Web service as a real-time system
In early December in St. Petersburg, in partnership with the Mail.Ru Group, the semifinals of the ACM ICPC World Programming Championship were held. As part of the championship, I met with the participants and talked about how to make a web service a real-time system; and now I want to share my report on Habré.
Speaking of a real-time system, we represent a nuclear power plant, an airplane, or something similar, where the lives of people depend on the reaction rate of an information system. If the team in the real-time system slows down for 10 seconds due to garbage collection, the consequences can be more than disastrous. The reaction must be instantaneous, and for the guaranteed time.
When a web service works, of course, a person’s life does not depend on how quickly he opened the letter in the mail, but the requirements for the web service are almost the same. 15 years ago, when the user clicked on the link, he waited 10 seconds for the reaction; for the slow internet of that time it was normal. Modern Internet is wide channels, fast computers. Everything works quickly for users, and they expect the same from services.
')
When a user clicks somewhere, he expects to instantly get a reaction to his click. What is instant? For a person, a comfortable delay is considered the response time of about 200 milliseconds, although in fact the human eye distinguishes between about 10 milliseconds . A web service should respond to user actions in less than 200 milliseconds - the smaller, the better.
So, a modern web service, in fact, should be a real-time system. How to make it meet this requirement, I will tell on the example of Mail Mail.Ru.
What is the sum of the request processing time?
The processing time of the request to the web service consists of the following things:
1 The first is a DNS query. The DNS query, of course, does not always happen, because the client caches the results of the DNS rezolving for a while. In principle, it can be cached for a long time, but the DNS record has such a thing as TTL. If it is small, the client is obliged to make another DNS request during TTL swelling. This time.
2 Then there is a connection to the server from the browser. A connection is several network roundtripes, and if this is an HTTPS connection, then there are even more. This is also a time.
3 After the connection is followed by sending a request over the network. The browser sends a request that is processed on the server.
4 Then the browser receives a response from the server, renders the HTML into a beautiful view, and only then shows it to the user.
It is important to understand that all these actions are carried out strictly consistently. A delay at any of the stages leads to an increase in response time, which cannot be reduced at all if you optimize another stage. For example, if the connection is slow, then no matter how you optimize the processing of the request on the server, all the same, the total request processing time will not be faster than the connection time.
Since it is impossible to grasp the immense, in this article I will review the processing on the server and tell you how we at Mail.Ru achieve high speed.
What happens on the server
Processing on the server also consists of several sequential actions.
The web server should:
1 accept the connection;
2 parse the request;
3 send the request to the handler;
4 execute all the business logic of the request;
5 get the answer from the handler;
6 give the answer to the client.
Again, all these actions are strictly sequential, and they are also summarized with all the other actions described above.
Let's look at a specific example of reading a message in Mail.Ru Mail, what happens inside the processing of requests and what business logic there is.
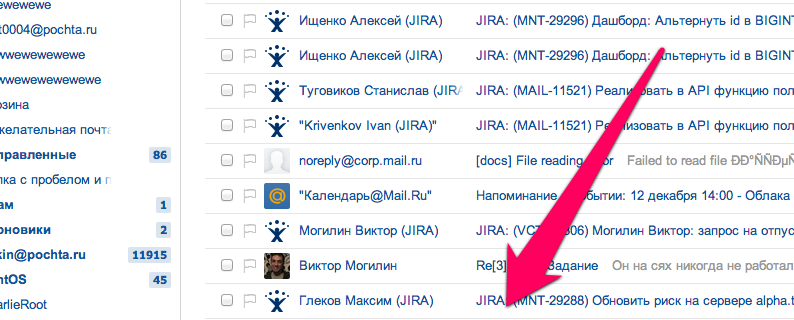
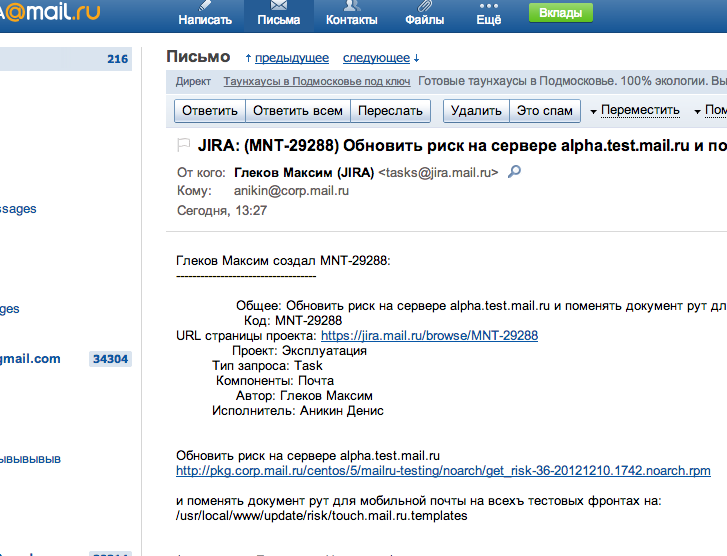
What happens inside the readmsg processing? The business logic handler in the web server must first check the session and find out which of the storage servers follow the message header. Then he asks for data about the header of the letter, this is a trip to another server. After that, he asks for the text of the letter, then parses the letter for the presence of XSSs in it, which he naturally cuts from there. Next comes a check for phishing images, and at the end - sending data to the internal statistics system for antispam.
Thus, request processing is a large number of sequential actions. Everything is arranged like a sandwich: one server accesses the other, that one - to the next, and we have a lot of actions performed on different servers, but strictly sequentially.
Only the most basic actions are listed here. Now they are all executed sequentially. We are working on parallelizing these processes, but for now we are optimizing what we have.
Accordingly, all these actions should be as fast as possible. Next, I will describe on points how we achieve this.
Session check
Sessions need to be stored in an in-memory database. I do not recommend using MySQL, Postgres or Oracle for this purpose. Why? Because in any SQL database, something unpredictable in terms of execution time can occur - for example, the index is pushed out of the cache - it will turn to disk, and you can hardly interfere with it in any way (theoretically, of course, you can, but you should always remember this, because the database stores everything on disk). The access to the disk in the loaded database is unpredictable in time. Maybe no, no, yes, and stick.
In addition, a general-purpose SQL database performs many different superfluous logic — and not because it is stupid, but because it is too general and not tailored to your specific task. What does this mean in session verification? The fact that we went to some database and began to do SELECT, and the database also consistently performs a large number of actions that continue to increase the overall response time.
It turns out that SQL cannot be stored, only NoSQL storage, only in memory, only hardcore. In Mail.Ru, we use our own Tarantool database as in-memory storage. He reads only from memory, writes in memory and on disk. Writing is also very fast, because only APPEND is used, there is no random seek. Accordingly, in most cases, the response from Tarantool comes in fractions of a millisecond.
Mail storage
Now consider the request to the mail store. There is no way out of the disk, but there is still room for optimization.
Firstly, the storage protocol itself must have a minimum number of network roundtripes. Ideally, one, maximum two. Because each roundtrip can stick simply because the internal networks are also not perfect, something can accidentally slow down somewhere. The more roundtripes, the higher the likelihood that you will catch this accident. And if you catch this randomness on at least one roundtrip from, for example, 30 that make up the entire request, that's all, your whole request is slowing down. Consequently, the smaller roundtripes, the lower this probability.
In addition, the storage itself should cache the hottest data in memory, and what is not cached should be given in just a few hits to the disk. If these hits are random, they should always be very few. There should not be much seek over a long file: many reads from different places strain the disk, force the head to move, and this all inevitably increases the processing time for requests.
Letter parsing
It is necessary to do the parsing in one pass and without working with dynamic memory. And, most importantly, parsing should include adding new features without changing this basic principle. Why is that? Yes, because when you have two passes, where there are two, there are three, where there are three, there are ten, and you begin to increase the time the request runs for a millisecond per millisecond.
Why no dynamic memory? Because the running time of the dynamic memory is unpredictable. If the memory is fragmented - long, if we are lucky, and there is no fragmentation, then quickly. Since we cannot rely on this indicator, and we have a real-time system, we should not use malloc-i, we should have an allocator, for example, a slab-allocator, or some kind of static buffers.
Phishing
Verifying phishing images is very similar to accessing sessions in the sense that the anti-phishing database must be completely in-memory (such as Memcached or Tarantool), and you need to make one request for all the pictures in the letter. If there are 100 pictures in the letter, you do not need to make 100 requests to the memcache. Even within a single connection, 100 requests are 100 roundtripes. We make one request and get out of it all in bulk. Each roundtrip is a delay plus some tenths of a millisecond, even for the internal network. And this delay, firstly, is increasing, and secondly, it can take somewhere and turn, for example, into 100 milliseconds. By chance. And that's all. Again, the more requests, the more likely it is to happen.
Statistics
Statistics should also be sent using a minimalistic protocol. Ideally, over UDP, but even if it is TCP, timeouts should be set for it to run for a controlled time, no more than a few milliseconds. In addition, statistics should not use third-party libraries. If third-party libraries are used, you must be completely sure of them.
There is a good example: imagine that a guy from a neighboring department comes to you. He asks your code, which runs online, to add his own logic for sending statistics, for example, to the anti-spam department, and gives you his own library. You naively insert its code to yourself, send statistics through it, post it to production, everything is slowing down in you. Why? And because this library, for example, accumulates a queue in memory, the queues are overflowing, and it is tearing down its roof. It would seem that you saw a timeout in the code. It turns out that it was only a timeout for reading, but not a timeout for a connection.
Therefore, do not believe in any parameters called timeout in third-party libraries. Do not believe anything and anyone, believe only your eyes. If you are responsible for this piece of functionality, you must yourself see all the code that you use, understand completely how it works. Sometimes it is cheaper and faster to write something of your own or use something well-known that definitely cannot slow down.
findings
In conclusion - a few conclusions for the developers of those parts of the web systems that work online.
Always remember milliseconds. They only add up, they are never deducted, unfortunately. Everywhere, where you had some kind of delay, it is added.
Be sure of the performance of third-party code if you use it.
Cover everything and everyone with timeouts.
Well and, referring to the database, some third-party repositories or anything outside, do not think that there is magic inside and everything is done instantly. Actually inside the same code, which may well be non-optimal.
If you have any questions about how to optimize web services, or if you want to share your useful experience, I will be glad to talk with you in the comments.
Speaking of a real-time system, we represent a nuclear power plant, an airplane, or something similar, where the lives of people depend on the reaction rate of an information system. If the team in the real-time system slows down for 10 seconds due to garbage collection, the consequences can be more than disastrous. The reaction must be instantaneous, and for the guaranteed time.
When a web service works, of course, a person’s life does not depend on how quickly he opened the letter in the mail, but the requirements for the web service are almost the same. 15 years ago, when the user clicked on the link, he waited 10 seconds for the reaction; for the slow internet of that time it was normal. Modern Internet is wide channels, fast computers. Everything works quickly for users, and they expect the same from services.
')
When a user clicks somewhere, he expects to instantly get a reaction to his click. What is instant? For a person, a comfortable delay is considered the response time of about 200 milliseconds, although in fact the human eye distinguishes between about 10 milliseconds . A web service should respond to user actions in less than 200 milliseconds - the smaller, the better.
So, a modern web service, in fact, should be a real-time system. How to make it meet this requirement, I will tell on the example of Mail Mail.Ru.
The processing time of the request to the web service consists of the following things:
1 The first is a DNS query. The DNS query, of course, does not always happen, because the client caches the results of the DNS rezolving for a while. In principle, it can be cached for a long time, but the DNS record has such a thing as TTL. If it is small, the client is obliged to make another DNS request during TTL swelling. This time.
2 Then there is a connection to the server from the browser. A connection is several network roundtripes, and if this is an HTTPS connection, then there are even more. This is also a time.
3 After the connection is followed by sending a request over the network. The browser sends a request that is processed on the server.
4 Then the browser receives a response from the server, renders the HTML into a beautiful view, and only then shows it to the user.
It is important to understand that all these actions are carried out strictly consistently. A delay at any of the stages leads to an increase in response time, which cannot be reduced at all if you optimize another stage. For example, if the connection is slow, then no matter how you optimize the processing of the request on the server, all the same, the total request processing time will not be faster than the connection time.
Since it is impossible to grasp the immense, in this article I will review the processing on the server and tell you how we at Mail.Ru achieve high speed.
What happens on the server
Processing on the server also consists of several sequential actions.
The web server should:
1 accept the connection;
2 parse the request;
3 send the request to the handler;
4 execute all the business logic of the request;
5 get the answer from the handler;
6 give the answer to the client.
Again, all these actions are strictly sequential, and they are also summarized with all the other actions described above.
Let's look at a specific example of reading a message in Mail.Ru Mail, what happens inside the processing of requests and what business logic there is.
What happens inside the readmsg processing? The business logic handler in the web server must first check the session and find out which of the storage servers follow the message header. Then he asks for data about the header of the letter, this is a trip to another server. After that, he asks for the text of the letter, then parses the letter for the presence of XSSs in it, which he naturally cuts from there. Next comes a check for phishing images, and at the end - sending data to the internal statistics system for antispam.
Thus, request processing is a large number of sequential actions. Everything is arranged like a sandwich: one server accesses the other, that one - to the next, and we have a lot of actions performed on different servers, but strictly sequentially.
Only the most basic actions are listed here. Now they are all executed sequentially. We are working on parallelizing these processes, but for now we are optimizing what we have.
Accordingly, all these actions should be as fast as possible. Next, I will describe on points how we achieve this.
Session check
Sessions need to be stored in an in-memory database. I do not recommend using MySQL, Postgres or Oracle for this purpose. Why? Because in any SQL database, something unpredictable in terms of execution time can occur - for example, the index is pushed out of the cache - it will turn to disk, and you can hardly interfere with it in any way (theoretically, of course, you can, but you should always remember this, because the database stores everything on disk). The access to the disk in the loaded database is unpredictable in time. Maybe no, no, yes, and stick.
In addition, a general-purpose SQL database performs many different superfluous logic — and not because it is stupid, but because it is too general and not tailored to your specific task. What does this mean in session verification? The fact that we went to some database and began to do SELECT, and the database also consistently performs a large number of actions that continue to increase the overall response time.
It turns out that SQL cannot be stored, only NoSQL storage, only in memory, only hardcore. In Mail.Ru, we use our own Tarantool database as in-memory storage. He reads only from memory, writes in memory and on disk. Writing is also very fast, because only APPEND is used, there is no random seek. Accordingly, in most cases, the response from Tarantool comes in fractions of a millisecond.
Mail storage
Now consider the request to the mail store. There is no way out of the disk, but there is still room for optimization.
Firstly, the storage protocol itself must have a minimum number of network roundtripes. Ideally, one, maximum two. Because each roundtrip can stick simply because the internal networks are also not perfect, something can accidentally slow down somewhere. The more roundtripes, the higher the likelihood that you will catch this accident. And if you catch this randomness on at least one roundtrip from, for example, 30 that make up the entire request, that's all, your whole request is slowing down. Consequently, the smaller roundtripes, the lower this probability.
In addition, the storage itself should cache the hottest data in memory, and what is not cached should be given in just a few hits to the disk. If these hits are random, they should always be very few. There should not be much seek over a long file: many reads from different places strain the disk, force the head to move, and this all inevitably increases the processing time for requests.
Letter parsing
It is necessary to do the parsing in one pass and without working with dynamic memory. And, most importantly, parsing should include adding new features without changing this basic principle. Why is that? Yes, because when you have two passes, where there are two, there are three, where there are three, there are ten, and you begin to increase the time the request runs for a millisecond per millisecond.
Why no dynamic memory? Because the running time of the dynamic memory is unpredictable. If the memory is fragmented - long, if we are lucky, and there is no fragmentation, then quickly. Since we cannot rely on this indicator, and we have a real-time system, we should not use malloc-i, we should have an allocator, for example, a slab-allocator, or some kind of static buffers.
Phishing
Verifying phishing images is very similar to accessing sessions in the sense that the anti-phishing database must be completely in-memory (such as Memcached or Tarantool), and you need to make one request for all the pictures in the letter. If there are 100 pictures in the letter, you do not need to make 100 requests to the memcache. Even within a single connection, 100 requests are 100 roundtripes. We make one request and get out of it all in bulk. Each roundtrip is a delay plus some tenths of a millisecond, even for the internal network. And this delay, firstly, is increasing, and secondly, it can take somewhere and turn, for example, into 100 milliseconds. By chance. And that's all. Again, the more requests, the more likely it is to happen.
Statistics
Statistics should also be sent using a minimalistic protocol. Ideally, over UDP, but even if it is TCP, timeouts should be set for it to run for a controlled time, no more than a few milliseconds. In addition, statistics should not use third-party libraries. If third-party libraries are used, you must be completely sure of them.
There is a good example: imagine that a guy from a neighboring department comes to you. He asks your code, which runs online, to add his own logic for sending statistics, for example, to the anti-spam department, and gives you his own library. You naively insert its code to yourself, send statistics through it, post it to production, everything is slowing down in you. Why? And because this library, for example, accumulates a queue in memory, the queues are overflowing, and it is tearing down its roof. It would seem that you saw a timeout in the code. It turns out that it was only a timeout for reading, but not a timeout for a connection.
Therefore, do not believe in any parameters called timeout in third-party libraries. Do not believe anything and anyone, believe only your eyes. If you are responsible for this piece of functionality, you must yourself see all the code that you use, understand completely how it works. Sometimes it is cheaper and faster to write something of your own or use something well-known that definitely cannot slow down.
findings
In conclusion - a few conclusions for the developers of those parts of the web systems that work online.
Always remember milliseconds. They only add up, they are never deducted, unfortunately. Everywhere, where you had some kind of delay, it is added.
Be sure of the performance of third-party code if you use it.
Cover everything and everyone with timeouts.
Well and, referring to the database, some third-party repositories or anything outside, do not think that there is magic inside and everything is done instantly. Actually inside the same code, which may well be non-optimal.
If you have any questions about how to optimize web services, or if you want to share your useful experience, I will be glad to talk with you in the comments.
Source: https://habr.com/ru/post/162625/
All Articles