Implementing a Restricted Boltzmann machine on c #
Hey. The course on neural networks has ended. Good course, but little practice. So in this post we will look at, write and test a limited Boltzmann machine — a stochastic , generative model of a neural network . We will train it using the Contrastive Divergence (CD-k) algorithm, developed by Professor Jeffrey Hinton , who, by the way, leads the course. We will test on a set of printed English letters. In the next post, one of the shortcomings of the error back-propagation algorithm and the method of initial initialization of weights using the Boltzmann machine will be considered. Who is not afraid of formulas and sheets of text, please under the cat.
')
I will not particularly focus on the history of the origin of the limited Boltzmann machine (RBM), I will only mention that it all began with recurrent neural networks , which are feedback networks that are extremely difficult to train. As a consequence of this slight difficulty in learning, people began to invent more limited recurrent models for which simpler learning algorithms could be applied. One of these models was the Hopfield neural network , and he also introduced the concept of network energy, comparing neural network dynamics with thermodynamics:
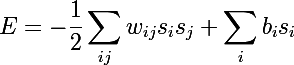
The next step on the path to RBM was Boltzmann’s ordinary machines , they differ from the Hopfield network in that they have a stochastic nature , and the neurons are divided into two groups describing the monitored and hidden states (by the way, with the hidden Markov models , by the way Hinton admits that from there he borrowed the word "hidden"). Energy in Boltzmann machines is expressed as follows:
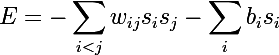
The Boltzmann machine is a fully connected undirected graph, and thus, any two vertices from the same group depend on each other.

But if we remove the links within the group to get a bipartite graph , we get the structure of the RBM model.

The peculiarity of this model is that with a given state of neurons of one group, the states of neurons of another group will be independent of each other. Now you can go to the theory where this property plays the key role.
RBMs are interpreted similarly to hidden Markov models. We have a number of states that we can observe (visible neurons that provide an interface for communicating with the external environment) and a number of states that are hidden, and we cannot directly see their state (hidden neurons). But we can make a probabilistic conclusion regarding hidden states, based on the states that we can observe. Having trained such a model, we also have the opportunity to draw conclusions regarding visible states, knowing the hidden ones (no one has canceled the Bayes theorem =), and thereby generate data from the probability distribution on which the model has been trained.
Thus, we can formulate the purpose of training the model: it is necessary to adjust the parameters of the model so that the recovered vector from the initial state is closest to the original. By restored is meant a vector obtained by a probabilistic inference from hidden states, which, in turn, are obtained by a probabilistic inference from the observed states, i.e. from the original vector.
We introduce the following notation:
We will consider a training set consisting of binary vectors, but this is easily generalized to vectors of real numbers. Suppose we have n visible neurons and m hidden ones. We introduce the concept of energy for RBM:
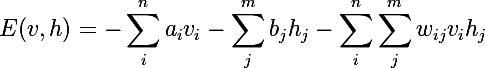
The neural network will calculate the joint probability of all possible pairs of v and h as follows:

where Z is a partition function or a normalizer ( partition function ) of the following form (suppose we have only N images v, and M images h):

Obviously, the total probability of the vector v will be calculated by summing over all h :

Consider the probability that for a given v one of the hidden states is h_k = 1 . To do this, we represent one neuron, then the energy of the system with 1 will be E1, and with 0 it will be E0, and the probability 1 will be equal to the sigmoid function of the linear combination of the current neuron with the state vector of the layer under review together with the offset:
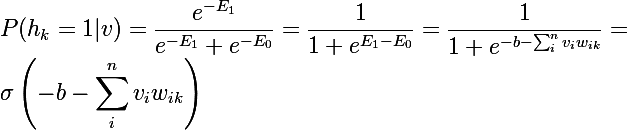
And since for this v all h_k are independent of each other, then:

A similar conclusion is made for the probability v for a given h .
As we remember, the purpose of training is to make the recovered vector closest to the original, or, in other words, maximize the probability p (v) . For this, it is necessary to calculate the partial derivatives of the probabilities from the model parameters. Let's start with the energy differentiation by model parameters:
We also need derivative exponents of negative energy:
Differentiate the amount of:
We are almost at the goal -) Consider the partial derivative of probability v by weights:
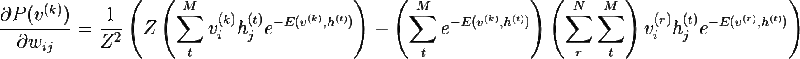
Obviously, maximizing probability is the same as maximizing the logarithm of probability, this trick will help come to a beautiful solution. Consider the derivative of the natural logarithm by weight:
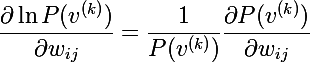
Combining the last two formulas, we get the following expression:
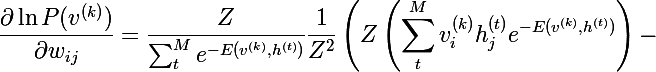
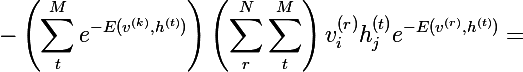

Multiplying the numerator and denominator of each term by Z and, simplifying to probabilities, we obtain the following expression:

And by the definition of mathematical expectation, we get the final expression (M before the square bracket is the sign of the mathematical expectation):
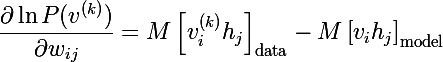
Derivatives based on displacement of neurons are derived in the same way:
And in the end, there are three rules for updating model parameters, where this is the speed of learning:
PS the fry in indexes could be mistaken, on Habré there is no built in editor =)
editor =)
This algorithm was invented by Professor Hinton in 2002, and it is notable for its simplicity. The main idea is that mathematical expectations are replaced by well-defined values. Introduces the concept of the sampling process (Gibbs sampling, to see the association, you can look here ). The CD-k process is as follows:
In lectures at Hinton, it looks like this:
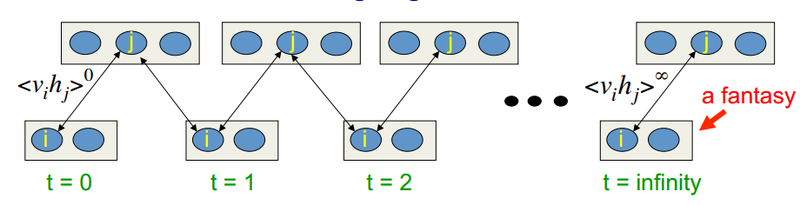
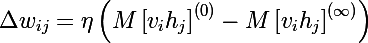
Those. the longer we do the sampling, the more accurate our gradient will be. At the same time, the professor claims that even for CD-1 (only one iteration of sampling), a quite good result is already obtained. The first term is called the positive phase , and the second with a minus sign is called the negative phase .
As in the implementation of the reverse error propagation algorithm , I use almost the same interfaces. So consider immediately the function of learning neural network. We will implement the training using the moment of inertia.
A very brief history excursion.
')
I will not particularly focus on the history of the origin of the limited Boltzmann machine (RBM), I will only mention that it all began with recurrent neural networks , which are feedback networks that are extremely difficult to train. As a consequence of this slight difficulty in learning, people began to invent more limited recurrent models for which simpler learning algorithms could be applied. One of these models was the Hopfield neural network , and he also introduced the concept of network energy, comparing neural network dynamics with thermodynamics:
- w - weight between neurons
- b - neuron displacement
- s - the state of the neuron
The next step on the path to RBM was Boltzmann’s ordinary machines , they differ from the Hopfield network in that they have a stochastic nature , and the neurons are divided into two groups describing the monitored and hidden states (by the way, with the hidden Markov models , by the way Hinton admits that from there he borrowed the word "hidden"). Energy in Boltzmann machines is expressed as follows:
The Boltzmann machine is a fully connected undirected graph, and thus, any two vertices from the same group depend on each other.
But if we remove the links within the group to get a bipartite graph , we get the structure of the RBM model.
The peculiarity of this model is that with a given state of neurons of one group, the states of neurons of another group will be independent of each other. Now you can go to the theory where this property plays the key role.
Interpretation and purpose
RBMs are interpreted similarly to hidden Markov models. We have a number of states that we can observe (visible neurons that provide an interface for communicating with the external environment) and a number of states that are hidden, and we cannot directly see their state (hidden neurons). But we can make a probabilistic conclusion regarding hidden states, based on the states that we can observe. Having trained such a model, we also have the opportunity to draw conclusions regarding visible states, knowing the hidden ones (no one has canceled the Bayes theorem =), and thereby generate data from the probability distribution on which the model has been trained.
Thus, we can formulate the purpose of training the model: it is necessary to adjust the parameters of the model so that the recovered vector from the initial state is closest to the original. By restored is meant a vector obtained by a probabilistic inference from hidden states, which, in turn, are obtained by a probabilistic inference from the observed states, i.e. from the original vector.
Theory
We introduce the following notation:
- w_ij - the web between the i-th neuron
- a_i - offset of the visible neuron
- b_j - offset of the hidden neuron
- v_i - the state of the visible neuron
- h_j - the state of the hidden neuron
We will consider a training set consisting of binary vectors, but this is easily generalized to vectors of real numbers. Suppose we have n visible neurons and m hidden ones. We introduce the concept of energy for RBM:
The neural network will calculate the joint probability of all possible pairs of v and h as follows:
where Z is a partition function or a normalizer ( partition function ) of the following form (suppose we have only N images v, and M images h):
Obviously, the total probability of the vector v will be calculated by summing over all h :
Consider the probability that for a given v one of the hidden states is h_k = 1 . To do this, we represent one neuron, then the energy of the system with 1 will be E1, and with 0 it will be E0, and the probability 1 will be equal to the sigmoid function of the linear combination of the current neuron with the state vector of the layer under review together with the offset:
And since for this v all h_k are independent of each other, then:
A similar conclusion is made for the probability v for a given h .
As we remember, the purpose of training is to make the recovered vector closest to the original, or, in other words, maximize the probability p (v) . For this, it is necessary to calculate the partial derivatives of the probabilities from the model parameters. Let's start with the energy differentiation by model parameters:
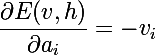
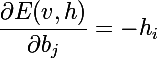
We also need derivative exponents of negative energy:

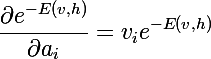

Differentiate the amount of:
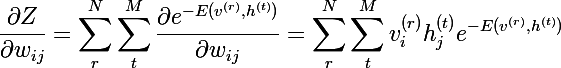
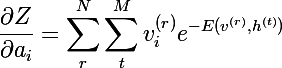

We are almost at the goal -) Consider the partial derivative of probability v by weights:
Obviously, maximizing probability is the same as maximizing the logarithm of probability, this trick will help come to a beautiful solution. Consider the derivative of the natural logarithm by weight:
Combining the last two formulas, we get the following expression:
Multiplying the numerator and denominator of each term by Z and, simplifying to probabilities, we obtain the following expression:
And by the definition of mathematical expectation, we get the final expression (M before the square bracket is the sign of the mathematical expectation):
Derivatives based on displacement of neurons are derived in the same way:
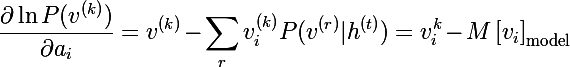

And in the end, there are three rules for updating model parameters, where this is the speed of learning:
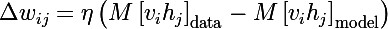
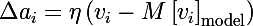

PS the fry in indexes could be mistaken, on Habré there is no built in
editor =)Algorithm learning Contrastive Divergence
This algorithm was invented by Professor Hinton in 2002, and it is notable for its simplicity. The main idea is that mathematical expectations are replaced by well-defined values. Introduces the concept of the sampling process (Gibbs sampling, to see the association, you can look here ). The CD-k process is as follows:
- the state of visible neurons is equal to the input image
- displays the probabilities of the states of the hidden layer
- each neuron of the hidden layer is assigned a state "1" with a probability equal to its current state
- the probabilities of the visible layer are derived based on the hidden
- if the current iteration is less than k, then return to step 2
- displays the probabilities of the states of the hidden layer
In lectures at Hinton, it looks like this:
Those. the longer we do the sampling, the more accurate our gradient will be. At the same time, the professor claims that even for CD-1 (only one iteration of sampling), a quite good result is already obtained. The first term is called the positive phase , and the second with a minus sign is called the negative phase .
Talk is cheap. Show me the code.
As in the implementation of the reverse error propagation algorithm , I use almost the same interfaces. So consider immediately the function of learning neural network. We will implement the training using the moment of inertia.
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .

#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):

:

, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :

MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :


public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);, Gibbs sampling, .
#region iterate through batch
// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }, . : ( ) . .
#region compute mean of wights nabla, and update them
for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }- . , , / , , , . : . , , , . .
#region Logging and error calculation
string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);, Gibbs sampling, .
#region iterate through batch
// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }, . : ( ) . .
#region compute mean of wights nabla, and update them
for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }- . , , / , , , . : . , , , . .
#region Logging and error calculation
string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update themfor (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculationstring msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update themfor (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculationstring msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update themfor (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculationstring msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update themfor (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculationstring msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update themfor (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculationstring msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch// foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update themfor (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculationstring msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
Source: https://habr.com/ru/post/159909/
All Articles