Switch to Percona XtraDB Cluster. One possible configuration
So, I started to implement Percona XtraDB Cluster in my organization - transfer databases from a regular MySQL server to a cluster architecture.
In the cluster we need to keep:
In other words, the database of almost all of our projects, of those that run on our MySQL, should now live in a cluster.
We keep most of the projects remotely in the DC, so the cluster will be located there.
The task of spreading a cluster geographically across different data centers is not worth it.
')
To build a cluster, 3 servers of the same configuration are used: HP DL160 G6, 2X Xeon E5620, 24 GB RAM, 4x SAS 300GB in hardware RAID 10. Not bad brand hardware that I have been using for a long time and which has not let me down yet.
- synchronous true multi-master replication (Galera)
- the possibility of commercial support from Percona
- fork MySQL with an impressive list of optimizations
In a cluster of 3 nodes, for each of the above physical server (OS Ubuntu 12.04).
A transparent connection to one virtual IP address is used, shared between all 3 servers using keepalived . For load balancing on nodes, HAProxy is used, of course, installed on each server, so that in case of failure of one of them, thanks to VIP, it continues to balance the other. We intentionally decided to use for LB and VIP the same pieces of iron as for the cluster.
Node A is used as a Reference (Backup) Node that our applications will not load with requests. However, she will be a full member of the cluster, and participate in replication. This is due to the fact that in the event of a cluster failure or data integrity violation, we will have a node that almost certainly contains the most consistent data that applications simply could not destroy due to lack of access. It may seem like a waste of resources, but for us, 99% data reliability is still more important than 24/7 availability. This is the node we will use for SST - State Snapshot Transfer - automatic dumping of a new node being added to the cluster or being lifted after a failure. In addition, Node A is an excellent candidate for the server, from where we will take standard periodic backups.
Schematically it can all be depicted like this:
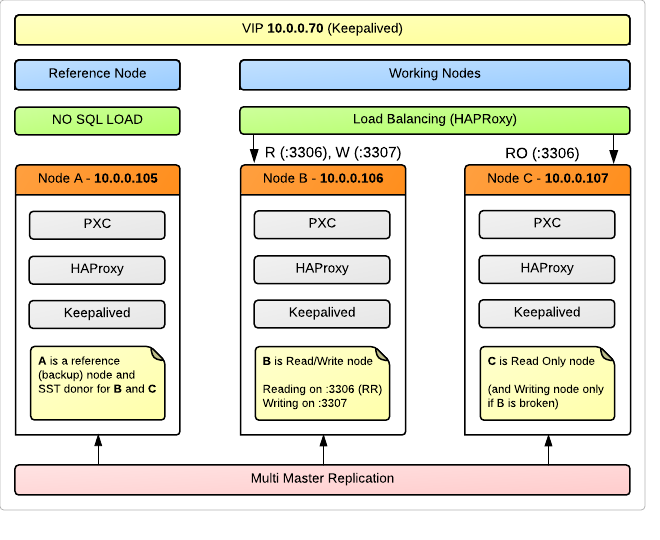
Node B and Node C are workhorses that hold the load, but only one of them takes over the write operation. This is the recommendation of many specialists, and below I will focus on this issue in detail.
Requests coming to port 3306 , HAProxy scatters on Round Robin between nodes B and C.
What comes to 3307 is proxied only to Node B. Moreover, if Node B suddenly falls, requests will be transferred to the specified Node C as the backup .
To implement our idea (to write only to one of the nodes), applications must be written so that read requests go through a connection from 10.0.0.70reed306 (10.0.0.70 is our VIP), and write requests go to 10.0.0.70: 3307 .
In our case, this will require some work on creating a new connection in the PHP config, and replacing the name of the DBHandler variable with another value. In general, it is not so difficult for those applications that are written by us. For third-party projects whose databases will also be in a cluster, we simply specify port 3307 by default. These projects create a small load, and the loss of the possibility of distributed reading is not so critical.
HAProxy config ( /etc/haproxy/haproxy.cfg ):
In order for HAProxy to determine if a cluster node is alive, the clustercheck utility (included in the percona-xtradb-cluster package) is used, which displays the status of the node (Synced / Not Synced) as an HTTP response. Each node must have a xinetd service configured:
/etc/xinetd.d/mysqlchk
/ etc / services
HAProxy raises the web server and provides a script to view statistics, which is very convenient for visual monitoring of the cluster status.
The URL looks like this:
The issue of setting up a cluster with balancing via HAProxy is well discussed here: www.mysqlperformanceblog.com/2012/06/20/percona-xtradb-cluster-reference-architecture-with-haproxy
/etc/keepalived/keepalived.conf
On Habré already have an article about installing and testing PXC: habrahabr.ru/post/152969 , where both issues are discussed in detail, so I omit the installation. But I will describe the configuration.
First of all, do not forget to synchronize the time on all nodes. I missed this moment, and for a long time I could not understand why my SST hangs tightly - it started, hung in the processes, but in fact nothing happened.
my.cnf on Node A (in my configs is node105 ):
Further, only different parameters:
Node B (node106)
Node C (node107)
In the last two configs, we unequivocally tell the server where to look for the first node in the cluster (which knows where all the members of the group live), and what exactly from it, and not from the other available, you need to take data for synchronization.
It is on this configuration that I stopped now, and I am going to gradually transfer projects to the cluster. I plan to continue writing about my experience further.
I’ll mark here the questions to which I didn’t immediately find the answer, but the answer to which is especially important for understanding the technology and proper work with the cluster.
Percona XtraDB Cluster
XtraDB Cluster on mysqlperfomanceblog.com
Percona Community Forums
Percona Discussion Google group
Galera wiki
Briefly about the task and input data
In the cluster we need to keep:
- DB of several websites with users
- DB with the statistics of these users
- BD for ticket systems, project management systems and other trifles
In other words, the database of almost all of our projects, of those that run on our MySQL, should now live in a cluster.
We keep most of the projects remotely in the DC, so the cluster will be located there.
The task of spreading a cluster geographically across different data centers is not worth it.
')
To build a cluster, 3 servers of the same configuration are used: HP DL160 G6, 2X Xeon E5620, 24 GB RAM, 4x SAS 300GB in hardware RAID 10. Not bad brand hardware that I have been using for a long time and which has not let me down yet.
Why Percona?
- synchronous true multi-master replication (Galera)
- the possibility of commercial support from Percona
- fork MySQL with an impressive list of optimizations
Cluster layout
In a cluster of 3 nodes, for each of the above physical server (OS Ubuntu 12.04).
A transparent connection to one virtual IP address is used, shared between all 3 servers using keepalived . For load balancing on nodes, HAProxy is used, of course, installed on each server, so that in case of failure of one of them, thanks to VIP, it continues to balance the other. We intentionally decided to use for LB and VIP the same pieces of iron as for the cluster.
Node A is used as a Reference (Backup) Node that our applications will not load with requests. However, she will be a full member of the cluster, and participate in replication. This is due to the fact that in the event of a cluster failure or data integrity violation, we will have a node that almost certainly contains the most consistent data that applications simply could not destroy due to lack of access. It may seem like a waste of resources, but for us, 99% data reliability is still more important than 24/7 availability. This is the node we will use for SST - State Snapshot Transfer - automatic dumping of a new node being added to the cluster or being lifted after a failure. In addition, Node A is an excellent candidate for the server, from where we will take standard periodic backups.
Schematically it can all be depicted like this:
Node B and Node C are workhorses that hold the load, but only one of them takes over the write operation. This is the recommendation of many specialists, and below I will focus on this issue in detail.
HAProxy and balancing details
Requests coming to port 3306 , HAProxy scatters on Round Robin between nodes B and C.
What comes to 3307 is proxied only to Node B. Moreover, if Node B suddenly falls, requests will be transferred to the specified Node C as the backup .
To implement our idea (to write only to one of the nodes), applications must be written so that read requests go through a connection from 10.0.0.70reed306 (10.0.0.70 is our VIP), and write requests go to 10.0.0.70: 3307 .
In our case, this will require some work on creating a new connection in the PHP config, and replacing the name of the DBHandler variable with another value. In general, it is not so difficult for those applications that are written by us. For third-party projects whose databases will also be in a cluster, we simply specify port 3307 by default. These projects create a small load, and the loss of the possibility of distributed reading is not so critical.
HAProxy config ( /etc/haproxy/haproxy.cfg ):
global log 127.0.0.1 local0 log 127.0.0.1 local1 notice maxconn 4096 chroot /usr/share/haproxy daemon defaults log global mode http option tcplog option dontlognull retries 3 option redispatch maxconn 2000 contimeout 5000 clitimeout 50000 srvtimeout 50000 frontend pxc-front bind 10.0.0.70:3306 mode tcp default_backend pxc-back frontend stats-front bind *:81 mode http default_backend stats-back frontend pxc-onenode-front bind 10.0.0.70:3307 mode tcp default_backend pxc-onenode-back backend pxc-back mode tcp balance leastconn option httpchk server c1 10.0.0.106:33061 check port 9200 inter 12000 rise 3 fall 3 server c2 10.0.0.107:33061 check port 9200 inter 12000 rise 3 fall 3 backend stats-back mode http balance roundrobin stats uri /haproxy/stats stats auth haproxy:password backend pxc-onenode-back mode tcp balance leastconn option httpchk server c1 10.0.0.106:33061 check port 9200 inter 12000 rise 3 fall 3 server c2 10.0.0.107:33061 check port 9200 inter 12000 rise 3 fall 3 backup backend pxc-referencenode-back mode tcp balance leastconn option httpchk server c0 10.0.0.105:33061 check port 9200 inter 12000 rise 3 fall 3 In order for HAProxy to determine if a cluster node is alive, the clustercheck utility (included in the percona-xtradb-cluster package) is used, which displays the status of the node (Synced / Not Synced) as an HTTP response. Each node must have a xinetd service configured:
/etc/xinetd.d/mysqlchk
service mysqlchk { disable = no flags = REUSE socket_type = stream port = 9200 wait = no user = nobody server = /usr/bin/clustercheck log_on_failure += USERID only_from = 0.0.0.0/0 per_source = UNLIMITED } / etc / services
... # Local services mysqlchk 9200/tcp # mysqlchk HAProxy raises the web server and provides a script to view statistics, which is very convenient for visual monitoring of the cluster status.
The URL looks like this:
http: // VIP: 81 / haproxy / statsPort, as well as login and password for Basic authorization are specified in the config.
The issue of setting up a cluster with balancing via HAProxy is well discussed here: www.mysqlperformanceblog.com/2012/06/20/percona-xtradb-cluster-reference-architecture-with-haproxy
Keepalived and VIP
$ echo "net.ipv4.ip_nonlocal_bind=1" >> /etc/sysctl.conf && sysctl -p /etc/keepalived/keepalived.conf
vrrp_script chk_haproxy { # Requires keepalived-1.1.13 script "killall -0 haproxy" # cheaper than pidof interval 2 # check every 2 seconds weight 2 # add 2 points of prio if OK } vrrp_instance VI_1 { interface eth0 state MASTER # SLAVE on backup virtual_router_id 51 priority 101 # 101 on master, 100 and 99 on backup virtual_ipaddress { 10.0.0.70 } track_script { chk_haproxy } } Node configuration
On Habré already have an article about installing and testing PXC: habrahabr.ru/post/152969 , where both issues are discussed in detail, so I omit the installation. But I will describe the configuration.
First of all, do not forget to synchronize the time on all nodes. I missed this moment, and for a long time I could not understand why my SST hangs tightly - it started, hung in the processes, but in fact nothing happened.
my.cnf on Node A (in my configs is node105 ):
[mysqld_safe] wsrep_urls=gcomm://10.0.0.106:4567,gcomm://10.0.0.107:4567 # wsrep_urls=gcomm://10.0.0.106:4567,gcomm://10.0.0.107:4567,gcomm:// # - , # , .. # , [mysqld] port=33061 bind-address=10.0.0.105 datadir=/var/lib/mysql skip-name-resolve log_error=/var/log/mysql/error.log binlog_format=ROW wsrep_provider=/usr/lib/libgalera_smm.so wsrep_slave_threads=16 wsrep_cluster_name=cluster0 wsrep_node_name=node105 wsrep_sst_method=xtrabackup wsrep_sst_auth=backup:password innodb_locks_unsafe_for_binlog=1 innodb_autoinc_lock_mode=2 innodb_buffer_pool_size=8G innodb_log_file_size=128M innodb_log_buffer_size=4M innodb-file-per-table Further, only different parameters:
Node B (node106)
[mysqld_safe] wsrep_urls=gcomm://10.0.0.105:4567 [mysqld] bind-address=10.0.0.106 wsrep_node_name=node106 wsrep_sst_donor=node105 Node C (node107)
[mysqld_safe] wsrep_urls=gcomm://10.0.0.105:4567 [mysqld] bind-address=10.0.0.107 wsrep_node_name=node107 wsrep_sst_donor=node105 In the last two configs, we unequivocally tell the server where to look for the first node in the cluster (which knows where all the members of the group live), and what exactly from it, and not from the other available, you need to take data for synchronization.
It is on this configuration that I stopped now, and I am going to gradually transfer projects to the cluster. I plan to continue writing about my experience further.
Problematic issues
I’ll mark here the questions to which I didn’t immediately find the answer, but the answer to which is especially important for understanding the technology and proper work with the cluster.
Why is it recommended to write on one node of all available in the cluster? After all, it would seem that this is contrary to the idea of multi-master replication.
When I first saw this recommendation, I was very upset. I imagined a multi-master in such a way that you can write about any node without worrying about anything, and the changes are guaranteed to be applied synchronously on all nodes. But the harsh realities of life are such that with this approach cluster-wide deadlocks may be possible. The probability is especially great in case of a parallel change of the same data in long transactions. Since I am not yet an expert in this matter, I can not explain this process on the fingers. But there is a good article where this problem is covered in the most detailed way: Percona XtraDB Cluster: Multi-node writing and Unexpected deadlocks
My own tests showed that with aggressive recording on all the nodes they went one after another, leaving only the Reference Node working, i.e. in fact, we can say that the cluster stopped working. This is certainly a minus of such a configuration, because the third node could in this case take the load on itself, but we are sure that the data is safe and, in the most extreme case, we can manually start it in the single server mode.
How to correctly specify the IP addresses of the nodes existing in the cluster when connecting a new one?
There are 2 directives for this:[mysqld_safe] wsrep_urls [mysqld] wsrep_cluster_address
The first, if I understood correctly, was added Galera relatively recently to be able to specify several node addresses at once. There are no more fundamental differences.
The values of these directives at first caused me a special confusion.
The fact is that many manuals advised to leave an empty gcomm: // value in wsrep_urls on the first node of the cluster.
It turned out that it is wrong. Having gcomm: // means initializing a new cluster. Therefore, immediately after the start of the first node in its config, you need to delete this value. Otherwise, after restarting this node, you will receive two different clusters, one of which will consist only of the first node.
For myself, I derived the configuration order at startup and restart of the cluster (already described above in more detail)
1. Node A: start with gcomm: // B, gcomm: // C, gcomm: //
2. Node A: deleting gcomm: // at the end of the line
3. Nodes B, C: run with gcomm: // A
NB: it is necessary to specify the port number for Group Communication requests, the default is 4567. That is, the correct entry: gcomm: // A: 4567
Can I write to the donor node with a non-blocking xtrabackup as an SST method?
During SST, a clustercheck on the donor will issue HTTP 503, respectively for HAProxy or another LB that uses this utility to determine status, the donor node will be considered inaccessible, as well as the node to which the transfer is made. But this behavior can be changed by editing clustercheck , which is essentially a regular bash script.
This is done by the following edit:
/ usr / bin / clustercheck#AVAILABLE_WHEN_DONOR=0 AVAILABLE_WHEN_DONOR=1
NB: note that you can only do this if you are sure that xtrabackup is used as SST, and not some other method. In our case, when we use a donor without a load, such editing does not make sense at all.
useful links
Percona XtraDB Cluster
XtraDB Cluster on mysqlperfomanceblog.com
Percona Community Forums
Percona Discussion Google group
Galera wiki
Source: https://habr.com/ru/post/158377/
All Articles