Multilingual spelling checker for programs using Hunspell
Many often face the need to check spelling in several languages at once, but not all existing programs allow such checking by prompting the user to switch from one language to another, which is rather inconvenient and takes a lot of time.

Not wanting to put up with such inconvenience for programs that use Hunspell dictionaries (FireFox, Seamonkey, Miranda, etc.), it was decided to create an automatic graphical utility for splicing several languages, with the possibility of further use of the resulting dictionaries.
A couple of lines about the history of creation. The idea originated in 2008, when I compiled a comprehensive Russian – English dictionary for FireFox.
It was posted on the Mozilla ftp site.
ftp.mozilla-russia.org/dictionaries/en-en_spell_dictionary.xpi
There was also a forum thread.
forum.mozilla-russia.org/viewtopic.php?id=15316
')
A lot of time has passed since that moment, but just recently, almost at the same time, I received several letters from interested people who asked for something more recent.
Rather than send ready-made updates, I decided to modify the GUI utility, which would allow users to put together several dictionaries together.
At that moment, the utility was written “for myself” in Delphi, which I used at work, but you cannot call it a cross-platform solution.
Of course, now you can use the latest versions of Embarcadero RAD Studio to create cross-platform solutions, however, I decided to stop at the implementation of an automatic utility using Java.
The utility in its minimum implementation should be able to
1. Download dictionaries from the following most common formats
- uncompressed * .dic and * .aff
- ZIP archive (* .zip)
- XPInstall format (* .xpi)
- OpenOffice Extensions (* .oxt)
2. To give the opportunity to choose dictionaries for gluing
3. To give the ability to change the name of the received dictionaries and descriptions
4. Upload in formats
- uncompressed * .dic and * .aff
- ZIP archive (* .zip)
- XPInstall format (* .xpi)
Before starting to create a program, it was necessary to study the format of dictionaries in order to be able to load and glue them.
Information on Hunspell can be found here.
hunspell.sourceforge.net
Format description
pwet.fr/man/linux/fichiers_speciaux/hunspell
or in Russian translation
mozilla-russia.org/projects/dictionary/hunspell.html
In short, Hunspell requires two files to check spelling. The first file is a dictionary containing words (* .dic), the second is an affix file (* .aff), which defines the values of special labels (flags) in the dictionary. Flags are assigned to words in a dictionary file, and are defined in an affix file.
Considering the format and structure of files, the main task was not to disrupt the correspondence of affixes for different dictionaries besides simple pasting the files of dictionaries.
There are three approaches to naming flags in an affix file.
1. By default, each affix is referred to as one letter (including the registry) or a number.
2. Long - each affix is called two letters or a letter with a number.
3. Number - each affix has a value from 1 to 65000.
Since in most cases (the dictionaries I encountered), the affix file contained only a few dozen different affix flags, the authors of the dictionaries could use the first approach with one letter, but it was clearly not suitable for splicing several files due to the large number of different affixes therefore it was decided to use digital naming in the resulting files. There is a minus, of course - some increase in the size of files, but I think this is not critical.
Also, all dictionary files were often in different encodings, therefore, for unification, the overall resulting UTF-8 encoding was chosen.
Otherwise, there were no particular problems.
The program loads dictionaries, sticks them together, ignoring duplicate words, as a result discards unused affix flags.
In this article, I will not go into the implementation of individual procedures, because for those who wish, I posted the source code here.
There is also a script for the ANT collector.
code.google.com/p/hunspell-merge
At the moment, I have tested the operation of the utility under Ubuntu and Windows 7 with the types of source files specified in the task for implementation.
Requires Java Runtime (JRE) .
Downloading HunspellMerge.jar and the startup file for your Linux or Windows OS from this page . For Linux, do not forget to put the right to run the file.
It is also possible to launch using Java Webstart - the launch file is located at this link .
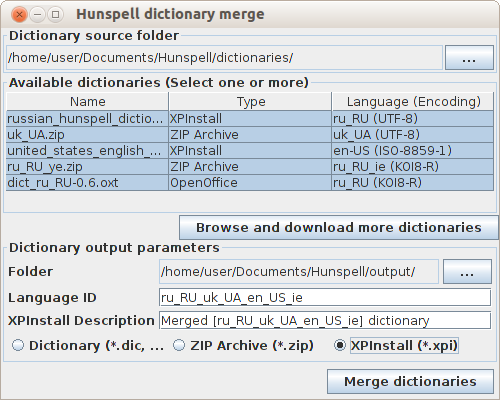
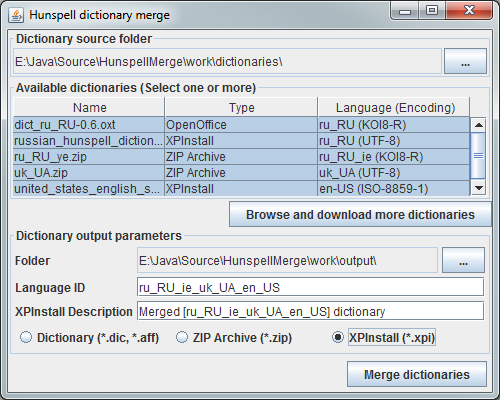
To work, you need to have a set of source files, which by default can be placed in the dictionaries subfolder of the working folder of the utility.
Additional dictionaries can be downloaded from the links located here.
code.google.com/p/hunspell-merge/wiki/OnlineDictionaries
After starting the utility or selecting a new source dictionary folder, they will be displayed in the list of dictionaries.
The user only needs to select (holding Ctrl or Shift) several dictionaries, select the destination folder, specify the language name and, if the upload is in XPInstall format, then correct the dictionary description.
Firefox
Output Format (XPInstall)
Just copy the file path or drag the file into the browser address bar.
Click the input and install the extension.
Miranda / MirandaNG
Output Format (Dictionary)
Copy the files (* .aff, * .dic) to the Dictionaries folder in the program directory. Restart Miranda.
Since the utility was written for a couple of evenings, there was no special time for testing and supporting extended instructions of the affixes file. It is in the plans for revision, however, some instructions for one language may be at odds with the same instructions for another, so for the time being three types of basic flags are supported - suffixes (SFX), prefixes (PFX), replacement (REP).
Add Russian language for the interface.
It would also be nice to write documentation and improve the page on GoogleCode.
I would very much like to hear in which other programs such glued dictionaries work.
I realize that the program is not without flaws, so I will be glad to hear suggestions and suggestions for improving the utility.
Thank you for your interest.
UPD As it turned out, there is a benefit even from simple gluing dictionaries of the same language, loaded with different resources or having different directions, for example, technical, economic.
Not wanting to put up with such inconvenience for programs that use Hunspell dictionaries (FireFox, Seamonkey, Miranda, etc.), it was decided to create an automatic graphical utility for splicing several languages, with the possibility of further use of the resulting dictionaries.
History of creation
A couple of lines about the history of creation. The idea originated in 2008, when I compiled a comprehensive Russian – English dictionary for FireFox.
It was posted on the Mozilla ftp site.
ftp.mozilla-russia.org/dictionaries/en-en_spell_dictionary.xpi
There was also a forum thread.
forum.mozilla-russia.org/viewtopic.php?id=15316
')
A lot of time has passed since that moment, but just recently, almost at the same time, I received several letters from interested people who asked for something more recent.
Rather than send ready-made updates, I decided to modify the GUI utility, which would allow users to put together several dictionaries together.
At that moment, the utility was written “for myself” in Delphi, which I used at work, but you cannot call it a cross-platform solution.
Of course, now you can use the latest versions of Embarcadero RAD Studio to create cross-platform solutions, however, I decided to stop at the implementation of an automatic utility using Java.
Task
The utility in its minimum implementation should be able to
1. Download dictionaries from the following most common formats
- uncompressed * .dic and * .aff
- ZIP archive (* .zip)
- XPInstall format (* .xpi)
- OpenOffice Extensions (* .oxt)
2. To give the opportunity to choose dictionaries for gluing
3. To give the ability to change the name of the received dictionaries and descriptions
4. Upload in formats
- uncompressed * .dic and * .aff
- ZIP archive (* .zip)
- XPInstall format (* .xpi)
Implementation
Before starting to create a program, it was necessary to study the format of dictionaries in order to be able to load and glue them.
Information on Hunspell can be found here.
hunspell.sourceforge.net
Format description
pwet.fr/man/linux/fichiers_speciaux/hunspell
or in Russian translation
mozilla-russia.org/projects/dictionary/hunspell.html
In short, Hunspell requires two files to check spelling. The first file is a dictionary containing words (* .dic), the second is an affix file (* .aff), which defines the values of special labels (flags) in the dictionary. Flags are assigned to words in a dictionary file, and are defined in an affix file.
Considering the format and structure of files, the main task was not to disrupt the correspondence of affixes for different dictionaries besides simple pasting the files of dictionaries.
There are three approaches to naming flags in an affix file.
1. By default, each affix is referred to as one letter (including the registry) or a number.
2. Long - each affix is called two letters or a letter with a number.
3. Number - each affix has a value from 1 to 65000.
Since in most cases (the dictionaries I encountered), the affix file contained only a few dozen different affix flags, the authors of the dictionaries could use the first approach with one letter, but it was clearly not suitable for splicing several files due to the large number of different affixes therefore it was decided to use digital naming in the resulting files. There is a minus, of course - some increase in the size of files, but I think this is not critical.
Also, all dictionary files were often in different encodings, therefore, for unification, the overall resulting UTF-8 encoding was chosen.
Otherwise, there were no particular problems.
The program loads dictionaries, sticks them together, ignoring duplicate words, as a result discards unused affix flags.
In this article, I will not go into the implementation of individual procedures, because for those who wish, I posted the source code here.
There is also a script for the ANT collector.
code.google.com/p/hunspell-merge
How to work
At the moment, I have tested the operation of the utility under Ubuntu and Windows 7 with the types of source files specified in the task for implementation.
Requires Java Runtime (JRE) .
Downloading HunspellMerge.jar and the startup file for your Linux or Windows OS from this page . For Linux, do not forget to put the right to run the file.
It is also possible to launch using Java Webstart - the launch file is located at this link .
To work, you need to have a set of source files, which by default can be placed in the dictionaries subfolder of the working folder of the utility.
Additional dictionaries can be downloaded from the links located here.
code.google.com/p/hunspell-merge/wiki/OnlineDictionaries
After starting the utility or selecting a new source dictionary folder, they will be displayed in the list of dictionaries.
The user only needs to select (holding Ctrl or Shift) several dictionaries, select the destination folder, specify the language name and, if the upload is in XPInstall format, then correct the dictionary description.
Use of work results
Firefox
Output Format (XPInstall)
Just copy the file path or drag the file into the browser address bar.
Click the input and install the extension.
Miranda / MirandaNG
Output Format (Dictionary)
Copy the files (* .aff, * .dic) to the Dictionaries folder in the program directory. Restart Miranda.
Plans
Since the utility was written for a couple of evenings, there was no special time for testing and supporting extended instructions of the affixes file. It is in the plans for revision, however, some instructions for one language may be at odds with the same instructions for another, so for the time being three types of basic flags are supported - suffixes (SFX), prefixes (PFX), replacement (REP).
Add Russian language for the interface.
It would also be nice to write documentation and improve the page on GoogleCode.
Conclusion
I would very much like to hear in which other programs such glued dictionaries work.
I realize that the program is not without flaws, so I will be glad to hear suggestions and suggestions for improving the utility.
Thank you for your interest.
UPD As it turned out, there is a benefit even from simple gluing dictionaries of the same language, loaded with different resources or having different directions, for example, technical, economic.
Source: https://habr.com/ru/post/158441/
All Articles