What is an in-memory data grid
In-memory data processing has been a rather widely discussed topic lately. Many companies, which in the past would not consider using in-memory technologies because of the high cost, are now rebuilding the architecture of their information systems to take advantage of the rapid transactional processing of data offered by these solutions. This is a consequence of the rapid fall in the cost of RAM (RAM), as a result of which it becomes possible to store the entire set of operational data in memory, increasing their processing speed by more than 1000 times. In-Memory Compute Grid and In-Memory Data Grid products provide the necessary tools for building such solutions.
The task of the In-Memory Data Grid ( IMDG ) is to provide ultra-high availability of data by storing them in RAM in a distributed state. Modern IMDGs are able to satisfy most requirements for processing large data sets.
Simplified, IMDG is a distributed storage of objects, similar in interface to a conventional multi-threaded hash table. You store objects by keys. But, unlike traditional systems, in which keys and values are limited to the data types “array of bytes” and “string”, in IMDG you can use any object from your business model as a key or value. This will greatly increase flexibility, allowing you to store in the Data Grid exactly the object your business logic works with, without the additional serialization / de-serialization required by alternative technologies. It also makes it easier to use your Data Grid, since in most cases you can work with a distributed data store as you would with a regular hash table. The ability to work with objects from the business model directly is one of the main differences between IMDG and In-Memory databases ( IMDB ). In the latter case, users are still forced to perform an object-relational mapping (Object-To-Relational Mapping), which, as a rule, leads to a significant decrease in performance.
There are other functional features that distinguish IMDG from other products, such as IMDB, NoSql or NewSql database. One of the main points is truly scalable data partitioning in a cluster. IMDG is essentially a distributed hash table, where each key is stored on a strictly defined server in a cluster. The larger the cluster, the more data can be stored in it. Fundamentally important in this architecture is that data should be processed on the same server where they are located (locally), eliminating (or minimizing) their movement across the cluster. In fact, when using a well-designed IMDG, data movement will be completely absent unless new servers are added to the cluster or existing servers are deleted, thereby changing the cluster topology and data distribution in it.
')
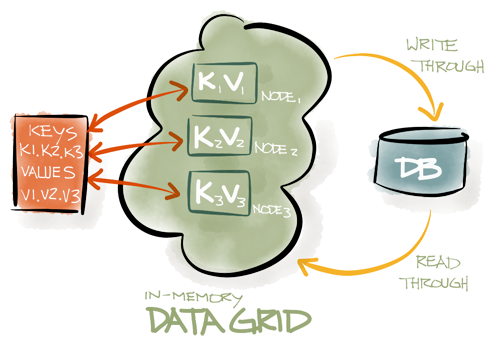
The diagram below shows a classic IMDG with a set of keys {k1, k2, k3}, in which each key belongs to a separate server. An external database is optional. If it is present, IMDG will usually automatically read data from the database or write it to it.
Another distinctive feature of IMDG is the support of transactionality that meets the requirements of ACID ( atomicity, consistency, isolation, durability - atomicity, integrity, isolation, preservation ). As a rule, in order to guarantee the integrity of data in a cluster, two-phase commit (2-phase-commit or 2PC) is used. Different IMDGs can have different locking mechanisms, but the most advanced implementations typically use parallel locks (for example, GridGain uses MVCC - multi-version concurrency control, concurrency control using multi-versioning), thus minimizing network exchange and ensuring transactional ACID integrity with high performance.
Data integrity is one of the main differences between IMDG and NoSQL databases. NoSQL databases, in most cases, are designed using an approach called “ integrity ultimately ” ( Eventual Consistency, EC ), in which data may be in an inconsistent state for some time, but will necessarily become consistent * with time *. In general, write operations in EC systems are quite fast compared to slower read operations (more precisely, not exceeding the speed of a write operation). The latest IMDGs with * optimized * 2PC at least correspond to EC systems in writing speed (if they are not ahead of them), and significantly outperform them in reading speed. Interestingly, the industry made a full circle, moving from the then slow 2PC to the EC, and now from the EC to the much faster * optimized * 2PC.
Different products may offer different 2PC optimizations, but in general, the objectives of all optimizations are to increase concurrency, minimize network traffic, and reduce the number of locks required to complete a transaction. For example, Google’s distributed global Spanner database is based on a transactional 2PC approach simply because 2PC provided a faster and easier way to guarantee data integrity and high throughput compared to MapReduce or EC.
Even though different IMDGs usually have a lot of common basic functionality, there are many additional features and implementation details that differ depending on the manufacturer. When evaluating the IMDG product, pay attention to eviction policies, data loading techniques, including, when the server starts ((pre) loading techniques), parallel partitioning (concurrent repartitioning), the amount of additional memory required for storage records (data overhead), and the like. Also, pay attention to the ability to make queries (query) in the cache at run time. Some IMDGs, for example, GridGain , allow users to query data stored in memory using standard SQL with support for distributed join-ovs (distributed joins) , which is quite a rarity.
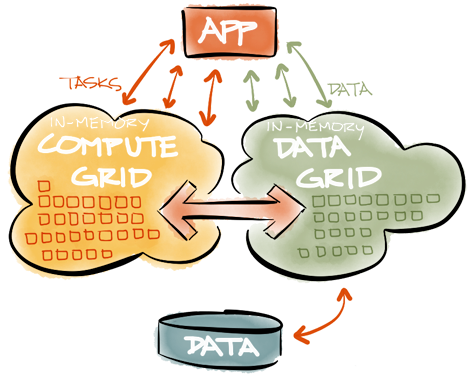
Data storage in the IMDG is only half the functionality required for an in-memory architecture. Data stored in the IMDG must also be processed in parallel and at high speed. A typical in-memory architecture partitions the data in a cluster using IMDG, and then the executable code is sent to the exact server where the data it needs is located. Since the executable code (computational task) is usually part of the computing clusters (Compute Grids) , it must be deployed properly (deployment), balanced by load (load-balancing), have fault tolerance ( fail-over ), and also be able to run on a schedule ( scheduling ), the integration between the Compute Grid and the IMDG is very important . The greatest effect can be obtained if IMDG and Compute Grid are parts of the same product and use the same API. This removes the burden of integration from the developer and usually allows to achieve the highest performance and reliability of the in-memory solution.
IMDG (along with Compute Grid) find their application in many areas, such as risk analysis (Risk Analytics), trading systems (Trading Systems), real-time anti-fraud systems (Fraud Detection), biometrics (Biometrics), e-commerce ( eCommerce), online games (Online Gaming). In fact, any product that faces scalability and performance issues can benefit from the use of In-Memory Processing and IMDG architecture.
The task of the In-Memory Data Grid ( IMDG ) is to provide ultra-high availability of data by storing them in RAM in a distributed state. Modern IMDGs are able to satisfy most requirements for processing large data sets.
Simplified, IMDG is a distributed storage of objects, similar in interface to a conventional multi-threaded hash table. You store objects by keys. But, unlike traditional systems, in which keys and values are limited to the data types “array of bytes” and “string”, in IMDG you can use any object from your business model as a key or value. This will greatly increase flexibility, allowing you to store in the Data Grid exactly the object your business logic works with, without the additional serialization / de-serialization required by alternative technologies. It also makes it easier to use your Data Grid, since in most cases you can work with a distributed data store as you would with a regular hash table. The ability to work with objects from the business model directly is one of the main differences between IMDG and In-Memory databases ( IMDB ). In the latter case, users are still forced to perform an object-relational mapping (Object-To-Relational Mapping), which, as a rule, leads to a significant decrease in performance.
There are other functional features that distinguish IMDG from other products, such as IMDB, NoSql or NewSql database. One of the main points is truly scalable data partitioning in a cluster. IMDG is essentially a distributed hash table, where each key is stored on a strictly defined server in a cluster. The larger the cluster, the more data can be stored in it. Fundamentally important in this architecture is that data should be processed on the same server where they are located (locally), eliminating (or minimizing) their movement across the cluster. In fact, when using a well-designed IMDG, data movement will be completely absent unless new servers are added to the cluster or existing servers are deleted, thereby changing the cluster topology and data distribution in it.
')
The diagram below shows a classic IMDG with a set of keys {k1, k2, k3}, in which each key belongs to a separate server. An external database is optional. If it is present, IMDG will usually automatically read data from the database or write it to it.
Another distinctive feature of IMDG is the support of transactionality that meets the requirements of ACID ( atomicity, consistency, isolation, durability - atomicity, integrity, isolation, preservation ). As a rule, in order to guarantee the integrity of data in a cluster, two-phase commit (2-phase-commit or 2PC) is used. Different IMDGs can have different locking mechanisms, but the most advanced implementations typically use parallel locks (for example, GridGain uses MVCC - multi-version concurrency control, concurrency control using multi-versioning), thus minimizing network exchange and ensuring transactional ACID integrity with high performance.
Data integrity is one of the main differences between IMDG and NoSQL databases. NoSQL databases, in most cases, are designed using an approach called “ integrity ultimately ” ( Eventual Consistency, EC ), in which data may be in an inconsistent state for some time, but will necessarily become consistent * with time *. In general, write operations in EC systems are quite fast compared to slower read operations (more precisely, not exceeding the speed of a write operation). The latest IMDGs with * optimized * 2PC at least correspond to EC systems in writing speed (if they are not ahead of them), and significantly outperform them in reading speed. Interestingly, the industry made a full circle, moving from the then slow 2PC to the EC, and now from the EC to the much faster * optimized * 2PC.
Different products may offer different 2PC optimizations, but in general, the objectives of all optimizations are to increase concurrency, minimize network traffic, and reduce the number of locks required to complete a transaction. For example, Google’s distributed global Spanner database is based on a transactional 2PC approach simply because 2PC provided a faster and easier way to guarantee data integrity and high throughput compared to MapReduce or EC.
Even though different IMDGs usually have a lot of common basic functionality, there are many additional features and implementation details that differ depending on the manufacturer. When evaluating the IMDG product, pay attention to eviction policies, data loading techniques, including, when the server starts ((pre) loading techniques), parallel partitioning (concurrent repartitioning), the amount of additional memory required for storage records (data overhead), and the like. Also, pay attention to the ability to make queries (query) in the cache at run time. Some IMDGs, for example, GridGain , allow users to query data stored in memory using standard SQL with support for distributed join-ovs (distributed joins) , which is quite a rarity.
Data storage in the IMDG is only half the functionality required for an in-memory architecture. Data stored in the IMDG must also be processed in parallel and at high speed. A typical in-memory architecture partitions the data in a cluster using IMDG, and then the executable code is sent to the exact server where the data it needs is located. Since the executable code (computational task) is usually part of the computing clusters (Compute Grids) , it must be deployed properly (deployment), balanced by load (load-balancing), have fault tolerance ( fail-over ), and also be able to run on a schedule ( scheduling ), the integration between the Compute Grid and the IMDG is very important . The greatest effect can be obtained if IMDG and Compute Grid are parts of the same product and use the same API. This removes the burden of integration from the developer and usually allows to achieve the highest performance and reliability of the in-memory solution.
IMDG (along with Compute Grid) find their application in many areas, such as risk analysis (Risk Analytics), trading systems (Trading Systems), real-time anti-fraud systems (Fraud Detection), biometrics (Biometrics), e-commerce ( eCommerce), online games (Online Gaming). In fact, any product that faces scalability and performance issues can benefit from the use of In-Memory Processing and IMDG architecture.
Source: https://habr.com/ru/post/160517/
All Articles