Is there a simple assessment of the quality of optimization of the application?

The quieter you go, the further you'll get...? Performance evaluation
For more than 7 years I have been doing performance analysis as part of the Performance Analysis group of the Novosibirsk branch of Intel. We are working to improve the performance of various applications, or rather, we are looking for ways in which our compiler could improve it. During this time, a useful experience has been accumulated, which, in my opinion, would be of interest to visitors of the esteemed Habr. In this case, it will not be about algorithmic optimization of applications, but about various modifications of applications without a fundamental change in their algorithms. It is clear that algorithmic program optimization also has the right to life, but this is a completely different task.
')
I am the developer of the Intel compiler, so all my research is related to various compiler optimizations, comparing different compilers (on Windows, this is usually a comparison of the Intel compiler with the Microsoft Visual Studio compiler). Actually, therefore, please do not treat my posts as advertising or anti-advertising. To illustrate my thoughts, I will use various tools, including those developed in our company. I hope that this post will grow into a series of articles on optimizing applications.
Is there a simple criterion for assessing the optimality of an application?
It is clear that any problem and task, including the task of improving application performance, begins with an examination of the current state of affairs. Evaluation is needed: how optimized the application is, and whether it makes sense to make efforts to speed it up. At first glance, the problem has a simple solution. It is enough to measure the CPU load to get such an estimate. Various performance analyzers make it possible not only to measure the execution time of various program sections, but also to calculate and link to the program code all intraprocessor events that occur during its execution. Using this information, you can estimate the load on the computational core. For example, to determine how many processor cycles on average it took to execute one instruction, and what reasons caused the execution delays. The proposed criterion links the efficiency of the kernel with the ability to improve application performance. Namely, if the kernel works efficiently, then there is no cause for concern - the program works optimally, otherwise the application can be improved and it makes sense to engage in its analysis. As a result of using such a criterion, works appear in which some processor events are analyzed, and the authors based on this analysis make assumptions about the possibilities of improving application performance. Probably, such methods of work are really useful for architects of computing systems and give them an opportunity to dream up about improving the architecture of the processor. But, unfortunately, for a programmer who thinks about improving the performance of his application, this method is extremely dubious, rarely works and does not answer the eternal question of the Russian intelligentsia: “What should I do? and is it possible to eat chicken with your hands?
In many cases, the maximum load on the computational core does not mean at all that it is impossible to improve the performance of the program and vice versa.
Let's look at a simple testik with the multiplication of rectangular matrices. Creating small working examples, in my opinion, is the best method of obtaining interesting information about the device of the universe, including the work of compilers and processors. In such tests, it is important that the execution time of the code being examined is long enough that it is not affected by the program load time and any random events, so you can execute the code being investigated many times.
#include <stdio.h> #include <stdlib.h> #define N 200 #define T 100 void matrix_mul_matrix(int t, int n, double *C, float *A, float *B) { int i,j,k; for (i=0; i<t; i++) for (j=0; j<t; j++) for(k=0;k<n;k++) C[i*t+j]+=(double)A[i*n+k] * (double)B[k*t+j]; } int main() { float *A,*B; double *C; int i,j; //... for(i=0;i<10000;i++) matrix_mul_matrix(T,N,C,A,B); printf("%f %f %f\n",C[0],C[1],C[100]); free(A); free(B); free(C); } On my lab machine with Windows Server 2008 R2 Enterprise and an Intel Xeon X5570 processor, I compile this program using the Microsoft VS 10.0 compiler. and Intel Parallel Studio XE2013. For simplicity, I work with the command line and take options corresponding to the release version of the compilation used by default in Visual Studio.
cl matrix.c / O2 / GL / GS / GR / W3 / nologo / Wp64 / Zi -Ob0 -Fematrix_cl
icl matrix.c / O2 / GL / GS / GR / W3 / nologo / Wp64 / Zi -Ob0 -Fematrix
It turns out that the operation time of matrix_cl is ~ 21.9 s, while the operating time of matrix is ~ 9.3 s.
Now let's see what Amplifier tells us about CPU usage. Intel VTune Amplifier XE 2011 is just a performance assessment tool that allows you to work with Intel processor processors.
Let's create two projects for the received applications in Amplifier and make a preliminary analysis - general exploration. So what do we see as a result? Here are the results of the "intelligence" application matrix_cl:

Pay attention to the CPI Rate (Clock per instruction, the average number of cycles per instruction). For my processor, the theoretical minimum of this value is 0.25. (Parallel execution of 4 instructions on 4 actuators). The number of CPI 0.546 is considered very good. There are of course delays. But, like there is nothing critical. The computing core works with a good load, and everything looks quite decent. Is it possible to understand from this assessment that the performance of the application can actually be more than doubled?
The results of the study for the matrix:
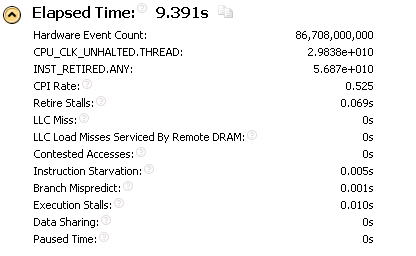
The magical performance improvement more than doubled, with virtually no effect on the main "ratings" of the computations collected by Intel VTune Amplifier XE 2011. That is, the study of the processor in this case did not give us any signals that the performance can be drastically improved.
This performance improvement was achieved through auto-vectorization. This is easy to see if you add -Qvec_report to the options for the Intel compiler. The compiler will issue
...
... \ matrix.c (9): (col. 5) remark: PERMUTED LOOP WAS VECTORIZED.
Those. application performance has been improved by applying cyclic permutation optimization. In order to understand that such optimization could be applied, it was necessary to investigate the matrix multiplication algorithm.
Now take an example of another kind and create a program that will bypass a long chain of objects:
#include <stdio.h> #include <stdlib.h> #define N 1000000 struct _planet { float x; float y; float z; double m; struct _planet *prev; struct _planet *next; } ; typedef struct _planet planet; planet* init_chain() { } int main() { planet *planet_chain; planet *cur; int i; double sum=0.0; planet_chain=init_chain(); for(i=0;i<1000;i++) { cur=planet_chain; while(cur) { sum += cur->m; cur=cur->next; } } printf("%f\n",sum); } Both compiler optimizers created applications running ~ 6.2s. Amplifier reports that everything is bad in this application:

The CPI rate is very bad, and most of the time the compute core is waiting for data to be processed.
So what to do with it? Suppose we continue research and establish that the reason for the poor loading of the computational core is the delay in the operation of the memory subsystem. Obviously, the kernel is badly loaded. But then this sacred knowledge helps us? What are the methods to improve the performance of the memory subsystem? Does the specificity of our application allow us to apply already known methods?
This is an example of an application in which everything is bad, and the situation cannot be radically rectified without changing the algorithm.
conclusion
Thus, simple calculations of various processor coefficients provide little information for evaluating the effectiveness of an application.
In this case, a simple analogue of the task of assessing the effectiveness of a running application is an athlete moving from point A to point B. If we take as a criterion for an athlete to perform optimally, the load on his muscles or compare his average speed on the track and the maximum speed with which a given athlete can move, then how far will we go with such criteria? If the athlete is bad, albeit very strong, and constantly breaks through the thicket, instead of running across the path, then you just need a smarter athlete. Conversely, if an athlete ran slowly, but his path ran through the swamp, where he had to stop, grope for a path and even go back periodically, then is the athlete to blame? You can get a more trained and fast athlete (for big money) to solve the problem, or you can get a competent coach who will analyze the race course at the start, the runner’s strengths and weaknesses, and then suggest the optimal route for the runner, and perhaps teach him to take it on the go the right decision in some simple situations.
In short, without analyzing the path that needed to be overcome and the knowledge of the strengths and weaknesses of the athlete, it is difficult to assess how good he really was at a distance.
Therefore, in my opinion, there is no simple universal working method for evaluating the effectiveness of the application and, therefore, simple ways to improve it. To solve this problem, you need to connect the brain and analyze a variety of situations, applying to them the well-known methods of improving performance. As in any business, a brain connection methodology is needed. To successfully solve a problem, he must know some things, for example:
1.) The main problems affecting the performance of the processor, and optimization methods that affect these problems.
2.) The main methods of compiler optimization. As a rule, all those methods that can help improve the performance of a program are already somehow taken into account and implemented in existing optimizing compilers. It is useful to know the tool that you use in your work. Perhaps success is simply adding another option. It is interesting to find out if your compiler can do this or that optimization, and why hasn’t it done for your code?
3.) Many of the well-known optimizations can effectively be made by hand. When can I try them? When is the application of this or that optimization profitable and why?
Accordingly, in the future, I will try to provide a sample of such a methodology and tell you about useful useful application optimization methods known to me.
Source: https://habr.com/ru/post/157671/
All Articles