A frequency analyzer of English words written in python 3 that can normalize words using WordNet and translate using StarDict
Hello to all!
I learn English and simplify this process in every possible way. Somehow I needed to get a list of words along with the translation and transcription for a specific text. The task was not difficult, and I set to work. A little later, a python script was written, which is all able, and even able a little more, since I also wanted to get a frequency dictionary from all the files with English text inside. So a small set of scripts came out, which I would like to talk about.
The work of the script consists in parsing files, extracting English words, normalizing them, counting and issuing the first countWord words from the entire resulting list of English words.
In the final file, the word is written in the form:
[number of repetitions] [word itself] [translation of a word]
What will happen next:
I used python 3.3 and I must say more than once regretted that I did not write in python 2.7, because the necessary modules were often not enough.
So, let's start with a simple one, get the files, parse them into words, count, sort, and give the result.
To begin with we will make a regular expression for the search of English words in the text.
')
A simple English word, for example “over”, can be found using the expression "([a-zA-Z] +)" - here one or more letters of the English alphabet are searched for.
A compound word, for example “commander-in-chief”, is somewhat more difficult to find, we need to look for sub-expressions of the form “commander-”, “in-” that follow each other, followed by the word “chief”. The regular expression takes the form "(([a-zA-Z] + -?) * [A-zA-Z] +)" .
If an intermediate subexpression is present in the expression, it is also included in the result. So, our result includes not only the word “commander-in-chief”, but also all the found subexpressions. To exclude them, add at the beginning of the subexpression '?: ' To the rhinestone after the opening parenthesis. Then the regular expression takes the form "((?: [A-zA-Z] + -?) * [A-zA-Z] +)" . We still have to include words with an apostrophe like "did not" in expressions. For this we replace in the first subexpression "-?" on "[-']?" .
Everything, on it we will finish improvements of the regular expression, it could be improved and further, but we will stop on the such:
"((?: [a-zA-Z] + [- ']?) * [a-zA-Z] +)"
On this, in essence, work with a frequency dictionary could have been completed, but our work is just beginning. The thing is that the words in the text are written taking into account the grammatical rules, which means that the text may contain words with the endings ed, ing, and so on. In fact, even the forms of the verb to be (am, is, are) will be counted for different words.
So before the word is added to the word counter, you need to bring it to the correct form.
We turn to the second part - the writing of the English word normalizer .
There are two algorithms - stemming and lemmatization . Stemming refers to heuristic analysis, it does not use any databases. During lemmatization, various bases of words are used, and transformations are applied according to grammatical rules. We will use lemmatization for our purposes, since the error of the result is much less than with the stemming.
About lemmatization, there have already been several articles on Habré, for example, here and here . They use aot bases. I did not want to repeat myself, and it was also interesting to look for some other bases for lemmatization. I would like to tell you about WordNet , and we will build a lemmatizer on it. To begin with, on the official WordNet website you can download the source code of the program and the databases themselves. WordNet can do a lot, but we need only a small part of its capabilities - the normalization of words.
We need only databases. The WordNet source code (in C) describes the normalization process itself, in essence, I took the algorithm from there, rewriting it in python. Oh yes, of course for WordNet there is a library for python - nltk , but firstly, it only works on python 2.7, and secondly, how quickly I looked, during normalization, only requests are sent to the WordNet server.
General class diagram for a lemmatizer:
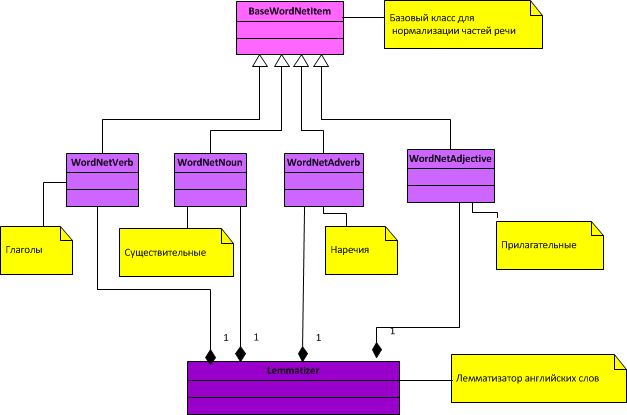
As can be seen from the diagram, only 4 parts of speech (nouns, verbs, adjectives and adverbs) are normalized.
Briefly describe the normalization process, it is as follows:
1. For each part of speech, 2 files are loaded from WordNet - an index dictionary (it has an index name and an extension according to a part of speech, for example, index.adv for adverbs) and an exclusion file (it has an exc extension and a name according to a part of speech, for example adv.exc for adverbs).
2. During normalization, the array of exceptions is first checked, if the word is there, its normalized form is returned. If the word is not an exception, then the word ghost begins according to grammatical rules, that is, the ending is cut off, a new ending is pasted, then the word is searched for in the indexed array, and if it is there, then the word is considered normalized. Otherwise, the following rule applies, and so on, until the rules end or the word is normalized earlier.
Classes for lemmalizator:
Well, with the normalization finished. Now the frequency analyzer is able to normalize words. We proceed to the last part of our task - receiving translations and transcriptions for English words.
You can write about StarDict for a long time, but the main advantage of this format is that there are a lot of vocabulary databases for it, in almost all languages. On Habré there were no articles on StarDict yet and it is time to fill this gap. The file that describes the StarDict format is usually located next to the sources themselves.
If we discard all the additions, then the most minimal set of knowledge on this format will be as follows:
Each dictionary must contain 3 required files:
1. File with ifo extension - contains a consistent description of the dictionary itself;
2. File with idx extension. Each entry inside the idx file consists of 3 fields, one after the other:
3. File with the dict extension - contains the translations themselves, which can be reached by knowing the offset to the translation (the offset is recorded in the idx file).
Without long thinking about which classes should end up, I created one class for each of the files, and one general StarDict class that unites them.
The resulting class diagram is:

Classes for StarDict translator:
Well, the translator is ready. Now we just have to combine the frequency analyzer, the word normalizer and the translator. Let's create the main main.py file and the Settings.ini file.
The only third-party library that you need to download and deliver additionally is xlwt , it will be required to create an Excel file (the result is written there).
In the Settings.ini settings file for the PathToStarDict variable, you can write several dictionaries with a ";". In this case, the words will be searched in the order of priority of the dictionaries - if the word is found in the first dictionary, the search ends, otherwise all the other StarDict dictionaries are searched.
All source codes described in this article can be downloaded on github .
Reminder:
I learn English and simplify this process in every possible way. Somehow I needed to get a list of words along with the translation and transcription for a specific text. The task was not difficult, and I set to work. A little later, a python script was written, which is all able, and even able a little more, since I also wanted to get a frequency dictionary from all the files with English text inside. So a small set of scripts came out, which I would like to talk about.
The work of the script consists in parsing files, extracting English words, normalizing them, counting and issuing the first countWord words from the entire resulting list of English words.
In the final file, the word is written in the form:
[number of repetitions] [word itself] [translation of a word]
What will happen next:
- We will start by getting a list of English words from a file (using regular expressions );
- Then we begin to normalize the words, that is, to bring them from the natural form into the form in which they are stored in dictionaries (here we will study the WordNet format a little);
- Then we calculate the number of occurrences of all normalized words (this is quick and easy);
- Next, we delve into the StarDict format, because it is through it that we will get translations and transcriptions.
- Well, at the very end we will write down the result somewhere (I chose an Excel file).
I used python 3.3 and I must say more than once regretted that I did not write in python 2.7, because the necessary modules were often not enough.
Frequency analyzer.
So, let's start with a simple one, get the files, parse them into words, count, sort, and give the result.
To begin with we will make a regular expression for the search of English words in the text.
')
Regular expression to search for English words
A simple English word, for example “over”, can be found using the expression "([a-zA-Z] +)" - here one or more letters of the English alphabet are searched for.
A compound word, for example “commander-in-chief”, is somewhat more difficult to find, we need to look for sub-expressions of the form “commander-”, “in-” that follow each other, followed by the word “chief”. The regular expression takes the form "(([a-zA-Z] + -?) * [A-zA-Z] +)" .
If an intermediate subexpression is present in the expression, it is also included in the result. So, our result includes not only the word “commander-in-chief”, but also all the found subexpressions. To exclude them, add at the beginning of the subexpression '?: ' To the rhinestone after the opening parenthesis. Then the regular expression takes the form "((?: [A-zA-Z] + -?) * [A-zA-Z] +)" . We still have to include words with an apostrophe like "did not" in expressions. For this we replace in the first subexpression "-?" on "[-']?" .
Everything, on it we will finish improvements of the regular expression, it could be improved and further, but we will stop on the such:
"((?: [a-zA-Z] + [- ']?) * [a-zA-Z] +)"
The implementation of the frequency analyzer English words
We will write a small class that can extract English words, count them and produce a result.
# -*- coding: utf-8 -*- import re import os from collections import Counter class FrequencyDict: def __init__(): # self.wordPattern = re.compile("((?:[a-zA-Z]+[-']?)*[a-zA-Z]+)") # ( collections.Counter ) self.frequencyDict = Counter() # , def ParseBook(self, file): if file.endswith(".txt"): self.__ParseTxtFile(file, self.__FindWordsFromContent) else: print('Warning: The file format is not supported: "%s"' %file) # txt def __ParseTxtFile(self, txtFile, contentHandler): try: with open(txtFile, 'rU') as file: for line in file: # contentHandler(line) # except Exception as e: print('Error parsing "%s"' % txtFile, e) # def __FindWordsFromContent(self, content): result = self.wordPattern.findall(content) # for word in result: word = word.lower() # self.frequencyDict[word] += 1 # # countWord , def FindMostCommonElements(self, countWord): dict = list(self.frequencyDict.items()) dict.sort(key=lambda t: t[0]) dict.sort(key=lambda t: t[1], reverse = True) return dict[0 : int(countWord)] On this, in essence, work with a frequency dictionary could have been completed, but our work is just beginning. The thing is that the words in the text are written taking into account the grammatical rules, which means that the text may contain words with the endings ed, ing, and so on. In fact, even the forms of the verb to be (am, is, are) will be counted for different words.
So before the word is added to the word counter, you need to bring it to the correct form.
We turn to the second part - the writing of the English word normalizer .
English lemmatizer
There are two algorithms - stemming and lemmatization . Stemming refers to heuristic analysis, it does not use any databases. During lemmatization, various bases of words are used, and transformations are applied according to grammatical rules. We will use lemmatization for our purposes, since the error of the result is much less than with the stemming.
About lemmatization, there have already been several articles on Habré, for example, here and here . They use aot bases. I did not want to repeat myself, and it was also interesting to look for some other bases for lemmatization. I would like to tell you about WordNet , and we will build a lemmatizer on it. To begin with, on the official WordNet website you can download the source code of the program and the databases themselves. WordNet can do a lot, but we need only a small part of its capabilities - the normalization of words.
We need only databases. The WordNet source code (in C) describes the normalization process itself, in essence, I took the algorithm from there, rewriting it in python. Oh yes, of course for WordNet there is a library for python - nltk , but firstly, it only works on python 2.7, and secondly, how quickly I looked, during normalization, only requests are sent to the WordNet server.
General class diagram for a lemmatizer:
As can be seen from the diagram, only 4 parts of speech (nouns, verbs, adjectives and adverbs) are normalized.
Briefly describe the normalization process, it is as follows:
1. For each part of speech, 2 files are loaded from WordNet - an index dictionary (it has an index name and an extension according to a part of speech, for example, index.adv for adverbs) and an exclusion file (it has an exc extension and a name according to a part of speech, for example adv.exc for adverbs).
2. During normalization, the array of exceptions is first checked, if the word is there, its normalized form is returned. If the word is not an exception, then the word ghost begins according to grammatical rules, that is, the ending is cut off, a new ending is pasted, then the word is searched for in the indexed array, and if it is there, then the word is considered normalized. Otherwise, the following rule applies, and so on, until the rules end or the word is normalized earlier.
Classes for lemmalizator:
Base class for parts of speech BaseWordNetItem.py
# -*- coding: utf-8 -*- import os class BaseWordNetItem: # def __init__(self, pathWordNetDict, excFile, indexFile): self.rule=() # . self.wordNetExcDict={} # self.wordNetIndexDict=[] # self.excFile = os.path.join(pathWordNetDict, excFile) # self.indexFile = os.path.join(pathWordNetDict, indexFile) # self.__ParseFile(self.excFile, self.__AppendExcDict) # self.__ParseFile(self.indexFile, self.__AppendIndexDict) # self.cacheWords={} # . , - , - # . # : [-][][] def __AppendExcDict(self, line): # , 2 ( - , - ). group = [item.strip() for item in line.replace("\n","").split(" ")] self.wordNetExcDict[group[0]] = group[1] # . def __AppendIndexDict(self, line): # group = [item.strip() for item in line.split(" ")] self.wordNetIndexDict.append(group[0]) # , , def __ParseFile(self, file, contentHandler): try: with open(file, 'r') as openFile: for line in openFile: contentHandler(line) # except Exception as e: raise Exception('File does not load: "%s"' %file) # . , . # def _GetDictValue(self, dict, key): try: return dict[key] except KeyError: return None # , True, False. # , , , ( ). def _IsDefined(self, word): if word in self.wordNetIndexDict: return True return False # ( ) def GetLemma(self, word): word = word.strip().lower() # if word == None: return None # , lemma = self._GetDictValue(self.cacheWords, word) if lemma != None: return lemma # , , if self._IsDefined(word): return word # , , lemma = self._GetDictValue(self.wordNetExcDict, word) if lemma != None: return lemma # , , . lemma = self._RuleNormalization(word) if lemma != None: self.cacheWords[word] = lemma # return lemma return None # ( , ) def _RuleNormalization(self, word): # , , , . for replGroup in self.rule: endWord = replGroup[0] if word.endswith(endWord): lemma = word # lemma = lemma.rstrip(endWord) # lemma += replGroup[1] # if self._IsDefined(lemma): # , , , return lemma return None Class for the normalization of verbs WordNetVerb.py
# -*- coding: utf-8 -*- from WordNet.BaseWordNetItem import BaseWordNetItem # # BaseWordNetItem class WordNetVerb(BaseWordNetItem): def __init__(self, pathToWordNetDict): # (BaseWordNetItem) BaseWordNetItem.__init__(self, pathToWordNetDict, 'verb.exc', 'index.verb') # . , "s" "" , "ies" "y" . self.rule = ( ["s" , "" ], ["ies" , "y" ], ["es" , "e" ], ["es" , "" ], ["ed" , "e" ], ["ed" , "" ], ["ing" , "e" ], ["ing" , "" ] ) # GetLemma(word) BaseWordNetItem Class for the normalization of nouns WordNetNoun.py
# -*- coding: utf-8 -*- from WordNet.BaseWordNetItem import BaseWordNetItem # # BaseWordNetItem class WordNetNoun(BaseWordNetItem): def __init__(self, pathToWordNetDict): # (BaseWordNetItem) BaseWordNetItem.__init__(self, pathToWordNetDict, 'noun.exc', 'index.noun') # . , "s" "", "ses" "s" . self.rule = ( ["s" , "" ], ["'s" , "" ], ["'" , "" ], ["ses" , "s" ], ["xes" , "x" ], ["zes" , "z" ], ["ches" , "ch" ], ["shes" , "sh" ], ["men" , "man" ], ["ies" , "y" ] ) # ( ) # BaseWordNetItem, , # def GetLemma(self, word): word = word.strip().lower() # , if len(word) <= 2: return None # "ss", if word.endswith("ss"): return None # , lemma = self._GetDictValue(self.cacheWords, word) if lemma != None: return lemma # , , if self._IsDefined(word): return word # , , lemma = self._GetDictValue(self.wordNetExcDict, word) if (lemma != None): return lemma # "ful", "ful", , . # , , "spoonsful" "spoonful" suff = "" if word.endswith("ful"): word = word[:-3] # "ful" suff = "ful" # "ful", # , , . lemma = self._RuleNormalization(word) if (lemma != None): lemma += suff # "ful", self.cacheWords[word] = lemma # return lemma return None Class for the normalization of adverbs WordNetAdverb.py
# -*- coding: utf-8 -*- from WordNet.BaseWordNetItem import BaseWordNetItem # # BaseWordNetItem class WordNetAdverb(BaseWordNetItem): def __init__(self, pathToWordNetDict): # (BaseWordNetItem) BaseWordNetItem.__init__(self, pathToWordNetDict, 'adv.exc', 'index.adv') # (adv.exc) (index.adv). # . Class for the normalization of adjectives WordNetAdjective.py
# -*- coding: utf-8 -*- from WordNet.BaseWordNetItem import BaseWordNetItem # # BaseWordNetItem class WordNetAdjective(BaseWordNetItem): def __init__(self, pathToWordNetDict): # (BaseWordNetItem) BaseWordNetItem.__init__(self, pathToWordNetDict, 'adj.exc', 'index.adj') # . , "er" "" "e" . self.rule = ( ["er" , "" ], ["er" , "e"], ["est" , "" ], ["est" , "e"] ) # GetLemma(word) BaseWordNetItem Lemmatizer class Lemmatizer.py
# -*- coding: utf-8 -*- from WordNet.WordNetAdjective import WordNetAdjective from WordNet.WordNetAdverb import WordNetAdverb from WordNet.WordNetNoun import WordNetNoun from WordNet.WordNetVerb import WordNetVerb class Lemmatizer: def __init__(self, pathToWordNetDict): # self.splitter = "-" # adj = WordNetAdjective(pathToWordNetDict) # noun = WordNetNoun(pathToWordNetDict) # adverb = WordNetAdverb(pathToWordNetDict) # verb = WordNetVerb(pathToWordNetDict) # self.wordNet = [verb, noun, adj, adverb] # (, ) def GetLemma(self, word): # , , ( ) , wordArr = word.split(self.splitter) resultWord = [] for word in wordArr: lemma = self.__GetLemmaWord(word) if (lemma != None): resultWord.append(lemma) if (resultWord != None): return self.splitter.join(resultWord) return None # ( ) def __GetLemmaWord(self, word): for item in self.wordNet: lemma = item.GetLemma(word) if (lemma != None): return lemma return None Well, with the normalization finished. Now the frequency analyzer is able to normalize words. We proceed to the last part of our task - receiving translations and transcriptions for English words.
Translator of foreign words using StarDict dictionaries
You can write about StarDict for a long time, but the main advantage of this format is that there are a lot of vocabulary databases for it, in almost all languages. On Habré there were no articles on StarDict yet and it is time to fill this gap. The file that describes the StarDict format is usually located next to the sources themselves.
If we discard all the additions, then the most minimal set of knowledge on this format will be as follows:
Each dictionary must contain 3 required files:
1. File with ifo extension - contains a consistent description of the dictionary itself;
2. File with idx extension. Each entry inside the idx file consists of 3 fields, one after the other:
- word_str - A string in the utf-8 format, ending with '\ 0';
- word_data_offset — Offset before entry in the .dict file (32 or 64 bits);
- word_data_size - The size of the entire entry in the .dict file.
3. File with the dict extension - contains the translations themselves, which can be reached by knowing the offset to the translation (the offset is recorded in the idx file).
Without long thinking about which classes should end up, I created one class for each of the files, and one general StarDict class that unites them.
The resulting class diagram is:
Classes for StarDict translator:
Base class for BaseStarDictItem.py dictionary items
# -*- coding: utf-8 -*- import os class BaseStarDictItem: def __init__(self, pathToDict, exp): # self.encoding = "utf-8" # self.dictionaryFile = self.__PathToFileInDirByExp(pathToDict, exp) # self.realFileSize = os.path.getsize(self.dictionaryFile) # path exp def __PathToFileInDirByExp(self, path, exp): if not os.path.exists(path): raise Exception('Path "%s" does not exists' % path) end = '.%s'%(exp) list = [f for f in os.listdir(path) if f.endswith(end)] if list: return os.path.join(path, list[0]) # else: raise Exception('File does not exist: "*.%s"' % exp) Class ifo.py
# -*- coding: utf-8 -*- from StarDict.BaseStarDictItem import BaseStarDictItem from Frequency.IniParser import IniParser class Ifo(BaseStarDictItem): def __init__(self, pathToDict): # (BaseStarDictItem) BaseStarDictItem.__init__(self, pathToDict, 'ifo') # self.iniParser = IniParser(self.dictionaryFile) # ifo # , self.bookName = self.__getParameterValue("bookname", None) # [ ] self.wordCount = self.__getParameterValue("wordcount", None) # ".idx" [ ] self.synWordCount = self.__getParameterValue("synwordcount", "") # ".syn" [ , ".syn"] self.idxFileSize = self.__getParameterValue("idxfilesize", None) # ( ) ".idx" . , [ ] self.idxOffsetBits = self.__getParameterValue("idxoffsetbits", 32) # (32 64), .dict. 3.0.0, 32 [ ] self.author = self.__getParameterValue("author", "") # [ ] self.email = self.__getParameterValue("email", "") # [ ] self.description = self.__getParameterValue("description", "") # [ ] self.date = self.__getParameterValue("date", "") # [ ] self.sameTypeSequence = self.__getParameterValue("sametypesequence", None) # , [ ] self.dictType = self.__getParameterValue("dicttype", "") # , WordNet[ ] def __getParameterValue(self, key, defaultValue): try: return self.iniParser.GetValue(key) except: if defaultValue != None: return defaultValue raise Exception('\n"%s" has invalid format (missing parameter: "%s")' % (self.dictionaryFile, key)) Class Idx.py
# -*- coding: utf-8 -*- from struct import unpack from StarDict.BaseStarDictItem import BaseStarDictItem class Idx(BaseStarDictItem): # def __init__(self, pathToDict, wordCount, idxFileSize, idxOffsetBits): # (BaseStarDictItem) BaseStarDictItem.__init__(self, pathToDict, 'idx') self.idxDict ={} # , self.idxDict = {'.': [_____dict, _____dict], ...} self.idxFileSize = int(idxFileSize) # .idx, .ifo self.idxOffsetBytes = int(idxOffsetBits/8) # , .dict. self.wordCount = int(wordCount) # ".idx" # ( .ifo .idx [idxfilesize] ) self.__CheckRealFileSize() # self.idxDict .idx self.__FillIdxDict() # ( .ifo [wordcount] .idx ) self.__CheckRealWordCount() # , .ifo , def __CheckRealFileSize(self): if self.realFileSize != self.idxFileSize: raise Exception('size of the "%s" is incorrect' %self.dictionaryFile) # , .ifo , .idx def __CheckRealWordCount(self): realWordCount = len(self.idxDict) if realWordCount != self.wordCount: raise Exception('word count of the "%s" is incorrect' %self.dictionaryFile) # , def __getIntFromByteArray(self, sizeInt, stream): byteArray = stream.read(sizeInt) # , # formatCharacter = 'L' # "unsigned long" ( sizeInt = 4) if sizeInt == 8: formatCharacter = 'Q' # "unsigned long long" ( sizeInt = 8) format = '>' + formatCharacter # : " " + " " # '>' - , int( formatCharacter) . integer = (unpack(format, byteArray))[0] # return int(integer) # .idx ( 3- ) self.idxDict def __FillIdxDict(self): languageWord = "" with open(self.dictionaryFile, 'rb') as stream: while True: byte = stream.read(1) # if not byte: break # , if byte != b'\0': # '\0', languageWord += byte.decode("utf-8") else: # '\0', , (" dict" " dict") wordDataOffset = self.__getIntFromByteArray(self.idxOffsetBytes, stream) # " dict" wordDataSize = self.__getIntFromByteArray(4, stream) # " dict" self.idxDict[languageWord] = [wordDataOffset, wordDataSize] # self.idxDict : + + languageWord = "" # , # .dict (" dict" " dict"). # , None def GetLocationWord(self, word): try: return self.idxDict[word] except KeyError: return [None, None] Class Dict.py
# -*- coding: utf-8 -*- from StarDict.BaseStarDictItem import BaseStarDictItem # ( , sametypesequence = tm). # -x ( utf-8, '\0'): # 'm' - utf-8, '\0' # 'l' - utf-8, '\0' # 'g' - Pango # 't' - utf-8, '\0' # 'x' - utf-8, xdxf # 'y' - utf-8, (YinBiao) (KANA) # 'k' - utf-8, KingSoft PowerWord XML # 'w' - MediaWiki # 'h' - Html # 'n' - WordNet # 'r' - . (jpg), (wav), (avi), (bin) . # 'W' - wav # 'P' - # 'X' - class Dict(BaseStarDictItem): def __init__(self, pathToDict, sameTypeSequence): # (BaseStarDictItem) BaseStarDictItem.__init__(self, pathToDict, 'dict') # , self.sameTypeSequence = sameTypeSequence def GetTranslation(self, wordDataOffset, wordDataSize): try: # .dict self.__CheckValidArguments(wordDataOffset, wordDataSize) # .dict with open(self.dictionaryFile, 'rb') as file: # file.seek(wordDataOffset) # , byteArray = file.read(wordDataSize) # , return byteArray.decode(self.encoding) # o (self.encoding BaseDictionaryItem) except Exception: return None def __CheckValidArguments(self, wordDataOffset, wordDataSize): if wordDataOffset is None: pass if wordDataOffset < 0: pass endDataSize = wordDataOffset + wordDataSize if wordDataOffset < 0 or wordDataSize < 0 or endDataSize > self.realFileSize: raise Exception Well, the translator is ready. Now we just have to combine the frequency analyzer, the word normalizer and the translator. Let's create the main main.py file and the Settings.ini file.
Main file main.py
# -*- coding: utf-8 -*- import os import xlwt3 as xlwt from Frequency.IniParser import IniParser from Frequency.FrequencyDict import FrequencyDict from StarDict.StarDict import StarDict ConfigFileName="Settings.ini" class Main: def __init__(self): self.listLanguageDict = [] # StarDict self.result = [] # ( , , ) try: # - config = IniParser(ConfigFileName) self.pathToBooks = config.GetValue("PathToBooks") # ini PathToBooks, (, ), self.pathResult = config.GetValue("PathToResult") # ini PathToResult, self.countWord = config.GetValue("CountWord") # ini CountWord, , self.pathToWordNetDict = config.GetValue("PathToWordNetDict") # ini PathToWordNetDict, WordNet self.pathToStarDict = config.GetValue("PathToStarDict") # ini PathToStarDict, StarDict # StarDict . listPathToStarDict listPathToStarDict = [item.strip() for item in self.pathToStarDict.split(";")] # StarDict for path in listPathToStarDict: languageDict = StarDict(path) self.listLanguageDict.append(languageDict) # , self.listBooks = self.__GetAllFiles(self.pathToBooks) # self.frequencyDict = FrequencyDict(self.pathToWordNetDict) # , StarDict WordNet. , , self.__Run() except Exception as e: print('Error: "%s"' %e) # , path def __GetAllFiles(self, path): try: return [os.path.join(path, file) for file in os.listdir(path)] except Exception: raise Exception('Path "%s" does not exists' % path) # , . , def __GetTranslate(self, word): valueWord = "" for dict in self.listLanguageDict: valueWord = dict.Translate(word) if valueWord != "": return valueWord return valueWord # ( , , ) countWord Excel def __SaveResultToExcel(self): try: if not os.path.exists(self.pathResult): raise Exception('No such directory: "%s"' %self.pathResult) if self.result: description = 'Frequency Dictionary' style = xlwt.easyxf('font: name Times New Roman') wb = xlwt.Workbook() ws = wb.add_sheet(description + ' ' + self.countWord) nRow = 0 for item in self.result: ws.write(nRow, 0, item[0], style) ws.write(nRow, 1, item[1], style) ws.write(nRow, 2, item[2], style) nRow +=1 wb.save(os.path.join(self.pathResult, description +'.xls')) except Exception as e: print(e) # def __Run(self): # for book in self.listBooks: self.frequencyDict.ParseBook(book) # countWord mostCommonElements = self.frequencyDict.FindMostCommonElements(self.countWord) # for item in mostCommonElements: word = item[0] counterWord = item[1] valueWord = self.__GetTranslate(word) self.result.append([counterWord, word, valueWord]) # Excel self.__SaveResultToExcel() if __name__ == "__main__": main = Main() Settings.ini settings file
; (, ), PathToBooks = e:\Bienne\Frequency\Books ; WordNet( ) PathToWordNetDict = e:\Bienne\Frequency\WordNet\wn3.1.dict\ ; StarDict( ) PathToStarDict = e:\Bienne\Frequency\Dict\stardict-comn_dictd04_korolew ; , Excel CountWord = 100 ; , ( Excel - , , ) PathToResult = e:\Bienne\Frequency\Books The only third-party library that you need to download and deliver additionally is xlwt , it will be required to create an Excel file (the result is written there).
In the Settings.ini settings file for the PathToStarDict variable, you can write several dictionaries with a ";". In this case, the words will be searched in the order of priority of the dictionaries - if the word is found in the first dictionary, the search ends, otherwise all the other StarDict dictionaries are searched.
Afterword
All source codes described in this article can be downloaded on github .
Reminder:
- The scripts were written under windows ;
- Used for python 3.3 ;
- Additionally, you will need to put the xlwt library to work with Excel;
- Separately, you need to download dictionary databases for WordNet and StarDict (for StarDict dictionaries, you will need to additionally unpack files packed into the archive with the dict extension);
- In the Settings.ini file you need to register paths for dictionaries and where to save the result.
- , StarDict, ( ).
Source: https://habr.com/ru/post/161073/
All Articles