BM25 algorithm
For the first time, this algorithm was met on Wikipedia and did not pay much attention to it. Later, studying the scientific works of Yandex employees, I noticed that they refer to it, for example, in Segalovich's article on algorithms for determining fuzzy duplicates, so I decided to figure out the meaning of its use. I will try to explain this with simple examples. So what is this algorithm for?
The first. The dependence of relevance on the occurrence or non-occurrence of words in queries with more than one word is introduced.
Suppose there are several queries consisting of several words, for example (an example is purely illustrative):
Let two documents be compared (again, illustratively) and the first document does not contain the word Galaxy. According to the calculations, the relevance score is this sum of the relevances of each of the words.

')
The relevance of each word is equal to its IDF * to the second factor in the expression above. The relevance of the entire search query is equal to the sum of the relevance of all words. So the lack of a word or in other words (its frequency) is 0 gives the relevance of 0. Therefore, if the two first words of the score are the same, then the document that contains the word Galaxy will be more relevant.
(its frequency) is 0 gives the relevance of 0. Therefore, if the two first words of the score are the same, then the document that contains the word Galaxy will be more relevant.
The second. The advantage when searching in queries with more than 2 words, one of which is less commonly used (more narrowly specialized) will be given to documents that contain this highly specialized word. For example, there is a request to buy a Samsung Galaxy Note 2 (a purely illusory example). Let Note 2 is a rarer word (less often found in a collection than Samsung and Galaxy). Let there be 2 documents, each of which is relevant to the request and each of them contains, besides Samsung and Galaxy, also Note 2. In the first document, note 2 is used only once, whereas in the second, 3 times (it is assumed that the document contains more information about Note 2). But first, consider the result of the calculation of the relevance of the algorithm, if the frequencies of all specified words in documents are the same. Here is the BM25 in Excel.
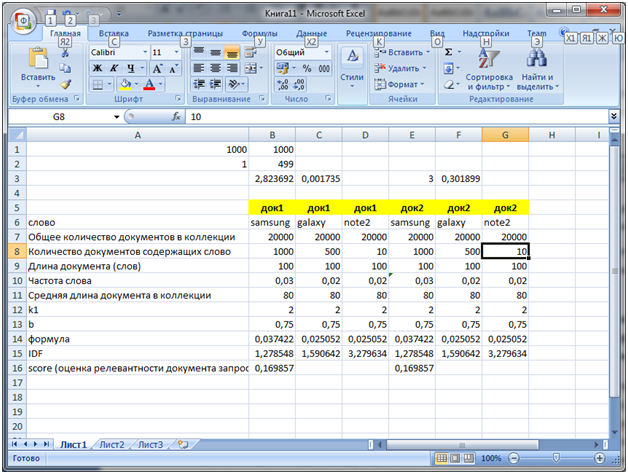
Please also note that due to the fact that the number of documents containing the word Note 2 is less than 50 times from those containing the word galaxy (500), we get an IDF of 3.279634, which is significantly more than the IDF for the word galaxy.
So far, we had the same frequency values for the word note 2 (for other words as well). Now let us in Excel increase the frequency of the word note 2 for doc2, instead of 0.02 we will do 0.05 (5 occurrences of the word).
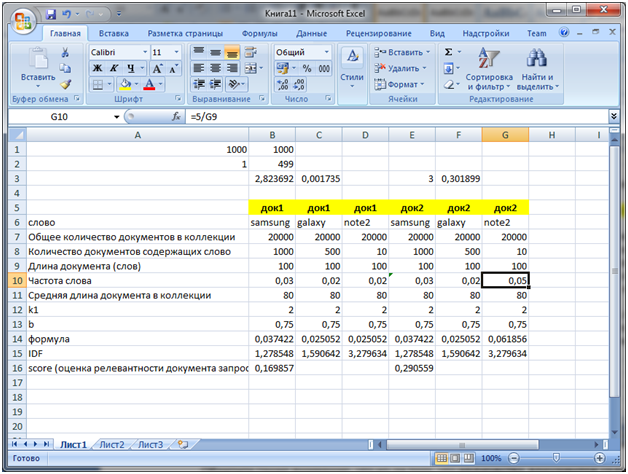
Please note that the IDF value does not change, but the formula value (the second factor in the image at the very top) now equals 0.061856, and it is this value that is involved in calculating the score, which is now 0.290559 for doc2
Now the most important thing. Increase the frequency of the word galaxy to 5 in the dock 1
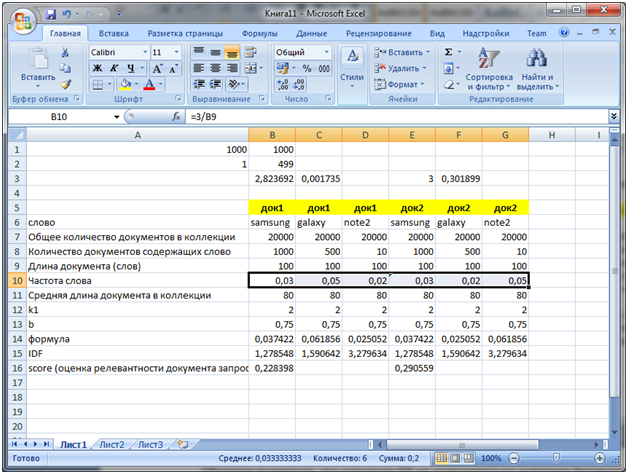
As we see, the total frequency of each of the words in doc1 and doc2 is the same. But the score value (relevance) is higher in doc2, because the word note2 is more rarely found, respectively, its resulting impact is greater than the word galaxy.
In practice, the presence of words in complex queries is very important. Of course, the relevance of modern search engines is determined not only on the basis of frequencies, as was shown by the example of the BM25 formula, but nevertheless some correlations can be made. This mainly concerns the fact that if a document does not contain a word from a search query, then such a document is much more difficult to climb into the TOC at the request compared to those with this word. Let's look at an example on the Yandex search engine.
Enter the query Samsung galaxy . My issue concerned the Samsung galaxy as a whole (2 sites, as usual Wikipedia) the rest of the model, pictures, etc.
Enter the query samsung galaxy note 2 . The issue is completely changed, now there are pages that contain information not only about the Samsung galaxy, but about the Samsung galaxy note 2.
Enter the query samsung galaxy note 2 price Again, the issue is now changing in the issuance of the page, which already contain the word price, and not just Samsung galaxy.
Enter the query samsung galaxy note 2 price Kharkov . The issue changes dramatically, all the pages in the TOP10 contain the word Kharkov.
Is it possible to say that the word Kharkov is more specialized, as it was cited in the BM25 algorithm above? IDF Closed Kharkov knows only the search engine, but in the context of the search query Samsung galaxy note 2, it undoubtedly narrows the search area. Maybe the example with Yandex is a bit unfortunate, due to the fact that taking into account the regionality of the query will play a big role, but I think any SEO will agree with me that the word from the search query must be in the text, I just tried to show the work of the BM25 algorithm and reveal 2 important aspects of it.
Link to xls document - book11.xls
The first. The dependence of relevance on the occurrence or non-occurrence of words in queries with more than one word is introduced.
Suppose there are several queries consisting of several words, for example (an example is purely illustrative):
- buy samsung smartphone
- buy a Samsung Galaxy smartphone
Let two documents be compared (again, illustratively) and the first document does not contain the word Galaxy. According to the calculations, the relevance score is this sum of the relevances of each of the words.
')
The relevance of each word is equal to its IDF * to the second factor in the expression above. The relevance of the entire search query is equal to the sum of the relevance of all words. So the lack of a word or in other words
(its frequency) is 0 gives the relevance of 0. Therefore, if the two first words of the score are the same, then the document that contains the word Galaxy will be more relevant.The second. The advantage when searching in queries with more than 2 words, one of which is less commonly used (more narrowly specialized) will be given to documents that contain this highly specialized word. For example, there is a request to buy a Samsung Galaxy Note 2 (a purely illusory example). Let Note 2 is a rarer word (less often found in a collection than Samsung and Galaxy). Let there be 2 documents, each of which is relevant to the request and each of them contains, besides Samsung and Galaxy, also Note 2. In the first document, note 2 is used only once, whereas in the second, 3 times (it is assumed that the document contains more information about Note 2). But first, consider the result of the calculation of the relevance of the algorithm, if the frequencies of all specified words in documents are the same. Here is the BM25 in Excel.
Please also note that due to the fact that the number of documents containing the word Note 2 is less than 50 times from those containing the word galaxy (500), we get an IDF of 3.279634, which is significantly more than the IDF for the word galaxy.
So far, we had the same frequency values for the word note 2 (for other words as well). Now let us in Excel increase the frequency of the word note 2 for doc2, instead of 0.02 we will do 0.05 (5 occurrences of the word).
Please note that the IDF value does not change, but the formula value (the second factor in the image at the very top) now equals 0.061856, and it is this value that is involved in calculating the score, which is now 0.290559 for doc2
Now the most important thing. Increase the frequency of the word galaxy to 5 in the dock 1
As we see, the total frequency of each of the words in doc1 and doc2 is the same. But the score value (relevance) is higher in doc2, because the word note2 is more rarely found, respectively, its resulting impact is greater than the word galaxy.
In practice, the presence of words in complex queries is very important. Of course, the relevance of modern search engines is determined not only on the basis of frequencies, as was shown by the example of the BM25 formula, but nevertheless some correlations can be made. This mainly concerns the fact that if a document does not contain a word from a search query, then such a document is much more difficult to climb into the TOC at the request compared to those with this word. Let's look at an example on the Yandex search engine.
Enter the query Samsung galaxy . My issue concerned the Samsung galaxy as a whole (2 sites, as usual Wikipedia) the rest of the model, pictures, etc.
Enter the query samsung galaxy note 2 . The issue is completely changed, now there are pages that contain information not only about the Samsung galaxy, but about the Samsung galaxy note 2.
Enter the query samsung galaxy note 2 price Again, the issue is now changing in the issuance of the page, which already contain the word price, and not just Samsung galaxy.
Enter the query samsung galaxy note 2 price Kharkov . The issue changes dramatically, all the pages in the TOP10 contain the word Kharkov.
Is it possible to say that the word Kharkov is more specialized, as it was cited in the BM25 algorithm above? IDF Closed Kharkov knows only the search engine, but in the context of the search query Samsung galaxy note 2, it undoubtedly narrows the search area. Maybe the example with Yandex is a bit unfortunate, due to the fact that taking into account the regionality of the query will play a big role, but I think any SEO will agree with me that the word from the search query must be in the text, I just tried to show the work of the BM25 algorithm and reveal 2 important aspects of it.
Link to xls document - book11.xls
Source: https://habr.com/ru/post/162937/
All Articles