Amazon SQS vs RabbitMQ
Introduction
Any progress and optimization is welcome by anyone. Today I would like to talk about a beautiful thing that makes life much easier - queues. Implementing the best practices in this matter not only improves the performance of the application, but also successfully prepares your application for the architecture “in the style” of Cloud Computing. Moreover, not using ready-made solutions from cloud providers is just silly.
In this article, we will look at Amazon Web Services in terms of designing the architecture of medium and large web applications.
Consider the scheme of such an application:
')
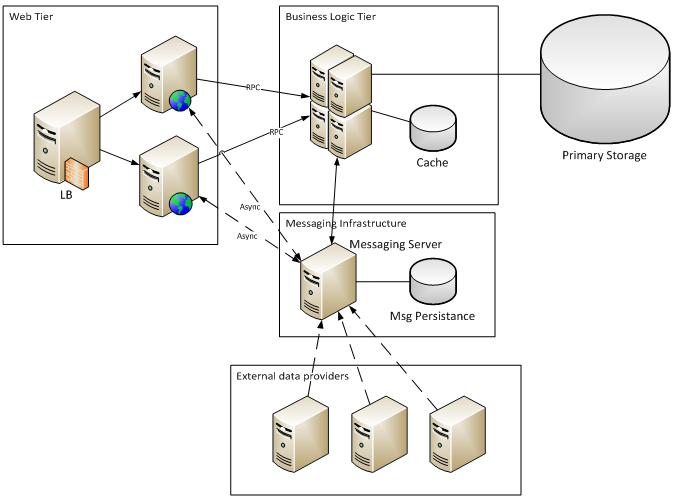
Examples of such an organization can be various kinds of aggregators: news, exchange rates, stock exchange quotes, etc.
External data providers generate a stream of messages that, while undergoing post-processing, are stored in the database.
Users through the web-tier do a sample of information from the database according to certain criteria (filters, grouping, sorting), and then optional processing of samples (various statistical functions).
Amazon tries to identify the most typical application components, then automates and provides a component service. Now there are more than two dozen of such services and the full list can be found on the AWS website: http://aws.amazon.com/products/ . On Habré already was an article describing a number of popular services: Popular about Amazon Web Services . This is attractive primarily because there is no need for independent installation and configuration, as well as higher reliability and piece-rate payment.
And if you use AWS, the project layout will look like this:
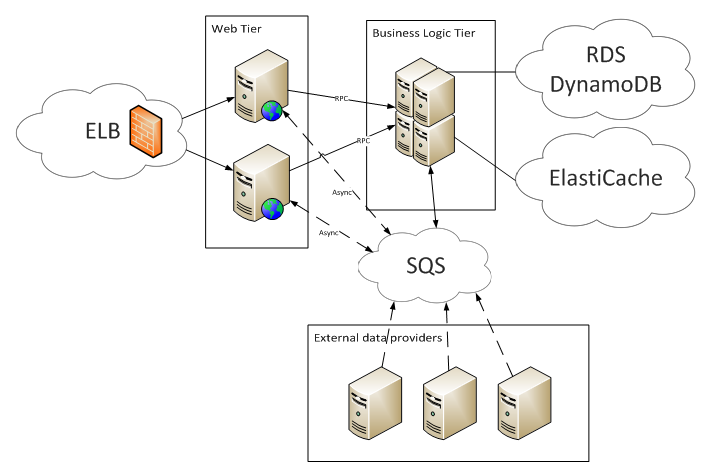
Undoubtedly, this approach is in demand and it has its own market. But often there are questions about the financial component:
- How much can you save using AWS?
- Is it possible to independently implement a service with the same properties, but for less money?
- Where is the line that separates AWS from its counterpart?
Next we will try to answer these questions.
1. Review of analogues
For comparison, we will consider the following components:
- Message-oriented middleware - RabbitMQ
- Analogue of the above service from AWS, which is called SQS
SQS service is paid based on the number of requests to the API + traffic
Consider each service in more detail.
1.1. SQS
Amazon SQS is a service that allows you to create and work with message queues. The standard cycle of working with the finished SQS queue is as follows:
- Producer to send a message to the queue must know its URL. Then, using the SendMessage command, adds the message.
- The consumer receives the message using the ReceiveMessag command.
- As soon as a message is received, it will be blocked to be re-received for a while.
- After processing the message successfully, Consumer uses the DeleteMessage command to remove the message from the queue. If an error occurred during processing or the DeleteMessage command was not called, the message will be returned to the queue after the timeout expires.
Thus, on average, 3 API calls are required to send and process a single message.
Using SQS, you pay for the number of API calls + traffic between regions. The cost of 10k calls is $ 0.01, i.e. on average, for 10k messages (x3 API call) you pay $ 0.03. Pricing in other regions you can see here .
There are many options for organizing the message sending service:
- RabbitMQ
- ActiveMQ
- ZMQ
- Openmq
- ejabbered (XMPP)
Each option has its pros and cons. We will choose RabbitMQ as one of the most popular implementation of the AMQP protocol.
1.2. RabbitMQ
1.2.1. Deployment Scheme
A server with RabbitMQ installed and defaults provides very good performance. But this variant of deployment does not suit us, because in the case of the fall of this node, we can immediately get a number of problems:
- Loss of important data in messages;
- "Accumulation" of information on Producer, which can lead to an overload of Consumer-s after restoring the work of the queue;
- Shut down the entire application while the problem is being resolved.
In testing, we will use 2 nodes in active-active mode with replication of queues between nodes. In RabbitMQ, this is called mirrored queues.
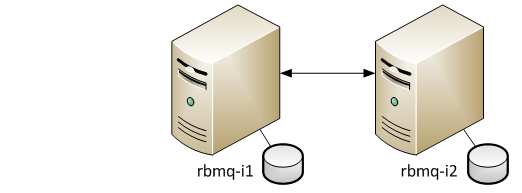
For each such queue, a master and a set of slaves is defined, where a copy of the queue is stored. In the case of the fall of the master node, one of the slaves is selected by the master.
To create such a queue, the “x-ha-policy” parameter is specified when declaring, which indicates where copies of the queue should be stored. 2 parameter values are possible.
- all: copies of the queue will be stored on all nodes in the cluster. When adding a new node to the cluster, a copy will be created on it;
- nodes: copies will be created only on the nodes specified by the “x-ha-policy-params” parameter.
You can read more about mirrored queues here: http://www.rabbitmq.com/ha.html .
1.2.2. Performance Measurement Technique
Earlier we examined how the test environment will be organized. Now let's consider what and how we will measure.
For all measurements m1.small instances (AWS) were used.
We will conduct a series of measurements:
The speed of sending messages to a certain value, then the speed of receiving - thus we will check the degradation of performance with an increase in the queue.
1. The speed of sending messages to a certain value, then the speed of receiving - thus we will check the performance degradation with increasing queue.
2. Simultaneous sending and receiving messages from one queue.
3. Simultaneous sending and receiving messages from different queues.
4. Asymmetric queue load:
- a. Send in a queue 10 times more threads than they accept;
- b. Receive from the queue 10 times more threads than send.
- a. 16 bytes;
- b. 1 kilobyte;
- c. 64 kilobytes (max for SQS).
All tests except the first will be conducted in 3 stages:
- Warming up for 2 seconds;
- Test run 15 seconds;
- Cleaning the queue.
Message Acknowledgment
This property is used to confirm the delivery and processing of a message. There are two modes of operation:
- Auto acknowledge - the message is considered successfully delivered immediately after it is sent to the recipient; in this mode, to receive one message, all you need is a single call to the server.
- Manual acknowledge - the message is considered successfully delivered after the recipient calls the appropriate command. This mode allows you to ensure guaranteed processing of the message, if you confirm delivery only after processing. In this mode, two calls to the server are required.
In the test, the second mode is selected, since it corresponds to the operation of SQS, where the processing of a message is done by two commands: ReceiveMessage and DeleteMessage.
Batch processing
In order not to waste time on each message to establish a connection, authorization, and other things, RabbitMQ and SQS allow processing messages in batches. This is available for both sending and receiving a message. Since batch processing is disabled by default in both RabbitMQ and SQS, we also will not use it for comparison.
1.2.3. Test results
Load-Unload Test
Summary results:
| Load-Unload Test | msg / s | Request time | ||||
| avg, ms | min, ms | max, ms | 90%, ms | |||
| SQS | Consume | 198 | 25 | 17 | 721 | 28 |
| Produce | 317 | sixteen | ten | 769 | 20 | |
| RabbitMQ | Consume | 1293 | 3 | 0 | 3716 | 3 |
| Produce | 1875 | 2 | 0 | 14785 | 0 | |
From the table it is clear that SQS works much more stable than RabbitMQ, in which dips can occur when sending a message for 15 seconds! Unfortunately, we could not immediately find the cause of this behavior, and in the test we try to adhere to the standard settings. At the same time, the average speed of RabbitMQ is about 6 times higher than that of SQS, and the query execution time is several times lower.
The following graphs with the distribution of the average speed depending on time.
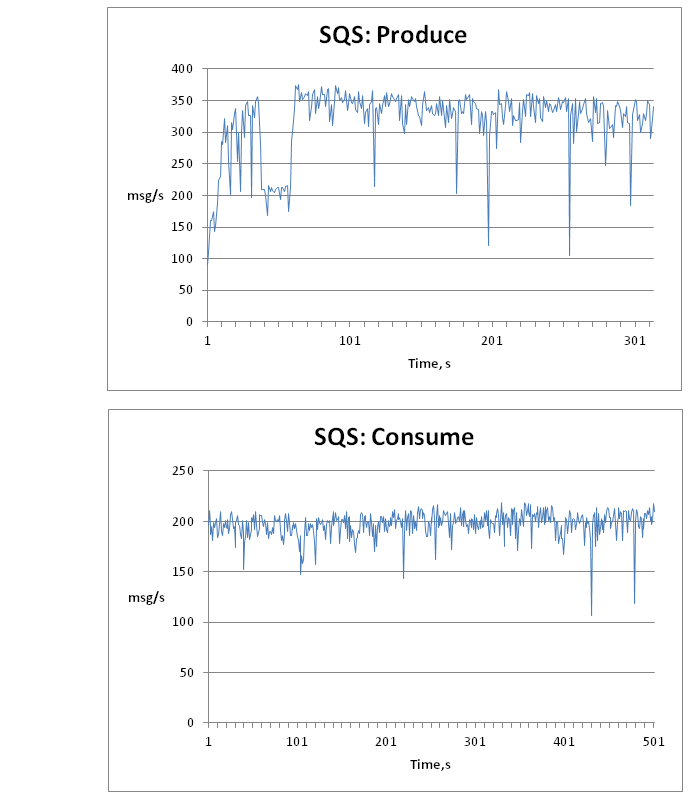
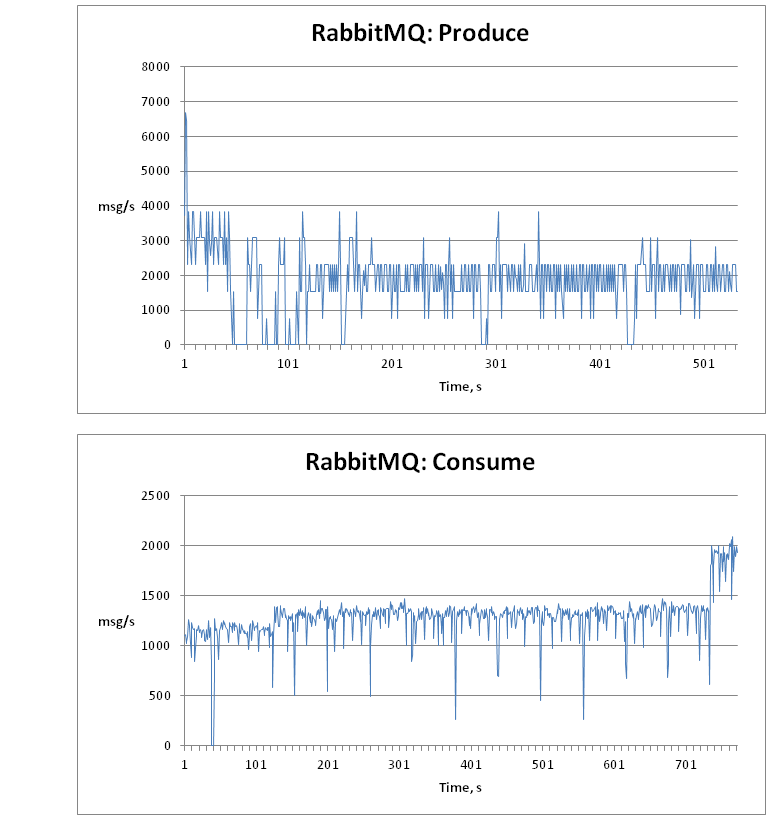
In general, there is no decrease in performance with an increase in the number of messages in the queue, which means you can not be afraid that if the receiving nodes fall, the queue will become a bottleneck.
Parallel
No less interesting is the test of the dependence of the speed of work on the number of simultaneously running threads. The results of the SQS test can be easily foreseen: since the work proceeds via the HTTP protocol and most of the time it takes to establish a connection, then, presumably, the results should increase with the number of threads, which is well illustrated by the following table:
| SQS msg / s | Threads | |||
| one | five | ten | 40 | |
| Produce | 65 | 324 | 641 | 969 |
| Consume | 33 | 186 | 333 | 435 |
It is also seen that for 1, 5 and 10 flows the dependence is linear, but with an increase to 40 flows, the average speed increases by 50% for sending and 30% for receiving, but the average query time significantly increases: 43ms and 98ms respectively.
For RabbitMQ, the saturation in speed occurs much faster; already at 5 streams the maximum is reached:
| RabbitMQ Threads | Threads | ||||
| one | five | ten | 40 | ||
| Produce | speed, msg / s | 3086 | 3157 | 3083 | 3200 |
| latency ms | 0 | one | 3 | eleven | |
| Consume | speed, msg / s | 272 | 811 | 820 | 798 |
| latency ms | 3 | 6 | 12 | 51 | |
During testing, a feature was discovered: if 1 stream for sending and 1 stream for receiving are working at the same time, the speed of receiving messages drops to almost 0, while the sending stream shows the maximum performance. The problem is solved by forcibly switching the context after each iteration of the test, while the sending bandwidth drops, but the upper limit of the query execution time is significantly reduced. From local tests at 1 stream (sending / reading): 11000/25 against 5000/1000.
Additionally, we conducted a test for RabbitMQ with several queues for 5 threads:
| RabbitMQ | Queues | |
| one | five | |
| Produce | 3157 | 3489 |
| Consume | 811 | 880 |
It can be seen that the speed for several queues is slightly higher. Summary results for 10 streams are presented in the following diagram:
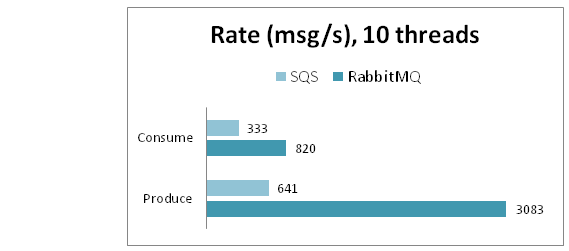
Size
In this test, we consider the dependence of the speed on the size of the transmitted data.
Both RabbitMQ and SQS showed an expected decrease in the speed of sending and receiving with increasing message size. In addition, the queue in RabbitMQ with the size of the message grows more often “freezes” and does not respond to requests. This indirectly confirms the conjecture that this is associated with working with a hard disk.
Comparative speed results:
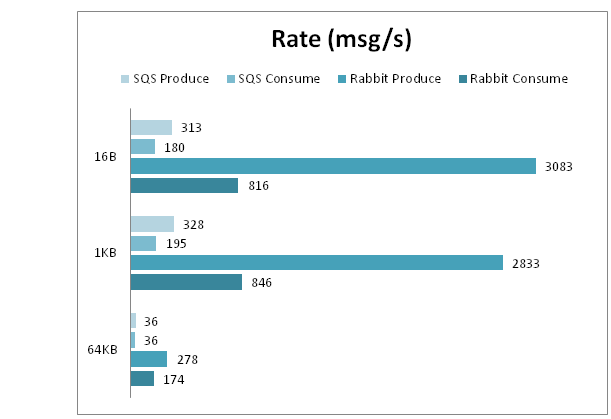
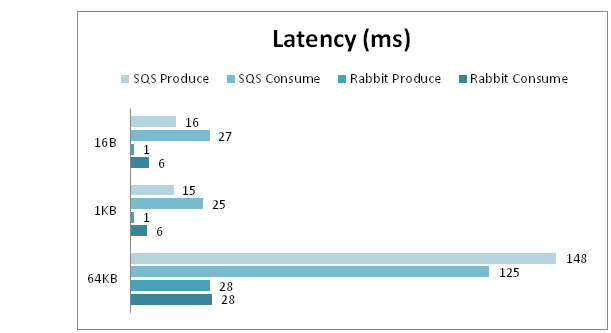
Comparative query time results:
2. Cost calculation and recommendations
From the estimated cost of $ 0.08 for one small instance in the European region, we get a cost of $ 0.16 for RabbitMQ in a two-node configuration + traffic cost. In SQS, the cost of sending and receiving 10,000 messages is $ 0.03. We get the following dependency:
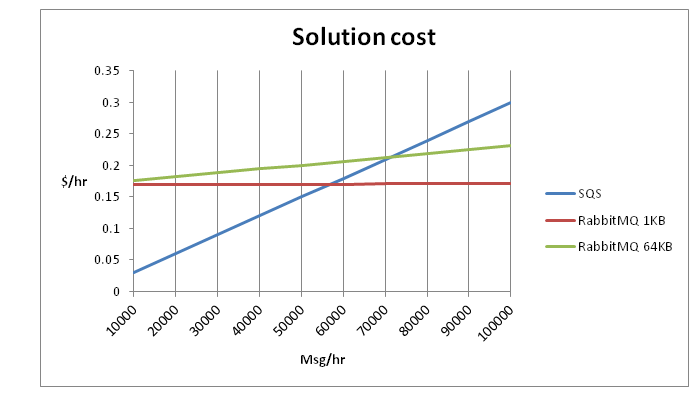
60 thousand messages per hour is about 17 messages per second, which is significantly less than the speed that SQS and RabbitMQ can provide.
Thus, if your application requires a speed of on average less than 17 messages per second, then SQS will be preferable. If the needs of the application become higher, then it is worth considering migration paths to dedicated messaging servers.
It is important to understand that these recommendations are valid only for average speeds, and calculations should be carried out throughout the entire cycle of the load oscillation, but if your application needs a much higher speed than the SQS allows, then this is also a reason to think about changing the provider.
Another reason to use RabbitMQ may be the latency request requirement, which is an order of magnitude lower than that of SQS.
2.1. Is it possible to reduce the cost of RabbitMQ solution?
There are two ways to reduce the cost:
- Do not use cluster.
- Use micro instance.
In the first case, the HA cluster is lost in the event of a node falling or the entire active zone, but it is not terrible if the entire application is hosted in only one zone.
In the second case, the micro instance can be cut back resources, if for some time the utilization of resources is close to 100%. This may affect the performance of the queue when the persistence queue is used.
3. Conclusion
Thus, we see that there is simply no unequivocal answer to the question “What solution should I use?” It all depends on many factors: the size of your wallet, the number of messages per second and the time of sending these messages. However, based on the metrics given in this material, it is possible to calculate the behavior for a particular case.
Thank!
The article is written and adapted based on the research of Maxim Bruner ( minim ), for EPAM Cloud Computing Competency Center
Source: https://habr.com/ru/post/161787/
All Articles