Clustering duplicates in search by pictures
Every month on Yandex, more than 20 million people use the search by pictures. And if any of them are looking for photographs of [ Marilyn Monroe ], this does not mean that they need to find only the most famous pictures of the actress. In this situation, the results in which most of the images found will be copies of the same pictures are unlikely to suit users. They will have to scroll through a large number of pages to see different photos of Monroe. In order to make it easier for people to do similar tasks, we need to sort the pictures in the search results so that they do not repeat. And we learned to "lay them out on the shelves."
When, in 2002, a search in pictures appeared on Yandex, technologies that allow computers to directly “see” what objects are in an image were not there at all. They appear now, but so far their degree of development is not enough for the computer to recognize Marilyn Monroe in the face or recognize the forest in the photo and immediately show it on an appropriate request. Therefore, the task to improve the methods that were invented in the first stages remains relevant.
')
So, the computer still needs to understand what is shown in the picture. He does not know how to “see”, but at the same time we have technologies that are well looking for text documents. And it is they who will help us: the image on the Internet is almost always accompanied by some text. He does not necessarily directly describe what is depicted in the picture, but is almost always associated with it in meaning and content. That is, we assume that his name will be mentioned with a high probability next to the photo of Einstein. We call such texts prikartinochnye.
Based on this data, the computer understands exactly which documents to show to the user at the request of [ Marilyn Monroe ]. As a result, in the search results a person will see miniatures of relevant images or, as you can call them, tumblers. They will be the same for copies of the same images. Hence our name for them - tumbler duplicates. Essentially the same pictures can be of different sizes and degrees of compression, but this does not change the content of the image. And sometimes in the pictures can make some changes. For example, add watermarks or logos, change colors or crop. But this will not be enough to consider this image new. Our task is to make sure that there are no duplicate thumbnails on the image search results page, and for each group of copies there is one that unites them.
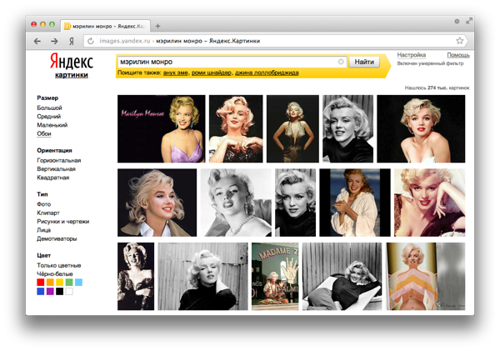
The data of the text-based texts basically made us understand that in the photos found Marilyn Monroe. But there are few of them to determine which of them are duplicates. And at this stage, we can help the existing technology of computer vision.
When you and I say that a child looks like a parent, it often sounds like “papa’s nose” or “mother’s eyes”. That is, we note some features of the faces of the parents, which are preserved in the child.
And what if you try to teach a computer to use a similar principle? In this case, at the first stage, he must understand which points in the picture you should look at. To do this, the image is processed with special filters that help to highlight their contours. On them the computer finds key points which do not change under any changes of the images themselves, and looks at what is around them. In order for the computer to "consider" these fragments, they need to be converted to digital format. So the description will remain true, even if the image is stretched, rotated or subjected to some other transformations. In fact, we to some extent train the computer to look at the image in the way that a person looks at it.
As a result, each picture receives a set of descriptions of what is at its cue points. And if the set of these areas of one image is similar to the set of areas of another image, then we can draw conclusions about the degree of their similarity in general.
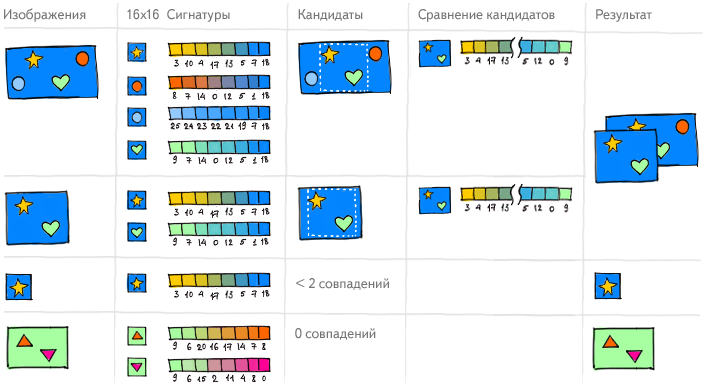
But there is a problem. It is impossible to decide that the images are duplicates without knowing what is depicted on them. We can decide for ourselves that a change of only 5% of the area allows us to consider them as such, but imagine pictures of a chessboard before the start of the game and after one or two moves. These are different pictures, although not more than 5% of them formally changed. And if you add, for example, a logo to one of the images of a chessboard with the same positions, they will also differ by 5%, but remain duplicates. Yes, to some extent we taught the computer to see the picture, but so far the technologies have not reached an absolute understanding of the subject area of images, and we continue to work on solving this problem.
All the operations described above should be carried out with each image indexed by us, and in total there are 10 billion images in our index. And this is not the final figure. To match the growth rate of content on the Internet, using our old algorithm, it would be necessary to increase resources incredibly quickly. Naturally, it took to find a more rational solution to this infrastructure problem. And we could do it.
Now, for example, to add and process 10 million new images that go through Yandex.Images every day, you do not need to re-launch the process on the billions already existing in the database.
In addition, the information that some images on the Internet are copies of each other helps us in ranking web documents in a large search result. Same pictures, like links, link documents together. Thanks to this, we can consider how valuable this or that page is to respond to a search query. Therefore, the above described technology is important not only for Yandex.Kartinok, but also in principle for our search.
And if you go back directly to the search by pictures, then there is another passing problem, which is solved by gluing duplicates - we can find a similar image even when it is not accompanied by text-based text. This is useful when it is in this form that the picture corresponds to the quality the person needs.
When, in 2002, a search in pictures appeared on Yandex, technologies that allow computers to directly “see” what objects are in an image were not there at all. They appear now, but so far their degree of development is not enough for the computer to recognize Marilyn Monroe in the face or recognize the forest in the photo and immediately show it on an appropriate request. Therefore, the task to improve the methods that were invented in the first stages remains relevant.
')
So, the computer still needs to understand what is shown in the picture. He does not know how to “see”, but at the same time we have technologies that are well looking for text documents. And it is they who will help us: the image on the Internet is almost always accompanied by some text. He does not necessarily directly describe what is depicted in the picture, but is almost always associated with it in meaning and content. That is, we assume that his name will be mentioned with a high probability next to the photo of Einstein. We call such texts prikartinochnye.
Based on this data, the computer understands exactly which documents to show to the user at the request of [ Marilyn Monroe ]. As a result, in the search results a person will see miniatures of relevant images or, as you can call them, tumblers. They will be the same for copies of the same images. Hence our name for them - tumbler duplicates. Essentially the same pictures can be of different sizes and degrees of compression, but this does not change the content of the image. And sometimes in the pictures can make some changes. For example, add watermarks or logos, change colors or crop. But this will not be enough to consider this image new. Our task is to make sure that there are no duplicate thumbnails on the image search results page, and for each group of copies there is one that unites them.
The data of the text-based texts basically made us understand that in the photos found Marilyn Monroe. But there are few of them to determine which of them are duplicates. And at this stage, we can help the existing technology of computer vision.
When you and I say that a child looks like a parent, it often sounds like “papa’s nose” or “mother’s eyes”. That is, we note some features of the faces of the parents, which are preserved in the child.
And what if you try to teach a computer to use a similar principle? In this case, at the first stage, he must understand which points in the picture you should look at. To do this, the image is processed with special filters that help to highlight their contours. On them the computer finds key points which do not change under any changes of the images themselves, and looks at what is around them. In order for the computer to "consider" these fragments, they need to be converted to digital format. So the description will remain true, even if the image is stretched, rotated or subjected to some other transformations. In fact, we to some extent train the computer to look at the image in the way that a person looks at it.
As a result, each picture receives a set of descriptions of what is at its cue points. And if the set of these areas of one image is similar to the set of areas of another image, then we can draw conclusions about the degree of their similarity in general.
But there is a problem. It is impossible to decide that the images are duplicates without knowing what is depicted on them. We can decide for ourselves that a change of only 5% of the area allows us to consider them as such, but imagine pictures of a chessboard before the start of the game and after one or two moves. These are different pictures, although not more than 5% of them formally changed. And if you add, for example, a logo to one of the images of a chessboard with the same positions, they will also differ by 5%, but remain duplicates. Yes, to some extent we taught the computer to see the picture, but so far the technologies have not reached an absolute understanding of the subject area of images, and we continue to work on solving this problem.
All the operations described above should be carried out with each image indexed by us, and in total there are 10 billion images in our index. And this is not the final figure. To match the growth rate of content on the Internet, using our old algorithm, it would be necessary to increase resources incredibly quickly. Naturally, it took to find a more rational solution to this infrastructure problem. And we could do it.
Now, for example, to add and process 10 million new images that go through Yandex.Images every day, you do not need to re-launch the process on the billions already existing in the database.
In addition, the information that some images on the Internet are copies of each other helps us in ranking web documents in a large search result. Same pictures, like links, link documents together. Thanks to this, we can consider how valuable this or that page is to respond to a search query. Therefore, the above described technology is important not only for Yandex.Kartinok, but also in principle for our search.
And if you go back directly to the search by pictures, then there is another passing problem, which is solved by gluing duplicates - we can find a similar image even when it is not accompanied by text-based text. This is useful when it is in this form that the picture corresponds to the quality the person needs.
Source: https://habr.com/ru/post/158067/
All Articles