About one method of memory allocation

It is no secret that sometimes memory allocation requires separate solutions. For example - when memory is allocated and released by a fast
As a result, the standard conservative allocator builds all requests in the queue at the pthread_mutex / critical section. And our multi-core processor is driving slowly and sadly in first gear.
And what to do with it? Let's take a closer look at the details of the implementation of the Scalable Lock-Free Dynamic Memory Allocation method. Maged M. Michael. IBM Thomas J. Watson Research Center.
')
The easiest code I managed to find was written under the LGPL comrades Scott Schneider and Christos Antonopoulos. And consider it.
Let's start from afar

So - how do we get rid of unnecessary locks?
The answer lies on the surface - it is necessary to allocate memory in the lock-free lists. Good idea - but how are such lists built?
Atomic operations are rushing to help us. The ones that are InterlockedCompareExchange. But wait, the maximum we can expect is a long long, aka __int64. And what to do? And that's what - we define our own pointer with the tag.
By limiting the address size to 46 bits, we can hide the add-ons we need in 64bit integer, and they will be needed later.
#pragma pack(1) typedef struct { volatile unsigned __int64 top:46, ocount:18; } top_aba_t; By the way, with 8/16 byte alignment, we can get not 2 to 46 degrees, but a bit more. Standard method - the address given cannot be odd and, moreover, must be aligned for a floating point.
And another point - the code becomes very long. That is the standard footcloth
desc->Next = queue_head; queue_head = desc; turns into pasta like that
descriptor_queue old_queue, new_queue; do { old_queue = queue_head; desc->Next = (descriptor*)old_queue.DescAvail; new_queue.DescAvail = (unsigned __int64)desc; new_queue.tag = old_queue.tag + 1; } while (!compare_and_swap64k(queue_head, old_queue, new_queue)); which greatly lengthens the code and makes it less readable. Therefore, the obvious things are removed under spoilers.
Lock-free fifo queue

Since we now have our own pointer, we can go over the list.
// Pseudostructure for lock-free list elements. // The only requirement is that the 5th-8th byte of // each element should be available to be used as // the pointer for the implementation of a singly-linked // list. struct queue_elem_t { char *_dummy; volatile queue_elem_t *next; }; And in our case - do not forget about alignment, for example
typedef struct { unsigned __int64 _pad0[8]; top_aba_t both; unsigned __int64 _pad1[8]; } lf_fifo_queue_t; Wrapping work with atomic functions

Now we define a couple of abstractions so that our code can be portable (for Win32, for example, this is implemented like this):
Atom Wrapper for Win32
#define fetch_and_store(address, value) InterlockedExchange((PLONG)(address), (value)) #define atmc_add(address, value) InterlockedExchangeAdd((PLONG)(address), (value)) #define compare_and_swap32(address, old_value, new_value) \ (InterlockedCompareExchange(\ (PLONG)(address), (new_value), (old_value))\ == (old_value)) #define compare_and_swap64(address, old_value, new_value) \ (InterlockedCompareExchange64(\ (PLONGLONG)(address), (__int64)(new_value), (__int64)(old_value)) \ == (__int64)(old_value)) #define compare_and_swap_ptr(address, old_value, new_value) \ (InterlockedCompareExchangePointer((address), \ (new_value), (old_value)) \ == (old_value)) and add another method, just to not be distracted by casting the parameters to __int64 and passing them along the pointers.
#define compare_and_swap64k(a,b,c) \ compare_and_swap64((volatile unsigned __int64*)&(a), \ *((unsigned __int64*)&(b)), \ *((unsigned __int64*)&(c))) And now we are ready to implement the basic functions (add and delete).
Determine the basic functions of the list
static inline int lf_fifo_enqueue(lf_fifo_queue_t *queue, void *element) { top_aba_t old_top; top_aba_t new_top; for(;;) { old_top.ocount = queue->both.ocount; old_top.top = queue->both.top; ((queue_elem_t *)element)->next = (queue_elem_t *)old_top.top; new_top.top = (unsigned __int64)element; new_top.ocount += 1; if (compare_and_swap64k(queue->both, old_top, new_top)) return 0; } } What you need to pay attention to - the usual operation to add is wrapped in a loop, the output of which is that we have successfully written a new value over the old one, and at the same time the old one has not changed. Well, if you change it, we repeat it all over again. And another point - in our ocount we write down the number of the attempt with which we succeeded. A trifle, and each attempt gives a unique 64bit integer.
It is on such a simple shamanism that lock-free data structures are built.
Similarly, the removal from the top of our FIFO list is implemented:
Similar to lf_fifo_dequeue
static inline void *lf_fifo_dequeue(lf_fifo_queue_t *queue) { top_aba_t head; top_aba_t next; for(;;) { head.top = queue->both.top; head.ocount = queue->both.ocount; if (head.top == 0) return NULL; next.top = (unsigned __int64)(((struct queue_elem_t *)head.top)->next); next.ocount += 1; if (compare_and_swap64k(queue->both, head, next)) return ((void *)head.top); } } Here we see exactly the same thing - in a cycle we try to remove, if there is something, and we remove so that the old value is still correct - that is fine, but no - we try again.
And of course, the initialization of such an element of the list is trivial - here it is:
lf_fifo_queue_init
static inline void lf_fifo_queue_init(lf_fifo_queue_t *queue) { queue->both.top = 0; queue->both.ocount = 0; } Actually the idea of the allocator

We now turn directly to the allocator. The allocator must be fast — so we divide the memory into classes. Large (directly from the system), and small, beaten for many, many small subclasses ranging in size from 8 bytes to 2 kilobytes.
Such a knight's move will allow us to solve two problems. The first - small pieces will be allocated super-fast, and due to the fact that they are divided into a table - will not lie in one huge list. And large pieces of memory will not interfere under your feet and lead to problems with fragmentation. Moreover, since in each subclass we have all the blocks of the same size, working with them is very easy.
And another moment! Selection of small pieces we will tie to the threads (and the release - no). Thus, we will kill two birds with one stone - the allocation control will be simplified, and the memory islands allocated to the thread locally - will not be mixed up once more.
We get something like this:
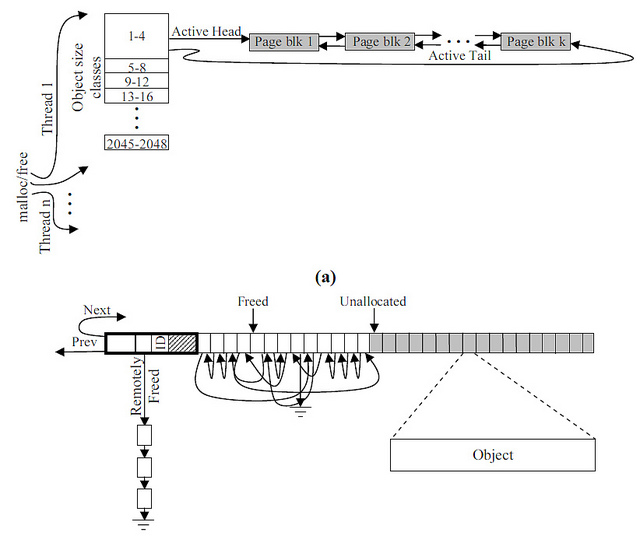
And this is how the data will be displayed on the superblock
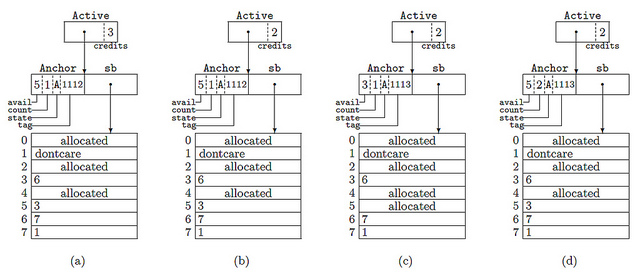
In the picture we see 4 cases
- The active superblock contains 5 items organized into a list, 4 of them are available for use.
- And now we have reserved the next item (see credits)
- As a result, they gave out block number 5.
- And then it was returned back (but it hit the partial list)
We describe the block hip and handle

Praying to the goddess Techno, let's get started.
Define a couple of constants
Balnalschina a la GRANULARITY and PAGE_SIZE
struct Descriptor; typedef struct Descriptor descriptor; struct Procheap; typedef struct Procheap procheap; #define TYPE_SIZE sizeof(void*) #define PTR_SIZE sizeof(void*) #define HEADER_SIZE (TYPE_SIZE + PTR_SIZE) #define LARGE 0 #define SMALL 1 #define PAGESIZE 4096 #define SBSIZE (16 * PAGESIZE) #define DESCSBSIZE (1024 * sizeof(descriptor)) #define ACTIVE 0 #define FULL 1 #define PARTIAL 2 #define EMPTY 3 #define MAXCREDITS 64 // 2^(bits for credits in active) #define GRANULARITY 8 And we will be engaged in a creative, we will define the necessary data types. So, we will have many hipov - each in its class, but tied to the current thread. There will be two pointers in the superblock - the active list and the redistributed one.
You ask - what is it and why is it so difficult?
First, it’s the main thing - to single out the list elementwise is trivially unprofitable. That is - the classic unidirectional list with millions of elements turns into hell and Israel. For each element of the list, you need to allocate 8/16 bytes in order to store two unfortunate pointers to the data itself and to the next element of the list.
Is it profitable? Obviously - no! And what should you do? That's right, but let's group our list descriptors into groups (stripe) by 500 (for example) items. And we get a list of not elements, but - groups. Economically, practically, it is possible to work with elements as in the classic version. The whole question is only in non-standard memory allocation.
Moreover, all the Next within the block simply point to the neighboring element of the array, and we can explicitly initialize them immediately when the stripe is selected. In fact, the last Next in a stripe will indicate the next stripe, but from the point of view of working with lists, nothing changes.
It is easy to guess that the lists of memory block descriptors are built that way.
And yet - Active is our active stripe with pre-allocated pieces of memory on an enByte, in which we conduct memory allocation on the FIFO principle. If there is a place in the stripe - we take from there. If not, we are already looking for the Partial classic list. If there is neither there nor there - well, select a new stripe.
Secondly, such “banding” leads to some memory overuse, since we can allocate a stripe for 8 byte memory pieces as an array in 64K, and a couple of pieces will be requested. And yet, active stripes for each thread is its own, which will further aggravate the problem.
However, if we are really actively working with memory, it will give a good gain in speed.
Here is the hip itself
struct Procheap { volatile active Active; // initially NULL volatile descriptor* Partial; // initially NULL sizeclass* sc; // pointer to parent sizeclass }; But what he needs:
What is this Active / Partial such
typedef struct { unsigned __int64 ptr:58, credits:6; } active; /* We need to squeeze this in 64-bits, but conceptually * this is the case: * descriptor* DescAvail; */ typedef struct { unsigned __int64 DescAvail:46, tag:18; } descriptor_queue; /* Superblock descriptor structure. We bumped avail and count * to 24 bits to support larger superblock sizes. */ typedef struct { unsigned __int64 avail:24,count:24, state:2, tag:14; } anchor; typedef struct { lf_fifo_queue_t Partial; // initially empty unsigned int sz; // block size unsigned int sbsize; // superblock size } sizeclass; and the descriptor itself is a handle to our fragment.
struct Descriptor { struct queue_elem_t lf_fifo_queue_padding; volatile anchor Anchor; // anchor to superblock exact place descriptor* Next; // next element in list void* sb; // pointer to superblock procheap* heap; // pointer to owner procheap unsigned int sz; // block size unsigned int maxcount; // superblock size / sz }; As you can see - nothing supernatural. We need the description of the hip and the superblock in the descriptor, since it is possible to allocate memory in one thread, and free it in another.
Let's start the implementation

First we need to define our local variables — hips, sizes, and so on. Something like this:
As without global variables
/* This is large and annoying, but it saves us from needing an * initialization routine. */ sizeclass sizeclasses[2048 / GRANULARITY] = { {LF_FIFO_QUEUE_STATIC_INIT, 8, SBSIZE}, {LF_FIFO_QUEUE_STATIC_INIT, 16, SBSIZE}, ... {LF_FIFO_QUEUE_STATIC_INIT, 2024, SBSIZE}, {LF_FIFO_QUEUE_STATIC_INIT, 2032, SBSIZE}, {LF_FIFO_QUEUE_STATIC_INIT, 2040, SBSIZE}, {LF_FIFO_QUEUE_STATIC_INIT, 2048, SBSIZE}, }; #define LF_FIFO_QUEUE_STATIC_INIT {{0, 0, 0, 0, 0, 0, 0, 0}, {0, 0}, {0, 0, 0, 0, 0, 0, 0, 0}} __declspec(thread) procheap* heaps[2048 / GRANULARITY]; // = { }; static volatile descriptor_queue queue_head; Here we see everything that was considered in the previous section:
__declspec(thread) procheap* heaps[2048 / GRANULARITY]; // = { }; static volatile descriptor_queue queue_head; This is our per thread heaps. And - a list of all per-process descriptors.
Malloc - how it works
Consider the actual memory allocation process in more detail. It is easy to see a few features, namely:
- If the requested size does not have our hip for small sizes, simply request from the system
- We allocate memory in turn - first from the active list, then from the list of fragments, and finally - try to request a new piece from the system.
- We always have memory in the system, and if not, we just need to wait in the loop.
Here is a solution.
void* my_malloc(size_t sz) { procheap *heap; void* addr; // Use sz and thread id to find heap. heap = find_heap(sz); if (!heap) // Large block return alloc_large_block(sz); for(;;) { addr = MallocFromActive(heap); if (addr) return addr; addr = MallocFromPartial(heap); if (addr) return addr; addr = MallocFromNewSB(heap); if (addr) return addr; } } Delve into the topic, consider each part separately. Let's start from the beginning - by adding a new piece from the system.
MallocFromNewSB
static void* MallocFromNewSB(procheap* heap) { descriptor* desc; void* addr; active newactive, oldactive; *((unsigned __int64*)&oldactive) = 0; desc = DescAlloc(); desc->sb = AllocNewSB(heap->sc->sbsize, SBSIZE); desc->heap = heap; desc->Anchor.avail = 1; desc->sz = heap->sc->sz; desc->maxcount = heap->sc->sbsize / desc->sz; // Organize blocks in a linked list starting with index 0. organize_list(desc->sb, desc->maxcount, desc->sz); *((unsigned __int64*)&newactive) = 0; newactive.ptr = (__int64)desc; newactive.credits = min(desc->maxcount - 1, MAXCREDITS) - 1; desc->Anchor.count = max(((signed long)desc->maxcount - 1 ) - ((signed long)newactive.credits + 1), 0); // max added by Scott desc->Anchor.state = ACTIVE; // memory fence. if (compare_and_swap64k(heap->Active, oldactive, newactive)) { addr = desc->sb; *((char*)addr) = (char)SMALL; addr = (char*) addr + TYPE_SIZE; *((descriptor **)addr) = desc; return (void *)((char*)addr + PTR_SIZE); } else { //Free the superblock desc->sb. munmap(desc->sb, desc->heap->sc->sbsize); DescRetire(desc); return NULL; } } No miracles - just creating a superblock, a descriptor, and initializing an empty list. And adding to the list of active new block. Here I ask you to pay attention to the fact that there is no assignment loop. If it failed, then it failed. Why is that? Because the function is already called from the loop, and if it was not possible to insert it into the list, it means that someone else inserted it and it is necessary to allocate the memory first.
We now turn to the selection of a block from the list of active ones - after all, we have already learned how to select the superblock and so on.
MallocFromActive
static void* MallocFromActive(procheap *heap) { active newactive, oldactive; descriptor* desc; anchor oldanchor, newanchor; void* addr; unsigned __int64 morecredits = 0; unsigned long next = 0; // First step: reserve block do { newactive = oldactive = heap->Active; if (!(*((unsigned __int64*)(&oldactive)))) return NULL; if (oldactive.credits == 0) *((unsigned __int64*)(&newactive)) = 0; else --newactive.credits; } while (!compare_and_swap64k(heap->Active, oldactive, newactive)); // Second step: pop block desc = mask_credits(oldactive); do { // state may be ACTIVE, PARTIAL or FULL newanchor = oldanchor = desc->Anchor; addr = (void *)((unsigned __int64)desc->sb + oldanchor.avail * desc->sz); next = *(unsigned long *)addr; newanchor.avail = next; ++newanchor.tag; if (oldactive.credits == 0) { // state must be ACTIVE if (oldanchor.count == 0) newanchor.state = FULL; else { morecredits = min(oldanchor.count, MAXCREDITS); newanchor.count -= morecredits; } } } while (!compare_and_swap64k(desc->Anchor, oldanchor, newanchor)); if (oldactive.credits == 0 && oldanchor.count > 0) UpdateActive(heap, desc, morecredits); *((char*)addr) = (char)SMALL; addr = (char*) addr + TYPE_SIZE; *((descriptor**)addr) = desc; return ((void*)((char*)addr + PTR_SIZE)); } The algorithm itself is simple, only a cumbersome form of recording confuses us slightly. In fact, if you have something to take, then we take a new piece from the superblock, and note this fact. Along the way, we check to see if we took the last piece, and if so, mark that.
There is a roano here, one subtlety, namely, if it suddenly turned out that we took the last piece from the superblock, then the next query after us will lead to the addition of a new superblock in exchange for the already used one. And as soon as we discovered this, we have nowhere to write down the fact that the block is selected. Therefore, we enter the newly selected piece in the partial list.
UpdateActive
static void UpdateActive(procheap* heap, descriptor* desc, unsigned __int64 morecredits) { active oldactive, newactive; anchor oldanchor, newanchor; *((unsigned __int64*)&oldactive) = 0; newactive.ptr = (__int64)desc; newactive.credits = morecredits - 1; if (compare_and_swap64k(heap->Active, oldactive, newactive)) return; // Someone installed another active sb // Return credits to sb and make it partial do { newanchor = oldanchor = desc->Anchor; newanchor.count += morecredits; newanchor.state = PARTIAL; } while (!compare_and_swap64k(desc->Anchor, oldanchor, newanchor)); HeapPutPartial(desc); } It is time to consider working with descriptors before we get to the final part of this essay.
Memory Block Descriptors

For starters, learn how to create a descriptor. But where? Actually, if anyone has forgotten - we are just writing a memory allocation. An obvious and beautiful solution would be to use the same mechanisms as for the generic allocation, but alas, it would be the well-known joke pkunzip.zip. Therefore, the principle is the same - we select a large block containing an array of descriptors, and as soon as the array is full, we create a new one and combine it with the previous one into the list.
DescAlloc
static descriptor* DescAlloc() { descriptor_queue old_queue, new_queue; descriptor* desc; for(;;) { old_queue = queue_head; if (old_queue.DescAvail) { new_queue.DescAvail = (unsigned __int64)((descriptor*)old_queue.DescAvail)->Next; new_queue.tag = old_queue.tag + 1; if (compare_and_swap64k(queue_head, old_queue, new_queue)) { desc = (descriptor*)old_queue.DescAvail; break; } } else { desc = AllocNewSB(DESCSBSIZE, sizeof(descriptor)); organize_desc_list((void *)desc, DESCSBSIZE / sizeof(descriptor), sizeof(descriptor)); new_queue.DescAvail = (unsigned long)desc->Next; new_queue.tag = old_queue.tag + 1; if (compare_and_swap64k(queue_head, old_queue, new_queue)) break; munmap((void*)desc, DESCSBSIZE); } } return desc; } Well, now it's up to a no less powerful witch - you also have to learn how to return the descriptor back. However, we will return in the same FIFO - because we will need to return only if we took it by mistake, and this fact is revealed immediately. So it turns out to be much easier.
DescRetire
void DescRetire(descriptor* desc) { descriptor_queue old_queue, new_queue; do { old_queue = queue_head; desc->Next = (descriptor*)old_queue.DescAvail; new_queue.DescAvail = (unsigned __int64)desc; new_queue.tag = old_queue.tag + 1; } while (!compare_and_swap64k(queue_head, old_queue, new_queue)); } Helpers

We also give auxiliary functions for initializing lists, etc. The functions are so self-evident that there is no sense even to describe them.
organize_list
static void organize_list(void* start, unsigned long count, unsigned long stride) { char* ptr; unsigned long i; ptr = (char*)start; for (i = 1; i < count - 1; i++) { ptr += stride; *((unsigned long*)ptr) = i + 1; } } organize_desc_list
static void organize_desc_list(descriptor* start, unsigned long count, unsigned long stride) { char* ptr; unsigned int i; start->Next = (descriptor*)(start + stride); ptr = (char*)start; for (i = 1; i < count - 1; i++) { ptr += stride; ((descriptor*)ptr)->Next = (descriptor*)((char*)ptr + stride); } ptr += stride; ((descriptor*)ptr)->Next = NULL; } mask_credits
static descriptor* mask_credits(active oldactive) { return (descriptor*)oldactive.ptr; } The superblock is simply requested from the system:
static void* AllocNewSB(size_t size, unsigned long alignement) { return VirtualAlloc(NULL, size, MEM_COMMIT, PAGE_READWRITE); } Similarly, we get large blocks by requesting a little more under the block header:
alloc_large_block
static void* alloc_large_block(size_t sz) { void* addr = VirtualAlloc(NULL, sz + HEADER_SIZE, MEM_COMMIT, PAGE_READWRITE); // If the highest bit of the descriptor is 1, then the object is large // (allocated / freed directly from / to the OS) *((char*)addr) = (char)LARGE; addr = (char*) addr + TYPE_SIZE; *((unsigned long *)addr) = sz + HEADER_SIZE; return (void*)((char*)addr + PTR_SIZE); } And this is a search in our hip table adapted to the desired size (bkb zero if the size is too large):
find_heap
static procheap* find_heap(size_t sz) { procheap* heap; // We need to fit both the object and the descriptor in a single block sz += HEADER_SIZE; if (sz > 2048) return NULL; heap = heaps[sz / GRANULARITY]; if (heap == NULL) { heap = VirtualAlloc(NULL, sizeof(procheap), MEM_COMMIT, PAGE_READWRITE); *((unsigned __int64*)&(heap->Active)) = 0; heap->Partial = NULL; heap->sc = &sizeclasses[sz / GRANULARITY]; heaps[sz / GRANULARITY] = heap; } return heap; } And here are wrappers for lists. They are added solely for clarity - we have more than enough code with macaroni around the atomics, so that in one function yt we add ten cycles around compare and swap.
ListGetPartial
static descriptor* ListGetPartial(sizeclass* sc) { return (descriptor*)lf_fifo_dequeue(&sc->Partial); } ListPutPartial
static void ListPutPartial(descriptor* desc) { lf_fifo_enqueue(&desc->heap->sc->Partial, (void*)desc); } The deletion is built in the simplest way - by rebuilding the list into a temporary one and back:
ListRemoveEmptyDesc
static void ListRemoveEmptyDesc(sizeclass* sc) { descriptor *desc; lf_fifo_queue_t temp = LF_FIFO_QUEUE_STATIC_INIT; while (desc = (descriptor *)lf_fifo_dequeue(&sc->Partial)) { lf_fifo_enqueue(&temp, (void *)desc); if (desc->sb == NULL) DescRetire(desc); else break; } while (desc = (descriptor *)lf_fifo_dequeue(&temp)) lf_fifo_enqueue(&sc->Partial, (void *)desc); } And a few wrappers around partial lists
RemoveEmptyDesc
static void RemoveEmptyDesc(procheap* heap, descriptor* desc) { if (compare_and_swap_ptr(&heap->Partial, desc, NULL)) DescRetire(desc); else ListRemoveEmptyDesc(heap->sc); } HeapGetPartial
static descriptor* HeapGetPartial(procheap* heap) { descriptor* desc; do { desc = *((descriptor**)&heap->Partial); // casts away the volatile if (desc == NULL) return ListGetPartial(heap->sc); } while (!compare_and_swap_ptr(&heap->Partial, desc, NULL)); return desc; } HeapPutPartial
static void HeapPutPartial(descriptor* desc) { descriptor* prev; do { prev = (descriptor*)desc->heap->Partial; // casts away volatile } while (!compare_and_swap_ptr(&desc->heap->Partial, prev, desc)); if (prev) ListPutPartial(prev); } The last spurt - and select / release ready!

And finally, we are ready to realize memory allocation not in a stripe, we already have all the possibilities for this.
The algorithm is simple - we find our list, reserve a place in it (freeing up empty blocks at the same time), and return it to the client.
MallocFromPartial
static void* MallocFromPartial(procheap* heap) { descriptor* desc; anchor oldanchor, newanchor; unsigned __int64 morecredits; void* addr; retry: desc = HeapGetPartial(heap); if (!desc) return NULL; desc->heap = heap; do { // reserve blocks newanchor = oldanchor = desc->Anchor; if (oldanchor.state == EMPTY) DescRetire(desc); goto retry; } // oldanchor state must be PARTIAL // oldanchor count must be > 0 morecredits = min(oldanchor.count - 1, MAXCREDITS); newanchor.count -= morecredits + 1; newanchor.state = morecredits > 0 ? ACTIVE : FULL; } while (!compare_and_swap64k(desc->Anchor, oldanchor, newanchor)); do { // pop reserved block newanchor = oldanchor = desc->Anchor; addr = (void*)((unsigned __int64)desc->sb + oldanchor.avail * desc->sz); newanchor.avail = *(unsigned long*)addr; ++newanchor.tag; } while (!compare_and_swap64k(desc->Anchor, oldanchor, newanchor)); if (morecredits > 0) UpdateActive(heap, desc, morecredits); *((char*)addr) = (char)SMALL; addr = (char*) addr + TYPE_SIZE; *((descriptor**)addr) = desc; return ((void *)((char*)addr + PTR_SIZE)); } Now consider how to get us back to the list of memory. In general, the classic algorithm: we retrieve the handle by the pointer given to us, and by the anchor stored in the handle we get to the place of the superblock we need and mark the desired piece as free, and who still read the beer. And of course, a couple of checks - if we don’t need to free the entire superblock, otherwise it’s the last one that has not been released.
void my_free(void* ptr) { descriptor* desc; void* sb; anchor oldanchor, newanchor; procheap* heap = NULL; if (!ptr) return; // get prefix ptr = (void*)((char*)ptr - HEADER_SIZE); if (*((char*)ptr) == (char)LARGE) { munmap(ptr, *((unsigned long *)((char*)ptr + TYPE_SIZE))); return; } desc = *((descriptor**)((char*)ptr + TYPE_SIZE)); sb = desc->sb; do { newanchor = oldanchor = desc->Anchor; *((unsigned long*)ptr) = oldanchor.avail; newanchor.avail = ((char*)ptr - (char*)sb) / desc->sz; if (oldanchor.state == FULL) newanchor.state = PARTIAL; if (oldanchor.count == desc->maxcount - 1) { heap = desc->heap; // instruction fence. newanchor.state = EMPTY; } else ++newanchor.count; // memory fence. } while (!compare_and_swap64k(desc->Anchor, oldanchor, newanchor)); if (newanchor.state == EMPTY) { munmap(sb, heap->sc->sbsize); RemoveEmptyDesc(heap, desc); } else if (oldanchor.state == FULL) HeapPutPartial(desc); } — partial list, — Active , « ». .
findings

lock-free FIFO lists, , . , .
Additional materials
- Scalable Lock-Free Dynamic Memory Allocation
- Hoard memory allocator
- Scalable Locality-ConsciousMultithreaded Memory Allocation
, [3] ( ).
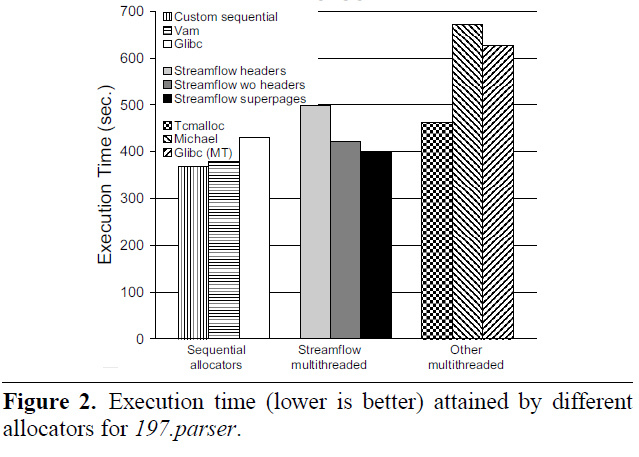
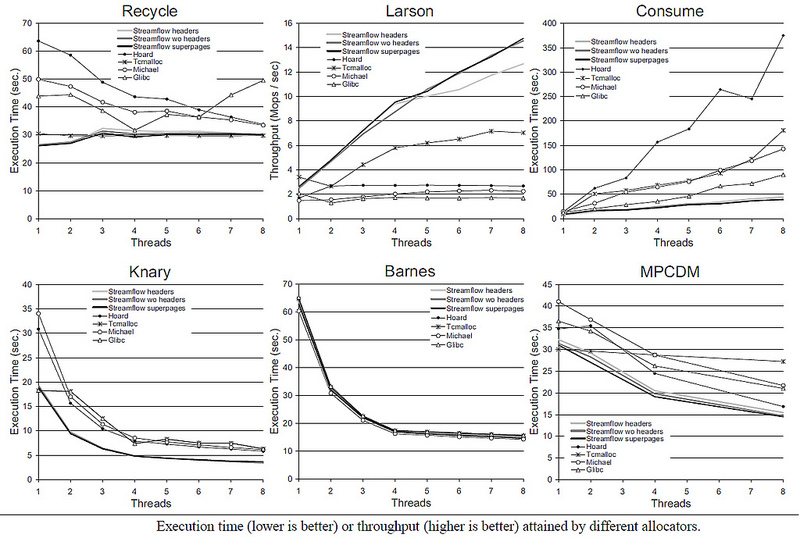
, , , .
Update: SkidanovAlex :
, ocount. tagged pointer. , , ( ABA — top_aba_t):
pop :
do { long snapshot = stack->head; long next = snapshot->next; } while (!cas(&stack->head, next, snapshot)); deque , ocount. : , B ( A -> B). snapshot = A, next = B.
A, C, . :
A -> C -> B.
pop , CAS (stack->head == snapshot, A), stack->head B. C .
ocount , A ocount, CAS .
ocount . snapshot next A 2^18 , ocount , ABA .
48 . 64- , , , ocount ( ), double cas.
Source: https://habr.com/ru/post/162187/
All Articles