Java.util.concurrent. * Overview
In everyday work, it’s not often the case that the java.util.concurrent package for multi-threading is encountered. Sometimes there are design restrictions on using java 1.4.2, where there is no this package, but most often there is enough normal synchronization and nothing supernatural is required. Fortunately, sometimes there are tasks that make you think a little about brains and either write a bicycle, or rummage through javadocs and find something more suitable. There are no problems with a bicycle - you just take it and write, since there is nothing super-complex in multithreading. On the other hand, less code - less bugs. Moreover, nobody in their right mind writes a multi-threading unit, since These are already complete integration tests with all the ensuing consequences.
What to choose for a particular case? In terms of parking and deadlines, it is quite difficult to cover the entire java.util.concurrent. Something similar is selected and go! So, gradually, ArrayBlockingQueue, ConcurrentHashMap, AtomicInteger, Collections.synchronizedList (new LinkedList ()) and other interesting things appear in the code. Sometimes right, sometimes not. At some point in time you begin to realize that more than 95% of the standard classes in java are not used at all in product development. Collections, primitives, shifting from one place to another, hibernate, spring or EJB, some other library and, voila, the application is ready.
In order to somehow streamline knowledge and facilitate entry into the topic, below is a review of classes for working with multithreading. I write primarily as a cheat sheet for myself. And if anyone else is fit, it is generally wonderful.
')
Immediately bring a couple of interesting links. The first is for those who float a little in multithreading. The second for "advanced" programmers - maybe there is something useful here.
If anyone ever opened the source code for the classes java.util.concurrent, they could not help but notice in the authors Doug Lea (Doug Lee), professor Oswego (Osuigo) of the University of New York. The list of his most famous developments included java collections and util.concurrent , which in one form or another were reflected in existing JDKs. He also wrote a dlmalloc implementation for dynamic memory allocation. Concurrent Programming in Java: Design Principles and Pattern, 2nd Edition . More information can be found on his homepage .

Speech by Doug Lea at the JVM Language Summit in 2010.
Probably many had a feeling of some chaos with a quick glance at java.util.concurrent. In the same package, different classes are mixed with completely different functionalities, which makes it somewhat difficult to understand what it is and how it works. Therefore, it is possible to schematically divide classes and interfaces according to a functional attribute, and then run through the implementation of specific parts.
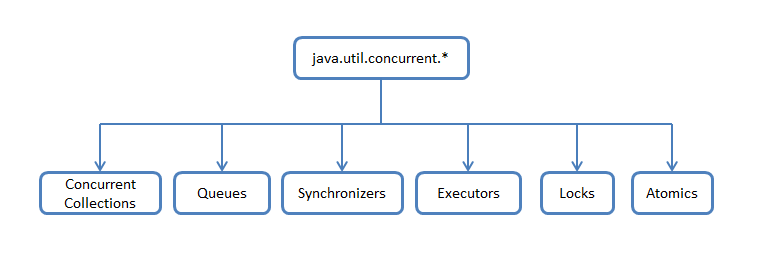
Concurrent Collections is a collection of collections that work more effectively in a multithreaded environment than standard universal collections from the java.util package. Instead of the base wrapper Collections.synchronizedList with blocking access to the entire collection, blocking by data segments is used, or work is optimized for parallel reading of data on wait-free algorithms.
Queues - non-blocking and blocking queues with multithreading support. Non-blocking queues are sharpened for speed and operation without blocking threads. Blocking queues are used when you need to “slow down” the “Producer” or “Consumer” streams, if some conditions are not met, for example, the queue is empty or replayed, or there is no free “Consumer” 'a.
Synchronizers are helper utilities for thread synchronization. Represent a powerful weapon in "parallel" calculations.
Executors - contains excellent frameworks for creating thread pools, scheduling work of asynchronous tasks with getting results.
Locks - is an alternative and more flexible thread synchronization mechanisms compared to the basic synchronized, wait, notify, notifyAll.
Atomics - classes with support for atomic operations on primitives and references.
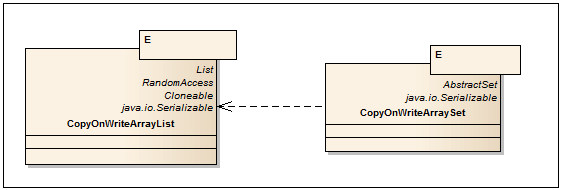
The name speaks for itself. All operations to modify the collection (add, set, remove) lead to the creation of a new copy of the internal array. This ensures that when iterating through the collection, ConcurrentModificationException is not thrown. It should be remembered that when copying an array, only references (references) to objects (shallow copy) are copied, including access to fields of elements is not thread-safe. CopyOnWrite collections are useful when write operations are quite rare, for example, when implementing the listeners subscription mechanism and passing through them.
CopyOnWriteArrayList <E>
 - Thread safe analog ArrayList, implemented with CopyOnWrite algorithm.
- Thread safe analog ArrayList, implemented with CopyOnWrite algorithm.
CopyOnWriteArraySet <E> - Implementation of the Set interface, using CopyOnWriteArrayList as the basis. Unlike CopyOnWriteArrayList, there are no additional methods.
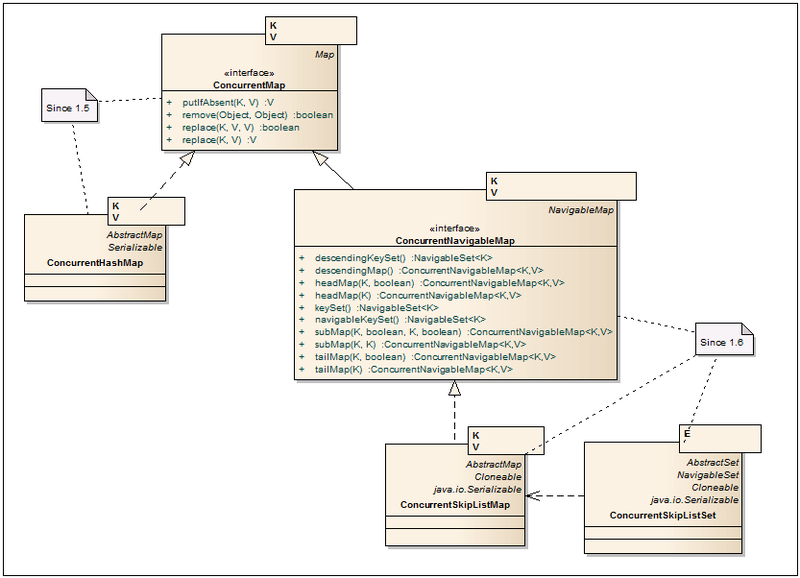
Improved implementations of HashMap, TreeMap with better support for multithreading and scalability.
ConcurrentMap <K, V> - An interface that extends the Map with several additional atomic operations.
- An interface that extends the Map with several additional atomic operations.
ConcurrentHashMap <K, V> - Unlike Hashtable and synhronized blocks on a HashMap, data is presented in the form of segments, divided by hash keys. As a result, data access is tracked by segments, and not by one object. In addition, iterators provide data for a specific time slice and do not throw a ConcurrentModificationException. In more detail ConcurrentHashMap is described in habratopik here .
ConcurrentNavigableMap <K, V> - Extends the NavigableMap interface and forces the use of ConcurrentNavigableMap objects as return values. All iterators are declared safe to use and do not throw a ConcurrentModificationException.
- Extends the NavigableMap interface and forces the use of ConcurrentNavigableMap objects as return values. All iterators are declared safe to use and do not throw a ConcurrentModificationException.
ConcurrentSkipListMap <K, V> - Is an analogue of a treemap with multithreading support. The data is also sorted by key and the average log (N) performance is guaranteed for containsKey, get, put, remove, and other similar operations. Algorithm SkipList described on the Wiki and Habré .
ConcurrentSkipListSet <E> - Implementation of the Set interface, made on the basis of ConcurrentSkipListMap.

Thread-safe and non-blocking implementation of Queue on linked nodes.
ConcurrentLinkedQueue <E> - The implementation uses the wait-free algorithm from Michael & Scott, adapted for working with the garbage collector. This algorithm is quite effective and, most importantly, very fast, because built on CAS . The size () method can work for a long time, t.ch. better not to jerk it all the time. A detailed description of the algorithm can be found here .
ConcurrentLinkedDeque <E> - Deque stands for Double ended queue and reads like “Deck”. This means that data can be added and pulled from both sides. Accordingly, the class supports both modes of operation: FIFO (First In First Out) and LIFO (Last In First Out). In practice, ConcurrentLinkedDeque should be used only if it is necessary to use LIFO, since due to the bidirectional node, this class loses in performance by 40% compared with the ConcurrentLinkedQueue.
- Deque stands for Double ended queue and reads like “Deck”. This means that data can be added and pulled from both sides. Accordingly, the class supports both modes of operation: FIFO (First In First Out) and LIFO (Last In First Out). In practice, ConcurrentLinkedDeque should be used only if it is necessary to use LIFO, since due to the bidirectional node, this class loses in performance by 40% compared with the ConcurrentLinkedQueue.
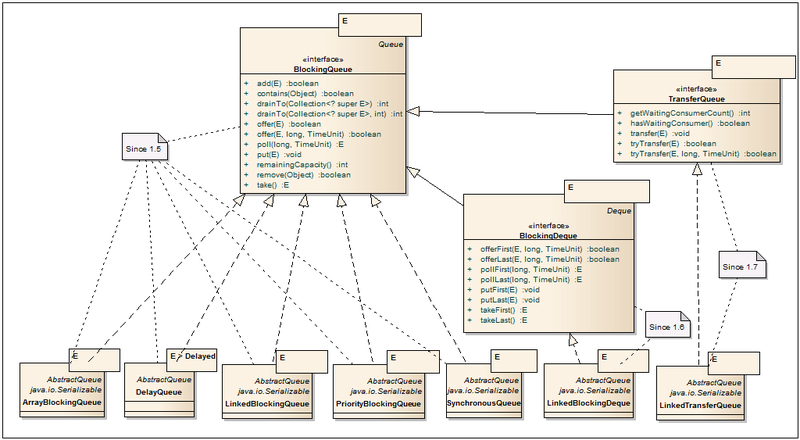
BlockingQueue <E> - When processing large data streams through queues, it is clearly not enough to use ConcurrentLinkedQueue. If the threads clearing the queue no longer cope with the influx of data, then you can quickly get out of memory or overload IO / Net so that performance drops by several times until the system fails due to timeouts or because there are no free descriptors in the system. For such cases, you need a queue with the ability to set the size of the queue or with locks on the conditions. This is where the BlockingQueue interface appears, opening the way to a whole set of useful classes. In addition to the ability to set the queue size, new methods have been added that react differently to the non-filling or queue overflow. So, for example, when adding an item to an overflowing queue, one method will throw IllegalStateException, another will return false, the third will block the stream until a place appears, the fourth will block the stream with timeout and return false if the place does not appear. It is also worth noting that blocking queues do not support null values, since This value is used in the poll method as a timeout indicator.
ArrayBlockingQueue <E> - A blocking queue class built on a classic circular buffer. In addition to the size of the queue, it is possible to manage the "integrity" of locks. If fair = false (by default), then the order of the threads is not guaranteed. More details about “honesty” can be found in the description of ReentrantLock.
DelayQueue <E extends Delayed> - A rather specific class that allows you to pull items out of the queue only after a certain delay defined in each item through the Delayed interface’s getDelay method.
LinkedBlockingQueue <E> - Blocking queue on connected nodes, implemented on the “two lock queue” algorithm: one lock to add, the other to pull out the element. Due to the two locks, compared with ArrayBlockingQueue, this class shows better performance, but it also has a higher memory consumption. The queue size is set through the constructor and the default is Integer.MAX_VALUE.
PriorityBlockingQueue <E> - Is a multi-threaded wrapper over a PriorityQueue. When an element is inserted into a queue, its order is determined in accordance with the logic of the Comparator or the implementation of the Comparable interface for the elements. The first out of the queue is the smallest element.
SynchronousQueue <E> - This queue works on the principle of one entered, one out. Each insertion operation blocks the Producer stream until the Consumer thread pulls the item out of the queue and vice versa, the Consumer waits until the Producer inserts the item.
BlockingDeque <E> - An interface describing additional methods for a bidirectional blocking queue. Data can be inserted and pulled from both sides of the queue.
LinkedBlockingDeque <E> - Bidirectional blocking queue on connected nodes, implemented as a simple bidirectional list with one lock. The queue size is set through the constructor and the default is Integer.MAX_VALUE.
TransferQueue <E> - This interface can be interesting in that when adding an item to a queue, it is possible to block the inserting “Producer” stream until another “Consumer” flow pulls the item out of the queue. A lock can be either with a timeout or it can be replaced by checking for the presence of waiting “Consumer” s. Thus, it becomes possible to implement a message transfer mechanism that supports both synchronous and asynchronous messages.
LinkedTransferQueue <E> - Implementing TransferQueue based on Dual Queues with Slack algorithm. Actively uses CAS and parking flows when they are in standby mode.
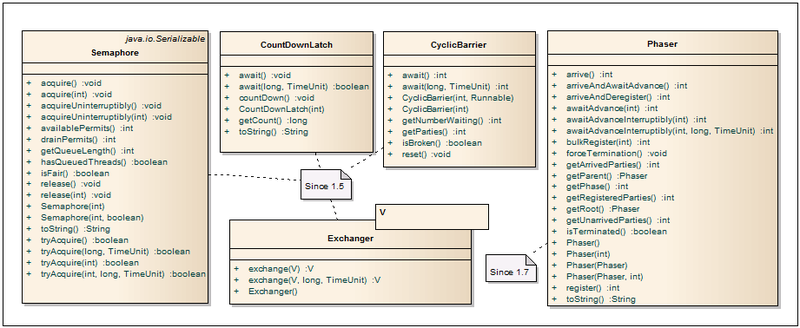
This section presents classes for active thread management.
Semaphore - Semaphores are most often used to limit the number of threads when working with hardware resources or a file system. Access to a shared resource is controlled by a counter. If it is greater than zero, then access is allowed, and the value of the counter decreases. If the counter is zero, the current thread is blocked until another thread releases the resource. The number of permissions and "honesty" of the release of threads is set through the constructor. The bottleneck when using semaphores is setting the number of permissions, since often this number has to be selected depending on the power of the “iron”.
CountDownLatch - Allows one or more threads to wait until a certain number of operations are completed, performing in other threads. The classic driver example describes the class logic quite well: The threads that call the driver will hang in the await method (with or without timeout) until the driver stream initializes and then calls the countDown method. This method reduces the count down counter by one. As soon as the counter becomes zero, all the waiting threads in await will continue their work, and all subsequent await calls will pass without waiting. The count down counter is one-time and cannot be reset to its original state.
CyclicBarrier - Can be used to synchronize a specified number of threads at one point. The barrier is reached when N-threads call the await (...) method and block. After that, the counter is reset to its original value, and the waiting threads are freed. Additionally, if needed, it is possible to run a special code before unlocking threads and resetting the counter. For this, an object with the implementation of the Runnable interface is passed through the constructor.
Exchanger <V> - As the name implies, the main purpose of this class is the exchange of objects between two streams. At the same time, null values are also supported, which allows using this class to transfer only one object or simply as a synchronizer of two streams. The first thread that calls the exchange (...) method will block until the same method calls the second thread. As soon as this happens, the threads will exchange values and continue their work.
Phaser - Improved implementation of the barrier to synchronize threads, which combines the functionality of CyclicBarrier and CountDownLatch, incorporating the best of them. Thus, the number of threads is not strictly specified and can dynamically change. The class can be reused and report the readiness of a thread without blocking it. More details can be found in habratopik here .
So we got to the biggest part of the package. Interfaces for running asynchronous tasks with the ability to get results through Future and Callable interfaces, as well as services and factories for creating thread pools: ThreadPoolExecutor, ScheduledPoolExecutor, ForkJoinPool will be described here. For better understanding, let's make a small decomposition of interfaces and classes.
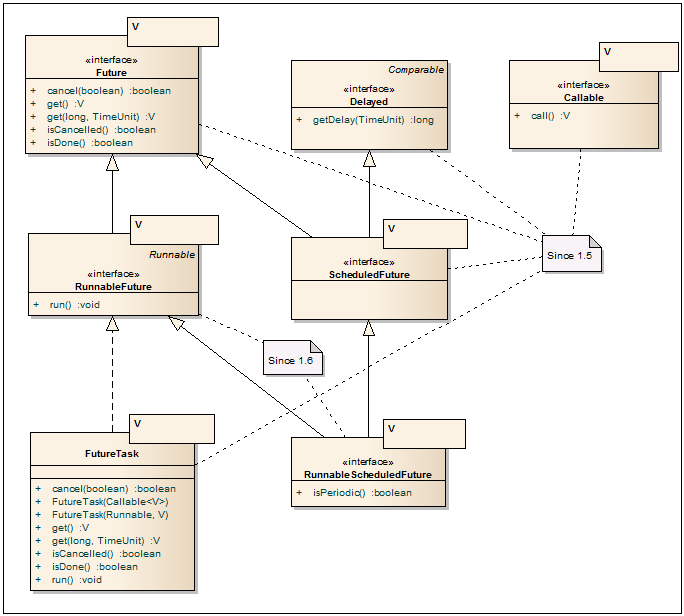
Future <V> - A great interface for getting the results of an asynchronous operation. The key method here is the get method, which blocks the current thread (with or without timeout) until the asynchronous operation completes on another thread. Also, in addition, there are methods for canceling the operation and checking the current status. The FutureTask class is often used as implementation.
RunnableFuture <V> - If Future is an interface for the Client API, then the RunnableFuture interface is already used to start the asynchronous part. Successful completion of the run () method completes the asynchronous operation and allows you to pull the results through the get method.
Callable <V> - Enhanced analogue interface Runnable for asynchronous operations. Allows you to return a typed value and throw a checked exception. Although there is no run () method in this interface, many java.util.concurrent classes support it along with Runnable.
FutureTask <V> - Future / RunnableFuture interface implementation. An asynchronous operation is taken to the input of one of the constructors in the form of Runnable or Callable objects. The very same FutureTask class is designed to run in a worker thread, for example, through new Thread (task) .start (), or through ThreadPoolExecutor. The results of an asynchronous operation are pulled out via the get (...) method.
Delayed - Used for asynchronous tasks that should start in the future, as well as in the DelayQueue. Allows you to set the time to start an asynchronous operation.
ScheduledFuture <V> - Marker interface, combining Future and Delayed interfaces.
RunnableScheduledFuture <V> - Interface that combines RunnableFuture and ScheduledFuture. Additionally, you can specify whether the task is a one-time task or it should be launched at a specified frequency.
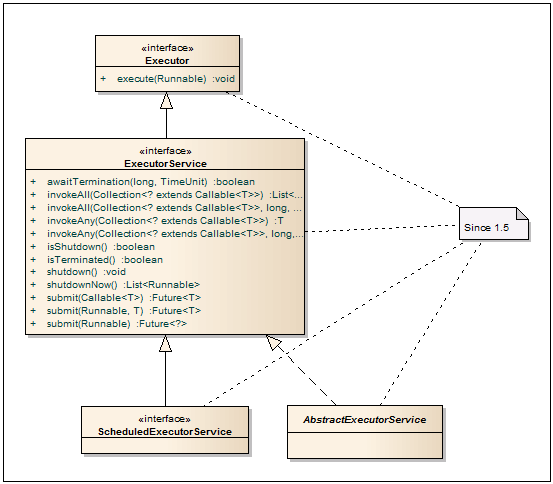
Executor - It is a basic interface for classes that run runnable tasks. This ensures the isolation between adding a task and the way it is launched.
ExecutorService - An interface that describes a service for running Runnable or Callable tasks. The submit methods on an input accept a task in the form of Callable or Runnable, and the return value is the Future, through which you can get the result. The invokeAll methods work with task lists with blocking the thread until all tasks in the passed list are completed or the specified timeout period expires. The invokeAny methods block the calling thread until the completion of any transferred tasks. Additionally, the interface contains methods for graceful shutdown. After calling the shutdown method, this service will no longer accept tasks, throwing a RejectedExecutionException when trying to throw a task into the service.
ScheduledExecutorService - In addition to the methods ExecutorService, this interface adds the ability to run pending tasks.
AbstractExecutorService - Abstract class for building ExecutorService. The implementation contains the basic implementation of the methods submit, invokeAll, invokeAny. ThreadPoolExecutor, ScheduledThreadPoolExecutor, and ForkJoinPool are inherited from this class.
- Abstract class for building ExecutorService. The implementation contains the basic implementation of the methods submit, invokeAll, invokeAny. ThreadPoolExecutor, ScheduledThreadPoolExecutor, and ForkJoinPool are inherited from this class.
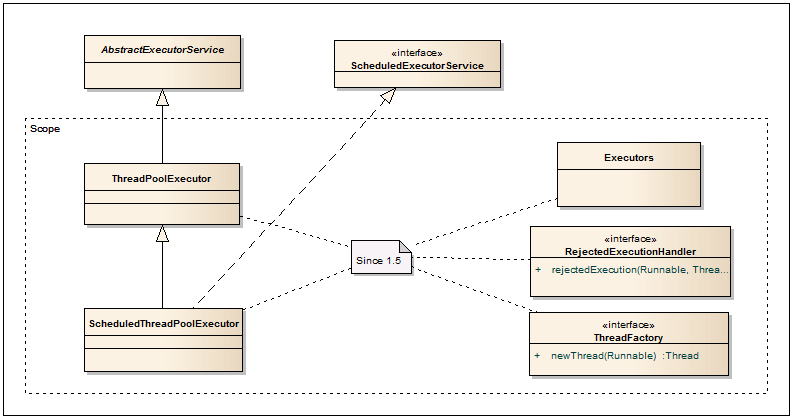
Executors - Factory class for creating ThreadPoolExecutor, ScheduledThreadPoolExecutor. If you need to create one of these pools, this factory is exactly what you need. Also, it contains various adapters Runnable-Callable, PrivilegedAction-Callable, PrivilegedExceptionAction-Callable and others.
- Factory class for creating ThreadPoolExecutor, ScheduledThreadPoolExecutor. If you need to create one of these pools, this factory is exactly what you need. Also, it contains various adapters Runnable-Callable, PrivilegedAction-Callable, PrivilegedExceptionAction-Callable and others.
ThreadPoolExecutor - Very powerful and important class. Used to run asynchronous tasks in the thread pool. Thus, the overhead to raise and stop flows is almost completely absent. And due to the fixed maximum of threads in the pool, the projected application performance is ensured. As previously stated, it is preferable to create this pool through one of the methods of the Executors factory. If the standard configuration is not enough, then through the designers or setters you can set all the basic parameters of the pool. More information can be found in this topic .
ScheduledThreadPoolExecutor - In addition to the methods ThreadPoolExecutor, allows you to run tasks after a certain delay, as well as with a certain frequency, which allows you to implement Timer Service on the basis of this class.
Threadfactory - By default, ThreadPoolExecutor uses a standard thread factory, obtained through Executors.defaultThreadFactory (). If you need something more, for example, setting a priority or a thread name, then you can create a class with the implementation of this interface and pass it to ThreadPoolExecutor.
RejectedExecutionHandler - Allows you to define a handler for tasks that for some reason can not be performed through ThreadPoolExecutor. Such a case can occur when there are no free threads or the service is shutting down or shutting down (shutdown). Several standard implementations are in the ThreadPoolExecutor class: CallerRunsPolicy - runs the task in the calling thread; AbortPolicy - throws an extra; DiscardPolicy - ignores the task; DiscardOldestPolicy - removes the oldest unallocated task from the queue, then tries to add a new task again.

In java 1.7, a new Fork Join framework for solving recursive tasks using the divide and manage or Map Reduce algorithms has appeared . To make it clearer, you can give a visual example of the quicksort sorting algorithm:
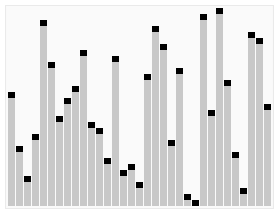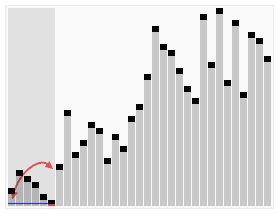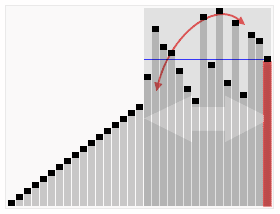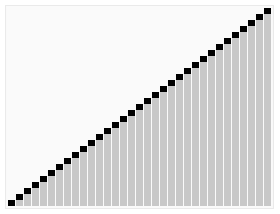
So, due to splitting into parts, it is possible to achieve their parallel processing in different streams. To solve this problem, you can use the usual ThreadPoolExecutor, but due to frequent context switching and tracking the execution control, all this does not work very effectively. This is where the Fork Join framework comes to the rescue. It is based on the work-stealing algorithm. Most well reveals itself in systems with a large number of processors. More information can be found on the blog here or the publication of Doug Lea. Pro performance and scalability can be read here .
ForkJoinPool - It is an entry point for running root (main) ForkJoinTask tasks. Subtasks are launched through the methods of the task from which you want to shoot (fork). By default, a thread pool is created with the number of threads equal to the number of cores available for JVM processors.
ForkJoinTask - Base class for all Fork Join tasks. Key methods include: fork () - adds a task to the current thread's queue ForkJoinWorkerThread for asynchronous execution; invoke () - runs the task in the current thread; join () - waits for completion of the subtask with the return of the result; invokeAll (...) - combines all three previous previous operations, performing two or more tasks in one go; adapt (...) - creates a new task ForkJoinTask from Runnable or Callable objects.
RecursiveTask - Abstract class from ForkJoinTask, with the declaration of the compute method, in which an asynchronous operation should be performed in the heir.
RecursiveAction - Differs from RecursiveTask in that it does not return a result.
ForkJoinWorkerThread - Used as default implementation in ForkJoinPoll. If desired, you can follow and overload the initialization and completion methods of the worker flow.
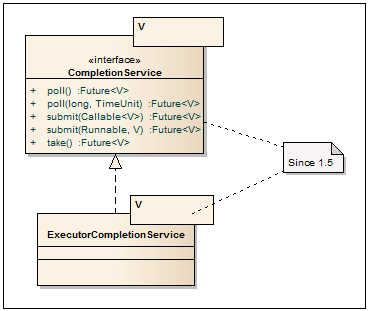
CompletionService - Service interface with decoupling the launch of asynchronous tasks and obtaining results. So, for adding tasks, the submit methods are used, and for pulling the results of completed tasks, the blocking take method and non-blocking poll are used.
ExecutorCompletionService - In fact, it is a wrapper over any class that implements the Executor interface, for example ThreadPoolExecutor or ForkJoinPool. It is used mainly when you want to abstract from the method of launching tasks and controlling their execution. If there are completed tasks - pull them out, if not - wait in take until something is completed. The default service is based on LinkedBlockingQueue, but any other implementation of BlockingQueue can be transmitted.
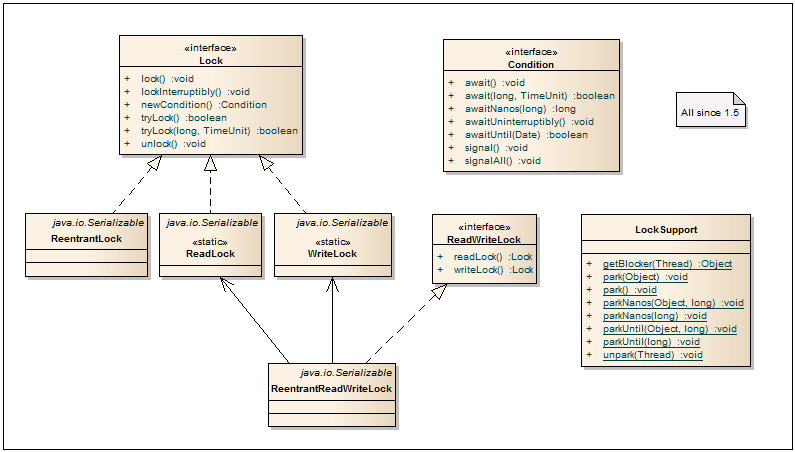
Condition - An interface that describes alternative methods to the standard wait / notify / notifyAll. An object with a condition is most often obtained from locks via the lock.newCondition () method. Thereby it is possible to get several sets of wait / notify for one object.
Lock - The base interface of the lock framework, which provides a more flexible approach to limit access to resources / blocks rather than using synchronized. So, when using multiple locks, the order of their release can be arbitrary. Plus there is an opportunity to go on an alternative scenario, if the lock is already captured by someone.
Reentrant lock - Lock on entry. Only one thread can enter a protected block. The class supports “fair” (fair) and “unfair” (non-fair) unblocking of threads. When “fair” unlocking, the order of freeing the threads calling lock () is observed. With “unfair” unlocking, the order of freeing threads is not guaranteed, but, as a bonus, such unlocking works faster. By default, “unfair” unlocking is used.
ReadWriteLock - Additional interface for creating read / write locks. Such locks are extremely useful when the system has many reads and few write operations.
ReentrantReadWriteLock - Very often used in multithreaded services and caches, showing a very good performance boost compared to synchronized blocks.In fact, the class works in 2 mutually exclusive modes: many readers read data in parallel and when only 1 writer writes data.
ReentrantReadWriteLock.ReadLock - Read lock for readers, obtained through readWriteLock.readLock ().
ReentrantReadWriteLock.WriteLock - Write lock for writers, obtained through readWriteLock.writeLock ().
LockSupport - Designed for building classes with locks. Contains methods for parking threads instead of obsolete methods Thread.suspend () and Thread.resume ().
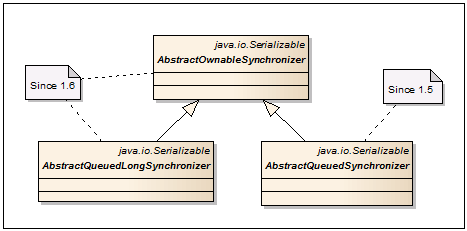
AbstractOwnableSynchronizer - The base class for building mechanisms for synchronization. It contains only one pair of getter / setter for storing and reading an exclusive stream that can work with data.
AbstractQueuedSynchronizer - Used as the base class for the synchronization mechanism in FutureTask, CountDownLatch, Semaphore, ReentrantLock, ReentrantReadWriteLock. It can be used to create new synchronization mechanisms that rely on single and atomic int values.
AbstractQueuedLongSynchronizer - An AbstractQueuedSynchronizer variation that supports an atomic long value.

AtomicBoolean , AtomicInteger , AtomicLong , AtomicIntegerArray , AtomicLongArray - What if a class needs to synchronize access to one simple int variable? You can use constructions with synchronized, and when using atomic set / get operations, volatile is also suitable. But you can do even better by using the new Atomic classes *. Through the use of CAS , operations with these classes work faster than if synchronized via synchronized / volatile. Plus, there are methods for atomic addition by a given amount, as well as increment / decrement.
AtomicReference - A class for atomic operations with an object reference.
AtomicMarkableReference - A class for an atomic operation with the following pair of fields: an object reference and a bit flag (true / false).
AtomicStampedReference - A class for an atomic operation with the following pair of fields: an object reference and an int value.
AtomicReferenceArray - An array of object references that can be atomically updated.
AtomicIntegerFieldUpdater , AtomicLongFieldUpdater , AtomicReferenceFieldUpdater - Classes for the atomic update of fields by their names through reflection. The offset fields for CAS is determined in the constructor and cached, t.ch. there is no dramatic drop in performance due to reflection.
Thank you for reading to the end, or at least leafing through the article to the end. I just want to emphasize that there is only a brief description of the classes without any examples. This was done deliberately so as not to clutter the article with excessive code inserts. The basic idea: to give a quick overview of the classes in order to know which direction to go and what to use. Examples of using classes can be easily found on the Internet or in the source code of the classes themselves. I hope this post will help to quickly and efficiently solve interesting problems with multithreading.

What to choose for a particular case? In terms of parking and deadlines, it is quite difficult to cover the entire java.util.concurrent. Something similar is selected and go! So, gradually, ArrayBlockingQueue, ConcurrentHashMap, AtomicInteger, Collections.synchronizedList (new LinkedList ()) and other interesting things appear in the code. Sometimes right, sometimes not. At some point in time you begin to realize that more than 95% of the standard classes in java are not used at all in product development. Collections, primitives, shifting from one place to another, hibernate, spring or EJB, some other library and, voila, the application is ready.
In order to somehow streamline knowledge and facilitate entry into the topic, below is a review of classes for working with multithreading. I write primarily as a cheat sheet for myself. And if anyone else is fit, it is generally wonderful.
')
For seed
Immediately bring a couple of interesting links. The first is for those who float a little in multithreading. The second for "advanced" programmers - maybe there is something useful here.
A little about the author of the java.util.concurrent package
If anyone ever opened the source code for the classes java.util.concurrent, they could not help but notice in the authors Doug Lea (Doug Lee), professor Oswego (Osuigo) of the University of New York. The list of his most famous developments included java collections and util.concurrent , which in one form or another were reflected in existing JDKs. He also wrote a dlmalloc implementation for dynamic memory allocation. Concurrent Programming in Java: Design Principles and Pattern, 2nd Edition . More information can be found on his homepage .
Speech by Doug Lea at the JVM Language Summit in 2010.
According to the chords
Probably many had a feeling of some chaos with a quick glance at java.util.concurrent. In the same package, different classes are mixed with completely different functionalities, which makes it somewhat difficult to understand what it is and how it works. Therefore, it is possible to schematically divide classes and interfaces according to a functional attribute, and then run through the implementation of specific parts.
Concurrent Collections is a collection of collections that work more effectively in a multithreaded environment than standard universal collections from the java.util package. Instead of the base wrapper Collections.synchronizedList with blocking access to the entire collection, blocking by data segments is used, or work is optimized for parallel reading of data on wait-free algorithms.
Queues - non-blocking and blocking queues with multithreading support. Non-blocking queues are sharpened for speed and operation without blocking threads. Blocking queues are used when you need to “slow down” the “Producer” or “Consumer” streams, if some conditions are not met, for example, the queue is empty or replayed, or there is no free “Consumer” 'a.
Synchronizers are helper utilities for thread synchronization. Represent a powerful weapon in "parallel" calculations.
Executors - contains excellent frameworks for creating thread pools, scheduling work of asynchronous tasks with getting results.
Locks - is an alternative and more flexible thread synchronization mechanisms compared to the basic synchronized, wait, notify, notifyAll.
Atomics - classes with support for atomic operations on primitives and references.
1. Concurrent Collections
CopyOnWrite collections
The name speaks for itself. All operations to modify the collection (add, set, remove) lead to the creation of a new copy of the internal array. This ensures that when iterating through the collection, ConcurrentModificationException is not thrown. It should be remembered that when copying an array, only references (references) to objects (shallow copy) are copied, including access to fields of elements is not thread-safe. CopyOnWrite collections are useful when write operations are quite rare, for example, when implementing the listeners subscription mechanism and passing through them.
CopyOnWriteArrayList <E>
- Thread safe analog ArrayList, implemented with CopyOnWrite algorithm.Additional methods and constructor
| CopyOnWriteArrayList (E [] toCopyIn) | A constructor that takes an array as input. |
| int indexOf (E e, int index) | Returns the index of the first found item, starting the search with the specified index. |
| int lastIndexOf (E e, int index) | Returns the index of the first element found in the reverse search, starting at the specified index. |
| boolean addIfAbsent (E e) | Add an item if it is not in the collection. To compare elements, use the equals method. |
| int addAllAbsent (Collection <? extends E> c) | Add items if they are missing from the collection. Returns the number of elements added. |
CopyOnWriteArraySet <E>
- Implementation of the Set interface, using CopyOnWriteArrayList as the basis. Unlike CopyOnWriteArrayList, there are no additional methods.Scalable Maps
Improved implementations of HashMap, TreeMap with better support for multithreading and scalability.
ConcurrentMap <K, V>
- An interface that extends the Map with several additional atomic operations.Additional methods
| V putIfAbsent (K key, V value) | Adds a new key-value pair only if the key is not in the collection. Returns the previous value for the specified key. |
| boolean remove (Object key, Object value) | Removes a key-value pair only if the specified key matches the specified value in the Map. Returns true if the item was successfully deleted. |
| boolean replace (K key, V oldValue, V newValue) | Replaces the old value with the new one by key only if the old value corresponds to the specified value in the Map. Returns true if the value has been replaced with a new one. |
| V replace (K key, V value) | Replaces the old value with the new one by key only if the key is associated with any value. Returns the previous value for the specified key. |
ConcurrentHashMap <K, V>
- Unlike Hashtable and synhronized blocks on a HashMap, data is presented in the form of segments, divided by hash keys. As a result, data access is tracked by segments, and not by one object. In addition, iterators provide data for a specific time slice and do not throw a ConcurrentModificationException. In more detail ConcurrentHashMap is described in habratopik here .Additional constructor
| ConcurrentHashMap (int initialCapacity, float loadFactor, int concurrencyLevel) | The 3rd parameter of the constructor is the expected number of simultaneously writing streams. The default value is 16. Affects the size of the collection in memory and performance. |
ConcurrentNavigableMap <K, V>
- Extends the NavigableMap interface and forces the use of ConcurrentNavigableMap objects as return values. All iterators are declared safe to use and do not throw a ConcurrentModificationException.ConcurrentSkipListMap <K, V>
- Is an analogue of a treemap with multithreading support. The data is also sorted by key and the average log (N) performance is guaranteed for containsKey, get, put, remove, and other similar operations. Algorithm SkipList described on the Wiki and Habré .ConcurrentSkipListSet <E>
- Implementation of the Set interface, made on the basis of ConcurrentSkipListMap.2. Queues
Non-Blocking Queues
Thread-safe and non-blocking implementation of Queue on linked nodes.
ConcurrentLinkedQueue <E>
- The implementation uses the wait-free algorithm from Michael & Scott, adapted for working with the garbage collector. This algorithm is quite effective and, most importantly, very fast, because built on CAS . The size () method can work for a long time, t.ch. better not to jerk it all the time. A detailed description of the algorithm can be found here .ConcurrentLinkedDeque <E>
- Deque stands for Double ended queue and reads like “Deck”. This means that data can be added and pulled from both sides. Accordingly, the class supports both modes of operation: FIFO (First In First Out) and LIFO (Last In First Out). In practice, ConcurrentLinkedDeque should be used only if it is necessary to use LIFO, since due to the bidirectional node, this class loses in performance by 40% compared with the ConcurrentLinkedQueue.Blocking queues
BlockingQueue <E>
- When processing large data streams through queues, it is clearly not enough to use ConcurrentLinkedQueue. If the threads clearing the queue no longer cope with the influx of data, then you can quickly get out of memory or overload IO / Net so that performance drops by several times until the system fails due to timeouts or because there are no free descriptors in the system. For such cases, you need a queue with the ability to set the size of the queue or with locks on the conditions. This is where the BlockingQueue interface appears, opening the way to a whole set of useful classes. In addition to the ability to set the queue size, new methods have been added that react differently to the non-filling or queue overflow. So, for example, when adding an item to an overflowing queue, one method will throw IllegalStateException, another will return false, the third will block the stream until a place appears, the fourth will block the stream with timeout and return false if the place does not appear. It is also worth noting that blocking queues do not support null values, since This value is used in the poll method as a timeout indicator.ArrayBlockingQueue <E>
- A blocking queue class built on a classic circular buffer. In addition to the size of the queue, it is possible to manage the "integrity" of locks. If fair = false (by default), then the order of the threads is not guaranteed. More details about “honesty” can be found in the description of ReentrantLock.DelayQueue <E extends Delayed>
- A rather specific class that allows you to pull items out of the queue only after a certain delay defined in each item through the Delayed interface’s getDelay method.LinkedBlockingQueue <E>
- Blocking queue on connected nodes, implemented on the “two lock queue” algorithm: one lock to add, the other to pull out the element. Due to the two locks, compared with ArrayBlockingQueue, this class shows better performance, but it also has a higher memory consumption. The queue size is set through the constructor and the default is Integer.MAX_VALUE.PriorityBlockingQueue <E>
- Is a multi-threaded wrapper over a PriorityQueue. When an element is inserted into a queue, its order is determined in accordance with the logic of the Comparator or the implementation of the Comparable interface for the elements. The first out of the queue is the smallest element.SynchronousQueue <E>
- This queue works on the principle of one entered, one out. Each insertion operation blocks the Producer stream until the Consumer thread pulls the item out of the queue and vice versa, the Consumer waits until the Producer inserts the item.BlockingDeque <E>
- An interface describing additional methods for a bidirectional blocking queue. Data can be inserted and pulled from both sides of the queue.LinkedBlockingDeque <E>
- Bidirectional blocking queue on connected nodes, implemented as a simple bidirectional list with one lock. The queue size is set through the constructor and the default is Integer.MAX_VALUE.TransferQueue <E>
- This interface can be interesting in that when adding an item to a queue, it is possible to block the inserting “Producer” stream until another “Consumer” flow pulls the item out of the queue. A lock can be either with a timeout or it can be replaced by checking for the presence of waiting “Consumer” s. Thus, it becomes possible to implement a message transfer mechanism that supports both synchronous and asynchronous messages.LinkedTransferQueue <E>
- Implementing TransferQueue based on Dual Queues with Slack algorithm. Actively uses CAS and parking flows when they are in standby mode.3. Synchronizers
This section presents classes for active thread management.
Semaphore
- Semaphores are most often used to limit the number of threads when working with hardware resources or a file system. Access to a shared resource is controlled by a counter. If it is greater than zero, then access is allowed, and the value of the counter decreases. If the counter is zero, the current thread is blocked until another thread releases the resource. The number of permissions and "honesty" of the release of threads is set through the constructor. The bottleneck when using semaphores is setting the number of permissions, since often this number has to be selected depending on the power of the “iron”.CountDownLatch
- Allows one or more threads to wait until a certain number of operations are completed, performing in other threads. The classic driver example describes the class logic quite well: The threads that call the driver will hang in the await method (with or without timeout) until the driver stream initializes and then calls the countDown method. This method reduces the count down counter by one. As soon as the counter becomes zero, all the waiting threads in await will continue their work, and all subsequent await calls will pass without waiting. The count down counter is one-time and cannot be reset to its original state.CyclicBarrier
- Can be used to synchronize a specified number of threads at one point. The barrier is reached when N-threads call the await (...) method and block. After that, the counter is reset to its original value, and the waiting threads are freed. Additionally, if needed, it is possible to run a special code before unlocking threads and resetting the counter. For this, an object with the implementation of the Runnable interface is passed through the constructor.Exchanger <V>
- As the name implies, the main purpose of this class is the exchange of objects between two streams. At the same time, null values are also supported, which allows using this class to transfer only one object or simply as a synchronizer of two streams. The first thread that calls the exchange (...) method will block until the same method calls the second thread. As soon as this happens, the threads will exchange values and continue their work.Phaser
- Improved implementation of the barrier to synchronize threads, which combines the functionality of CyclicBarrier and CountDownLatch, incorporating the best of them. Thus, the number of threads is not strictly specified and can dynamically change. The class can be reused and report the readiness of a thread without blocking it. More details can be found in habratopik here .4. Executors
So we got to the biggest part of the package. Interfaces for running asynchronous tasks with the ability to get results through Future and Callable interfaces, as well as services and factories for creating thread pools: ThreadPoolExecutor, ScheduledPoolExecutor, ForkJoinPool will be described here. For better understanding, let's make a small decomposition of interfaces and classes.
Future and callable
Future <V>
- A great interface for getting the results of an asynchronous operation. The key method here is the get method, which blocks the current thread (with or without timeout) until the asynchronous operation completes on another thread. Also, in addition, there are methods for canceling the operation and checking the current status. The FutureTask class is often used as implementation.RunnableFuture <V>
- If Future is an interface for the Client API, then the RunnableFuture interface is already used to start the asynchronous part. Successful completion of the run () method completes the asynchronous operation and allows you to pull the results through the get method.Callable <V>
- Enhanced analogue interface Runnable for asynchronous operations. Allows you to return a typed value and throw a checked exception. Although there is no run () method in this interface, many java.util.concurrent classes support it along with Runnable.FutureTask <V>
- Future / RunnableFuture interface implementation. An asynchronous operation is taken to the input of one of the constructors in the form of Runnable or Callable objects. The very same FutureTask class is designed to run in a worker thread, for example, through new Thread (task) .start (), or through ThreadPoolExecutor. The results of an asynchronous operation are pulled out via the get (...) method.Delayed
- Used for asynchronous tasks that should start in the future, as well as in the DelayQueue. Allows you to set the time to start an asynchronous operation.ScheduledFuture <V>
- Marker interface, combining Future and Delayed interfaces.RunnableScheduledFuture <V>
- Interface that combines RunnableFuture and ScheduledFuture. Additionally, you can specify whether the task is a one-time task or it should be launched at a specified frequency.Executor services
Executor
- It is a basic interface for classes that run runnable tasks. This ensures the isolation between adding a task and the way it is launched.ExecutorService
- An interface that describes a service for running Runnable or Callable tasks. The submit methods on an input accept a task in the form of Callable or Runnable, and the return value is the Future, through which you can get the result. The invokeAll methods work with task lists with blocking the thread until all tasks in the passed list are completed or the specified timeout period expires. The invokeAny methods block the calling thread until the completion of any transferred tasks. Additionally, the interface contains methods for graceful shutdown. After calling the shutdown method, this service will no longer accept tasks, throwing a RejectedExecutionException when trying to throw a task into the service.ScheduledExecutorService
- In addition to the methods ExecutorService, this interface adds the ability to run pending tasks.AbstractExecutorService
- Abstract class for building ExecutorService. The implementation contains the basic implementation of the methods submit, invokeAll, invokeAny. ThreadPoolExecutor, ScheduledThreadPoolExecutor, and ForkJoinPool are inherited from this class.ThreadPoolExecutor & Factory
Executors
- Factory class for creating ThreadPoolExecutor, ScheduledThreadPoolExecutor. If you need to create one of these pools, this factory is exactly what you need. Also, it contains various adapters Runnable-Callable, PrivilegedAction-Callable, PrivilegedExceptionAction-Callable and others.ThreadPoolExecutor
- Very powerful and important class. Used to run asynchronous tasks in the thread pool. Thus, the overhead to raise and stop flows is almost completely absent. And due to the fixed maximum of threads in the pool, the projected application performance is ensured. As previously stated, it is preferable to create this pool through one of the methods of the Executors factory. If the standard configuration is not enough, then through the designers or setters you can set all the basic parameters of the pool. More information can be found in this topic .ScheduledThreadPoolExecutor
- In addition to the methods ThreadPoolExecutor, allows you to run tasks after a certain delay, as well as with a certain frequency, which allows you to implement Timer Service on the basis of this class.Threadfactory
- By default, ThreadPoolExecutor uses a standard thread factory, obtained through Executors.defaultThreadFactory (). If you need something more, for example, setting a priority or a thread name, then you can create a class with the implementation of this interface and pass it to ThreadPoolExecutor.RejectedExecutionHandler
- Allows you to define a handler for tasks that for some reason can not be performed through ThreadPoolExecutor. Such a case can occur when there are no free threads or the service is shutting down or shutting down (shutdown). Several standard implementations are in the ThreadPoolExecutor class: CallerRunsPolicy - runs the task in the calling thread; AbortPolicy - throws an extra; DiscardPolicy - ignores the task; DiscardOldestPolicy - removes the oldest unallocated task from the queue, then tries to add a new task again.Fork join
In java 1.7, a new Fork Join framework for solving recursive tasks using the divide and manage or Map Reduce algorithms has appeared . To make it clearer, you can give a visual example of the quicksort sorting algorithm:
So, due to splitting into parts, it is possible to achieve their parallel processing in different streams. To solve this problem, you can use the usual ThreadPoolExecutor, but due to frequent context switching and tracking the execution control, all this does not work very effectively. This is where the Fork Join framework comes to the rescue. It is based on the work-stealing algorithm. Most well reveals itself in systems with a large number of processors. More information can be found on the blog here or the publication of Doug Lea. Pro performance and scalability can be read here .
ForkJoinPool
- It is an entry point for running root (main) ForkJoinTask tasks. Subtasks are launched through the methods of the task from which you want to shoot (fork). By default, a thread pool is created with the number of threads equal to the number of cores available for JVM processors.ForkJoinTask
- Base class for all Fork Join tasks. Key methods include: fork () - adds a task to the current thread's queue ForkJoinWorkerThread for asynchronous execution; invoke () - runs the task in the current thread; join () - waits for completion of the subtask with the return of the result; invokeAll (...) - combines all three previous previous operations, performing two or more tasks in one go; adapt (...) - creates a new task ForkJoinTask from Runnable or Callable objects.RecursiveTask
- Abstract class from ForkJoinTask, with the declaration of the compute method, in which an asynchronous operation should be performed in the heir.RecursiveAction
- Differs from RecursiveTask in that it does not return a result.ForkJoinWorkerThread
- Used as default implementation in ForkJoinPoll. If desired, you can follow and overload the initialization and completion methods of the worker flow.Completion Service
CompletionService
- Service interface with decoupling the launch of asynchronous tasks and obtaining results. So, for adding tasks, the submit methods are used, and for pulling the results of completed tasks, the blocking take method and non-blocking poll are used.ExecutorCompletionService
- In fact, it is a wrapper over any class that implements the Executor interface, for example ThreadPoolExecutor or ForkJoinPool. It is used mainly when you want to abstract from the method of launching tasks and controlling their execution. If there are completed tasks - pull them out, if not - wait in take until something is completed. The default service is based on LinkedBlockingQueue, but any other implementation of BlockingQueue can be transmitted.5. Locks
Condition
- An interface that describes alternative methods to the standard wait / notify / notifyAll. An object with a condition is most often obtained from locks via the lock.newCondition () method. Thereby it is possible to get several sets of wait / notify for one object.Lock
- The base interface of the lock framework, which provides a more flexible approach to limit access to resources / blocks rather than using synchronized. So, when using multiple locks, the order of their release can be arbitrary. Plus there is an opportunity to go on an alternative scenario, if the lock is already captured by someone.Reentrant lock
- Lock on entry. Only one thread can enter a protected block. The class supports “fair” (fair) and “unfair” (non-fair) unblocking of threads. When “fair” unlocking, the order of freeing the threads calling lock () is observed. With “unfair” unlocking, the order of freeing threads is not guaranteed, but, as a bonus, such unlocking works faster. By default, “unfair” unlocking is used.ReadWriteLock
- Additional interface for creating read / write locks. Such locks are extremely useful when the system has many reads and few write operations.ReentrantReadWriteLock
- Very often used in multithreaded services and caches, showing a very good performance boost compared to synchronized blocks.In fact, the class works in 2 mutually exclusive modes: many readers read data in parallel and when only 1 writer writes data.ReentrantReadWriteLock.ReadLock
- Read lock for readers, obtained through readWriteLock.readLock ().ReentrantReadWriteLock.WriteLock
- Write lock for writers, obtained through readWriteLock.writeLock ().LockSupport
- Designed for building classes with locks. Contains methods for parking threads instead of obsolete methods Thread.suspend () and Thread.resume ().AbstractOwnableSynchronizer
- The base class for building mechanisms for synchronization. It contains only one pair of getter / setter for storing and reading an exclusive stream that can work with data.AbstractQueuedSynchronizer
- Used as the base class for the synchronization mechanism in FutureTask, CountDownLatch, Semaphore, ReentrantLock, ReentrantReadWriteLock. It can be used to create new synchronization mechanisms that rely on single and atomic int values.AbstractQueuedLongSynchronizer
- An AbstractQueuedSynchronizer variation that supports an atomic long value.6. Atomics
AtomicBoolean , AtomicInteger , AtomicLong , AtomicIntegerArray , AtomicLongArray
- What if a class needs to synchronize access to one simple int variable? You can use constructions with synchronized, and when using atomic set / get operations, volatile is also suitable. But you can do even better by using the new Atomic classes *. Through the use of CAS , operations with these classes work faster than if synchronized via synchronized / volatile. Plus, there are methods for atomic addition by a given amount, as well as increment / decrement.AtomicReference
- A class for atomic operations with an object reference.AtomicMarkableReference
- A class for an atomic operation with the following pair of fields: an object reference and a bit flag (true / false).AtomicStampedReference
- A class for an atomic operation with the following pair of fields: an object reference and an int value.AtomicReferenceArray
- An array of object references that can be atomically updated.AtomicIntegerFieldUpdater , AtomicLongFieldUpdater , AtomicReferenceFieldUpdater
- Classes for the atomic update of fields by their names through reflection. The offset fields for CAS is determined in the constructor and cached, t.ch. there is no dramatic drop in performance due to reflection.Instead of conclusion
Thank you for reading to the end, or at least leafing through the article to the end. I just want to emphasize that there is only a brief description of the classes without any examples. This was done deliberately so as not to clutter the article with excessive code inserts. The basic idea: to give a quick overview of the classes in order to know which direction to go and what to use. Examples of using classes can be easily found on the Internet or in the source code of the classes themselves. I hope this post will help to quickly and efficiently solve interesting problems with multithreading.
Source: https://habr.com/ru/post/157273/
All Articles