Downloading music collection vk.com
Hi, Habrahabr!
I decided to somehow download my music collection from vkontakte (which is almost 1000 songs). I did not want to contact vk.api, so I decided to use the python + request library. What came out of it - under the cut!
First, let's see what our browser does when we turn to our audio page on VKontakte. Open the developer tools (I used Chrome, F12) and go to vk.com/audio . We can see all the requests that the browser makes:
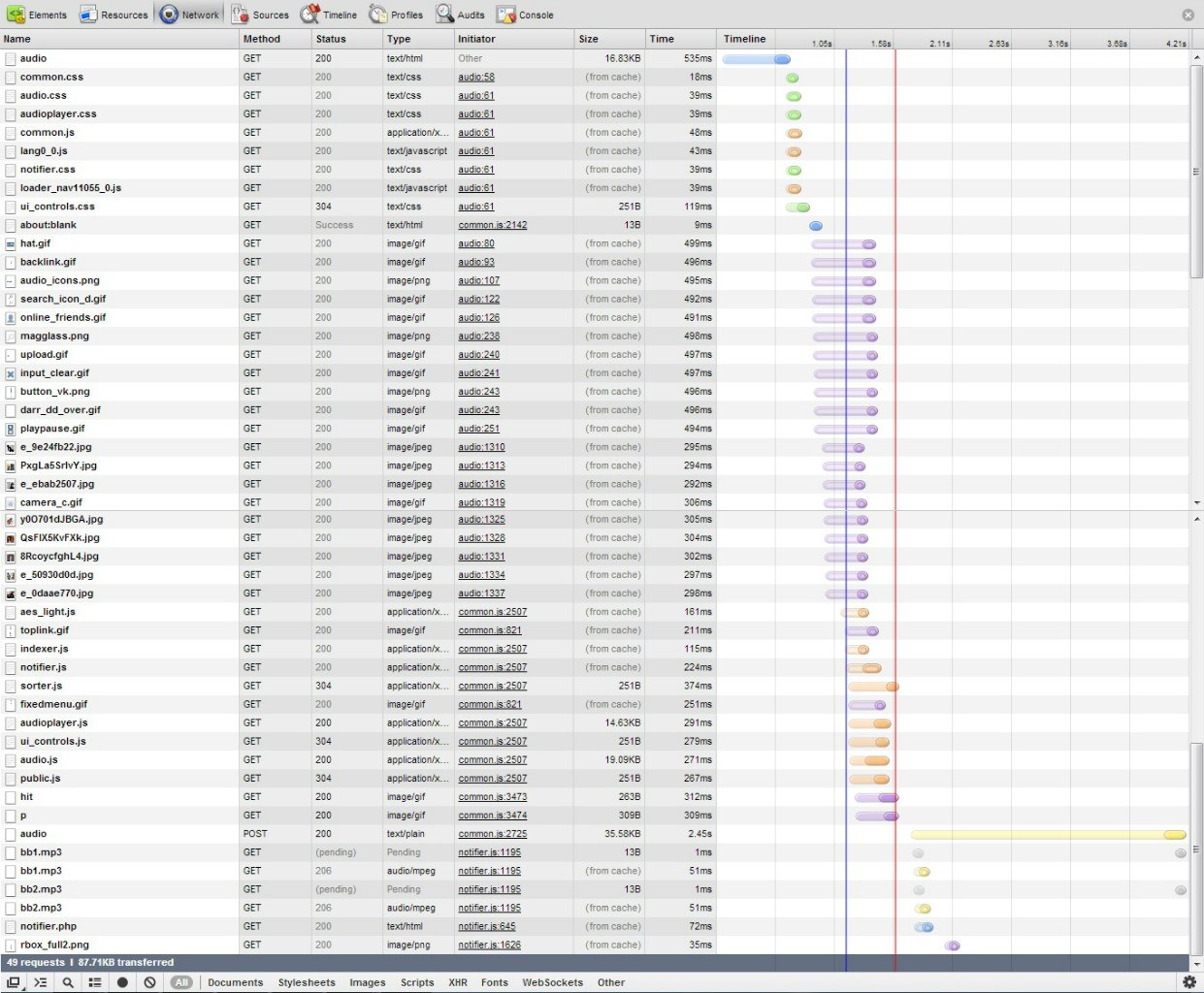
')
The meaning of the actions of the browser is as follows:
The first line is the GET request, which we send to the server when we first enter the page. In response, the server gives us the html page code.
Then the browser begins to load all the necessary resources: css, js and images.
Towards the end of the list we see a non-standard line: this is a POST request with the name audio. Most likely, this request sends javascript to get a list of audio recordings.
In the response, the server returns to us a line like:
Bingo! This is exactly what we need. In response, the server returns us a JSON list of all our compositions and for each of them passes the following parameters:
How do we get the desired list? Let's see what headers the browser sends in our request:
Let's try to simulate our query:
The function request.post creates a POST request to the url. It can pass several parameters. Here are the main ones:
The function will display
The result is predictable - after all, we did not indicate that we are an authorized user. For this you need to pass the server cookies. Let's fix our query a bit:
Now we get what we need.
Good. The list we received. Now you need to otparsit and download each song separately. I decided not to bother, and just used regular expressions:
The main function here is OneDownload (). In fact, it is she who downloads the songs. This is done using the standard function urllib.urlretrieve (url, file_path, ...). This function downloads the data that the server returns when accessing the url and writes to the file that is in the file_path path.
Everything is good, everything is downloaded, but slowly!
We can try to parallelize our algorithm. Functions that I would like to perform in parallel is OneDownload. Create a parallelization decorator:
A decorator in Python is a function that takes a function as an argument and performs some action.
This decorator simply starts the received function in a separate thread.
Add a global variable - the number of threads. It will not be possible to directly change this variable from Threads, therefore we add functions
increment, and getting:
Now we make changes to the code. Here is the final version of the program:
Now everything works.
Sources and compiled version can be downloaded from this link:
VKmusic
#UPD
In the compiled version there was a bug, the music swayed only from my page. Corrected version:
VKMusic
I decided to somehow download my music collection from vkontakte (which is almost 1000 songs). I did not want to contact vk.api, so I decided to use the python + request library. What came out of it - under the cut!
First, let's see what our browser does when we turn to our audio page on VKontakte. Open the developer tools (I used Chrome, F12) and go to vk.com/audio . We can see all the requests that the browser makes:
')
The meaning of the actions of the browser is as follows:
The first line is the GET request, which we send to the server when we first enter the page. In response, the server gives us the html page code.
Then the browser begins to load all the necessary resources: css, js and images.
Towards the end of the list we see a non-standard line: this is a POST request with the name audio. Most likely, this request sends javascript to get a list of audio recordings.
In the response, the server returns to us a line like:
11055<!>audio.css,audio.js<!>0<!>6362<!>0<!>{"all":[ ['17738938','173762121', 'http://cs1276.userapi.com/u1040081/audio/c0e97293c5e2.mp3','300','5:00', 'Louis Prima','Sing, Sing, Sing (With A Swing)','369754','0','0','','0','1'], ['17738938','173368012', 'http://cs4372.userapi.com/u9237008/audio/5f51ceac6ca1.mp3','326','5:26', 'Look at my horse','My horse is amazing','10324035','0','0','','0','1'], ... Bingo! This is exactly what we need. In response, the server returns us a JSON list of all our compositions and for each of them passes the following parameters:
- 0 - my id
- 1 - composition id
- 2 - link to the song
- 3 - bitrate?
- 4 - duration
- 5 - author
- 6 - the name of the composition
- 7 - size in bytes?
- The remaining parameters are not clear.
We get a list of audio recordings
How do we get the desired list? Let's see what headers the browser sends in our request:
Request Headers: Accept:*/* Accept-Charset:windows-1251,utf-8;q=0.7,*;q=0.3 Accept-Encoding:gzip,deflate,sdch Accept-Language:ru-RU,ru;q=0.8,en-US;q=0.6,en;q=0.4 Connection:keep-alive Content-Length:45 Content-Type:application/x-www-form-urlencoded Cookie:remixlang=0; remixseenads=2; audio_vol=100; remixdt=0;remixsid=************; remixflash=11.4.31 Host:vk.com Origin:http://vk.com Referer:http://vk.com/audio User-Agent:Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.4 (KHTML, like Gecko) Chrome/22.0.1229.94 Safari/537.4 X-Requested-With:XMLHttpRequest Form: Dataview URL encoded act:load_audios_silent al:1 gid:0 id:17738938 Let's try to simulate our query:
import requests as r def getAudio(): response = r.post(url = "http://vk.com/audio", data = { "act":"load_audios_silent", "al":"1", "gid":"0", "id":"17738938" } ) print response.content getAudio() The function request.post creates a POST request to the url. It can pass several parameters. Here are the main ones:
- headers - dictionary of the leaders we want to send to the server
- data - a dictionary of data to be transmitted in the request
The function will display
<!--11055<!>audio.css,audio.js<!>0<!>6362<!>3<!>230b860567731c4875 The result is predictable - after all, we did not indicate that we are an authorized user. For this you need to pass the server cookies. Let's fix our query a bit:
import requests as r def getAudio(): response = r.post( "http://vk.com/audio", data = { 'act':"load_audios_silent", "al":"1", "gid":"0", "id":"17738938" }, headers = { "Cookie":"remixlang=0; remixseenads=2; remixdt=0; remixsid=**************; audio_vol=96; remixflash=11.4.31" } ) print response.content[0:1000] getAudio() Now we get what we need.
Good. The list we received. Now you need to otparsit and download each song separately. I decided not to bother, and just used regular expressions:
#-*-coding:cp1251-*- import requests as r import re import random as ran import os import urllib as ur # : ALLOW_SYMBOLS = " qwertyuiopasdfghjklzxcvbnm.,-()" COOKIE = "" # cookies, . def getAllowName(string): """ , ALLOW_SYMBOLS""" s='' for x in string.lower(): if x in ALLOW_SYMBOLS: s += x return s def getRandomElement(arr, delete = False): """ arr. delete = True, .""" index = ran.randrange(0, len(arr), 1) value = arr[index] if delete: arr.remove(value) return value def getAudio(): """ . """ response = r.post( "http://vk.com/audio", data = { 'act':"load_audios_silent", "al":"1", "gid":"0", "id":"17738938" }, headers = { "Cookie":COOKIE } ) i=0 pat = re.compile(r"\[.+?\]") # [.*] return pat.findall(response.content) # already_added = [] # id , . pat = re.compile(r"\'(.+?)\'") # '.*' def OneDownload(x): """ , ( ['...', '...', '...', ...]) """ global already_added try: elements = pat.findall(x) # id, url, author, name = (elements[1], elements[2], elements[5], elements[6]) # - id, url, author, name except: return if id not in already_added: # already_added.append(id) # file_path = "audio/"+getAllowName(author+" - "+name)+".mp3" # , with open(file_path, "w"): # pass ur.urlretrieve(url, file_path) # print name, "downloaded" def getFirstNSongs(first=0, last = None): """, , """ if not os.path.exists(os.path.join(os.getcwd(), 'audio')): # audio os.mkdir('audio') songs = getAudio() # # , first last: if last!=None: songs = songs[first:last+1] else: songs = songs[first:] for x in songs: # OneDownload(x) # getFirstNSongs(last = 10) The main function here is OneDownload (). In fact, it is she who downloads the songs. This is done using the standard function urllib.urlretrieve (url, file_path, ...). This function downloads the data that the server returns when accessing the url and writes to the file that is in the file_path path.
Everything is good, everything is downloaded, but slowly!
We can try to parallelize our algorithm. Functions that I would like to perform in parallel is OneDownload. Create a parallelization decorator:
def Thread(f): def _inside(*a, **k): thr = threading.Thread(target = f, args = a, kwargs = k) thr.start() return _inside A decorator in Python is a function that takes a function as an argument and performs some action.
This decorator simply starts the received function in a separate thread.
Add a global variable - the number of threads. It will not be possible to directly change this variable from Threads, therefore we add functions
increment, and getting:
alive_threads = 0 def inc(x): # global alive_threads alive_threads+=x return alive_threads def get(): # global alive_threads return alive_threads Now we make changes to the code. Here is the final version of the program:
#-*-coding:cp1251-*- import requests as r import re import threading import time import random as ran import os import urllib as ur THREADS_COUNT = 10 ALLOW_SYMBOLS = " qwertyuiopasdfghjklzxcvbnm.,-()" COOKIE = "" # cookies def getAllowName(string): s='' print string.lower() for x in string.lower(): if x in ALLOW_SYMBOLS: s += x return s def getRandomElement(arr, delete = False): index = ran.randrange(0, len(arr), 1) value = arr[index] if delete: arr.remove(value) return value alive_threads = 0 def inc(x): global alive_threads alive_threads+=x return alive_threads def get(): global alive_threads return alive_threads def Thread(f): def _inside(*a, **k): thr = threading.Thread(target = f, args = a, kwargs = k) thr.start() return _inside def getAudio(): response = r.post( "http://vk.com/audio", data = { 'act':"load_audios_silent", "al":"1", "gid":"0", "id":"17738938" }, headers = { "Cookie":COOKIE } ) i=0 pat = re.compile(r"\[.+?\]") return pat.findall(response.content) already_added = [] # id , . pat = re.compile(r"\'(.+?)\'") # '.*' count = 0 @Thread def OneDownload(x): global already_added inc(1) # - try: elements = pat.findall(x) id, url, author, name = (elements[1], elements[2], elements[5], elements[6]) except: return if id not in already_added: already_added.append(id) file_path = "audio/"+getAllowName(author+" - "+name)+".mp3" with open(file_path, "w"): pass ur.urlretrieve(url, file_path) inc(-1) # - def getFirstNSongs(a=0, N = None): if not os.path.exists(os.path.join(os.getcwd(), 'audio')): os.mkdir('audio') songs = getAudio() if N!=None: songs = songs[a:N] else: songs = songs[a:] previous = 0 # cc=10 while (len(songs)>0 and len(songs)!=previous) or (len(songs) == previous and cc>0): # , 10 if previous != len(songs): previous = len(songs) #, . - cc=10 # - 10 else: cc-=1 # , 1. - 10 print " ", len(songs), " ", alive_threads while alive_threads<THREADS_COUNT: # x = getRandomElement(songs, delete = True) # , try: OneDownload(x) # except: songs.append(x) # - . while alive_threads>=THREADS_COUNT: time.sleep(10) # - 10 . getFirstNSongs(N=3) #, , 3 Now everything works.
Sources and compiled version can be downloaded from this link:
VKmusic
#UPD
In the compiled version there was a bug, the music swayed only from my page. Corrected version:
VKMusic
Source: https://habr.com/ru/post/157925/
All Articles