Puppet under load
 Puppet is a fairly convenient configuration management tool. In fact, this is a system that allows you to automate the configuration and management of a large fleet of machines and services.
Puppet is a fairly convenient configuration management tool. In fact, this is a system that allows you to automate the configuration and management of a large fleet of machines and services.There is a lot of basic information about the system itself, including on Habré: here , here and here . We tried to collect in one article several “recipes” of using Puppet under really large loads - in the “combat conditions” of Badoo.
What will be discussed:
')
- Puppet: educational program;
- clustering, scaling;
- asynchronous Storeconfigs;
- collection of reports;
- data analysis.
Immediately make a reservation that the article is written in the wake of the report of Anton Turetsky at the HighLoad ++ 2012 conference. Over the course of a few days, our “recipes” are overgrown with additional details and examples.
Returning to the loads, it should be noted that in Badoo they are really high:
- more than 2000 servers;
- more than 30,000 lines in manifests (English manifest , in this case - the configuration file for the management server);
- more than 200 servers accessing puppet master every 3 minutes;
- over 200 servers sending reports in the same time period.
How it works

By itself, the Puppet application is client-server. In the case of Puppet, the initiator of the connection is the client; in this case, this is the node (English node ) on which you want to deploy the configuration.
Step 1: facts in exchange for configuration

The client collects facts about himself with the help of the facter utility, an essential dependency of the Puppet application, then sends them with a regular HTTP POST request to the server and waits for his response.
Step 2: processing and response
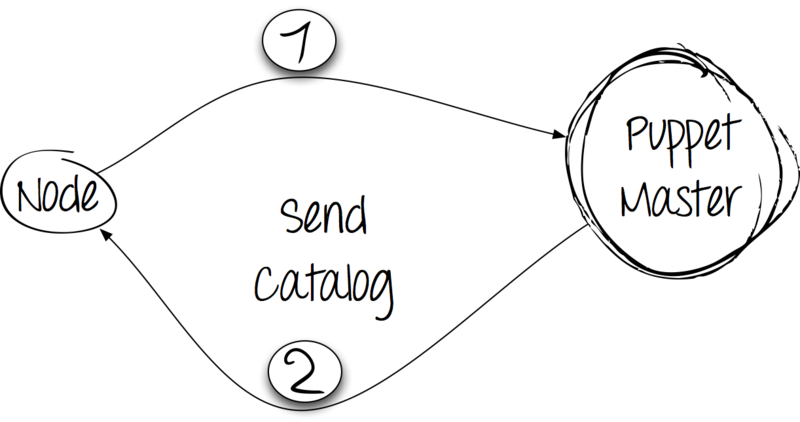
The server receives a dump with facts from the client and compiles the directory. At the same time, it proceeds from the information in the manifests available on the server, but also takes into account the facts received from the client. The catalog is sent to the client.
Step 3: apply the catalog and report the results

Having received the catalog from the server, the client makes changes in the system. Reports the results of the execution to the server using an HTTP POST request.
Step 4: collecting and storing reports
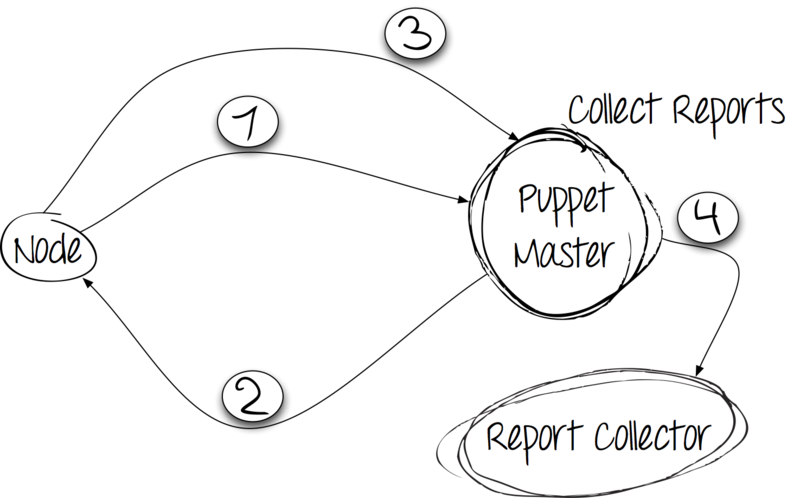
After the client has completed all the rules, the report should be saved. Puppet proposes to use both their own groundwork and third-party collectors for this. We try!
Install the base package and get the following picture:
At first glance, everything is fine - set and work. However, over time, the picture becomes less joyful. The number of clients is increasing, system administrators are writing manifests, which increase the time spent on compiling code and processing each client.
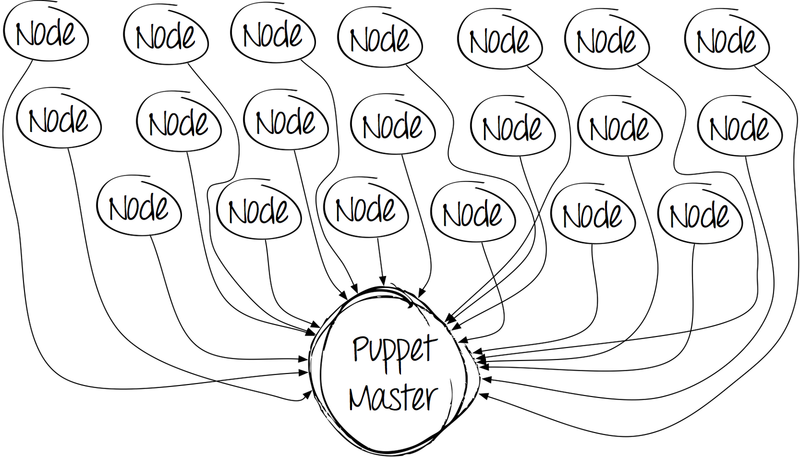
And at a certain point the picture becomes very sad.
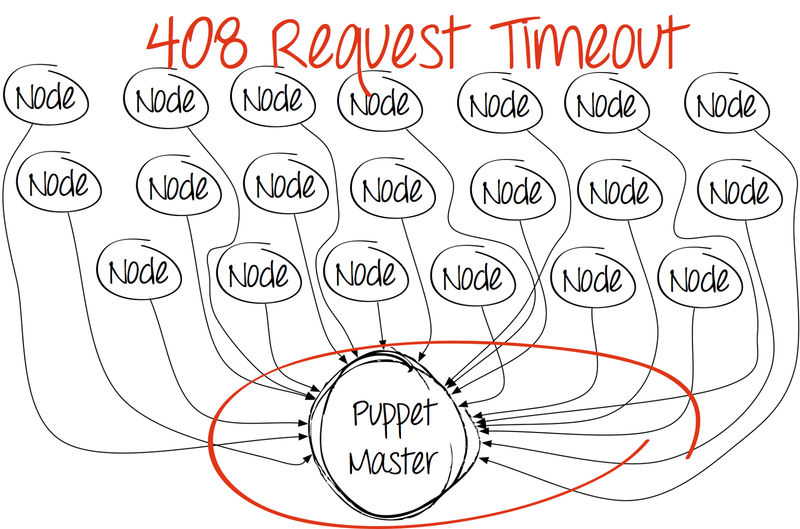
The first thing that comes to mind is to increase the number of puppet master processes on the server. Yes, precisely because Puppet does not know how to do this in the basic delivery, and it is not “smeared” by the cores.
Are there any solutions offered by the manufacturer? Of course, but for various reasons they turned out to be inapplicable in our conditions.
Why not Apache + mod_passenger? For some reason, our company does not use the Apache web server at all.
Why not nginx + passenger? To avoid the need for an additional module in the nginx build that we use.
What then?
Meet Unicorn
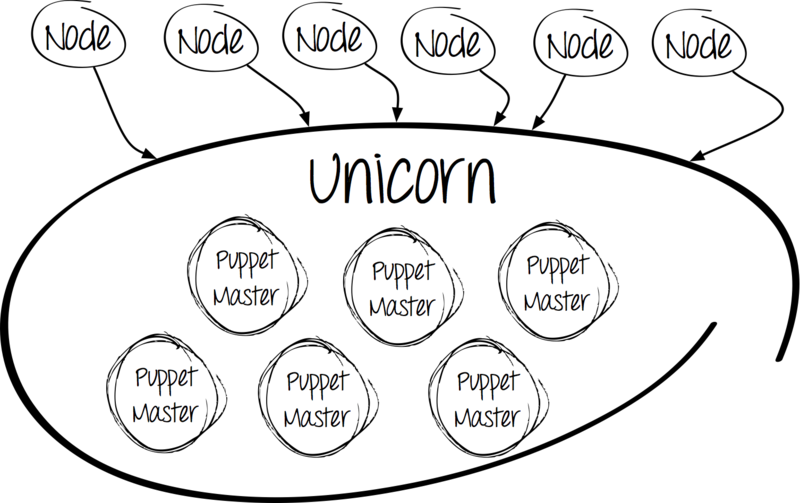
Why Unicorn ?
Here, in our opinion, its advantages:
- Linux kernel level balancing
- running all processes in your environment;
- update without losing the “nginx-style” connections;
- the ability to listen on multiple interfaces;
- similar to PHP-FPM, but for Ruby.
Another reason for choosing Unicorn was the simplicity of its installation and configuration.
worker_processes 12 working_directory "/etc/puppet" listen '0.0.0.0:3000', :backlog => 512 preload_app true timeout 120 pid "/var/run/puppet/puppetmaster_unicorn.pid" if GC.respond_to?(:copy_on_write_friendly=) GC.copy_on_write_friendly = true end before_fork do |server, worker| old_pid = "#{server.config[:pid]}.oldbin" if File.exists?(old_pid) && server.pid != old_pid begin Process.kill("QUIT", File.read(old_pid).to_i) rescue Errno::ENOENT, Errno::ESRCH end end end So, the good news: we have the ability to run multiple processes. But there is also a bad one: managing processes has become much more difficult. Not scary - for this situation, there is a "recipe".
"In God We Trust"
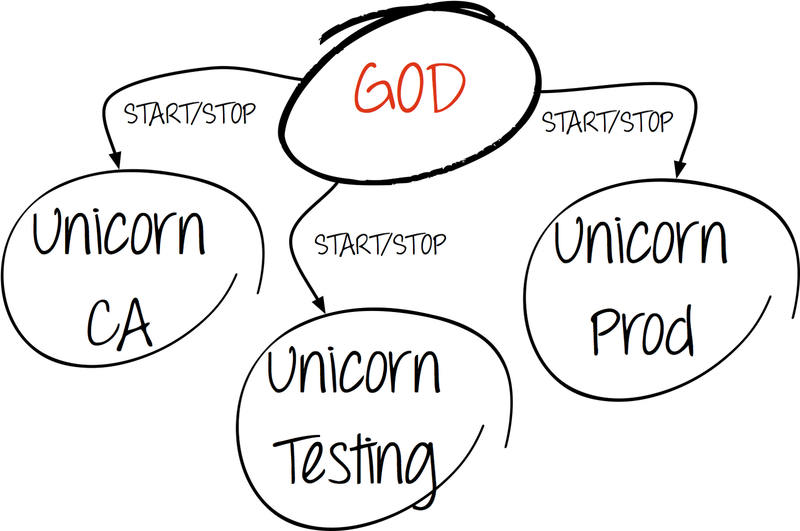
God is a process monitoring framework. It is easy to set up and written in Ruby, like Puppet itself.
In our case, God manages various instances of puppet master processes:
- production environment;
- testing environment;
- Puppet CA.
With the setting of special problems also does not arise. It is enough to create a configuration file in the / etc / god / directory to process * .god files.
God.watch do |w| w.name = "puppetmaster" w.interval = 30.seconds w.pid_file = "/var/run/puppet/puppetmaster_unicorn.pid" w.start = "cd /etc/puppet && /usr/bin/unicorn -c /etc/puppet/unicorn.conf -D" w.stop = "kill -QUIT `cat #{w.pid_file}`" w.restart = "kill -USR2 `cat #{w.pid_file}`" w.start_grace = 10.seconds w.restart_grace = 10.seconds w.uid = "puppet" w.gid = "puppet" w.behavior(:clean_pid_file) w.start_if do |start| start.condition(:process_running) do |c| c.interval = 5.seconds c.running = false end end end Please note that we have allocated Puppet CA to a separate instance. This was done specifically so that all customers use a single source to verify and obtain their certificates. A little later we will tell how to achieve this.
Balancing
As already mentioned, the entire process of exchanging information between the client and the server occurs via HTTP, which means that nothing prevents us from setting up a simple http balancing using the help of nginx.
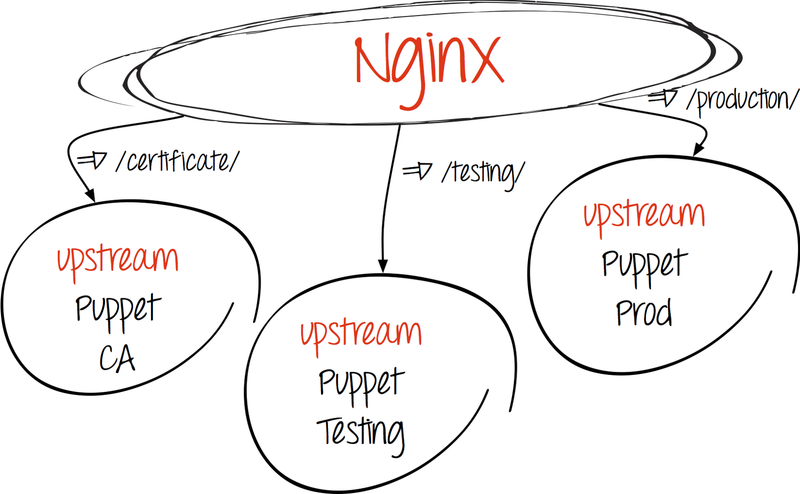
- Create upstream:
upstream puppetmaster_unicorn { server 127.0.0.1:3000 fail_timeout=0; server server2:3000 fail_timeout=0; } # puppet master ( , production-) upstream puppetca { server 127.0.0.1:3000 fail_timeout=0; } # Puppet CA - We redirect requests to recipients:
- Puppet ca
location ^~ /production/certificate/ca { proxy_pass http://puppetca; } location ^~ /production/certificate { proxy_pass http://puppetca; } location ^~ /production/certificate_revocation_list/ca { proxy_pass http://puppetca; } - Puppet master
location / { proxy_pass http://puppetmaster_unicorn; proxy_redirect off; }
- Puppet ca
Let's sum up the intermediate results. So, the above actions allow us to:
- run multiple processes;
- manage the launch processes;
- balance the load.
And scaling?
The technical capabilities of the puppet master server are not limitless, and if the loads on it become the maximum permissible, then the question of scaling arises.
This problem is solved as follows:
- The RPM package for our puppet server is stored in our repository;
- all manifestos, as well as configurations for God and Unicorn are in our Git repository.
To start another server is enough for us:
- put the base system;
- install puppet-server, Unicorn, God;
- clone git repository;
- add car upstream.
At this, our "tuning" does not end, so let us return to the theory again.
Storeconfigs: what and why?
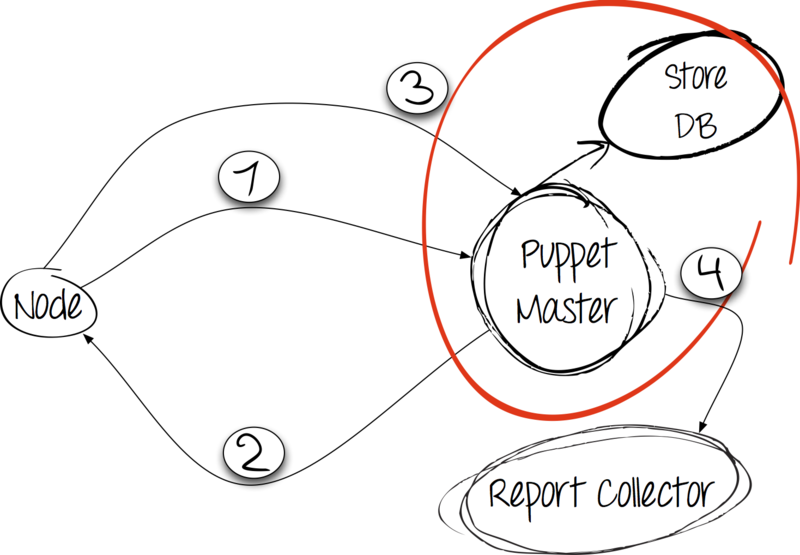
If a client sends us a report and facts about himself, then why not keep this information?
This will help us Storeconfigs - option puppet-server, which allows you to store current customer information in the database. The system compares the latest data from the client with the existing ones. Storeconfigs supports the following storages: SQLite, MySQL, PostgreSQL. We use MySQL.
In our case, many clients pick up the configuration every three minutes, about the same send reports. As a result, we already get large queues to write to MySQL. But we still have to take data from the database.
This problem received the following solution:
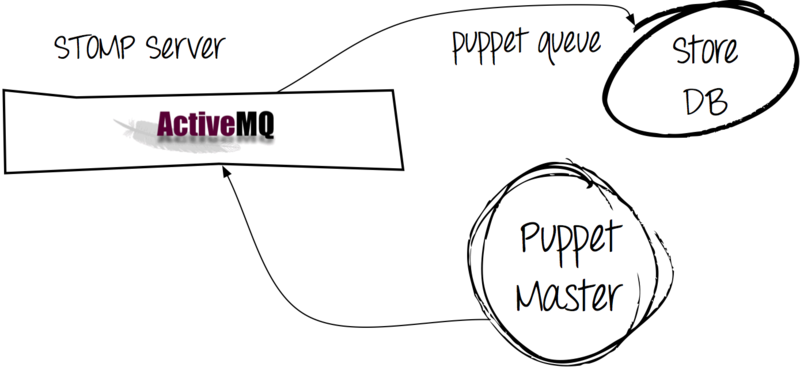
Using Apache ActiveMQ allowed us to send messages from clients not immediately to the database, but to pass them through the message queue.
As a result, we have:
- faster execution of the puppet process on the client, because when you try to send a report to the server, it immediately receives an “OK” (it is easier to put a message in the queue than to write it to the database);
- reducing the load on MySQL (the puppet queue process writes data to the database asynchronously).
To configure puppet-server, it was necessary to add the following lines to the configuration:
[main] async_storeconfigs = true queue_type = stomp queue_source = stomp://ACTIVEMQ_address:61613 dbadapter = mysql dbuser = secretuser dbpassword = secretpassword dbserver = mysql-server And let's not forget about starting the puppet queue process.
Thanks to the described settings, Puppet works on the server smartly and well, but it would be good to regularly monitor its activity. It is time to remember about Puppet Reports.
Non-standard reporting
What is offered to us by default:
- http;
- tagmai;
- log;
- rrdgraph;
- store.
Alas, none of the options completely satisfied us for one reason - the lack of a high-quality visual component. Unfortunately, and perhaps fortunately, the standard Puppet Dashboard at that moment seemed too boring to us.
Therefore, we opted for Foreman , which pleased us with cute charts with the most necessary.


In the picture on the left we see how much time is spent on the use of each type of resources. For 360 degrees, the total execution time on the client is taken.
The picture on the right displays the number of events with the status. In this example, only one service was launched, more than 10 events were missed due to the fact that their current state fully corresponds to the reference one.
And the last recommendation: upgrade to version 3.0.0

The graph clearly shows the time gain after the update. True, productivity has grown not by 50%, as the developers promised, but the increase turned out to be quite tangible. After editing the manifestos (see the message ), we still achieved the promised 50%, so our efforts were fully justified.
In conclusion, with proper configuration, Puppet is able to cope with serious workloads and configuration management for 2000 servers is well within its reach.
Anton [ banuchka ] Turkish, system administrator
Badoo
Source: https://habr.com/ru/post/157023/
All Articles