. Studies show that HFT traders hold an average share of just 22 seconds [2]. Aite Group claims that HFT has a significant impact on the market, more than 50% of transactions in US stocks were completely HFT in 2010, while the growth in 2009 alone was 70% [3].
HFT traders use several strategy options, such as liquidity strategy, statistical arbitrage strategy, and liquidity search strategy [2]. In a strategy to ensure liquidity, the high frequency traders are trying to make money on a bid-ask spread, which reflects the difference that sellers are willing to sell and buyers to buy. High volatility and a wide bid-ask spread can turn into a profit for the HFT trader, and at the same time it becomes a liquidity provider and narrows the bid-ask spread, as if playing the role of a market maker. Liquidity and a small ask-bid spread are important because they reduce trading costs and allow you to more accurately determine the value of an asset [4]. Traders who use arbitrage strategies use a correlation between the prices of derivatives and their underlying assets [5]. Liquidity strategies explore the market in search of large bids by sending small orders that help locate large hidden bids. All strategies are united by one thing; they require uncompromisingly low time delays to work, since only the fastest HFT companies are able to take advantage of the opportunities arising in the market.
Electronic stock trading occurs by sending requests in electronic form to the exchange. Purchase and sale applications are then matched on the exchange and the transaction is executed. Exhibited bids are visible to all bidders through the so-called feeds. A feed is a compressed or uncompressed data stream, delivered in real time by some independent organization, such as the Options Price Reporting Authority (OPRA). The feed contains financial information on stocks and is transmitted via multicast to market participants via standardized protocols, mainly via Ethernet via UDP. The standard market data delivery protocol is the Financial Information Exchange (FIX) Adapted for Streaming (FAST), which is used on most exchanges [18].
')
In order to achieve a minimum delay time, the HFT engine must be optimized at all levels. To reduce the delay time for transmission over the network, collocation is used when the HFT server is installed next to the exchange gateway. The data feed should be distributed with minimal delay to the HFT servers. Efficient processing of UDP and FAST packets is also necessary. Finally, the decision to create an application and its transfer should be carried out with the lowest possible delay. To achieve these goals, a new HFT engine was developed, implemented on the FPGA board. Through the use of FPGA, it became possible to remove the load on processing UDP and FAST from the central processor and transfer it to specially optimized blocks of the board. In the presented system, the entire processing cycle is implemented at the hardware level, with the exception of trading decisions, including an extremely flexible microcode engine for processing FAST messages. The approach gives a significant reduction in delays by more than 70% compared to software solutions and at the same time makes it much easier to modify or add processing of new protocols than integrated application-specific integrated circuits.
Background
The current section talks about the basic concepts and implementation of the exchange infrastructure. In addition, the basic properties of the FAST protocol will be discussed to determine the hardware implementation requirements.
Trading Infrastructure
A typical trading infrastructure consists of several components controlled by various participants. This is the exchange, the feed provider and market participants, as shown in Figure 1. The engine for matching applications (the match), the data center router, and the gateway are controlled by the exchange. The feed mechanism is provided by another organization. A router for access by market participants is the property of these participants, in this case HFT firms.
The procedure is as follows:
- In the match engine a favorable opportunity is formed.
- The match engine sends a notification to the feed provider.
- The feed engine multicasts this information to all participants.
- The client assesses the situation and responds with an application.
- The gateway receives the request and sends it to the match engine.
- The match engine executes the first request received, and the transaction is considered to be completed.
Protocol stack
E-commerce has to involve several layers of the network stack. An illustration of these layers is shown in Figure 2.
- Ethernet (ETH) layer
The bottommost layer of the network stack. Provides basic functionality for sending packets over the network. Contains frame support and Cyclic Redundancy Check (CRC) to support data integrity. In addition to this, ETH provides identification of both participants using Media Access Control (MAC) addresses. - IP layer
IP is one level above ETH. The widely used protocol groups computers into logical groups and assigns each end node a unique address within such a group. It can also be used to send messages to many participants at once (multicast), and because of this it is used on the vast majority of trading platforms. - UDP layer
User Datagram Protocol (UDP) is used by software applications to send messages between participants. Allows the use of multiple recipients and senders on a single node and uses data integrity checks using checksums. - FAST
The FAST protocol was developed to transfer market data from the exchange to users using feeds. The protocol describes various fields and operators for identifying securities and their prices. An important aspect of this protocol is the possibility of data compression, to reduce the amount of data transferred, however, it introduces additional load on the processor. Feed processing is quite a bottleneck, and therefore bringing this functionality to an FPGA is a good idea. A more detailed description of the protocol will be provided in the following parts of the document. - Making trading decisions
Making trading decisions can be a very difficult and costly task, depending on the complexity of the algorithms. In essence, the decision-making process consists in comparing the specified parameters with the incoming data, using mathematical methods or statistics. A detailed analysis of such mechanisms is beyond the scope of this article. Due to the high complexity, making trading decisions is not made on the FPGA, but implemented by software.
FAST protocol basics
The FAST protocol is used by the feed provider to transfer financial information to market participants. To reduce the load, several FAST messages can be combined in one UDP packet. These messages do not use framing and do not contain information about the size of the message. Instead, each type of message is described in a template that must be known to properly process the data stream. Most feed providers declare their own implementation of the protocol by supplying their own independent specifications for templates. Processing must be carried out with due care, as an error in one message will result in the loss of the entire UDP packet. Patterns describe a set of fields, sequences, and groups. Groups are a set of fields where each field can be contained only once, and sequences can contain sets of repeating fields.
Each message begins with a presence map (PMAP) and a template identifier (TID) as shown in Figure 3. PMAP is a mask, and indicates which of the declared fields, groups, and sequences are contained in the current thread. Fields can be either mandatory or optional, and can also contain an operator associated with them. Moreover, this fact depends on the presence attribute, as well as on the bit flag in PMAP, if an operator is attached to the field. This adds additional complexity, since it is not known in advance whether PMAP processing is required or not.
The TID is used to identify the template that will be required to process the message. Patterns are described in XML, for example,
<template name="This_is_a_template" id="1"> <uInt32 name="first_field"/> <group name="some_group" presence="optional"> <sint64 name="second_field"/> </group> <string name="third_field" presence="optional"/> </template> In this example, the TID is 1, and the pattern consists of two fields and one group. The field type can be a string, an integer, a fractional number, 32 or 64 bit, as well as a decimal type, where 32 bits will be allocated to the exponent and 64 bits per mantissa.
To reduce the load on the network, only those bytes are transmitted that contain explicit values. For example, only one byte will be transmitted for a 64-bit integer with the value '1', despite the fact that in memory this number takes 64 bits.
Only the first seven bits of each transmitted byte are used to record payload data, the eighth bit is used as a stop bit and serves to separate the fields. The stop bit must be deleted, and the remaining 7 bits must be combined if the field consists of more than one byte.
Suppose the following binary stream was received:
1 0000111 0 0101010 1 0111111
Based on the underlined stop bits, it follows that these three bytes contain two fields. To get the value of the first field, replace the eighth bit with the value 0. The result will be:
Binary value: 0 0111111
Hexadecimal value: 0x63
The second field consists of 2 bytes. To get the real value, it is required to replace the eighth bit with 0 in each byte and combine the remaining parts. The result will be:
Binary value: 00 000011 10101010
Hexadecimal value: 0x03 0xAA
In fact, it is still more complicated, for example, the fields must be processed differently, depending on their presence attribute. An optional integer should be decremented by one, but not a mandatory one.
Operators prescribe the execution of an action with a field after it has been received, or if the field is not represented at all in the stream. The available operators are constant, copy, default, delta, and increment. For example, constant, says that the field always contains the same value, and, therefore, is never passed in the feed.
The FAST specification also provides for the declaration of a byte array in which no stop bits are used, and all eight bits in a byte are used to transmit payload data. This array in turn contains a field in which the total number of bytes is specified. This part of the specification was not implemented due to the high complexity and the fact that it is not used on the target exchange, in this case in Frankfurt.
Similar work
Recently, a lot of literature has appeared on the topic, but still, most of the work is done inside organizations and is not published. A very good overview of HFT optimization is given in [6]. Moreover, a system is provided to optimize the processing of the ORPA FAST feed using the Myrinet MX device. The multithreaded “faster FAST” engine, for use on multicore systems, is presented in [7]. Although both systems are focused on optimizing FAST processing, the approach from this article is the first one that uses FPGA. Morris [8] describes a HFT system that uses FPGA to optimize UDP / IP processing, similar to [9]. Other related topics are the use of FPGA for algorithmic trading techniques based on the Monte Carlo method [10], [11], [12]. Sadoghi [13] uses FPGA-based technologies for efficient event processing in algorithmic trading. Mittal introduces a software FAST decoder, which runs on a PowerPC 405, which is embedded in several FPGA boards [13]. Lastly, Tandon published the work “A Programmable Architecture for Real-time Derivative Trading” [14].
Implementation
Three different approaches are proposed for reducing delay times in HFT applications. The first is UDP optimization, the second is the hardware implementation of FAST message processing, and the third is the use of parallel hardware structures for simultaneous processing of several threads.
UDP optimization
In normal systems, UDP data comes to the network interface card (NIC) as raw ETH packets. The NIC then sends the packets to the OS kernel, which checks the checksum and processes the packet. The execution flow for this process is shown in Figure 4. This approach shows high time delays, due to the fact that interrupts are used to inform the OS about incoming packets, as well as due to the introduction of another additional layer that serves to transfer data to the user space — sockets . Moreover, the OS kernel may be occupied by other activities, which also adversely affects the processing times. A detailed list of the various time delays that appear during TCP / IP processing can be found in [15]. In the case of UDP, the situation is very similar, since the difference with TCP begins to appear only at higher levels.
The first and most effective approach to reducing latency is bypassing the OS kernel and processing incoming packets in hardware, as shown in Figure 5. Consequently, the Address Resolution Protocol (ARP) will be required to correctly receive and send packets. ARP is used to match IP addresses with the participants' physical MAC addresses.
To obtain a multicast, you also need the support of the Internet Group Management Protocol (IGMP), which is required to connect and disconnect multicast groups. Other protocols that will require implementation are ETH, IP and UDP. All of these protocols are effectively implemented, with a focus on the lowest possible latency for ETH, IP, and UDP. The implementation of IGMP and ARP protocols is not critical to speed, since they do not participate in direct data transmission during trading. All checksums of the headers of the various protocols and the ETH CRC are calculated in parallel, while checking these checksums at the very last stage.
The checked package is then transmitted to the FAST processor or to the DMA engine, which is able to write raw data to the address space of the trading software. An example of when FAST processing is done on an FPGA, and then transmitted through the DMA engine to the user application, is shown in Figure 6.
FAST hardware processing
Due to the high complexity of the FAST decoder is divided into three independent parts. As shown in Figure 7, all three parts are decoupled through FIFO buffers to compensate for different and sometimes unforeseen delays in each of the modules. Since decompression increases the amount of data to be processed, the FAST processor can operate at a higher frequency than the ETH core, which will increase the throughput and compensate for the high amount of data.
- FAST decompressor
FAST decompressor processes the stop bits and aligns each field with a length of 64 bits. This is done so that all fields have the same size, which simplifies processing in further steps. - FAST microcode engine
Since FAST messages vary greatly, depending on the template used, it was decided to use a microcode engine that would be flexible enough to be used with any variation of the FAST protocol. The use of partial reconfiguration, instead of the microcode engine, was rejected due to high reconfiguration time delays of a few milliseconds.
This engine starts the program, which is on the FPGA, with a separate procedure for each template when the device boots. The jump table contains pointers to the desired procedure, depending on the template ID, this ID is indicated at the beginning of each FAST message. All FAST message fields are processed by the corresponding subroutine. Depending on the subroutine, the contents of the field are either discarded or transferred to the next module for processing. The binary code for the microcode engine is implemented as an assembly language, using a simple object-oriented language (DSL), which was specifically designed for this purpose. The assembler code for the template that was presented in the example above will look like this: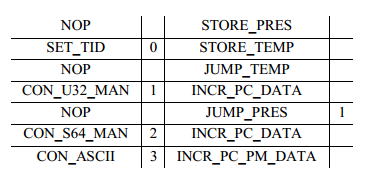
As you can see, the proposed domain-specific language contains four columns. The two left columns describe the data that should be processed in the specified step. The two right-hand points to the command to be executed by the microcode engine. In particular, the first column describes the field with its presence attribute, the second matches the field with a unique identifier that can be further processed by the software. The third column declares a specific control command that can increment the current pointer, jump commands, select data from the FIFO buffer, or check PMAP. The last column is used to indicate the purpose of the transition.
Using assembly language in conjunction with the microcode engine simplifies FPGA adaptation when changing templates, or even when switching to another stock exchange, without having to revise the architecture. This makes it much easier to work with FPGA for any changes to the protocol. - FAST DMA engine
To deliver the processed data to the trading software, the DMA engine was developed. Each field in different templates is marked with a unique identifier for its unambiguous definition in the trading software. The DMA engine transmits the received information to the ring buffer, which is located in the software address space. Each record consists of eight quadruple words, exactly the same size is equal to the size of the cache line in the x86 processor. Seven of these four words are used as the content of the fields, and the eighth contains seven identifiers for the fields presented in the second column of the table, as well as additional information on the status. The status information also contains an extra bit, which is inverted each time it writes to the ring buffer. Using this bit allows you to effectively determine when new data appears, without the need to overwrite the buffer.
This implementation allows to obtain the minimum possible level of time delays when using a constant polling buffer (polling). Polling shows much smaller delay times than interrupts. The main reason for the high delays when using interrupts is that you have to switch the execution context. However, the chosen approach leads to an increased load on the CPU and increased power consumption, but the low latencies outweigh these disadvantages.
Parallelism
The FAST protocol is strictly sequential, since the beginning of each field in the stream depends on the previous field. Even after the FAST decoder aligns the data, it will still not be possible to process the stream in parallel. These are protocol limitations.
Fortunately, exchanges deliver data to several feeds at once. Therefore, you can increase bandwidth and reduce delays by parallel processing of FAST feeds by the processor. Each FAST processor operates with a separate FAST thread. Throughput can be significantly increased due to this approach. Each FAST processor uses a schema of 5620 lookup tables.
Computer Interface
To further reduce latency when nanoseconds count, the HyperTransport interface offered by AMD for Opetron processors is used. This technology allows for much shorter delays than PCI Express due to the fact that the FPGA is directly connected to the central processor, bypassing various intermediate buses [16]. This technology uses the HTX slot in AMD Opetron systems.
Ultimate architecture
The device was implemented using synthesized constructs verilog RTL code and tested on an FPGA card based on Xilinx Virtex-4 FX100.
Figure 8 schematically illustrates the architecture of an HFT device. The one on the left is the HT core operating at 200 MHz. Next comes HTAX, connecting FAST processors, UDP, and RegisterFile with the HT core. This part works at a maximum frequency of 160 MHz. In the right part, the infrastructure for processing network packets connected to the Gigabit Ethernet MAC, which operates at 125 MHz, is shown in red. The entire architecture, including 4 FAST processors, uses 77 slices.
Performance
For the measurements, the recorded data supplied by the feed provider was sent to the standard server network card, located first, to determine the starting point for subsequent calculations. Figure 9 shows the message flow in a similar system. The measured delay for a NIC of 9 µs, for a kernel space of 1.8 µs and for a user space of 2 µs. The total delay is 12.8 µs.
The same feed was then sent to the FPGA device. In the first experiment, only the passage of the feed through the nuclear space was removed, as shown in Figure 10. The measured delay in passing the network stack on the FPGA board is 2 μs, the delay in user space is 2.1 μs. Thus, the delay value has already decreased to 4.1 µs, which reduces the execution time by 62 percent, compared with the standard implementation.
In the second experiment, the FAST processor was turned on, which allowed processing the messages in the hardware device and then transferring the result to the software address space, this process is shown in Figure 11. The measured delay value when both the network stack and FAST processing are delivered to the FPGA is 28 percent less and is only 2.6 µs. As a result, a reduction in the delay of 4 times, compared with the standard solution.
Conclusion
An implementation of a device aimed at optimizing HFT was shown, which can significantly reduce the amount of time required to receive and process trade information based on FAST. In particular, the delays were reduced four times, which significantly reduced the round-trip time for transactions.
The special nature of the FAST protocol, which does not allow its efficient processing on standard CPUs, makes it very attractive for implementation on FPGAs, with a significant reduction in time delays. The successful implementation of this approach was shown in this article.
Links
[1] JA Brogaard, “High Frequency Trading,” 5th Annual Conference on Employment Law, 2010.
[2] M. Chlistalla, “High-frequency trading Better than its reputation ?,” Deutsche Bank research report, 2011.
[3] A. Group, 2009.
[4] KH Chung and Y. Kim, “Volatility, Market Structure, and the Bid-Ask Spread,” Asia-Pacific Journal of Financial Studies, vol. 38, Feb. 2009
[5] J. Chiu, D. Lukman, K. Modarresi, and A. Velayutham, “High frequency trading,” Stanford University Research Report, 2011.
[6] H. Subramoni, F. Petrini, V. Agarwal, and D. Pasetto, “Streaming, low-level communication,” International Symposium on Parallel & Distributed Processing, Workshops (IPDPSW), 2010.
[7] V. Agarwal, D. a Bader, L. Dan, L.-K. Liu, D. Pasetto, M. Perrone, and F. Petrini, “Faster FAST: multicore acceleration of streaming financial data,” Computer Science - Research and Development, vol. 23, May. 2009
[8] GW Morris, DB Thomas, and W. Luk, “FPGA Accelerated LowLatency Market Data Feed Processing,” 2009 17th IEEE Symposium on High Performance Interconnects, Aug. 2009
[9] F. Herrmann and G. Perin, “An UDP / IP Network Stack in FPGA,” Electronics, Circuits, and Systems (ICECS), 2009.
[10] GL Zhang, PHW Leong, CH Ho, KH Tsoi, CCC Cheung, D. Lee, RCC Cheung, and W. Luk, “IEEE International Conference on Field-Programmable Technology,” 2005.
[11] DB Thomas, “Acceleration of Financial Monte-Carlo Simulations using FPGAs,” Workshop on High Performance Computational Finance (WHPCF), 2010.
[12] N. a. Woods and T. VanCourt, “FPGA acceleration of quasi-Monte Carlo finance,” 2008 International Conference on Field Programmable Logic and Applications, 2008, pp. 335-340.
[13] M. Sadoghi, M. Labrecque, H. Singh, W. Shum, and H.-arno Jacobsen, “Efficient Event Processing for Reconfigurable Hardware for Algorithmic Trading,” Journal of Proceedings of the VLDB Endowment, 2010.
[14] S. Tandon, “A Programmable Architecture for Real-Time Derivative Trading,” Master Thesis, University of Edinburgh, 2003.
[15] S. Larsen and P. Sarangam, “Architectural Breakdown of the End-to-End Latency in a TCP / IP Network,” International Journal of Parallel Programming, Springer, 2009.
[16] D. Slogsnat, A. Giese, M. Nüssle, and U. Brüning, “An open-source HyperTransport core,” ACM Transactions on Reconfigurable Technology and Systems, vol. 1, Sep. 2008, pp. 1-21.
[17] G. Mittal, DC Zaretsky, P. Banerjee, “FPGA,“ International Symposium on Field Programmable Gate Arrays - FPGA09, 2009.
[18] FIX adapted for Streaming, www.fixprotocol.org/fast
Source: https://habr.com/ru/post/163371/
All Articles