Text Mining Framework (Java)
What is it and for whom (instead of entry)
In this article I would like to talk about the small results of my research activities in the field of Text Mining. These very “results” became a small FrameWork, which, as yet, doesn’t hold out very well, but we are growing =). This project is the implementation in practice of some theoretical concepts developed by me. As a consequence of this, I imagine the possibilities that he may potentially have at the end of the implementation of all ideas. Named this creation: "Text Mining FrameWork" (TextMF). Let's take a brief look at what TextMF will allow in its first final version and what is working now.
Should be in the final version :
Already implemented (partially available or undergoing testing) :
')
Why another text processing library?
The point is that the goal of this project is not to create a tool that can be used to implement some kind of word processing algorithm (such as Python NLTK and similar ones), but to enable the use of ready-made algorithms. And at the same time to test in practice your own algorithm. Those. This is not another statistical analyzer or a set of containers optimized for working with text data. Not! This is a set of heuristics that will work out of the box, without needing additional knowledge.
What input data does TextMF work with: for now only text files. Of course, further support for much larger input formats is planned. It is also planned to make integration with the Web, so that it would be possible to calmly analyze Web pages.
Turns and Passwords
The project is distributed through the BitBucket repository.
Clone it yourself and connect to your project =) Everything is extremely simple. Soon the assemblies will be available as a plug-in jar.
Usage example
Word processing often takes a lot of time, especially if you try to open a whole book! So in order to "try it out" I highly recommend limiting yourself to a few page texts from sites. However, very small texts can also give not very good results, due to the lack of information in them.
As mentioned earlier, the basic idea is to maximize ease of use and hiding heuristics and algorithms. So everything is trite:
Again, getting the topic is quite a long procedure, so calling this method be careful;) It will by itself implement the asynchronous method for getting the topic, but later. It is also VERY important to note that the quality of the work of the methods increases depending on the size of the text submitted to the input. The more information there is, as a rule, the greater the opportunity to learn a language. However, the time it takes to open files increases significantly as the size of the content increases.
Small UI program
For a visual demonstration of some of the functions of the program, my colleague by the name of Andrew, in haste was written a small UI client. At the current stage, it is simply an introductory nature, as it is sometimes more convenient to use it. It is written in Java FX, and is not yet distributed as a separate jar file. In order to “touch” him, you need to collect it = (.
Main program window:
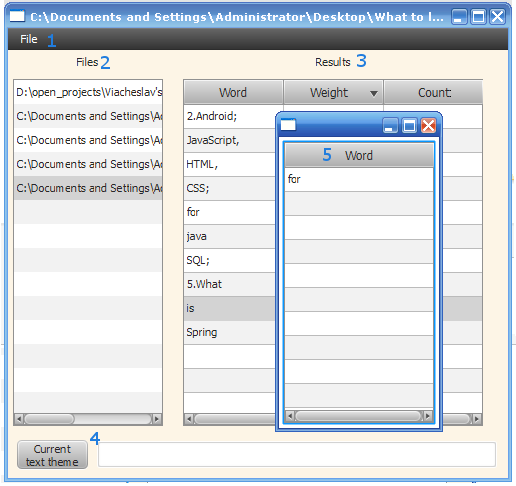
1) Text selection menu for processing;
2) List of selected files;
3) Results of work:
a) the word found in the text;
b) the weight of the word in the text;
c) the number of repetitions in the text
4) A field for displaying the topic of the text;
5) List of word forms.
Let's see what we can learn using our program for this text: Owners of the Volga and the Muscovites will be given another year :
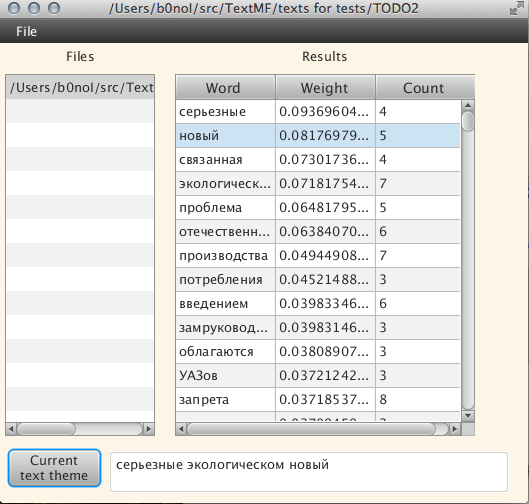
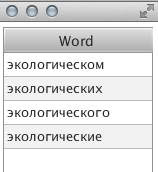
The search for the topic was carried out for about a minute (long, I agree). When choosing a particular word, you can see its word forms:

or here:
And now let's try another text: “The aliens kidnapped a family of Ukrainians and told about the future of earthmen! ", Probably one of the most" yellow "texts =):
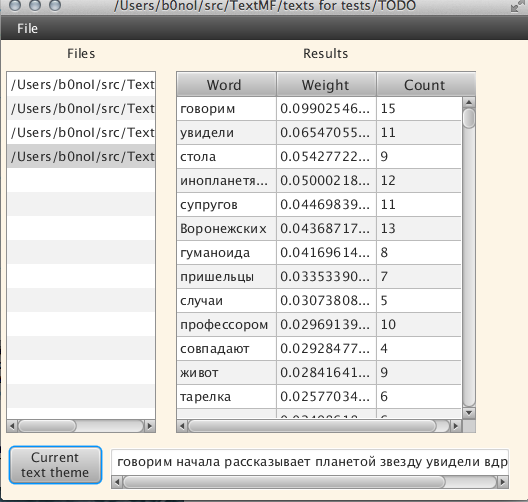
The text opened for a long time, probably a minute, I was looking for a topic somewhere the same. Of course, under the theme of the text is to understand the chain of words that the algorithm considered as the theme of the text. In the future, the algorithm will be able to produce output in a readable form, but this is the future, and now
We need your help
Of course, we really need your help! A lot of tasks, and the project is free. Tasks start from the simplest ones: to do the site, write examples, document the code, to the most hardcore ones: to help in optimizing the mat. apparatus and refine it. Now, for example, it would be nice for someone to take on the issue of expanding input formats and do something more than just a text file. Testing assistance is also very important. The project has a domain: www.textmf.com , however it’s empty and I would be very happy if someone helped me fix it =)
For any offers of cooperation, please contact: Viacheslav@b0noI.com
Immediate plans
From what will be in the near future (I think within a month or two) with the project:
Far plans
Now TextMF has become a semi-finalist of the project www.ukrinnovation.com . So there is, albeit a small, but still a chance to get investment for development.
I know that for now this is a dream, but if I was asked what functionality I see at the end, I would answer: a library, using which you can write a chat bot that will pass the Turing test. If we talk more real, then most likely the engines for dynamic tracking of information on the Internet. Tracking links and control their changes. And, of course, something to create any local search engines.
The idea itself has enormous potential, there are spam filters, search engines, automatic referencing systems, and many, many things that can be built on the basis of such a framework.
TextMF authors:
Your humble servant Vyacheslav V Kovalevsky and
UI developer Andrei Prischepa (vinglfm@gmail.com)
In this article I would like to talk about the small results of my research activities in the field of Text Mining. These very “results” became a small FrameWork, which, as yet, doesn’t hold out very well, but we are growing =). This project is the implementation in practice of some theoretical concepts developed by me. As a consequence of this, I imagine the possibilities that he may potentially have at the end of the implementation of all ideas. Named this creation: "Text Mining FrameWork" (TextMF). Let's take a brief look at what TextMF will allow in its first final version and what is working now.
Should be in the final version :
- Statistical text analysis;
- Search for all words and word forms of each word in the text;
- Ranking of words by weight in the text;
- Search for subjects in the text in question;
- Links between subjects in the text (direct and non-direct links);
- Text summarization;
- Determining the topic of the text;
- Language training;
- Organization of interaction with the user by means of communication (chat).
Already implemented (partially available or undergoing testing) :
')
- Statistical analysis of the text (as long as it is implemented very partially);
- Search for all words and word forms in the text;
- Sort words by their weight in this text;
- Search for persons in the text;
- Definition of the text theme (testing and adjustment of formulas in progress).
Why another text processing library?
The point is that the goal of this project is not to create a tool that can be used to implement some kind of word processing algorithm (such as Python NLTK and similar ones), but to enable the use of ready-made algorithms. And at the same time to test in practice your own algorithm. Those. This is not another statistical analyzer or a set of containers optimized for working with text data. Not! This is a set of heuristics that will work out of the box, without needing additional knowledge.
What input data does TextMF work with: for now only text files. Of course, further support for much larger input formats is planned. It is also planned to make integration with the Web, so that it would be possible to calmly analyze Web pages.
Turns and Passwords
The project is distributed through the BitBucket repository.
Clone it yourself and connect to your project =) Everything is extremely simple. Soon the assemblies will be available as a plug-in jar.
Usage example
Word processing often takes a lot of time, especially if you try to open a whole book! So in order to "try it out" I highly recommend limiting yourself to a few page texts from sites. However, very small texts can also give not very good results, due to the lack of information in them.
As mentioned earlier, the basic idea is to maximize ease of use and hiding heuristics and algorithms. So everything is trite:
// , TEXT_FILE_NAME Text text = new Text(TEXT_FILE_NAME); // List<Word> words = text.getWords(); // List<Word> theme = text.getThem(); // Word word = words.get(0); // List<String> wordForms =word.getWordForms(); // long count = word.getCount(); // , List<Word> objects = text.getObjects(); // double weight = text.getWordWeight(word); Again, getting the topic is quite a long procedure, so calling this method be careful;) It will by itself implement the asynchronous method for getting the topic, but later. It is also VERY important to note that the quality of the work of the methods increases depending on the size of the text submitted to the input. The more information there is, as a rule, the greater the opportunity to learn a language. However, the time it takes to open files increases significantly as the size of the content increases.
Small UI program
For a visual demonstration of some of the functions of the program, my colleague by the name of Andrew, in haste was written a small UI client. At the current stage, it is simply an introductory nature, as it is sometimes more convenient to use it. It is written in Java FX, and is not yet distributed as a separate jar file. In order to “touch” him, you need to collect it = (.
Main program window:
1) Text selection menu for processing;
2) List of selected files;
3) Results of work:
a) the word found in the text;
b) the weight of the word in the text;
c) the number of repetitions in the text
4) A field for displaying the topic of the text;
5) List of word forms.
Let's see what we can learn using our program for this text: Owners of the Volga and the Muscovites will be given another year :
The search for the topic was carried out for about a minute (long, I agree). When choosing a particular word, you can see its word forms:
or here:
And now let's try another text: “The aliens kidnapped a family of Ukrainians and told about the future of earthmen! ", Probably one of the most" yellow "texts =):
The text opened for a long time, probably a minute, I was looking for a topic somewhere the same. Of course, under the theme of the text is to understand the chain of words that the algorithm considered as the theme of the text. In the future, the algorithm will be able to produce output in a readable form, but this is the future, and now
We need your help
Of course, we really need your help! A lot of tasks, and the project is free. Tasks start from the simplest ones: to do the site, write examples, document the code, to the most hardcore ones: to help in optimizing the mat. apparatus and refine it. Now, for example, it would be nice for someone to take on the issue of expanding input formats and do something more than just a text file. Testing assistance is also very important. The project has a domain: www.textmf.com , however it’s empty and I would be very happy if someone helped me fix it =)
For any offers of cooperation, please contact: Viacheslav@b0noI.com
Immediate plans
From what will be in the near future (I think within a month or two) with the project:
- add assembly jar file;
- the project will be divided into core and UI, i.e. add another repository;
- implementation of long-term memory will begin;
- analysis of relationships between persons;
- the possibility of abstracting the text will appear;
- creating a self-sufficient jar with UI.
Far plans
Now TextMF has become a semi-finalist of the project www.ukrinnovation.com . So there is, albeit a small, but still a chance to get investment for development.
I know that for now this is a dream, but if I was asked what functionality I see at the end, I would answer: a library, using which you can write a chat bot that will pass the Turing test. If we talk more real, then most likely the engines for dynamic tracking of information on the Internet. Tracking links and control their changes. And, of course, something to create any local search engines.
The idea itself has enormous potential, there are spam filters, search engines, automatic referencing systems, and many, many things that can be built on the basis of such a framework.
TextMF authors:
Your humble servant Vyacheslav V Kovalevsky and
UI developer Andrei Prischepa (vinglfm@gmail.com)
Source: https://habr.com/ru/post/158165/
All Articles