Overview and configuration of deduplication tools in Windows Server 2012
Good day to all!
Today I would like to review such an interesting new feature in Windows Server 2012 as data deduplication (data deduplication). The feature is extremely interesting, but still you first need to figure out how much it is needed ...
')
Every year (if not during the day) hard drive volumes are growing, and at the same time, the carriers themselves are also becoming cheaper.
Based on this tendency, the question arises: “Does data deduplication necessary?”.
However, if we live in our universe and on our planet, then almost everything in this world tends to obey the 3rd Newton's law. Maybe the analogy is not completely transparent, but I conclude that the disk systems and disks themselves, no matter how much the carriers themselves become cheaper, the requirements from the business point of view of the data storage space are constantly increasing and thus level the increase. volume and price drop.
According to IDC forecasts, in about a year, about 90 million terabytes will be required in total volume. The volume, frankly, is not small.
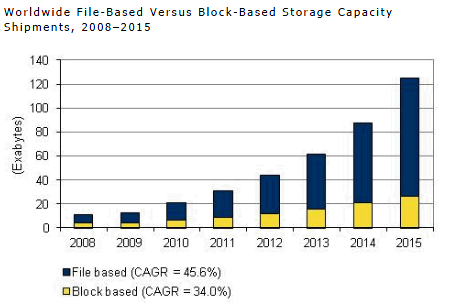
And this is where the issue of data deduplication becomes very relevant. After all, the data that we use are of different types, and they can have different purposes - somewhere it is production-data, somewhere it is archives and backup copies, and somewhere it is streaming data - I specifically cited such examples, since in the first case the effect of using deduplication will be average, in the archived data it will be maximum, and in the case of streaming data it will be minimal. But still, we can save space with you, especially since deduplication is now a matter of not only specialized storage systems, but also a component feature of the Windows Server 2012 server OS.
Before turning to the review of the deduplication mechanism itself in Windows Server 2012 , let's look at what types of deduplication are. I propose to start from top to bottom, in my opinion so it will be clearer.
1) File deduplication - like any deduplication mechanism, the operation of the algorithm is reduced to finding unique data sets and repetitive ones, where the second types of sets are replaced with references to the first sets. In other words, the algorithm tries to store only unique data, replacing duplicate data with links to unique ones. As you might guess from the name of this type of deduplication, all such operations occur at the file level. If you recall the history of Microsoft products - this approach has been repeatedly used before - in the Microsoft Exchange Server and the Microsoft System Center Data Protection Manager - and this mechanism was called SIS (Single Instance Storage). In the products of the Exchange line, it was abandoned in due time for performance reasons, but in Data Protection Manager, this mechanism is still successfully used and it will seem to continue to do so. As you might guess, the file level is the highest (if you remember the storage system in general) - and therefore the effect will be the most minimal compared to other types of deduplication. Scope - this type of deduplication is mainly applied to archived data.
2) Block deduplication - this mechanism is more interesting, since it works at the sub-file level - namely, at the level of data blocks. This type of deduplication is usually characteristic of industrial storage systems, and it is this type of deduplication that is used in Windows Server 2012. The mechanisms are the same as before - but at the block level (I think I said that, right?). Here, the scope of deduplication is expanding and now extends not only to archived data, but also to virtualized environments, which is quite logical - especially for VDI scripts. If we consider that VDI is a whole cloud of repetitive images of virtual machines, which still have differences from each other (this is why the file deduplication is powerless here) - then block deduplication is our choice!
3) Bit deduplica - the lowest (deep) type of data deduplication - has the highest degree of efficiency, but it is also the leader in resource consumption. It is understandable - to analyze data on uniqueness and plagiarism is a difficult process. Honestly, I personally do not know storage systems that operate at this level of deduplication, but I know for sure that there are traffic deduplication systems that operate at the bit level, say the same Citrix NetScaler. The meaning of such systems and applications is to save the transmitted traffic - this is very critical for scenarios with geographically distributed organizations, where there are many geographically dispersed branches of the enterprise, but there are no or extremely expensive data transmission channels in operation - here solutions in the field of bit deduplication will find themselves nowhere else will they reveal their talents.
The Microsoft report at USENIX 2012 , which took place in Boston in June, looks very interesting in this regard. There was a fairly large-scale analysis of the primary data in terms of applying to them the block deduplication mechanisms in WIndows Server 2012 - I recommend reading this material.
In order to understand how effective deduplication technology in Windows Server 2012, you first need to determine on what type of data this very efficiency should be measured. Typical file balls, user documents from the My Documents folder, distribution repositories and libraries, and virtual hard disk storage were taken as references.
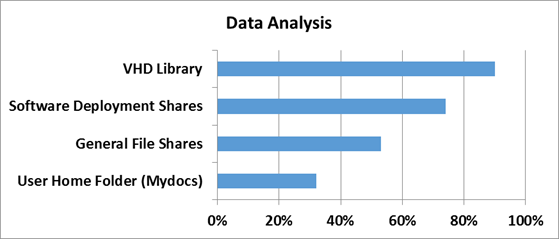
How effective deduplication in terms of workloads was checked at Microsoft in the software development department.
The 3 most popular scenarios became the objects of study:
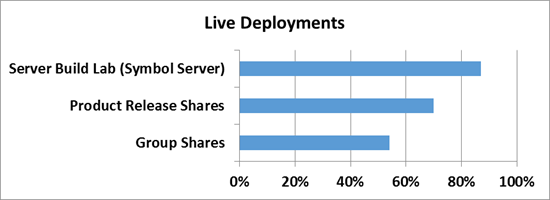
1) Software build build servers — a decent amount of builds of various products is collected every day at MS. Not even a significant change in the code leads to the build process of the build - and therefore a lot of duplicate data is created.
2) Spheres with product distribution kits for release - As it is not difficult to guess, all assemblies and ready versions of software need to be placed somewhere - inside Microsoft there are special servers for this, where all versions and language revisions of all products are placed - this is also quite an effective script where the efficiency of deduplication can reach up to 70%.
3) Group balls are a combination of a ball with documents and developer files, as well as their roaming profiles and redirected folders, which are stored in a single central space.
And now the most interesting - below is a screenshot of the volumes in Windows Server 2012, on which all this data is placed.
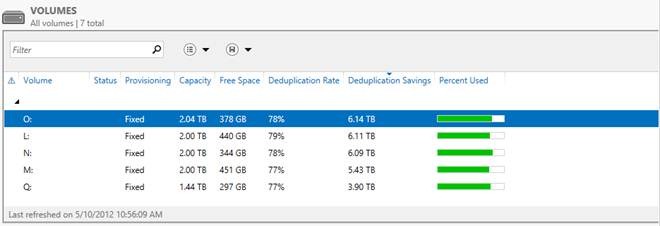
I think the words here will be superfluous - and everything is very clear. Saving at 6 TB on media at 2 TB - thermonuclear storage? Not so dangerous - but so effective!
And now let's consider the main characteristics of deduplication in Windows Server 2012.
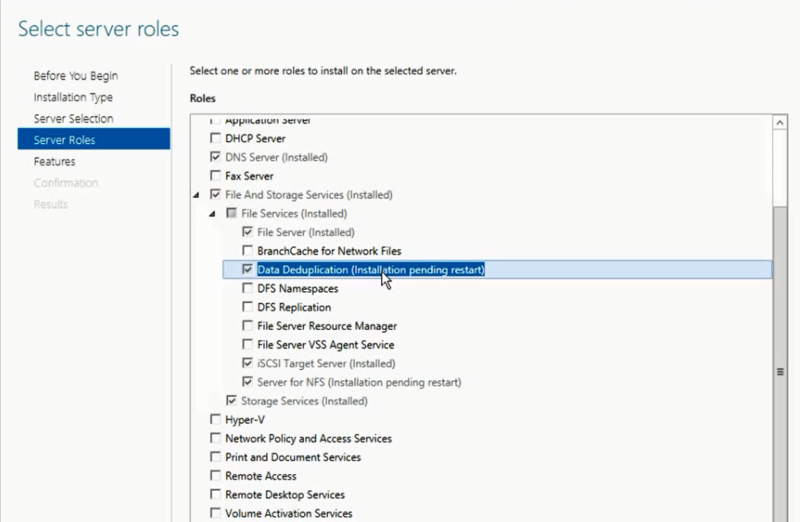
1) Transparency and ease of use - configuring deduplication is extremely simple. First, in the role wizard in Windows Server, you disclose the role of File and Storage Services, then File and iSCSI Services - and there you turn on the Data Deduplication option.
After that, in Server Manager you select Fike and Storage Services, right-click - and there you select the item “Enable Volume Deduplication”. Special link for PowerShell lovers . Everything is extremely simple. From the point of view of the end user and applications, access and work with data is carried out transparently and imperceptibly. If we talk about deduplication from the point of view of the file system, only NTFS is supported. ReFS cannot be deduplicated, just like volumes protected with EFS (Encrypted Fike System). Also, files of less than 32 KB and files with extended attributes (extended attributes) are not subject to deduplication. Deduplication, however, extends to dynamic volumes, BitLocker-encrypted volumes, but not CSV volumes, as well as system volumes (which is logical).
2) Optimization for basic data - it is worth noting immediately that deduplication is not an online process. Deduplications are files that reach a certain level of old age in terms of a given policy. After a certain storage period is reached, data starts to go through the deduplication process - by default, this time interval is 5 days, but no one bothers you to change this parameter - but be reasonable in your experiments!
3) Planning optimization processes - a mechanism that every hour checks files for compliance with deduplication parameters and adds them to the schedule.
4) Mechanisms for excluding objects from the deduplication area - this mechanism allows you to exclude files from the deduplication area by their type (JPG, MOV, AVI - as an example, this is streaming data - something that is least susceptible to deduplication - if it can be). You can also exclude entire file folders from the deduplication area at once (this is for fans of German films whose darkness is theirs).
5) Mobility - the deduplicated volume is a complete object - it can be transferred from one server to another (this is exclusively Windows Server 2012). In this case, you can easily access your data and can continue to work with them. All that is needed for this is the included Data Deduplication option on the target server.
6) Optimization of resource consumption - these mechanisms involve the optimization of algorithms to reduce the load on read / write operations, so if we are talking about the size of the hash index of data blocks, then the size of the index per 1 data block is 6 bytes. Thus, deduplication can even be applied to very massive data sets.
Also, the algorithm always checks whether there are enough memory resources for the deduplication process - if the answer is no, then the algorithm will delay the process until the required amount of resources is released.
7) BranchCache integration - indexing mechanisms for deduplication are also common for BranchCache - therefore, the efficiency of using these technologies in conjunction is beyond doubt!
The issue of reliability is extremely acute for deduplicated data - imagine that a data block, at least 1000 files depend hopelessly damaged ... I think validol-ez-e-service then will definitely come in handy, but not in our case.
1) Backup - Windows Server 2012, like System Center Data Protection Manager 2012 SP1, fully supports deduplicated volumes in terms of backup processes. Also available is a special API that allows third-party developers to use and maintain deduplication mechanisms, as well as restore data from deduplicated archives.
2) Additional copies for critical data — those data that have the most frequent conversion parameter are projected through the process of creating additional backup blocks — these are features of the mechanism of the mechanism. Also, in the case of using the Storage Spaces mechanisms, when finding a bad block, the algorithm automatically replaces it with the integral of the pair in the mirror.
3) By default, once a week, the process of finding garbage and bad blocks starts, which corrects the data of acquired pathologies. It is also possible to manually start this process at a deeper level. If the default process corrects errors that were recorded in the event log, then a deeper process involves scanning the entire volume.
Before turning on deduplication, always the normal person would think about how effective this mechanism will be in his particular case. To do this, you can use the Deduplication Data Evaluation Tool .
After installing deduplication, you can find a tool called DDPEval.exe , which is in \ Windows \ System32 \ - this scrap can be ported to removable media or another volume. Supports Windows 7 and higher. So you can analyze your data and understand the value of sheep skins. (smile).
This completes my review. I hope you were interested. If you have any questions, feel free to find me on social networks - VKontakte, Facebook - by name and surname - and I will try to help you.
For those who want to learn about new features in Windows Server 2012, as well as System Center 2012 SP1 - I invite everyone to visit IT Camp - November 26, this event will take place on the eve of TechEd Russia 2012 - I, George Hajiyev and Simon Perriman will conduct it who specially flies to us from the USA.
See you at IT Camp and at TechEd !
Respectfully,
fireman
George A. Gadzhiev
Microsoft Corporation
Today I would like to review such an interesting new feature in Windows Server 2012 as data deduplication (data deduplication). The feature is extremely interesting, but still you first need to figure out how much it is needed ...
')
Do you really need deuplication?
Every year (if not during the day) hard drive volumes are growing, and at the same time, the carriers themselves are also becoming cheaper.
Based on this tendency, the question arises: “Does data deduplication necessary?”.
However, if we live in our universe and on our planet, then almost everything in this world tends to obey the 3rd Newton's law. Maybe the analogy is not completely transparent, but I conclude that the disk systems and disks themselves, no matter how much the carriers themselves become cheaper, the requirements from the business point of view of the data storage space are constantly increasing and thus level the increase. volume and price drop.
According to IDC forecasts, in about a year, about 90 million terabytes will be required in total volume. The volume, frankly, is not small.
And this is where the issue of data deduplication becomes very relevant. After all, the data that we use are of different types, and they can have different purposes - somewhere it is production-data, somewhere it is archives and backup copies, and somewhere it is streaming data - I specifically cited such examples, since in the first case the effect of using deduplication will be average, in the archived data it will be maximum, and in the case of streaming data it will be minimal. But still, we can save space with you, especially since deduplication is now a matter of not only specialized storage systems, but also a component feature of the Windows Server 2012 server OS.
Types of deduplication and their use
Before turning to the review of the deduplication mechanism itself in Windows Server 2012 , let's look at what types of deduplication are. I propose to start from top to bottom, in my opinion so it will be clearer.
1) File deduplication - like any deduplication mechanism, the operation of the algorithm is reduced to finding unique data sets and repetitive ones, where the second types of sets are replaced with references to the first sets. In other words, the algorithm tries to store only unique data, replacing duplicate data with links to unique ones. As you might guess from the name of this type of deduplication, all such operations occur at the file level. If you recall the history of Microsoft products - this approach has been repeatedly used before - in the Microsoft Exchange Server and the Microsoft System Center Data Protection Manager - and this mechanism was called SIS (Single Instance Storage). In the products of the Exchange line, it was abandoned in due time for performance reasons, but in Data Protection Manager, this mechanism is still successfully used and it will seem to continue to do so. As you might guess, the file level is the highest (if you remember the storage system in general) - and therefore the effect will be the most minimal compared to other types of deduplication. Scope - this type of deduplication is mainly applied to archived data.
2) Block deduplication - this mechanism is more interesting, since it works at the sub-file level - namely, at the level of data blocks. This type of deduplication is usually characteristic of industrial storage systems, and it is this type of deduplication that is used in Windows Server 2012. The mechanisms are the same as before - but at the block level (I think I said that, right?). Here, the scope of deduplication is expanding and now extends not only to archived data, but also to virtualized environments, which is quite logical - especially for VDI scripts. If we consider that VDI is a whole cloud of repetitive images of virtual machines, which still have differences from each other (this is why the file deduplication is powerless here) - then block deduplication is our choice!
3) Bit deduplica - the lowest (deep) type of data deduplication - has the highest degree of efficiency, but it is also the leader in resource consumption. It is understandable - to analyze data on uniqueness and plagiarism is a difficult process. Honestly, I personally do not know storage systems that operate at this level of deduplication, but I know for sure that there are traffic deduplication systems that operate at the bit level, say the same Citrix NetScaler. The meaning of such systems and applications is to save the transmitted traffic - this is very critical for scenarios with geographically distributed organizations, where there are many geographically dispersed branches of the enterprise, but there are no or extremely expensive data transmission channels in operation - here solutions in the field of bit deduplication will find themselves nowhere else will they reveal their talents.
The Microsoft report at USENIX 2012 , which took place in Boston in June, looks very interesting in this regard. There was a fairly large-scale analysis of the primary data in terms of applying to them the block deduplication mechanisms in WIndows Server 2012 - I recommend reading this material.
Performance issues
In order to understand how effective deduplication technology in Windows Server 2012, you first need to determine on what type of data this very efficiency should be measured. Typical file balls, user documents from the My Documents folder, distribution repositories and libraries, and virtual hard disk storage were taken as references.
How effective deduplication in terms of workloads was checked at Microsoft in the software development department.
The 3 most popular scenarios became the objects of study:
1) Software build build servers — a decent amount of builds of various products is collected every day at MS. Not even a significant change in the code leads to the build process of the build - and therefore a lot of duplicate data is created.
2) Spheres with product distribution kits for release - As it is not difficult to guess, all assemblies and ready versions of software need to be placed somewhere - inside Microsoft there are special servers for this, where all versions and language revisions of all products are placed - this is also quite an effective script where the efficiency of deduplication can reach up to 70%.
3) Group balls are a combination of a ball with documents and developer files, as well as their roaming profiles and redirected folders, which are stored in a single central space.
And now the most interesting - below is a screenshot of the volumes in Windows Server 2012, on which all this data is placed.
I think the words here will be superfluous - and everything is very clear. Saving at 6 TB on media at 2 TB - thermonuclear storage? Not so dangerous - but so effective!
Deduplication features in Windows Server 2012
And now let's consider the main characteristics of deduplication in Windows Server 2012.
1) Transparency and ease of use - configuring deduplication is extremely simple. First, in the role wizard in Windows Server, you disclose the role of File and Storage Services, then File and iSCSI Services - and there you turn on the Data Deduplication option.
After that, in Server Manager you select Fike and Storage Services, right-click - and there you select the item “Enable Volume Deduplication”. Special link for PowerShell lovers . Everything is extremely simple. From the point of view of the end user and applications, access and work with data is carried out transparently and imperceptibly. If we talk about deduplication from the point of view of the file system, only NTFS is supported. ReFS cannot be deduplicated, just like volumes protected with EFS (Encrypted Fike System). Also, files of less than 32 KB and files with extended attributes (extended attributes) are not subject to deduplication. Deduplication, however, extends to dynamic volumes, BitLocker-encrypted volumes, but not CSV volumes, as well as system volumes (which is logical).
2) Optimization for basic data - it is worth noting immediately that deduplication is not an online process. Deduplications are files that reach a certain level of old age in terms of a given policy. After a certain storage period is reached, data starts to go through the deduplication process - by default, this time interval is 5 days, but no one bothers you to change this parameter - but be reasonable in your experiments!
3) Planning optimization processes - a mechanism that every hour checks files for compliance with deduplication parameters and adds them to the schedule.
4) Mechanisms for excluding objects from the deduplication area - this mechanism allows you to exclude files from the deduplication area by their type (JPG, MOV, AVI - as an example, this is streaming data - something that is least susceptible to deduplication - if it can be). You can also exclude entire file folders from the deduplication area at once (this is for fans of German films whose darkness is theirs).
5) Mobility - the deduplicated volume is a complete object - it can be transferred from one server to another (this is exclusively Windows Server 2012). In this case, you can easily access your data and can continue to work with them. All that is needed for this is the included Data Deduplication option on the target server.
6) Optimization of resource consumption - these mechanisms involve the optimization of algorithms to reduce the load on read / write operations, so if we are talking about the size of the hash index of data blocks, then the size of the index per 1 data block is 6 bytes. Thus, deduplication can even be applied to very massive data sets.
Also, the algorithm always checks whether there are enough memory resources for the deduplication process - if the answer is no, then the algorithm will delay the process until the required amount of resources is released.
7) BranchCache integration - indexing mechanisms for deduplication are also common for BranchCache - therefore, the efficiency of using these technologies in conjunction is beyond doubt!
Reliability issues for deduplicated volumes
The issue of reliability is extremely acute for deduplicated data - imagine that a data block, at least 1000 files depend hopelessly damaged ... I think validol-ez-e-service then will definitely come in handy, but not in our case.
1) Backup - Windows Server 2012, like System Center Data Protection Manager 2012 SP1, fully supports deduplicated volumes in terms of backup processes. Also available is a special API that allows third-party developers to use and maintain deduplication mechanisms, as well as restore data from deduplicated archives.
2) Additional copies for critical data — those data that have the most frequent conversion parameter are projected through the process of creating additional backup blocks — these are features of the mechanism of the mechanism. Also, in the case of using the Storage Spaces mechanisms, when finding a bad block, the algorithm automatically replaces it with the integral of the pair in the mirror.
3) By default, once a week, the process of finding garbage and bad blocks starts, which corrects the data of acquired pathologies. It is also possible to manually start this process at a deeper level. If the default process corrects errors that were recorded in the event log, then a deeper process involves scanning the entire volume.
Where to start and how to measure
Before turning on deduplication, always the normal person would think about how effective this mechanism will be in his particular case. To do this, you can use the Deduplication Data Evaluation Tool .
After installing deduplication, you can find a tool called DDPEval.exe , which is in \ Windows \ System32 \ - this scrap can be ported to removable media or another volume. Supports Windows 7 and higher. So you can analyze your data and understand the value of sheep skins. (smile).
This completes my review. I hope you were interested. If you have any questions, feel free to find me on social networks - VKontakte, Facebook - by name and surname - and I will try to help you.
For those who want to learn about new features in Windows Server 2012, as well as System Center 2012 SP1 - I invite everyone to visit IT Camp - November 26, this event will take place on the eve of TechEd Russia 2012 - I, George Hajiyev and Simon Perriman will conduct it who specially flies to us from the USA.
See you at IT Camp and at TechEd !
Respectfully,
fireman
George A. Gadzhiev
Microsoft Corporation
Source: https://habr.com/ru/post/158887/
All Articles